Feature-map-level Online Adversarial Knowledge Distillation论文笔记
论文地址:https://arxiv.org/abs/2002.01775v1
github地址:未公布
Motivation
Feature maps中包含丰富的空间相关性等图像信息,但是在分类任务上,过去的online Knowledge Distillation只利用了类别概率来进行学习,因此这篇文章提出使用对抗训练的方式在线互相学习feature map的分布,并结合原有的类别概率学习来进一步提升分类的精度。
Method

作者提出了如上图所示的框架图,该框架称为AFD(Online Adversarial Feature map Distillation)。图中以训练两个网络 Θ 1 , Θ 2 \varTheta_1, \varTheta_2 Θ1,Θ2为例,在原有的基于logit的预测上,另外增加一个基于feature-map的判断。其中基于 l o g i t logit logit的 l o s s loss loss包含两部分,一部分是传统的交叉熵,另一部分是使用KL散度定义的互蒸馏 l o s s loss loss(mutual distillation loss),基于feature map的loss通过判决器discriminator间接学习蒸馏feature map。在该框架中,训练 K K K个network则需要 K K K个判决器,每个判决器对应一个network,network输出的feature map被对应的判决器判别为fake,而将另一个network输出的feature map判别为real,从而使得该network学习到另一个network的feature map的特征分布。
- Logit-based mutual knowledge loss
L l o g i t 1 = L c e ( y , σ ( z 1 ) ) + T 2 × L k l ( σ ( z 2 / T ) , σ ( z 1 / T ) ) L l o g i t 2 = L c e ( y , σ ( z 2 ) ) + T 2 × L k l ( σ ( z 1 / T ) , σ ( z 2 / T ) ) \mathcal{L}_{logit}^{1}=\mathcal{L}_{ce}\left( y,\sigma \left( z_1 \right) \right) +T^2\times \mathcal{L}_{kl}\left( \sigma \left( z_2/T \right) ,\sigma \left( z_1/T \right) \right) \\ \mathcal{L}_{logit}^{2}=\mathcal{L}_{ce}\left( y,\sigma \left( z_2 \right) \right) +T^2\times \mathcal{L}_{kl}\left( \sigma \left( z_1/T \right) ,\sigma \left( z_2/T \right) \right) Llogit1=Lce(y,σ(z1))+T2×Lkl(σ(z2/T),σ(z1/T))Llogit2=Lce(y,σ(z2))+T2×Lkl(σ(z1/T),σ(z2/T)) - Adversarial Training for Feature-map-based KD
L D 1 = [ 1 − D 1 ( T 2 ( G 2 ( x ) ) ) ] 2 + [ D 1 ( T 1 ( G 1 ( x ) ) ) ] 2 L G 1 = [ 1 − D 1 ( T 1 ( G 1 ( x ) ) ) ] 2 \mathcal{L}_{D_1}=\left[ 1-D_1\left( T_2\left( G_2\left( x \right) \right) \right) \right] ^2+\left[ D_1\left( T_1\left( G_1\left( x \right) \right) \right) \right] ^2 \\ \mathcal{L}_{G_1}=\left[ 1-D_1\left( T_1\left( G_1\left( x \right) \right) \right) \right] ^2 LD1=[1−D1(T2(G2(x)))]2+[D1(T1(G1(x)))]2LG1=[1−D1(T1(G1(x)))]2
同时,针对多网络的同时训练模式提出cyclic learning的方法。该方法为一种单循环训练,将每个network的知识迁移到下一个network中,最后一个network的知识迁移到第一个network中。这种方式的主要作用就是减少判决器的数量。
Experiment
运行现有方法的结果:基于距离的以及ablation study(消融研究)——通过删除部分网络来研究网络的性能了解网络


通过不同的设定比较不同方法的性能:包括应用于同一个网络和不同网络结构,以及训练多个网络
数据集: CIFAR-100
实验重复次数: 5 5 5
Batchsize: 128 128 128
epoch: 300 300 300
分类的lr: SGD 0.1 0.1 0.1, 0.01 @ 150 0.01@150 0.01@150, 0.001 @ 225 0.001@225 0.001@225
momentum: 0.9 0.9 0.9,weight decay: 1 0 − 4 10^{-4} 10−4
feature map的lr: ADAM 2 × 1 0 − 4 f o r 2\times10^{-4} for 2×10−4for D a n d and and G, 2 × 1 0 − 6 @ 75 2\times10^{-6}@75 2×10−6@75, 2 × 1 0 − 7 @ 150 2\times10^{-7}@150 2×10−7@150 epoch
Weight decay: 0.1 0.1 0.1


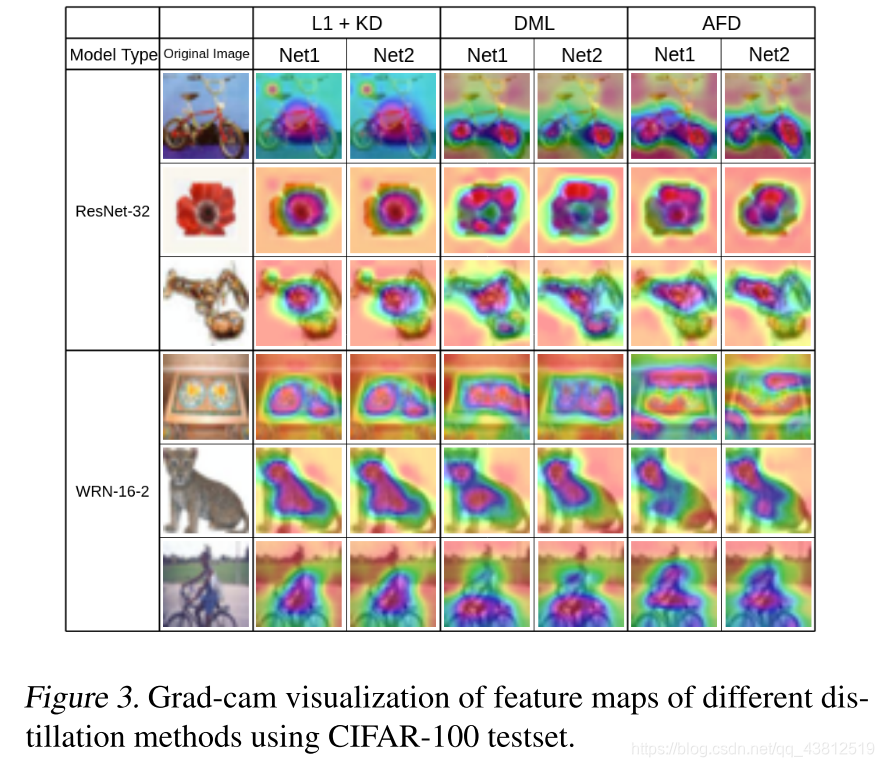
Analysis
作者使用 L 1 / L 2 L1/L2 L1/L2距离相似度与 c o s i n e cosine cosine相似度两种方式检测了三种方式训练不同network生成的feature map的相似度,并定性定量地分析了原因。