文章目录
前言
最近在做一些小目标分割的课题,看了一些论文后,亲自做了一些网络模块的实验,的确有不错的提升,现通过写这篇博文做相关总结。首先介绍下我做实验的数据集,该数据集是小目标分割数据集,汇集了NUST/IRSTD-1K/NUAA/annotation/红外(回丙伟)所有小目标红外图像,所有target目标像素在5*5以内,共原始图像1935张,不进行随机贴图。链接在我的github上。
个人认为小目标问题的难题在于如何提取特征(如何提取弱小目标的特征,如何消除不同深度特征层之间的语义差异,如何学习更加相关的信息),如何使模型收敛更加稳定?首先提取弱小目标特征应当会选取一个较深且不会过拟合的网络(可参考提取特征网络的发展过程),而不同层特征之间的语义差异和网络应当学习更相关的内容则势必要考虑注意力机制和尺度融合。
一些重要的网络模块
The Dense Nested Interaction Module; 来源于DNAnet。论文链接。
Channel and Spatial Attention Module; 来源于DNAnet。
Cascade Multi-Scale Convolution Module; 来源于wnet。论文链接。
Dual Supervised Module; 来源于wnet。
一、The Dense Nested Interaction Module;
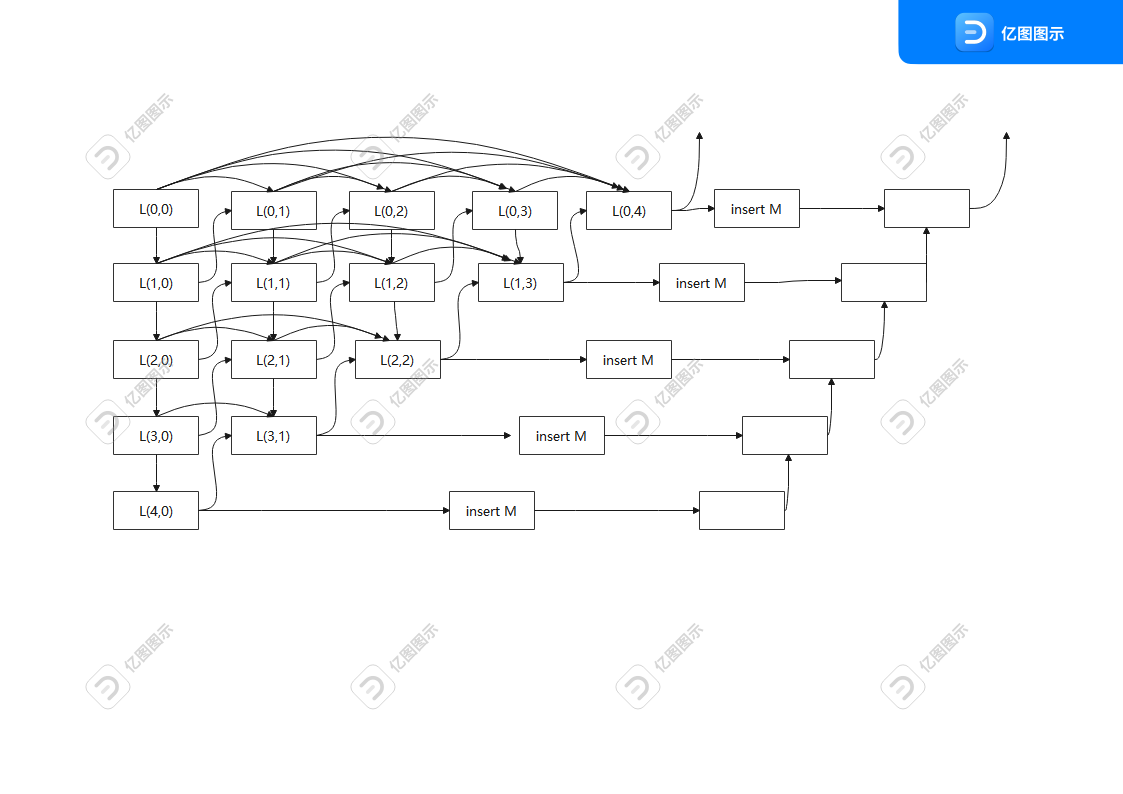
该提取特征模块灵感来源于DenseNet与NestedNet。要实现强大的上下文信息建模能力,一种直接的方法是不断增加层的数量。这样既可以获得高层次的信息,又可以获得更大的接受域。然而,弱小目标在尺寸上有很大的限制,随着网络层数的增加,可以获得目标的高级信息,r然而目标也有可能在多次池化操作后丢失。因此,我们应该设计一个专门的提取高层特征,并保持深层小目标的表示。密集嵌套交互模块,我们将多个u形子网络堆叠在一起,形成密集嵌套的结构。基于这种思想,我们在编码器和解码器子网络之间的路径上施加了多个节点。所有这些中间节点彼此紧密相连,形成一个嵌套状的网络。
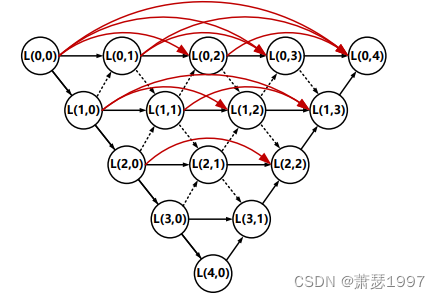
看图,L(0,0),L(1,0),L(2,0),L(3,0),L(4,0)就是我们说的backbone,而其他每个节点都可以接收到来自自身和相邻层的特征,导致重复的多层特征融合。这样,小目标的表示就保持在深层,从而可以获得更好的结果。
代码如下:
class DNANet_new(nn.Module):
def __init__(self, num_classes, input_channels, block, num_blocks, nb_filter,if_DCMSC = False):
super(DNANet_new, self).__init__()
self.relu = nn.ReLU(inplace = True)
self.if_DCMSC = if_DCMSC
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.down = nn.Upsample(scale_factor=0.5, mode='bilinear', align_corners=True)
self.up_4 = nn.Upsample(scale_factor=4, mode='bilinear', align_corners=True)
self.up_8 = nn.Upsample(scale_factor=8, mode='bilinear', align_corners=True)
self.up_16 = nn.Upsample(scale_factor=16, mode='bilinear', align_corners=True)
self.conv0_0 = self._make_layer(block, input_channels, nb_filter[0])
self.conv1_0 = self._make_layer(block, nb_filter[0], nb_filter[1], num_blocks[0])
self.conv2_0 = self._make_layer(block, nb_filter[1], nb_filter[2], num_blocks[1])
self.conv3_0 = self._make_layer(block, nb_filter[2], nb_filter[3], num_blocks[2])
self.conv4_0 = self._make_layer(block, nb_filter[3], nb_filter[4], num_blocks[3])
self.conv0_1 = self._make_layer(block, nb_filter[0] + nb_filter[1], nb_filter[0])
self.conv1_1 = self._make_layer(block, nb_filter[1] + nb_filter[2] + nb_filter[0], nb_filter[1], num_blocks[0])
self.conv2_1 = self._make_layer(block, nb_filter[2] + nb_filter[3] + nb_filter[1], nb_filter[2], num_blocks[1])
self.conv3_1 = self._make_layer(block, nb_filter[3] + nb_filter[4] + nb_filter[2], nb_filter[3], num_blocks[2])
self.conv0_2 = self._make_layer(block, nb_filter[0]*2 + nb_filter[1], nb_filter[0])
self.conv1_2 = self._make_layer(block, nb_filter[1]*2 + nb_filter[2]+ nb_filter[0], nb_filter[1], num_blocks[0])
self.conv2_2 = self._make_layer(block, nb_filter[2]*2 + nb_filter[3]+ nb_filter[1], nb_filter[2], num_blocks[1])
self.conv0_3 = self._make_layer(block, nb_filter[0]*3 + nb_filter[1], nb_filter[0])
self.conv1_3 = self._make_layer(block, nb_filter[1]*3 + nb_filter[2]+ nb_filter[0], nb_filter[1], num_blocks[0])
self.conv0_4 = self._make_layer(block, nb_filter[0]*4 + nb_filter[1], nb_filter[0])
self.conv0_4_final = self._make_layer(block, nb_filter[0]*5, nb_filter[0])
self.conv0_4_1x1 = nn.Conv2d(nb_filter[4], nb_filter[3], kernel_size=1, stride=1)
self.conv0_3_1x1 = nn.Conv2d(nb_filter[3]*2, nb_filter[2], kernel_size=1, stride=1)
self.conv0_2_1x1 = nn.Conv2d(nb_filter[2]*2, nb_filter[1], kernel_size=1, stride=1)
self.conv0_1_1x1 = nn.Conv2d(nb_filter[1]*2, nb_filter[0], kernel_size=1, stride=1)
self.final = nn.Conv2d (nb_filter[0], num_classes, kernel_size=1)
self.conv0_4_final = self._make_layer(block, nb_filter[0] * 2, nb_filter[0])
def _make_layer(self, block, input_channels, output_channels, num_blocks=1):
layers = []
#block可以自己设计,参考resnet等
layers.append(block(input_channels, output_channels))
for i in range(num_blocks-1):
layers.append(block(output_channels, output_channels))
return nn.Sequential(*layers)
def forward(self, input):
#这一部分是The Dense Nested Interaction Module,可见构建时较为复杂。
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0),self.down(x0_1)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0),self.down(x1_1)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1),self.down(x0_2)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0),self.down(x2_1)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1),self.down(x1_2)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2),self.down(x0_3)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
#
output4_0 = x4_0 #filter nb_filter[4] -> nb_filter[4]
output3_1 = torch.cat([x3_1,self.up(self.conv0_4_1x1(output4_0))],1) #filter nb_filter[3] -> nb_filter[3]*2
output2_2 = torch.cat([x2_2,self.up(self.conv0_3_1x1(output3_1))],1) #filter nb_filter[2] -> nb_filter[2]*2
output1_3 = torch.cat([x1_3,self.up(self.conv0_2_1x1(output2_2))],1) #filter nb_filter[1] -> nb_filter[1]*2
output0_4 = torch.cat([x0_4,self.up(self.conv0_1_1x1(output1_3))],1) #filter nb_filter[0] -> nb_filter[0]*2
Final_x0_4 = self.conv0_4_final(output0_4)
output = self.final(Final_x0_4)
return output
二、Channel and Spatial Attention Module;
该模块是通道注意力机制和空间注意力机制相结合的模块,即插即用。
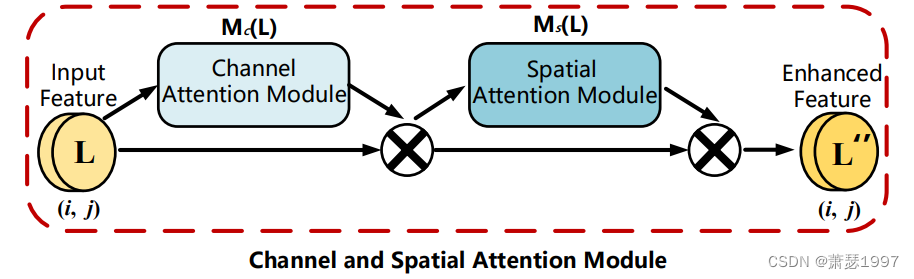
现在这样的用于解决信息不相关问题的注意力机制模块有很多。从PSANet、DANet、OCNet、CCNet、EMANet、SANet的一系列的演变,具体参考该博文。
同时还有通道注意力机制,SENet,CBAM,ECA。具体参考博文。
*其实,个人认为注意力机制比较好理解,可以用f(z1,z2,z3,…,zi,…)去描述zi。也就是通过一种方式来描述某一元素与其他元素(包括自己在内)之间的相似度,来描述相关性,构建元素相关性矩阵。比如我们对通道进行注意力机制时,最重要的就是构建C×C矩阵,能够衡量所有通道元素与其他通道(包括自己在内)的相关性,从而来聚焦这些通道中相对重要的通道,及与大部分通道都相关的通道,这个相关的程度可以用相似度粗略描述,也可以用更加复杂的方式,但是考虑到网络前向传播的效率,我们一般采取向量点积计算相似度的方式。
CSAM代码如下,可即插即用:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class Res_CBAM_block(nn.Module):
def __init__(self, in_channels, out_channels, stride = 1):
super(Res_CBAM_block, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size = 3, stride = stride, padding = 1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace = True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size = 3, padding = 1)
self.bn2 = nn.BatchNorm2d(out_channels)
if stride != 1 or out_channels != in_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size = 1, stride = stride),
nn.BatchNorm2d(out_channels))
else:
self.shortcut = None
self.ca = ChannelAttention(out_channels)
self.sa = SpatialAttention()
def forward(self, x):
residual = x
if self.shortcut is not None:
residual = self.shortcut(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out
out = self.sa(out) * out
out += residual
out = self.relu(out)
return out
三、Cascade Multi-Scale Convolution Module;
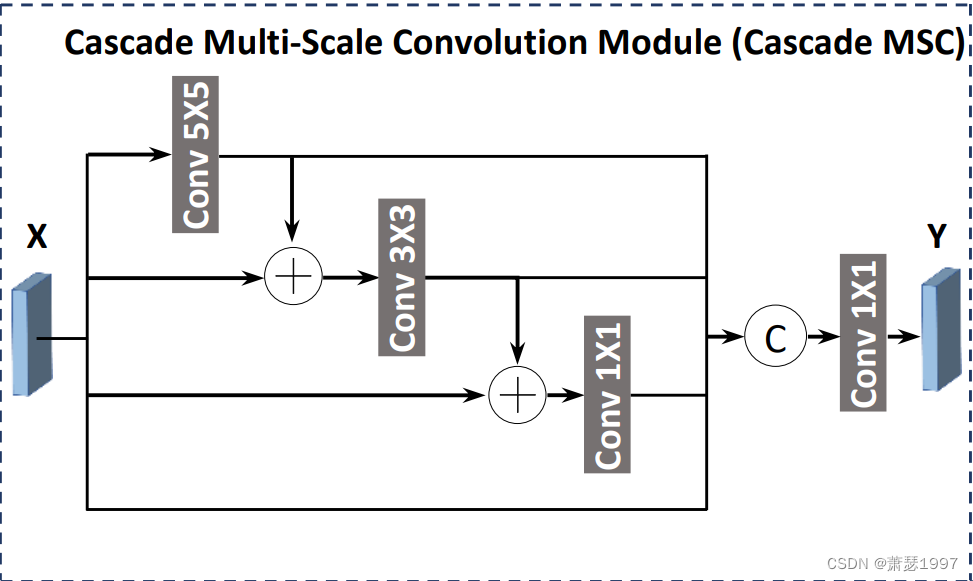
在直接使用跳过连接深层特征层这些特征映射,可能会削弱模型分割模型的性能。较深层生成的特征图较为抽象,因此通常更容易丢失一些小对象的重要信息因此,使用该策略融合多尺度特征信息可能不适用于小目标分割任务。因此,一种新的多尺度特征融合方案——级联多尺度卷积(cascade multi-scale convolution, MSC)。然后将这些多尺度特征映射融合在一起,弥合语义鸿沟。由于级联MSC在给定跳跃连接处生成的所有多尺度特征映射都是基于同一源特征映射,不使用任何更深层次的特征映射,因此在生成的多尺度特征映射中可以更大程度地保留小对象的特征信息。因此在很深层次时采用CMSCM。
在形式上,
X’ = Conu_5 X 5(X),
X2 = Conu_3 x3 (Sum(x, x’)),
X3 = Conu_1 x1 (Sum(x, X2)),
Y = conn_1 x1 (Concate(x, x’, x2, x3)) .
class Diversely_Connected_Multi_Scale_Convolution(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(Diversely_Connected_Multi_Scale_Convolution, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size = 5, stride = stride, padding = 2)
self.bn1 = nn.BatchNorm2d(in_channels)
self.relu1 = nn.ReLU(inplace = True)
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size = 3, stride = stride, padding = 1)
self.bn2 = nn.BatchNorm2d(in_channels)
self.relu2 = nn.ReLU(inplace = True)
self.conv3 = nn.Conv2d(in_channels, in_channels, kernel_size = 1, stride = stride)
self.bn3 = nn.BatchNorm2d(in_channels)
self.relu3 = nn.ReLU(inplace = True)
self.conv4 = nn.Conv2d(4*in_channels, out_channels, kernel_size = 1, stride = stride)
self.bn4 = nn.BatchNorm2d(out_channels)
self.relu4 = nn.ReLU(inplace = True)
def forward(self, x):
out4 = x
out = self.conv1(x)
out = self.bn1(out)
out1 = self.relu1(out)
input2 = out1 + x
out = self.conv2(input2)
out = self.bn2(out)
out2 = self.relu2(out)
input3 = out2 + x
out = self.conv3(input3)
out = self.bn3(out)
out3 = self.relu3(out)
out = self.conv4(torch.cat([out1,out2,out3,out4],1))
out = self.bn4(out)
out_final = self.relu4(out)
return out_final
四、Dual Supervised Module;
辅助监督,即增加了一个扩展路径,通过双监督实现更精确的分割性能。原始扩展路径每层上采样的特征映射不仅与收缩路径上的特征映射相连接,而且与附加扩展路径上采样的特征映射相连接。最后,在附加扩展路径的帮助下,通过双重监督学习w-Net,即既通过原始扩展路径的分割损失,又通过附加扩展路径的辅助分割损失。我们可以将附加扩展路径中的分割过程视为粗分割,粗中间分割结果再发送到原扩展路径中进行进一步细化,从而在原扩展路径中获得更准确的最终分割结果。直接上图,我没有重新画图,而是参考了W-net中的模型图,因为画图太麻烦了!这一模块的思想可以借鉴到其他网络中,通过输出前一阶段的损失,来共同拟合结果。
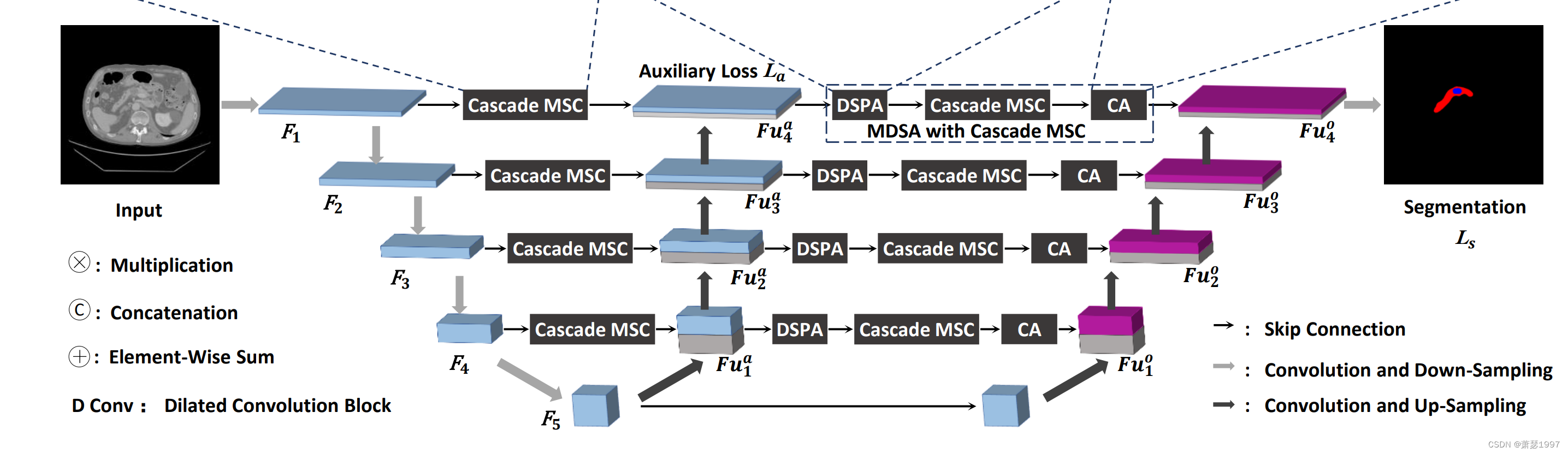
w-Net的第一个改进是在U-Net中
五、一些实验结果。
在探索分割网络性能的时候,本人设计一个Nested-Net 加辅助监督的模式,将DNANet与w-net结合起来,应对弱小目标分割。并尝试在这个基础网络中不同位置尝试插入Channel and Spatial Attention Module和Cascade Multi-Scale Convolution Module。但是发现这些即插即用的模块用的不是越多越好,有些地方插入CSAM反而影响性能,没有达到预期的效果。这是为什么呢?首先可能是参数过多导致过拟合有关,还有可能是因为CSAM是在过多关注通道重要性,且目标太小,这种Spatial Attention也不能起到很好效果。简单画了一下模型图。
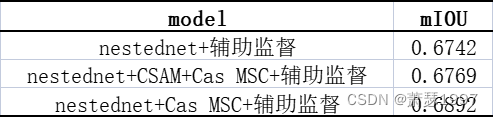
以上CSAM和Cas MSC模块添加在两监督之间,也就是Dual Supervised Module 之间,nestednet的backbone选取resnet18,该结果可以反映一定问题,仅供参考。
提示:实验结果仅供参考。
总结
以上在网络层面对弱小目标分割进行研究。在实际项目中,可能更多关注怎么解决数据量少的问题,emmm。各位博主有问题请留言!!