最近想要做一款语音听写APP,在网上搜索关于如何使用科大讯飞语音的Demo少之又少,又或者是只是单纯的按照文档来实现简单的语音听写,远远不能满足需求,看了几天的文档和自己搜索的一些资料,还有这几天中遇到的一些问题,觉得有必要做一个笔记,能给初学者一些帮助,也顺便理一下这些天的一些收获,本人只是一个初学者,假如有写得不对或者不好的地方,还望大家指出~~
1、首先当然是创建应用,我这里只是使用了语音听写的功能,创建完成后下载SDK,打开是这样子的:
2、导入SDK:
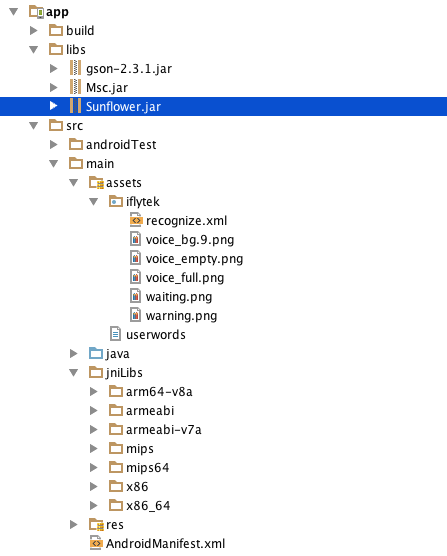
将开发工具包中libs目录下的Msc.jar和Sunflower.jar复制到Android工程的libs目录中,将online文件夹里面的子文件粘贴到工程目录src/main/jniLibs(这是Android studio 和eclipse的不同之处)。假如你要使用它自带的UI动画对话框录音,请将assets文件夹以及里面的子文件粘贴到工程目录src/main/下面,完成后如下图:
3、添加权限:
- <!–连接网络权限,用于执行云端语音能力 –>
- <uses-permission android:name=”android.permission.INTERNET”></uses-permission>
- <!–获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 –>
- <uses-permission android:name=”android.permission.RECORD_AUDIO”></uses-permission>
- <!–读取网络信息状态 –>
- <uses-permission android:name=”android.permission.ACCESS_NETWORK_STATE”></uses-permission>
- <!–获取当前wifi状态 –>
- <uses-permission android:name=”android.permission.ACCESS_WIFI_STATE”></uses-permission>
- <!–允许程序改变网络连接状态 –>
- <uses-permission android:name=”android.permission.CHANGE_NETWORK_STATE”></uses-permission>
- <!–读取手机信息权限 –>
- <uses-permission android:name=”android.permission.READ_PHONE_STATE”></uses-permission>
- <!–读取联系人权限,上传联系人需要用到此权限 –>
- <uses-permission android:name=”android.permission.READ_CONTACTS”></uses-permission>
- <!–假如我们要保存录音,还需要以下权限–>
- <!– 在SDCard中创建与删除文件权限 –>
- <uses-permission android:name=”android.permission.MOUNT_UNMOUNT_FILESYSTEMS”></uses-permission>
- <!– SD卡权限 –>
- <uses-permission android:name=”android.permission.WRITE_EXTERNAL_STORAGE”></uses-permission>
- <!– 允许程序读取或写入系统设置 –>
- <uses-permission android:name=”android.permission.WRITE_SETTINGS”></uses-permission>
<!--连接网络权限,用于执行云端语音能力 --> <uses-permission android:name="android.permission.INTERNET"></uses-permission> <!--获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 --> <uses-permission android:name="android.permission.RECORD_AUDIO"></uses-permission> <!--读取网络信息状态 --> <uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"></uses-permission> <!--获取当前wifi状态 --> <uses-permission android:name="android.permission.ACCESS_WIFI_STATE"></uses-permission> <!--允许程序改变网络连接状态 --> <uses-permission android:name="android.permission.CHANGE_NETWORK_STATE"></uses-permission> <!--读取手机信息权限 --> <uses-permission android:name="android.permission.READ_PHONE_STATE"></uses-permission> <!--读取联系人权限,上传联系人需要用到此权限 --> <uses-permission android:name="android.permission.READ_CONTACTS"></uses-permission> <!--假如我们要保存录音,还需要以下权限--> <!-- 在SDCard中创建与删除文件权限 --> <uses-permission android:name="android.permission.MOUNT_UNMOUNT_FILESYSTEMS"></uses-permission> <!-- SD卡权限 --> <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"></uses-permission> <!-- 允许程序读取或写入系统设置 --> <uses-permission android:name="android.permission.WRITE_SETTINGS"></uses-permission>
4、初始化:
//将“12345678”替换成您申请的APPID,申请地址:http://open.voicecloud.cn
SpeechUtility.createUtility(this, "appid=123456789");
数据收集接口:
- @Override
- protected void onResume() {
- // 开放统计 移动数据统计分析
- FlowerCollector.onResume(MainActivity.this);
- super.onResume();
- }
- @Override
- protected void onPause() {
- // 开放统计 移动数据统计分析
- FlowerCollector.onPause(MainActivity.this);
- super.onPause();
- }
@Override
protected void onResume() {
// 开放统计 移动数据统计分析
FlowerCollector.onResume(MainActivity.this);
super.onResume();
}
@Override
protected void onPause() {
// 开放统计 移动数据统计分析
FlowerCollector.onPause(MainActivity.this);
super.onPause();
}
说明:
1.确保在所有的 activity 中都调用 FlowerCollector.onResume() 和 FlowerCollector.onPause()方法。这两个调用将不会阻塞应用程序的主线程,也不会影响应用程序的性能。
2.注意,如果您的 Activity 之间有继承或者控制关系请不要同时在父和子 Activity 中重复添加onPause 和 onResume 方法,否则会造成重复统计(eg:使用 TabHost、TabActivity、ActivityGroup 时)。3.一个应用程序在多个 activity 之间连续切换时,会被视为同一个 session(启动)。4.当用户两次使用之间间隔超过 30 秒时,将被认为是两个的独立的 session(启动)。例如:用户回到home,或进入其他程序,经过一段时间后再返回之前的应用。
5.所有日志收集工作均在 onResume 之后进行,在 onPause 之后结束。 (ps:其实我也不懂这是干嘛的,猜想是为了收集数据的,还有一些参数设置我就不罗列了,有兴趣的同学可以去看,因为我发现就算没设置它们我也能进行语音听写,反正收集的数据我看不懂)
5、语音听写的使用(采取云端听写的引擎模式,暂时未考虑本地集成)
注意导包:com.iflytek.cloud而不是android.speech.SpeechRecognizer
1)使用自带UI语音对话框
优点:简单方便、美观
缺点:端点超时会自动停止识别(不理解的往下看设置参数说明)默认前段点:5000 后端点:1800
这是使用语音识别最简单的方法,在点击事件上调用start()方法就好了
- public void start() {
- //1.创建SpeechRecognizer对象,第二个参数:本地听写时传InitListener
- iatDialog = new RecognizerDialog(this, initListener);
- //2.设置听写参数
- iatDialog.setParameter(SpeechConstant.DOMAIN, “iat”);
- iatDialog.setParameter(SpeechConstant.LANGUAGE, “zh_cn”);
- iatDialog.setParameter(SpeechConstant.ACCENT, “mandarin ”);
- //3.设置回调接口
- iatDialog.setListener(new RecognizerDialogListener() {
- @Override
- public void onResult(RecognizerResult recognizerResult, boolean b) {
- if (!b) {
- String json = recognizerResult.getResultString();
- String str = JsonParser.parseIatResult(json);
- System.out.println(“说话内容:”+str);
- textView.setText(str);
- }
- }
- @Override
- public void onError(SpeechError speechError) {
- Log.d(“error”, speechError.toString());
- }
- });
- //4.开始听写
- iatDialog.show();
- }
public void start() {
//1.创建SpeechRecognizer对象,第二个参数:本地听写时传InitListener
iatDialog = new RecognizerDialog(this, initListener);
//2.设置听写参数
iatDialog.setParameter(SpeechConstant.DOMAIN, "iat");
iatDialog.setParameter(SpeechConstant.LANGUAGE, "zh_cn");
iatDialog.setParameter(SpeechConstant.ACCENT, "mandarin ");
//3.设置回调接口
iatDialog.setListener(new RecognizerDialogListener() {
@Override
public void onResult(RecognizerResult recognizerResult, boolean b) {
if (!b) {
String json = recognizerResult.getResultString();
String str = JsonParser.parseIatResult(json);
System.out.println("说话内容:"+str);
textView.setText(str);
}
}
@Override
public void onError(SpeechError speechError) {
Log.d("error", speechError.toString());
}
});
//4.开始听写
iatDialog.show();
}
增加if(!b)的判断是因为每次说话结束之后,返回数据的最后一次是返回一个标点符号”。”或者”!”之类的,当然你也可以设置不返回标点符号。
- //设置是否带标点符号 0表示不带标点,1则表示带标点。
- mIat.setParameter(SpeechConstant.ASR_PTT, ”0”);
//设置是否带标点符号 0表示不带标点,1则表示带标点。 mIat.setParameter(SpeechConstant.ASR_PTT, "0");
2)不使用自带UI对话框
优点:可以设置自己想要的参数
缺点:使用比较麻烦,对于初学者来讲,根据讲话音量大小自定义麦克风效果的View简直是噩梦(我不会,哪位大神做出来了求分享~~)
简单的用法:
1.创建对象:
- <span style=“font-size:18px;”>//1.创建SpeechRecognizer对象,第二个参数:本地听写时传InitListener
- mIat = SpeechRecognizer.createRecognizer(this, null);</span>
<span style="font-size:18px;">//1.创建SpeechRecognizer对象,第二个参数:本地听写时传InitListener mIat = SpeechRecognizer.createRecognizer(this, null);</span>
2.设置参数(听写这三个参数是必须的,下面设置时不再提示):
- mIat.setParameter(SpeechConstant.DOMAIN, “iat”);
- // 简体中文:”zh_cn”, 美式英文:”en_us”
- mIat.setParameter(SpeechConstant.LANGUAGE, ”zh_cn”);
- //普通话:mandarin(默认)
- //粤 语:cantonese
- //四川话:lmz
- //河南话:henanese
- mIat.setParameter(SpeechConstant.ACCENT, ”mandarin ”);
mIat.setParameter(SpeechConstant.DOMAIN, "iat"); // 简体中文:"zh_cn", 美式英文:"en_us" mIat.setParameter(SpeechConstant.LANGUAGE, "zh_cn"); //普通话:mandarin(默认) //粤 语:cantonese //四川话:lmz //河南话:henanese mIat.setParameter(SpeechConstant.ACCENT, "mandarin ");3.实例化监听对象
- private RecognizerListener recognizerListener = new RecognizerListener() {
- @Override
- public void onVolumeChanged(int i, byte[] bytes) {
- }
- @Override
- public void onBeginOfSpeech() {
- System.out.println(”开始识别”);
- }
- @Override
- public void onEndOfSpeech() {
- System.out.println(”识别结束”);
- }
- @Override
- public void onResult(RecognizerResult recognizerResult, boolean b) {
- String str=JsonParser.parseIatResult(recognizerResult.getResultString());
- System.out.println(”识别结果”+str);
- }
- @Override
- public void onError(SpeechError speechError) {
- System.out.println(”识别出错”);
- }
- @Override
- public void onEvent(int i, int i1, int i2, Bundle bundle) {
- }
- };
private RecognizerListener recognizerListener = new RecognizerListener() {
@Override
public void onVolumeChanged(int i, byte[] bytes) {
}
@Override
public void onBeginOfSpeech() {
System.out.println("开始识别");
}
@Override
public void onEndOfSpeech() {
System.out.println("识别结束");
}
@Override
public void onResult(RecognizerResult recognizerResult, boolean b) {
String str=JsonParser.parseIatResult(recognizerResult.getResultString());
System.out.println("识别结果"+str);
}
@Override
public void onError(SpeechError speechError) {
System.out.println("识别出错");
}
@Override
public void onEvent(int i, int i1, int i2, Bundle bundle) {
}
};
4.添加监听
- mIat.startListening(recognizerListener);
mIat.startListening(recognizerListener);
官方Demo给出的解析Json的类:
- package com.hxl.voicetest1;
- import org.json.JSONArray;
- import org.json.JSONObject;
- import org.json.JSONTokener;
- /**
- * Json结果解析类
- */
- public class JsonParser {
- public static String parseIatResult(String json) {
- StringBuffer ret = new StringBuffer();
- try {
- JSONTokener tokener = new JSONTokener(json);
- JSONObject joResult = new JSONObject(tokener);
- JSONArray words = joResult.getJSONArray(”ws”);
- for (int i = 0; i < words.length(); i++) {
- // 转写结果词,默认使用第一个结果
- JSONArray items = words.getJSONObject(i).getJSONArray(”cw”);
- JSONObject obj = items.getJSONObject(0);
- ret.append(obj.getString(”w”));
- //如果需要多候选结果,解析数组其他字段
- //for(int j = 0; j < items.length(); j++)
- //{
- //JSONObject obj = items.getJSONObject(j);
- //ret.append(obj.getString(“w”));
- //}
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- return ret.toString();
- }
- public static String parseGrammarResult(String json) {
- StringBuffer ret = new StringBuffer();
- try {
- JSONTokener tokener = new JSONTokener(json);
- JSONObject joResult = new JSONObject(tokener);
- JSONArray words = joResult.getJSONArray(”ws”);
- for (int i = 0; i < words.length(); i++) {
- JSONArray items = words.getJSONObject(i).getJSONArray(”cw”);
- for (int j = 0; j < items.length(); j++) {
- JSONObject obj = items.getJSONObject(j);
- if (obj.getString(“w”).contains(“nomatch”)) {
- ret.append(”没有匹配结果.”);
- return ret.toString();
- }
- ret.append(”【结果】” + obj.getString(“w”));
- ret.append(”【置信度】” + obj.getInt(“sc”));
- ret.append(”n”);
- }
- }
- } catch (Exception e) {
- e.printStackTrace();
- ret.append(”没有匹配结果.”);
- }
- return ret.toString();
- }
- }
package com.hxl.voicetest1;
import org.json.JSONArray;
import org.json.JSONObject;
import org.json.JSONTokener;
/**
* Json结果解析类
*/
public class JsonParser {
public static String parseIatResult(String json) {
StringBuffer ret = new StringBuffer();
try {
JSONTokener tokener = new JSONTokener(json);
JSONObject joResult = new JSONObject(tokener);
JSONArray words = joResult.getJSONArray("ws");
for (int i = 0; i < words.length(); i++) {
// 转写结果词,默认使用第一个结果
JSONArray items = words.getJSONObject(i).getJSONArray("cw");
JSONObject obj = items.getJSONObject(0);
ret.append(obj.getString("w"));
//如果需要多候选结果,解析数组其他字段
//for(int j = 0; j < items.length(); j++)
//{
//JSONObject obj = items.getJSONObject(j);
//ret.append(obj.getString("w"));
//}
}
} catch (Exception e) {
e.printStackTrace();
}
return ret.toString();
}
public static String parseGrammarResult(String json) {
StringBuffer ret = new StringBuffer();
try {
JSONTokener tokener = new JSONTokener(json);
JSONObject joResult = new JSONObject(tokener);
JSONArray words = joResult.getJSONArray("ws");
for (int i = 0; i < words.length(); i++) {
JSONArray items = words.getJSONObject(i).getJSONArray("cw");
for (int j = 0; j < items.length(); j++) {
JSONObject obj = items.getJSONObject(j);
if (obj.getString("w").contains("nomatch")) {
ret.append("没有匹配结果.");
return ret.toString();
}
ret.append("【结果】" + obj.getString("w"));
ret.append("【置信度】" + obj.getInt("sc"));
ret.append("n");
}
}
} catch (Exception e) {
e.printStackTrace();
ret.append("没有匹配结果.");
}
return ret.toString();
}
}
到这里,科大讯飞语音最简单的听写Demo就算完成了。这时你们会想:WTF?就这些我还不如自个儿看文档…..
当然了,既然写这篇博客,肯定不仅仅是简单介绍科大讯飞语音听写的使用而已。
我想要的效果是:无限制时间录音,并且我想知道我在第几秒说了什么话,回放录音的时候,播放到哪就显示相应的文字,还可以对识别错误的字段进行纠错修改。
我们来看一下一些常用的设置参数(个人认为),我们可以根据我们的需求来设置相应的参数
- // 清空参数
- mIat.setParameter(SpeechConstant.PARAMS, null);
- //短信和日常用语:iat (默认) 视频:video 地图:poi 音乐:music
- mIat.setParameter(SpeechConstant.DOMAIN, ”iat”);
- // 简体中文:”zh_cn”, 美式英文:”en_us”
- mIat.setParameter(SpeechConstant.LANGUAGE, ”zh_cn”);
- //普通话:mandarin(默认)
- //粤 语:cantonese
- //四川话:lmz
- //河南话:henanese<span style=”font-family: Menlo;”> </span>
- mIat.setParameter(SpeechConstant.ACCENT, ”mandarin ”);
- // 设置听写引擎 “cloud”, “local”,”mixed” 在线 本地 混合
- //本地的需要本地功能集成
- mIat.setParameter(SpeechConstant.ENGINE_TYPE, ”cloud”);
- // 设置返回结果格式 听写会话支持json和plain
- mIat.setParameter(SpeechConstant.RESULT_TYPE, ”json”);
- //设置是否带标点符号 0表示不带标点,1则表示带标点。
- mIat.setParameter(SpeechConstant.ASR_PTT, ”0”);
- //只有设置这个属性为1时,VAD_BOS VAD_EOS才会生效,且RecognizerListener.onVolumeChanged才有音量返回默认:1
- mIat.setParameter(SpeechConstant.VAD_ENABLE,”1”);
- // 设置语音前端点:静音超时时间,即用户多长时间不说话则当做超时处理1000~10000
- mIat.setParameter(SpeechConstant.VAD_BOS, ”5000”);
- // 设置语音后端点:后端点静音检测时间,即用户停止说话多长时间内即认为不再输入, 自动停止录音0~10000
- mIat.setParameter(SpeechConstant.VAD_EOS, ”1800”);
- // 设置音频保存路径,保存音频格式支持pcm、wav,设置路径为sd卡请注意WRITE_EXTERNAL_STORAGE权限
- // 注:AUDIO_FORMAT参数语记需要更新版本才能生效
- mIat.setParameter(SpeechConstant.AUDIO_FORMAT, ”wav”);
- //设置识别会话被中断时(如当前会话未结束就开启了新会话等),
- //是否通 过RecognizerListener.onError(com.iflytek.cloud.SpeechError)回调ErrorCode.ERROR_INTERRUPT错误。
- //默认false [null,true,false]
- mIat.setParameter(SpeechConstant.ASR_INTERRUPT_ERROR,”false”);
- //音频采样率 8000~16000 默认:16000
- mIat.setParameter(SpeechConstant.SAMPLE_RATE,”16000”);
- //默认:麦克风(1)(MediaRecorder.AudioSource.MIC)
- //在写音频流方式(-1)下,应用层通过writeAudio函数送入音频;
- //在传文件路径方式(-2)下,SDK通过应用层设置的ASR_SOURCE_PATH值, 直接读取音频文件。目前仅在SpeechRecognizer中支持。
- mIat.setParameter(SpeechConstant.AUDIO_SOURCE, ”-1”);
- //保存音频文件的路径 仅支持pcm和wav
- mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, Environment.getExternalStorageDirectory().getAbsolutePath() + ”test.wav”);
// 清空参数
mIat.setParameter(SpeechConstant.PARAMS, null);
//短信和日常用语:iat (默认) 视频:video 地图:poi 音乐:music
mIat.setParameter(SpeechConstant.DOMAIN, "iat");
// 简体中文:"zh_cn", 美式英文:"en_us"
mIat.setParameter(SpeechConstant.LANGUAGE, "zh_cn");
//普通话:mandarin(默认)
//粤 语:cantonese
//四川话:lmz
//河南话:henanese<span style="font-family: Menlo;"> </span>
mIat.setParameter(SpeechConstant.ACCENT, "mandarin ");
// 设置听写引擎 "cloud", "local","mixed" 在线 本地 混合
//本地的需要本地功能集成
mIat.setParameter(SpeechConstant.ENGINE_TYPE, "cloud");
// 设置返回结果格式 听写会话支持json和plain
mIat.setParameter(SpeechConstant.RESULT_TYPE, "json");
//设置是否带标点符号 0表示不带标点,1则表示带标点。
mIat.setParameter(SpeechConstant.ASR_PTT, "0");
//只有设置这个属性为1时,VAD_BOS VAD_EOS才会生效,且RecognizerListener.onVolumeChanged才有音量返回默认:1
mIat.setParameter(SpeechConstant.VAD_ENABLE,"1");
// 设置语音前端点:静音超时时间,即用户多长时间不说话则当做超时处理1000~10000
mIat.setParameter(SpeechConstant.VAD_BOS, "5000");
// 设置语音后端点:后端点静音检测时间,即用户停止说话多长时间内即认为不再输入, 自动停止录音0~10000
mIat.setParameter(SpeechConstant.VAD_EOS, "1800");
// 设置音频保存路径,保存音频格式支持pcm、wav,设置路径为sd卡请注意WRITE_EXTERNAL_STORAGE权限
// 注:AUDIO_FORMAT参数语记需要更新版本才能生效
mIat.setParameter(SpeechConstant.AUDIO_FORMAT, "wav");
//设置识别会话被中断时(如当前会话未结束就开启了新会话等),
//是否通 过RecognizerListener.onError(com.iflytek.cloud.SpeechError)回调ErrorCode.ERROR_INTERRUPT错误。
//默认false [null,true,false]
mIat.setParameter(SpeechConstant.ASR_INTERRUPT_ERROR,"false");
//音频采样率 8000~16000 默认:16000
mIat.setParameter(SpeechConstant.SAMPLE_RATE,"16000");
//默认:麦克风(1)(MediaRecorder.AudioSource.MIC)
//在写音频流方式(-1)下,应用层通过writeAudio函数送入音频;
//在传文件路径方式(-2)下,SDK通过应用层设置的ASR_SOURCE_PATH值, 直接读取音频文件。目前仅在SpeechRecognizer中支持。
mIat.setParameter(SpeechConstant.AUDIO_SOURCE, "-1");
//保存音频文件的路径 仅支持pcm和wav
mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, Environment.getExternalStorageDirectory().getAbsolutePath() + "test.wav");
我首先想到当然就是设置音频保存路径了啊,这还不简单
- mIat.setParameter(SpeechConstant.AUDIO_FORMAT, “wav”);
- mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, ”要保存的路径”);
mIat.setParameter(SpeechConstant.AUDIO_FORMAT, "wav"); mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, "要保存的路径");
时间戳这个好办,根据录音开始时记录当前时间startTime,在RecognizerListener的onResult方法获取当前时间currentTime,然后用currentTime-startTime 就是第几秒说的话了(由于云端识别会有延迟,这个秒数其实是不正确的,这里先忽略这个问题)。
结束了?
不是,我们再来看一下科大讯飞的说明文档中:
科大讯飞对语音听写做了限制,端点超时最大也只能设置10秒,超过这个时间识别自动终止,不再对后续的语音部分进行识别。假如我们要长时间录音,不可能让用户每10秒钟就要说一句话,而且还有一个是值得我们注意的:
也就是说,就算我们连续不停的讲话,音频录制最多也就是60秒而已,怎么办?
这时候我就想,我用自己的方法录音,用科大讯飞的去识别,这是个好方法,我立马在百度输入框敲上 ”Android录音“
这里推荐一个大神封装的录音类:http://www.cnblogs.com/Amandaliu/archive/2013/02/04/2891604.html
考虑到科大讯飞只支持wav、pcm文件,我只是把AudioRecordFunc类copy过来,考虑到科大讯飞对音频文件识别的要求:
上传音频的采样率与采样精度:A:采样率16KHZ或者8KHZ,单声道,采样精度16bit的PCM或者WAV格式的音频
我将代码进行了部分修改。- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileNotFoundException;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import android.media.AudioFormat;
- import android.media.AudioRecord;
- public class AudioRecordFunc {
- // 缓冲区字节大小
- private int bufferSizeInBytes = 0;
- //AudioName裸音频数据文件 ,麦克风
- private String AudioName = “”;
- //NewAudioName可播放的音频文件
- private String NewAudioName = “”;
- private AudioRecord audioRecord;
- private boolean isRecord = false;// 设置正在录制的状态
- private static AudioRecordFunc mInstance;
- private AudioRecordFunc() {
- }
- public synchronized static AudioRecordFunc getInstance() {
- if (mInstance == null)
- mInstance = new AudioRecordFunc();
- return mInstance;
- }
- public int startRecordAndFile() {
- //判断是否有外部存储设备sdcard
- if (AudioFileFunc.isSdcardExit()) {
- if (isRecord) {
- return ErrorCode.E_STATE_RECODING;
- } else {
- if (audioRecord == null)
- creatAudioRecord();
- audioRecord.startRecording();
- // 让录制状态为true
- isRecord = true;
- // 开启音频文件写入线程
- new Thread(new AudioRecordThread()).start();
- return ErrorCode.SUCCESS;
- }
- } else {
- return ErrorCode.E_NOSDCARD;
- }
- }
- public void stopRecordAndFile() {
- close();
- }
- public long getRecordFileSize() {
- return AudioFileFunc.getFileSize(NewAudioName);
- }
- private void close() {
- if (audioRecord != null) {
- System.out.println(”stopRecord”);
- isRecord = false;//停止文件写入
- audioRecord.stop();
- audioRecord.release();//释放资源
- audioRecord = null;
- }
- }
- private void creatAudioRecord() {
- // 获取音频文件路径
- AudioName = AudioFileFunc.getRawFilePath();
- NewAudioName = AudioFileFunc.getWavFilePath();
- // 获得缓冲区字节大小
- bufferSizeInBytes = AudioRecord.getMinBufferSize(AudioFileFunc.AUDIO_SAMPLE_RATE,
- AudioFormat.CHANNEL_IN_STEREO, AudioFormat.ENCODING_PCM_16BIT);
- // 创建AudioRecord对象(修改处)
- audioRecord = new AudioRecord(MediaRecorder.AudioSource.MIC, 16000, AudioFormat.CHANNEL_ IN_MONO, AudioFormat.ENCODING_PCM_16BIT, bufferSizeInBytes);
- }
- class AudioRecordThread implements Runnable {
- @Override
- public void run() {
- writeDateTOFile();//往文件中写入裸数据
- copyWaveFile(AudioName, NewAudioName);//给裸数据加上头文件
- }
- }
- /**
- * 这里将数据写入文件,但是并不能播放,因为AudioRecord获得的音频是原始的裸音频
- * 如果需要播放就必须加入一些格式或者编码的头信息。但是这样的好处就是你可以对音频的 裸数据进行处理
- * 比如你要做一个爱说话的TOM猫在这里就进行音频的处理,然后重新封装 所以说这样得到的音频比较容易做一些音频的处理。
- */
- private void writeDateTOFile() {
- // new一个byte数组用来存一些字节数据,大小为缓冲区大小
- byte[] audiodata = new byte[bufferSizeInBytes];
- FileOutputStream fos = null;
- int readsize = 0;
- try {
- File file = new File(AudioName);
- if (file.exists()) {
- file.delete();
- }
- fos = new FileOutputStream(file);
- // 建立一个可存取字节的文件
- } catch (Exception e) {
- e.printStackTrace();
- }
- while (isRecord == true) {
- readsize = audioRecord.read(audiodata, 0, bufferSizeInBytes);
- if (AudioRecord.ERROR_INVALID_OPERATION != readsize && fos != null) {
- try {
- fos.write(audiodata);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
- try {
- if (fos != null)
- fos.close();// 关闭写入流
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- // 这里得到可播放的音频文件
- private void copyWaveFile(String inFilename, String outFilename) {
- FileInputStream in = null;
- FileOutputStream out = null;
- long totalAudioLen = 0;
- long totalDataLen = totalAudioLen + 36;
- long longSampleRate = AudioFileFunc.AUDIO_SAMPLE_RATE;
- int channels = 2;
- long byteRate = 16 * AudioFileFunc.AUDIO_SAMPLE_RATE * channels / 8;
- byte[] data = new byte[bufferSizeInBytes];
- try {
- in = new FileInputStream(inFilename);
- out = new FileOutputStream(outFilename);
- totalAudioLen = in.getChannel().size();
- totalDataLen = totalAudioLen + 36;
- WriteWaveFileHeader(out, totalAudioLen, totalDataLen, longSampleRate, channels, byteRate);
- while (in.read(data) != -1) {
- out.write(data);
- }
- in.close();
- out.close();
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- /**
- * 这里提供一个头信息。插入这些信息就可以得到可以播放的文件。
- * 为我为啥插入这44个字节,这个还真没深入研究,不过你随便打开一个wav
- * 音频的文件,可以发现前面的头文件可以说基本一样哦。每种格式的文件都有自己特有的头文件。
- */
- private void WriteWaveFileHeader(FileOutputStream out, long totalAudioLen, long totalDataLen, long longSampleRate, int channels, long byteRate) throws IOException {
- byte[] header = new byte[44];
- header[0] = ‘R’; // RIFF/WAVE header
- header[1] = ‘I’;
- header[2] = ‘F’;
- header[3] = ‘F’;
- header[4] = (byte) (totalDataLen & 0xff);
- header[5] = (byte) ((totalDataLen >> 8) & 0xff);
- header[6] = (byte) ((totalDataLen >> 16) & 0xff);
- header[7] = (byte) ((totalDataLen >> 24) & 0xff);
- header[8] = ‘W’;
- header[9] = ‘A’;
- header[10] = ‘V’;
- header[11] = ‘E’;
- header[12] = ‘f’; // ‘fmt ’ chunk
- header[13] = ‘m’;
- header[14] = ‘t’;
- header[15] = ‘ ’;
- header[16] = 16; // 4 bytes: size of ‘fmt ’ chunk
- header[17] = 0;
- header[18] = 0;
- header[19] = 0;
- header[20] = 1; // format = 1
- header[21] = 0;
- header[22] = (byte) channels;
- header[23] = 0;
- header[24] = (byte) (longSampleRate & 0xff);
- header[25] = (byte) ((longSampleRate >> 8) & 0xff);
- header[26] = (byte) ((longSampleRate >> 16) & 0xff);
- header[27] = (byte) ((longSampleRate >> 24) & 0xff);
- header[28] = (byte) (byteRate & 0xff);
- header[29] = (byte) ((byteRate >> 8) & 0xff);
- header[30] = (byte) ((byteRate >> 16) & 0xff);
- header[31] = (byte) ((byteRate >> 24) & 0xff);
- header[32] = (byte) (2 * 16 / 8); // block align
- header[33] = 0;
- header[34] = 16; // bits per sample
- header[35] = 0;
- header[36] = ‘d’;
- header[37] = ‘a’;
- header[38] = ‘t’;
- header[39] = ‘a’;
- header[40] = (byte) (totalAudioLen & 0xff);
- header[41] = (byte) ((totalAudioLen >> 8) & 0xff);
- header[42] = (byte) ((totalAudioLen >> 16) & 0xff);
- header[43] = (byte) ((totalAudioLen >> 24) & 0xff);
- out.write(header, 0, 44);
- }
- }
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import android.media.AudioFormat;
import android.media.AudioRecord;
public class AudioRecordFunc {
// 缓冲区字节大小
private int bufferSizeInBytes = 0;
//AudioName裸音频数据文件 ,麦克风
private String AudioName = "";
//NewAudioName可播放的音频文件
private String NewAudioName = "";
private AudioRecord audioRecord;
private boolean isRecord = false;// 设置正在录制的状态
private static AudioRecordFunc mInstance;
private AudioRecordFunc() {
}
public synchronized static AudioRecordFunc getInstance() {
if (mInstance == null)
mInstance = new AudioRecordFunc();
return mInstance;
}
public int startRecordAndFile() {
//判断是否有外部存储设备sdcard
if (AudioFileFunc.isSdcardExit()) {
if (isRecord) {
return ErrorCode.E_STATE_RECODING;
} else {
if (audioRecord == null)
creatAudioRecord();
audioRecord.startRecording();
// 让录制状态为true
isRecord = true;
// 开启音频文件写入线程
new Thread(new AudioRecordThread()).start();
return ErrorCode.SUCCESS;
}
} else {
return ErrorCode.E_NOSDCARD;
}
}
public void stopRecordAndFile() {
close();
}
public long getRecordFileSize() {
return AudioFileFunc.getFileSize(NewAudioName);
}
private void close() {
if (audioRecord != null) {
System.out.println("stopRecord");
isRecord = false;//停止文件写入
audioRecord.stop();
audioRecord.release();//释放资源
audioRecord = null;
}
}
private void creatAudioRecord() {
// 获取音频文件路径
AudioName = AudioFileFunc.getRawFilePath();
NewAudioName = AudioFileFunc.getWavFilePath();
// 获得缓冲区字节大小
bufferSizeInBytes = AudioRecord.getMinBufferSize(AudioFileFunc.AUDIO_SAMPLE_RATE,
AudioFormat.CHANNEL_IN_STEREO, AudioFormat.ENCODING_PCM_16BIT);
// 创建AudioRecord对象(修改处)
audioRecord = new AudioRecord(MediaRecorder.AudioSource.MIC, 16000, AudioFormat.CHANNEL_ IN_MONO, AudioFormat.ENCODING_PCM_16BIT, bufferSizeInBytes);
}
class AudioRecordThread implements Runnable {
@Override
public void run() {
writeDateTOFile();//往文件中写入裸数据
copyWaveFile(AudioName, NewAudioName);//给裸数据加上头文件
}
}
/**
* 这里将数据写入文件,但是并不能播放,因为AudioRecord获得的音频是原始的裸音频
* 如果需要播放就必须加入一些格式或者编码的头信息。但是这样的好处就是你可以对音频的 裸数据进行处理
* 比如你要做一个爱说话的TOM猫在这里就进行音频的处理,然后重新封装 所以说这样得到的音频比较容易做一些音频的处理。
*/
private void writeDateTOFile() {
// new一个byte数组用来存一些字节数据,大小为缓冲区大小
byte[] audiodata = new byte[bufferSizeInBytes];
FileOutputStream fos = null;
int readsize = 0;
try {
File file = new File(AudioName);
if (file.exists()) {
file.delete();
}
fos = new FileOutputStream(file);
// 建立一个可存取字节的文件
} catch (Exception e) {
e.printStackTrace();
}
while (isRecord == true) {
readsize = audioRecord.read(audiodata, 0, bufferSizeInBytes);
if (AudioRecord.ERROR_INVALID_OPERATION != readsize && fos != null) {
try {
fos.write(audiodata);
} catch (IOException e) {
e.printStackTrace();
}
}
}
try {
if (fos != null)
fos.close();// 关闭写入流
} catch (IOException e) {
e.printStackTrace();
}
}
// 这里得到可播放的音频文件
private void copyWaveFile(String inFilename, String outFilename) {
FileInputStream in = null;
FileOutputStream out = null;
long totalAudioLen = 0;
long totalDataLen = totalAudioLen + 36;
long longSampleRate = AudioFileFunc.AUDIO_SAMPLE_RATE;
int channels = 2;
long byteRate = 16 * AudioFileFunc.AUDIO_SAMPLE_RATE * channels / 8;
byte[] data = new byte[bufferSizeInBytes];
try {
in = new FileInputStream(inFilename);
out = new FileOutputStream(outFilename);
totalAudioLen = in.getChannel().size();
totalDataLen = totalAudioLen + 36;
WriteWaveFileHeader(out, totalAudioLen, totalDataLen, longSampleRate, channels, byteRate);
while (in.read(data) != -1) {
out.write(data);
}
in.close();
out.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 这里提供一个头信息。插入这些信息就可以得到可以播放的文件。
* 为我为啥插入这44个字节,这个还真没深入研究,不过你随便打开一个wav
* 音频的文件,可以发现前面的头文件可以说基本一样哦。每种格式的文件都有自己特有的头文件。
*/
private void WriteWaveFileHeader(FileOutputStream out, long totalAudioLen, long totalDataLen, long longSampleRate, int channels, long byteRate) throws IOException {
byte[] header = new byte[44];
header[0] = 'R'; // RIFF/WAVE header
header[1] = 'I';
header[2] = 'F';
header[3] = 'F';
header[4] = (byte) (totalDataLen & 0xff);
header[5] = (byte) ((totalDataLen >> 8) & 0xff);
header[6] = (byte) ((totalDataLen >> 16) & 0xff);
header[7] = (byte) ((totalDataLen >> 24) & 0xff);
header[8] = 'W';
header[9] = 'A';
header[10] = 'V';
header[11] = 'E';
header[12] = 'f'; // 'fmt ' chunk
header[13] = 'm';
header[14] = 't';
header[15] = ' ';
header[16] = 16; // 4 bytes: size of 'fmt ' chunk
header[17] = 0;
header[18] = 0;
header[19] = 0;
header[20] = 1; // format = 1
header[21] = 0;
header[22] = (byte) channels;
header[23] = 0;
header[24] = (byte) (longSampleRate & 0xff);
header[25] = (byte) ((longSampleRate >> 8) & 0xff);
header[26] = (byte) ((longSampleRate >> 16) & 0xff);
header[27] = (byte) ((longSampleRate >> 24) & 0xff);
header[28] = (byte) (byteRate & 0xff);
header[29] = (byte) ((byteRate >> 8) & 0xff);
header[30] = (byte) ((byteRate >> 16) & 0xff);
header[31] = (byte) ((byteRate >> 24) & 0xff);
header[32] = (byte) (2 * 16 / 8); // block align
header[33] = 0;
header[34] = 16; // bits per sample
header[35] = 0;
header[36] = 'd';
header[37] = 'a';
header[38] = 't';
header[39] = 'a';
header[40] = (byte) (totalAudioLen & 0xff);
header[41] = (byte) ((totalAudioLen >> 8) & 0xff);
header[42] = (byte) ((totalAudioLen >> 16) & 0xff);
header[43] = (byte) ((totalAudioLen >> 24) & 0xff);
out.write(header, 0, 44);
}
}
然后在录音按钮里的点击事件里写了这么两行行代码:
- //开始进行语音听写
- mIat.startListening(mRecoListener);
- //开始录音并且保存录音到sd卡
- audioRecordFunc.startRecordAndFile();
//开始进行语音听写
mIat.startListening(mRecoListener);
//开始录音并且保存录音到sd卡
audioRecordFunc.startRecordAndFile();这里会发生一个很奇怪的现象,能听写的时候不能录音,能录音的时候不能听写,录音的两个类MediaRecorder、AudioRecord中
MediaRecorder的start()方法中有这么一句话:
The apps should not start another recording session during recording.
(一个app不应该在录音期间开启另外一个录音),原因我大致理解为麦克风被占用了
既然不能一边录音一边识别,那我们只好录完音后再上传去识别,嗯,回头看了一下设置的参数
- mIat.setParameter(SpeechConstant.AUDIO_SOURCE, “-2”);
- mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, ”要识别的音频绝对路径“);
mIat.setParameter(SpeechConstant.AUDIO_SOURCE, "-2");
mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, ”要识别的音频绝对路径“);
设置好参数之后
- mIat.startListening(mRecoListener);
mIat.startListening(mRecoListener);这下可以了,保存的音频文件可以识别,而且识别的速度和讲话的时候是一样的,也就是说,你在第5秒说的话,就是在第五秒开始识别(不考虑网络延迟的时候),这样,就可以实现了我们的需求。
然而,事情往往没有那么简单,还是回到了原始的问题,也就是前后端点超时或者一分钟过后的音频不再识别!!!
有两个解决方法:
1、自己重新写一个类继承科大讯飞里面的类,重写里面的方法
2、通过流的方式去控制,假如文件流读取没完成,音频不再识别,那就重新激活,直到文件流读取完毕
两秒钟之后我立马放弃了第一种解决方案,源码是长这样子的:那就只能采用第二种方案了,此时我们要进行相应的参数设置:
- mIat.setParameter(SpeechConstant.AUDIO_SOURCE, “-1”);
- //开始进行语音听写
- mIat.startListening(mRecoListener);
- //然后在进行音频流输入
- mIat.writeAudio(bytes, 0, bytes.length);
mIat.setParameter(SpeechConstant.AUDIO_SOURCE, "-1"); //开始进行语音听写 mIat.startListening(mRecoListener); //然后在进行音频流输入 mIat.writeAudio(bytes, 0, bytes.length);
录完音后,根据音频文件读取流。代码我就不粘贴出来了,因为这个方法行不通,原因是因为流读取的速度太快,几分钟的文件一下子就读取完了,端点超时问题还是会出现(ps:希望有个人告诉流能否控制其读取速度,怎么控制),而且就算能控制速度,假如用户录音一个小时的,你不可能又要花一个小时去识别音频吧,这不现实!!
未完待续...
</div>
最近想要做一款语音听写APP,在网上搜索关于如何使用科大讯飞语音的Demo少之又少,又或者是只是单纯的按照文档来实现简单的语音听写,远远不能满足需求,看了几天的文档和自己搜索的一些资料,还有这几天中遇到的一些问题,觉得有必要做一个笔记,能给初学者一些帮助,也顺便理一下这些天的一些收获,本人只是一个初学者,假如有写得不对或者不好的地方,还望大家指出~~
1、首先当然是创建应用,我这里只是使用了语音听写的功能,创建完成后下载SDK,打开是这样子的:
2、导入SDK:
将开发工具包中libs目录下的Msc.jar和Sunflower.jar复制到Android工程的libs目录中,将online文件夹里面的子文件粘贴到工程目录src/main/jniLibs(这是Android studio 和eclipse的不同之处)。假如你要使用它自带的UI动画对话框录音,请将assets文件夹以及里面的子文件粘贴到工程目录src/main/下面,完成后如下图:
3、添加权限:
- <!–连接网络权限,用于执行云端语音能力 –>
- <uses-permission android:name=”android.permission.INTERNET”></uses-permission>
- <!–获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 –>
- <uses-permission android:name=”android.permission.RECORD_AUDIO”></uses-permission>
- <!–读取网络信息状态 –>
- <uses-permission android:name=”android.permission.ACCESS_NETWORK_STATE”></uses-permission>
- <!–获取当前wifi状态 –>
- <uses-permission android:name=”android.permission.ACCESS_WIFI_STATE”></uses-permission>
- <!–允许程序改变网络连接状态 –>
- <uses-permission android:name=”android.permission.CHANGE_NETWORK_STATE”></uses-permission>
- <!–读取手机信息权限 –>
- <uses-permission android:name=”android.permission.READ_PHONE_STATE”></uses-permission>
- <!–读取联系人权限,上传联系人需要用到此权限 –>
- <uses-permission android:name=”android.permission.READ_CONTACTS”></uses-permission>
- <!–假如我们要保存录音,还需要以下权限–>
- <!– 在SDCard中创建与删除文件权限 –>
- <uses-permission android:name=”android.permission.MOUNT_UNMOUNT_FILESYSTEMS”></uses-permission>
- <!– SD卡权限 –>
- <uses-permission android:name=”android.permission.WRITE_EXTERNAL_STORAGE”></uses-permission>
- <!– 允许程序读取或写入系统设置 –>
- <uses-permission android:name=”android.permission.WRITE_SETTINGS”></uses-permission>
<!--连接网络权限,用于执行云端语音能力 --> <uses-permission android:name="android.permission.INTERNET"></uses-permission> <!--获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 --> <uses-permission android:name="android.permission.RECORD_AUDIO"></uses-permission> <!--读取网络信息状态 --> <uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"></uses-permission> <!--获取当前wifi状态 --> <uses-permission android:name="android.permission.ACCESS_WIFI_STATE"></uses-permission> <!--允许程序改变网络连接状态 --> <uses-permission android:name="android.permission.CHANGE_NETWORK_STATE"></uses-permission> <!--读取手机信息权限 --> <uses-permission android:name="android.permission.READ_PHONE_STATE"></uses-permission> <!--读取联系人权限,上传联系人需要用到此权限 --> <uses-permission android:name="android.permission.READ_CONTACTS"></uses-permission> <!--假如我们要保存录音,还需要以下权限--> <!-- 在SDCard中创建与删除文件权限 --> <uses-permission android:name="android.permission.MOUNT_UNMOUNT_FILESYSTEMS"></uses-permission> <!-- SD卡权限 --> <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"></uses-permission> <!-- 允许程序读取或写入系统设置 --> <uses-permission android:name="android.permission.WRITE_SETTINGS"></uses-permission>
4、初始化:
//将“12345678”替换成您申请的APPID,申请地址:http://open.voicecloud.cn
SpeechUtility.createUtility(this, "appid=123456789");
数据收集接口:
- @Override
- protected void onResume() {
- // 开放统计 移动数据统计分析
- FlowerCollector.onResume(MainActivity.this);
- super.onResume();
- }
- @Override
- protected void onPause() {
- // 开放统计 移动数据统计分析
- FlowerCollector.onPause(MainActivity.this);
- super.onPause();
- }
@Override
protected void onResume() {
// 开放统计 移动数据统计分析
FlowerCollector.onResume(MainActivity.this);
super.onResume();
}
@Override
protected void onPause() {
// 开放统计 移动数据统计分析
FlowerCollector.onPause(MainActivity.this);
super.onPause();
}
说明:
1.确保在所有的 activity 中都调用 FlowerCollector.onResume() 和 FlowerCollector.onPause()方法。这两个调用将不会阻塞应用程序的主线程,也不会影响应用程序的性能。
2.注意,如果您的 Activity 之间有继承或者控制关系请不要同时在父和子 Activity 中重复添加onPause 和 onResume 方法,否则会造成重复统计(eg:使用 TabHost、TabActivity、ActivityGroup 时)。3.一个应用程序在多个 activity 之间连续切换时,会被视为同一个 session(启动)。4.当用户两次使用之间间隔超过 30 秒时,将被认为是两个的独立的 session(启动)。例如:用户回到home,或进入其他程序,经过一段时间后再返回之前的应用。
5.所有日志收集工作均在 onResume 之后进行,在 onPause 之后结束。 (ps:其实我也不懂这是干嘛的,猜想是为了收集数据的,还有一些参数设置我就不罗列了,有兴趣的同学可以去看,因为我发现就算没设置它们我也能进行语音听写,反正收集的数据我看不懂)
5、语音听写的使用(采取云端听写的引擎模式,暂时未考虑本地集成)
注意导包:com.iflytek.cloud而不是android.speech.SpeechRecognizer
1)使用自带UI语音对话框
优点:简单方便、美观
缺点:端点超时会自动停止识别(不理解的往下看设置参数说明)默认前段点:5000 后端点:1800
这是使用语音识别最简单的方法,在点击事件上调用start()方法就好了
- public void start() {
- //1.创建SpeechRecognizer对象,第二个参数:本地听写时传InitListener
- iatDialog = new RecognizerDialog(this, initListener);
- //2.设置听写参数
- iatDialog.setParameter(SpeechConstant.DOMAIN, “iat”);
- iatDialog.setParameter(SpeechConstant.LANGUAGE, “zh_cn”);
- iatDialog.setParameter(SpeechConstant.ACCENT, “mandarin ”);
- //3.设置回调接口
- iatDialog.setListener(new RecognizerDialogListener() {
- @Override
- public void onResult(RecognizerResult recognizerResult, boolean b) {
- if (!b) {
- String json = recognizerResult.getResultString();
- String str = JsonParser.parseIatResult(json);
- System.out.println(“说话内容:”+str);
- textView.setText(str);
- }
- }
- @Override
- public void onError(SpeechError speechError) {
- Log.d(“error”, speechError.toString());
- }
- });
- //4.开始听写
- iatDialog.show();
- }
public void start() {
//1.创建SpeechRecognizer对象,第二个参数:本地听写时传InitListener
iatDialog = new RecognizerDialog(this, initListener);
//2.设置听写参数
iatDialog.setParameter(SpeechConstant.DOMAIN, "iat");
iatDialog.setParameter(SpeechConstant.LANGUAGE, "zh_cn");
iatDialog.setParameter(SpeechConstant.ACCENT, "mandarin ");
//3.设置回调接口
iatDialog.setListener(new RecognizerDialogListener() {
@Override
public void onResult(RecognizerResult recognizerResult, boolean b) {
if (!b) {
String json = recognizerResult.getResultString();
String str = JsonParser.parseIatResult(json);
System.out.println("说话内容:"+str);
textView.setText(str);
}
}
@Override
public void onError(SpeechError speechError) {
Log.d("error", speechError.toString());
}
});
//4.开始听写
iatDialog.show();
}
增加if(!b)的判断是因为每次说话结束之后,返回数据的最后一次是返回一个标点符号”。”或者”!”之类的,当然你也可以设置不返回标点符号。
- //设置是否带标点符号 0表示不带标点,1则表示带标点。
- mIat.setParameter(SpeechConstant.ASR_PTT, ”0”);
//设置是否带标点符号 0表示不带标点,1则表示带标点。 mIat.setParameter(SpeechConstant.ASR_PTT, "0");
2)不使用自带UI对话框
优点:可以设置自己想要的参数
缺点:使用比较麻烦,对于初学者来讲,根据讲话音量大小自定义麦克风效果的View简直是噩梦(我不会,哪位大神做出来了求分享~~)
简单的用法:
1.创建对象:
- <span style=“font-size:18px;”>//1.创建SpeechRecognizer对象,第二个参数:本地听写时传InitListener
- mIat = SpeechRecognizer.createRecognizer(this, null);</span>
<span style="font-size:18px;">//1.创建SpeechRecognizer对象,第二个参数:本地听写时传InitListener mIat = SpeechRecognizer.createRecognizer(this, null);</span>
2.设置参数(听写这三个参数是必须的,下面设置时不再提示):
- mIat.setParameter(SpeechConstant.DOMAIN, “iat”);
- // 简体中文:”zh_cn”, 美式英文:”en_us”
- mIat.setParameter(SpeechConstant.LANGUAGE, ”zh_cn”);
- //普通话:mandarin(默认)
- //粤 语:cantonese
- //四川话:lmz
- //河南话:henanese
- mIat.setParameter(SpeechConstant.ACCENT, ”mandarin ”);
mIat.setParameter(SpeechConstant.DOMAIN, "iat"); // 简体中文:"zh_cn", 美式英文:"en_us" mIat.setParameter(SpeechConstant.LANGUAGE, "zh_cn"); //普通话:mandarin(默认) //粤 语:cantonese //四川话:lmz //河南话:henanese mIat.setParameter(SpeechConstant.ACCENT, "mandarin ");3.实例化监听对象
- private RecognizerListener recognizerListener = new RecognizerListener() {
- @Override
- public void onVolumeChanged(int i, byte[] bytes) {
- }
- @Override
- public void onBeginOfSpeech() {
- System.out.println(”开始识别”);
- }
- @Override
- public void onEndOfSpeech() {
- System.out.println(”识别结束”);
- }
- @Override
- public void onResult(RecognizerResult recognizerResult, boolean b) {
- String str=JsonParser.parseIatResult(recognizerResult.getResultString());
- System.out.println(”识别结果”+str);
- }
- @Override
- public void onError(SpeechError speechError) {
- System.out.println(”识别出错”);
- }
- @Override
- public void onEvent(int i, int i1, int i2, Bundle bundle) {
- }
- };
private RecognizerListener recognizerListener = new RecognizerListener() {
@Override
public void onVolumeChanged(int i, byte[] bytes) {
}
@Override
public void onBeginOfSpeech() {
System.out.println("开始识别");
}
@Override
public void onEndOfSpeech() {
System.out.println("识别结束");
}
@Override
public void onResult(RecognizerResult recognizerResult, boolean b) {
String str=JsonParser.parseIatResult(recognizerResult.getResultString());
System.out.println("识别结果"+str);
}
@Override
public void onError(SpeechError speechError) {
System.out.println("识别出错");
}
@Override
public void onEvent(int i, int i1, int i2, Bundle bundle) {
}
};
4.添加监听
- mIat.startListening(recognizerListener);
mIat.startListening(recognizerListener);
官方Demo给出的解析Json的类:
- package com.hxl.voicetest1;
- import org.json.JSONArray;
- import org.json.JSONObject;
- import org.json.JSONTokener;
- /**
- * Json结果解析类
- */
- public class JsonParser {
- public static String parseIatResult(String json) {
- StringBuffer ret = new StringBuffer();
- try {
- JSONTokener tokener = new JSONTokener(json);
- JSONObject joResult = new JSONObject(tokener);
- JSONArray words = joResult.getJSONArray(”ws”);
- for (int i = 0; i < words.length(); i++) {
- // 转写结果词,默认使用第一个结果
- JSONArray items = words.getJSONObject(i).getJSONArray(”cw”);
- JSONObject obj = items.getJSONObject(0);
- ret.append(obj.getString(”w”));
- //如果需要多候选结果,解析数组其他字段
- //for(int j = 0; j < items.length(); j++)
- //{
- //JSONObject obj = items.getJSONObject(j);
- //ret.append(obj.getString(“w”));
- //}
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- return ret.toString();
- }
- public static String parseGrammarResult(String json) {
- StringBuffer ret = new StringBuffer();
- try {
- JSONTokener tokener = new JSONTokener(json);
- JSONObject joResult = new JSONObject(tokener);
- JSONArray words = joResult.getJSONArray(”ws”);
- for (int i = 0; i < words.length(); i++) {
- JSONArray items = words.getJSONObject(i).getJSONArray(”cw”);
- for (int j = 0; j < items.length(); j++) {
- JSONObject obj = items.getJSONObject(j);
- if (obj.getString(“w”).contains(“nomatch”)) {
- ret.append(”没有匹配结果.”);
- return ret.toString();
- }
- ret.append(”【结果】” + obj.getString(“w”));
- ret.append(”【置信度】” + obj.getInt(“sc”));
- ret.append(”n”);
- }
- }
- } catch (Exception e) {
- e.printStackTrace();
- ret.append(”没有匹配结果.”);
- }
- return ret.toString();
- }
- }
package com.hxl.voicetest1;
import org.json.JSONArray;
import org.json.JSONObject;
import org.json.JSONTokener;
/**
* Json结果解析类
*/
public class JsonParser {
public static String parseIatResult(String json) {
StringBuffer ret = new StringBuffer();
try {
JSONTokener tokener = new JSONTokener(json);
JSONObject joResult = new JSONObject(tokener);
JSONArray words = joResult.getJSONArray("ws");
for (int i = 0; i < words.length(); i++) {
// 转写结果词,默认使用第一个结果
JSONArray items = words.getJSONObject(i).getJSONArray("cw");
JSONObject obj = items.getJSONObject(0);
ret.append(obj.getString("w"));
//如果需要多候选结果,解析数组其他字段
//for(int j = 0; j < items.length(); j++)
//{
//JSONObject obj = items.getJSONObject(j);
//ret.append(obj.getString("w"));
//}
}
} catch (Exception e) {
e.printStackTrace();
}
return ret.toString();
}
public static String parseGrammarResult(String json) {
StringBuffer ret = new StringBuffer();
try {
JSONTokener tokener = new JSONTokener(json);
JSONObject joResult = new JSONObject(tokener);
JSONArray words = joResult.getJSONArray("ws");
for (int i = 0; i < words.length(); i++) {
JSONArray items = words.getJSONObject(i).getJSONArray("cw");
for (int j = 0; j < items.length(); j++) {
JSONObject obj = items.getJSONObject(j);
if (obj.getString("w").contains("nomatch")) {
ret.append("没有匹配结果.");
return ret.toString();
}
ret.append("【结果】" + obj.getString("w"));
ret.append("【置信度】" + obj.getInt("sc"));
ret.append("n");
}
}
} catch (Exception e) {
e.printStackTrace();
ret.append("没有匹配结果.");
}
return ret.toString();
}
}
到这里,科大讯飞语音最简单的听写Demo就算完成了。这时你们会想:WTF?就这些我还不如自个儿看文档…..
当然了,既然写这篇博客,肯定不仅仅是简单介绍科大讯飞语音听写的使用而已。
我想要的效果是:无限制时间录音,并且我想知道我在第几秒说了什么话,回放录音的时候,播放到哪就显示相应的文字,还可以对识别错误的字段进行纠错修改。
我们来看一下一些常用的设置参数(个人认为),我们可以根据我们的需求来设置相应的参数
- // 清空参数
- mIat.setParameter(SpeechConstant.PARAMS, null);
- //短信和日常用语:iat (默认) 视频:video 地图:poi 音乐:music
- mIat.setParameter(SpeechConstant.DOMAIN, ”iat”);
- // 简体中文:”zh_cn”, 美式英文:”en_us”
- mIat.setParameter(SpeechConstant.LANGUAGE, ”zh_cn”);
- //普通话:mandarin(默认)
- //粤 语:cantonese
- //四川话:lmz
- //河南话:henanese<span style=”font-family: Menlo;”> </span>
- mIat.setParameter(SpeechConstant.ACCENT, ”mandarin ”);
- // 设置听写引擎 “cloud”, “local”,”mixed” 在线 本地 混合
- //本地的需要本地功能集成
- mIat.setParameter(SpeechConstant.ENGINE_TYPE, ”cloud”);
- // 设置返回结果格式 听写会话支持json和plain
- mIat.setParameter(SpeechConstant.RESULT_TYPE, ”json”);
- //设置是否带标点符号 0表示不带标点,1则表示带标点。
- mIat.setParameter(SpeechConstant.ASR_PTT, ”0”);
- //只有设置这个属性为1时,VAD_BOS VAD_EOS才会生效,且RecognizerListener.onVolumeChanged才有音量返回默认:1
- mIat.setParameter(SpeechConstant.VAD_ENABLE,”1”);
- // 设置语音前端点:静音超时时间,即用户多长时间不说话则当做超时处理1000~10000
- mIat.setParameter(SpeechConstant.VAD_BOS, ”5000”);
- // 设置语音后端点:后端点静音检测时间,即用户停止说话多长时间内即认为不再输入, 自动停止录音0~10000
- mIat.setParameter(SpeechConstant.VAD_EOS, ”1800”);
- // 设置音频保存路径,保存音频格式支持pcm、wav,设置路径为sd卡请注意WRITE_EXTERNAL_STORAGE权限
- // 注:AUDIO_FORMAT参数语记需要更新版本才能生效
- mIat.setParameter(SpeechConstant.AUDIO_FORMAT, ”wav”);
- //设置识别会话被中断时(如当前会话未结束就开启了新会话等),
- //是否通 过RecognizerListener.onError(com.iflytek.cloud.SpeechError)回调ErrorCode.ERROR_INTERRUPT错误。
- //默认false [null,true,false]
- mIat.setParameter(SpeechConstant.ASR_INTERRUPT_ERROR,”false”);
- //音频采样率 8000~16000 默认:16000
- mIat.setParameter(SpeechConstant.SAMPLE_RATE,”16000”);
- //默认:麦克风(1)(MediaRecorder.AudioSource.MIC)
- //在写音频流方式(-1)下,应用层通过writeAudio函数送入音频;
- //在传文件路径方式(-2)下,SDK通过应用层设置的ASR_SOURCE_PATH值, 直接读取音频文件。目前仅在SpeechRecognizer中支持。
- mIat.setParameter(SpeechConstant.AUDIO_SOURCE, ”-1”);
- //保存音频文件的路径 仅支持pcm和wav
- mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, Environment.getExternalStorageDirectory().getAbsolutePath() + ”test.wav”);
// 清空参数
mIat.setParameter(SpeechConstant.PARAMS, null);
//短信和日常用语:iat (默认) 视频:video 地图:poi 音乐:music
mIat.setParameter(SpeechConstant.DOMAIN, "iat");
// 简体中文:"zh_cn", 美式英文:"en_us"
mIat.setParameter(SpeechConstant.LANGUAGE, "zh_cn");
//普通话:mandarin(默认)
//粤 语:cantonese
//四川话:lmz
//河南话:henanese<span style="font-family: Menlo;"> </span>
mIat.setParameter(SpeechConstant.ACCENT, "mandarin ");
// 设置听写引擎 "cloud", "local","mixed" 在线 本地 混合
//本地的需要本地功能集成
mIat.setParameter(SpeechConstant.ENGINE_TYPE, "cloud");
// 设置返回结果格式 听写会话支持json和plain
mIat.setParameter(SpeechConstant.RESULT_TYPE, "json");
//设置是否带标点符号 0表示不带标点,1则表示带标点。
mIat.setParameter(SpeechConstant.ASR_PTT, "0");
//只有设置这个属性为1时,VAD_BOS VAD_EOS才会生效,且RecognizerListener.onVolumeChanged才有音量返回默认:1
mIat.setParameter(SpeechConstant.VAD_ENABLE,"1");
// 设置语音前端点:静音超时时间,即用户多长时间不说话则当做超时处理1000~10000
mIat.setParameter(SpeechConstant.VAD_BOS, "5000");
// 设置语音后端点:后端点静音检测时间,即用户停止说话多长时间内即认为不再输入, 自动停止录音0~10000
mIat.setParameter(SpeechConstant.VAD_EOS, "1800");
// 设置音频保存路径,保存音频格式支持pcm、wav,设置路径为sd卡请注意WRITE_EXTERNAL_STORAGE权限
// 注:AUDIO_FORMAT参数语记需要更新版本才能生效
mIat.setParameter(SpeechConstant.AUDIO_FORMAT, "wav");
//设置识别会话被中断时(如当前会话未结束就开启了新会话等),
//是否通 过RecognizerListener.onError(com.iflytek.cloud.SpeechError)回调ErrorCode.ERROR_INTERRUPT错误。
//默认false [null,true,false]
mIat.setParameter(SpeechConstant.ASR_INTERRUPT_ERROR,"false");
//音频采样率 8000~16000 默认:16000
mIat.setParameter(SpeechConstant.SAMPLE_RATE,"16000");
//默认:麦克风(1)(MediaRecorder.AudioSource.MIC)
//在写音频流方式(-1)下,应用层通过writeAudio函数送入音频;
//在传文件路径方式(-2)下,SDK通过应用层设置的ASR_SOURCE_PATH值, 直接读取音频文件。目前仅在SpeechRecognizer中支持。
mIat.setParameter(SpeechConstant.AUDIO_SOURCE, "-1");
//保存音频文件的路径 仅支持pcm和wav
mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, Environment.getExternalStorageDirectory().getAbsolutePath() + "test.wav");
我首先想到当然就是设置音频保存路径了啊,这还不简单
- mIat.setParameter(SpeechConstant.AUDIO_FORMAT, “wav”);
- mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, ”要保存的路径”);
mIat.setParameter(SpeechConstant.AUDIO_FORMAT, "wav"); mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, "要保存的路径");
时间戳这个好办,根据录音开始时记录当前时间startTime,在RecognizerListener的onResult方法获取当前时间currentTime,然后用currentTime-startTime 就是第几秒说的话了(由于云端识别会有延迟,这个秒数其实是不正确的,这里先忽略这个问题)。
结束了?
不是,我们再来看一下科大讯飞的说明文档中:
科大讯飞对语音听写做了限制,端点超时最大也只能设置10秒,超过这个时间识别自动终止,不再对后续的语音部分进行识别。假如我们要长时间录音,不可能让用户每10秒钟就要说一句话,而且还有一个是值得我们注意的:
也就是说,就算我们连续不停的讲话,音频录制最多也就是60秒而已,怎么办?
这时候我就想,我用自己的方法录音,用科大讯飞的去识别,这是个好方法,我立马在百度输入框敲上 ”Android录音“
这里推荐一个大神封装的录音类:http://www.cnblogs.com/Amandaliu/archive/2013/02/04/2891604.html
考虑到科大讯飞只支持wav、pcm文件,我只是把AudioRecordFunc类copy过来,考虑到科大讯飞对音频文件识别的要求:
上传音频的采样率与采样精度:A:采样率16KHZ或者8KHZ,单声道,采样精度16bit的PCM或者WAV格式的音频
我将代码进行了部分修改。- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileNotFoundException;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import android.media.AudioFormat;
- import android.media.AudioRecord;
- public class AudioRecordFunc {
- // 缓冲区字节大小
- private int bufferSizeInBytes = 0;
- //AudioName裸音频数据文件 ,麦克风
- private String AudioName = “”;
- //NewAudioName可播放的音频文件
- private String NewAudioName = “”;
- private AudioRecord audioRecord;
- private boolean isRecord = false;// 设置正在录制的状态
- private static AudioRecordFunc mInstance;
- private AudioRecordFunc() {
- }
- public synchronized static AudioRecordFunc getInstance() {
- if (mInstance == null)
- mInstance = new AudioRecordFunc();
- return mInstance;
- }
- public int startRecordAndFile() {
- //判断是否有外部存储设备sdcard
- if (AudioFileFunc.isSdcardExit()) {
- if (isRecord) {
- return ErrorCode.E_STATE_RECODING;
- } else {
- if (audioRecord == null)
- creatAudioRecord();
- audioRecord.startRecording();
- // 让录制状态为true
- isRecord = true;
- // 开启音频文件写入线程
- new Thread(new AudioRecordThread()).start();
- return ErrorCode.SUCCESS;
- }
- } else {
- return ErrorCode.E_NOSDCARD;
- }
- }
- public void stopRecordAndFile() {
- close();
- }
- public long getRecordFileSize() {
- return AudioFileFunc.getFileSize(NewAudioName);
- }
- private void close() {
- if (audioRecord != null) {
- System.out.println(”stopRecord”);
- isRecord = false;//停止文件写入
- audioRecord.stop();
- audioRecord.release();//释放资源
- audioRecord = null;
- }
- }
- private void creatAudioRecord() {
- // 获取音频文件路径
- AudioName = AudioFileFunc.getRawFilePath();
- NewAudioName = AudioFileFunc.getWavFilePath();
- // 获得缓冲区字节大小
- bufferSizeInBytes = AudioRecord.getMinBufferSize(AudioFileFunc.AUDIO_SAMPLE_RATE,
- AudioFormat.CHANNEL_IN_STEREO, AudioFormat.ENCODING_PCM_16BIT);
- // 创建AudioRecord对象(修改处)
- audioRecord = new AudioRecord(MediaRecorder.AudioSource.MIC, 16000, AudioFormat.CHANNEL_ IN_MONO, AudioFormat.ENCODING_PCM_16BIT, bufferSizeInBytes);
- }
- class AudioRecordThread implements Runnable {
- @Override
- public void run() {
- writeDateTOFile();//往文件中写入裸数据
- copyWaveFile(AudioName, NewAudioName);//给裸数据加上头文件
- }
- }
- /**
- * 这里将数据写入文件,但是并不能播放,因为AudioRecord获得的音频是原始的裸音频
- * 如果需要播放就必须加入一些格式或者编码的头信息。但是这样的好处就是你可以对音频的 裸数据进行处理
- * 比如你要做一个爱说话的TOM猫在这里就进行音频的处理,然后重新封装 所以说这样得到的音频比较容易做一些音频的处理。
- */
- private void writeDateTOFile() {
- // new一个byte数组用来存一些字节数据,大小为缓冲区大小
- byte[] audiodata = new byte[bufferSizeInBytes];
- FileOutputStream fos = null;
- int readsize = 0;
- try {
- File file = new File(AudioName);
- if (file.exists()) {
- file.delete();
- }
- fos = new FileOutputStream(file);
- // 建立一个可存取字节的文件
- } catch (Exception e) {
- e.printStackTrace();
- }
- while (isRecord == true) {
- readsize = audioRecord.read(audiodata, 0, bufferSizeInBytes);
- if (AudioRecord.ERROR_INVALID_OPERATION != readsize && fos != null) {
- try {
- fos.write(audiodata);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
- try {
- if (fos != null)
- fos.close();// 关闭写入流
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- // 这里得到可播放的音频文件
- private void copyWaveFile(String inFilename, String outFilename) {
- FileInputStream in = null;
- FileOutputStream out = null;
- long totalAudioLen = 0;
- long totalDataLen = totalAudioLen + 36;
- long longSampleRate = AudioFileFunc.AUDIO_SAMPLE_RATE;
- int channels = 2;
- long byteRate = 16 * AudioFileFunc.AUDIO_SAMPLE_RATE * channels / 8;
- byte[] data = new byte[bufferSizeInBytes];
- try {
- in = new FileInputStream(inFilename);
- out = new FileOutputStream(outFilename);
- totalAudioLen = in.getChannel().size();
- totalDataLen = totalAudioLen + 36;
- WriteWaveFileHeader(out, totalAudioLen, totalDataLen, longSampleRate, channels, byteRate);
- while (in.read(data) != -1) {
- out.write(data);
- }
- in.close();
- out.close();
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- /**
- * 这里提供一个头信息。插入这些信息就可以得到可以播放的文件。
- * 为我为啥插入这44个字节,这个还真没深入研究,不过你随便打开一个wav
- * 音频的文件,可以发现前面的头文件可以说基本一样哦。每种格式的文件都有自己特有的头文件。
- */
- private void WriteWaveFileHeader(FileOutputStream out, long totalAudioLen, long totalDataLen, long longSampleRate, int channels, long byteRate) throws IOException {
- byte[] header = new byte[44];
- header[0] = ‘R’; // RIFF/WAVE header
- header[1] = ‘I’;
- header[2] = ‘F’;
- header[3] = ‘F’;
- header[4] = (byte) (totalDataLen & 0xff);
- header[5] = (byte) ((totalDataLen >> 8) & 0xff);
- header[6] = (byte) ((totalDataLen >> 16) & 0xff);
- header[7] = (byte) ((totalDataLen >> 24) & 0xff);
- header[8] = ‘W’;
- header[9] = ‘A’;
- header[10] = ‘V’;
- header[11] = ‘E’;
- header[12] = ‘f’; // ‘fmt ’ chunk
- header[13] = ‘m’;
- header[14] = ‘t’;
- header[15] = ‘ ’;
- header[16] = 16; // 4 bytes: size of ‘fmt ’ chunk
- header[17] = 0;
- header[18] = 0;
- header[19] = 0;
- header[20] = 1; // format = 1
- header[21] = 0;
- header[22] = (byte) channels;
- header[23] = 0;
- header[24] = (byte) (longSampleRate & 0xff);
- header[25] = (byte) ((longSampleRate >> 8) & 0xff);
- header[26] = (byte) ((longSampleRate >> 16) & 0xff);
- header[27] = (byte) ((longSampleRate >> 24) & 0xff);
- header[28] = (byte) (byteRate & 0xff);
- header[29] = (byte) ((byteRate >> 8) & 0xff);
- header[30] = (byte) ((byteRate >> 16) & 0xff);
- header[31] = (byte) ((byteRate >> 24) & 0xff);
- header[32] = (byte) (2 * 16 / 8); // block align
- header[33] = 0;
- header[34] = 16; // bits per sample
- header[35] = 0;
- header[36] = ‘d’;
- header[37] = ‘a’;
- header[38] = ‘t’;
- header[39] = ‘a’;
- header[40] = (byte) (totalAudioLen & 0xff);
- header[41] = (byte) ((totalAudioLen >> 8) & 0xff);
- header[42] = (byte) ((totalAudioLen >> 16) & 0xff);
- header[43] = (byte) ((totalAudioLen >> 24) & 0xff);
- out.write(header, 0, 44);
- }
- }
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import android.media.AudioFormat;
import android.media.AudioRecord;
public class AudioRecordFunc {
// 缓冲区字节大小
private int bufferSizeInBytes = 0;
//AudioName裸音频数据文件 ,麦克风
private String AudioName = "";
//NewAudioName可播放的音频文件
private String NewAudioName = "";
private AudioRecord audioRecord;
private boolean isRecord = false;// 设置正在录制的状态
private static AudioRecordFunc mInstance;
private AudioRecordFunc() {
}
public synchronized static AudioRecordFunc getInstance() {
if (mInstance == null)
mInstance = new AudioRecordFunc();
return mInstance;
}
public int startRecordAndFile() {
//判断是否有外部存储设备sdcard
if (AudioFileFunc.isSdcardExit()) {
if (isRecord) {
return ErrorCode.E_STATE_RECODING;
} else {
if (audioRecord == null)
creatAudioRecord();
audioRecord.startRecording();
// 让录制状态为true
isRecord = true;
// 开启音频文件写入线程
new Thread(new AudioRecordThread()).start();
return ErrorCode.SUCCESS;
}
} else {
return ErrorCode.E_NOSDCARD;
}
}
public void stopRecordAndFile() {
close();
}
public long getRecordFileSize() {
return AudioFileFunc.getFileSize(NewAudioName);
}
private void close() {
if (audioRecord != null) {
System.out.println("stopRecord");
isRecord = false;//停止文件写入
audioRecord.stop();
audioRecord.release();//释放资源
audioRecord = null;
}
}
private void creatAudioRecord() {
// 获取音频文件路径
AudioName = AudioFileFunc.getRawFilePath();
NewAudioName = AudioFileFunc.getWavFilePath();
// 获得缓冲区字节大小
bufferSizeInBytes = AudioRecord.getMinBufferSize(AudioFileFunc.AUDIO_SAMPLE_RATE,
AudioFormat.CHANNEL_IN_STEREO, AudioFormat.ENCODING_PCM_16BIT);
// 创建AudioRecord对象(修改处)
audioRecord = new AudioRecord(MediaRecorder.AudioSource.MIC, 16000, AudioFormat.CHANNEL_ IN_MONO, AudioFormat.ENCODING_PCM_16BIT, bufferSizeInBytes);
}
class AudioRecordThread implements Runnable {
@Override
public void run() {
writeDateTOFile();//往文件中写入裸数据
copyWaveFile(AudioName, NewAudioName);//给裸数据加上头文件
}
}
/**
* 这里将数据写入文件,但是并不能播放,因为AudioRecord获得的音频是原始的裸音频
* 如果需要播放就必须加入一些格式或者编码的头信息。但是这样的好处就是你可以对音频的 裸数据进行处理
* 比如你要做一个爱说话的TOM猫在这里就进行音频的处理,然后重新封装 所以说这样得到的音频比较容易做一些音频的处理。
*/
private void writeDateTOFile() {
// new一个byte数组用来存一些字节数据,大小为缓冲区大小
byte[] audiodata = new byte[bufferSizeInBytes];
FileOutputStream fos = null;
int readsize = 0;
try {
File file = new File(AudioName);
if (file.exists()) {
file.delete();
}
fos = new FileOutputStream(file);
// 建立一个可存取字节的文件
} catch (Exception e) {
e.printStackTrace();
}
while (isRecord == true) {
readsize = audioRecord.read(audiodata, 0, bufferSizeInBytes);
if (AudioRecord.ERROR_INVALID_OPERATION != readsize && fos != null) {
try {
fos.write(audiodata);
} catch (IOException e) {
e.printStackTrace();
}
}
}
try {
if (fos != null)
fos.close();// 关闭写入流
} catch (IOException e) {
e.printStackTrace();
}
}
// 这里得到可播放的音频文件
private void copyWaveFile(String inFilename, String outFilename) {
FileInputStream in = null;
FileOutputStream out = null;
long totalAudioLen = 0;
long totalDataLen = totalAudioLen + 36;
long longSampleRate = AudioFileFunc.AUDIO_SAMPLE_RATE;
int channels = 2;
long byteRate = 16 * AudioFileFunc.AUDIO_SAMPLE_RATE * channels / 8;
byte[] data = new byte[bufferSizeInBytes];
try {
in = new FileInputStream(inFilename);
out = new FileOutputStream(outFilename);
totalAudioLen = in.getChannel().size();
totalDataLen = totalAudioLen + 36;
WriteWaveFileHeader(out, totalAudioLen, totalDataLen, longSampleRate, channels, byteRate);
while (in.read(data) != -1) {
out.write(data);
}
in.close();
out.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 这里提供一个头信息。插入这些信息就可以得到可以播放的文件。
* 为我为啥插入这44个字节,这个还真没深入研究,不过你随便打开一个wav
* 音频的文件,可以发现前面的头文件可以说基本一样哦。每种格式的文件都有自己特有的头文件。
*/
private void WriteWaveFileHeader(FileOutputStream out, long totalAudioLen, long totalDataLen, long longSampleRate, int channels, long byteRate) throws IOException {
byte[] header = new byte[44];
header[0] = 'R'; // RIFF/WAVE header
header[1] = 'I';
header[2] = 'F';
header[3] = 'F';
header[4] = (byte) (totalDataLen & 0xff);
header[5] = (byte) ((totalDataLen >> 8) & 0xff);
header[6] = (byte) ((totalDataLen >> 16) & 0xff);
header[7] = (byte) ((totalDataLen >> 24) & 0xff);
header[8] = 'W';
header[9] = 'A';
header[10] = 'V';
header[11] = 'E';
header[12] = 'f'; // 'fmt ' chunk
header[13] = 'm';
header[14] = 't';
header[15] = ' ';
header[16] = 16; // 4 bytes: size of 'fmt ' chunk
header[17] = 0;
header[18] = 0;
header[19] = 0;
header[20] = 1; // format = 1
header[21] = 0;
header[22] = (byte) channels;
header[23] = 0;
header[24] = (byte) (longSampleRate & 0xff);
header[25] = (byte) ((longSampleRate >> 8) & 0xff);
header[26] = (byte) ((longSampleRate >> 16) & 0xff);
header[27] = (byte) ((longSampleRate >> 24) & 0xff);
header[28] = (byte) (byteRate & 0xff);
header[29] = (byte) ((byteRate >> 8) & 0xff);
header[30] = (byte) ((byteRate >> 16) & 0xff);
header[31] = (byte) ((byteRate >> 24) & 0xff);
header[32] = (byte) (2 * 16 / 8); // block align
header[33] = 0;
header[34] = 16; // bits per sample
header[35] = 0;
header[36] = 'd';
header[37] = 'a';
header[38] = 't';
header[39] = 'a';
header[40] = (byte) (totalAudioLen & 0xff);
header[41] = (byte) ((totalAudioLen >> 8) & 0xff);
header[42] = (byte) ((totalAudioLen >> 16) & 0xff);
header[43] = (byte) ((totalAudioLen >> 24) & 0xff);
out.write(header, 0, 44);
}
}
然后在录音按钮里的点击事件里写了这么两行行代码:
- //开始进行语音听写
- mIat.startListening(mRecoListener);
- //开始录音并且保存录音到sd卡
- audioRecordFunc.startRecordAndFile();
//开始进行语音听写
mIat.startListening(mRecoListener);
//开始录音并且保存录音到sd卡
audioRecordFunc.startRecordAndFile();这里会发生一个很奇怪的现象,能听写的时候不能录音,能录音的时候不能听写,录音的两个类MediaRecorder、AudioRecord中
MediaRecorder的start()方法中有这么一句话:
The apps should not start another recording session during recording.
(一个app不应该在录音期间开启另外一个录音),原因我大致理解为麦克风被占用了
既然不能一边录音一边识别,那我们只好录完音后再上传去识别,嗯,回头看了一下设置的参数
- mIat.setParameter(SpeechConstant.AUDIO_SOURCE, “-2”);
- mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, ”要识别的音频绝对路径“);
mIat.setParameter(SpeechConstant.AUDIO_SOURCE, "-2");
mIat.setParameter(SpeechConstant.ASR_SOURCE_PATH, ”要识别的音频绝对路径“);
设置好参数之后
- mIat.startListening(mRecoListener);
mIat.startListening(mRecoListener);这下可以了,保存的音频文件可以识别,而且识别的速度和讲话的时候是一样的,也就是说,你在第5秒说的话,就是在第五秒开始识别(不考虑网络延迟的时候),这样,就可以实现了我们的需求。
然而,事情往往没有那么简单,还是回到了原始的问题,也就是前后端点超时或者一分钟过后的音频不再识别!!!
有两个解决方法:
1、自己重新写一个类继承科大讯飞里面的类,重写里面的方法
2、通过流的方式去控制,假如文件流读取没完成,音频不再识别,那就重新激活,直到文件流读取完毕
两秒钟之后我立马放弃了第一种解决方案,源码是长这样子的:那就只能采用第二种方案了,此时我们要进行相应的参数设置:
- mIat.setParameter(SpeechConstant.AUDIO_SOURCE, “-1”);
- //开始进行语音听写
- mIat.startListening(mRecoListener);
- //然后在进行音频流输入
- mIat.writeAudio(bytes, 0, bytes.length);
mIat.setParameter(SpeechConstant.AUDIO_SOURCE, "-1"); //开始进行语音听写 mIat.startListening(mRecoListener); //然后在进行音频流输入 mIat.writeAudio(bytes, 0, bytes.length);
录完音后,根据音频文件读取流。代码我就不粘贴出来了,因为这个方法行不通,原因是因为流读取的速度太快,几分钟的文件一下子就读取完了,端点超时问题还是会出现(ps:希望有个人告诉流能否控制其读取速度,怎么控制),而且就算能控制速度,假如用户录音一个小时的,你不可能又要花一个小时去识别音频吧,这不现实!!
未完待续...
</div>