1.基本特性
一个分布式的实时文档存储库,每个字段都可以被索引与搜索;
一个分布式的实时分析搜索引擎;
能胜任上百个服务节点的扩展,并支持PB级别的结构化或者非结构化数据。
2.相关概念
近实时(Near Real Time,NRT):
Elasticsearch是一个近实时的数据搜索和分析平台,这意味着从索引文档到可搜索文档都会有一段微小的延迟(通常是1s以内)。
集群(Cluster):
集群是一个或多个节点的集合,这些节点将共同拥有完整的数据,并跨节点提供联合索引、搜索和分析功能。
集群由唯一的名称标识(elasticsearch.yml配置文件中的参数cluster.name,默认名称为:Elasticsearch)。可以存在多独立的集群,但每个集群必须都有自己唯一的集群名称!
节点(Node):
节点是一个Elasticsearch的运行实例,也就是一个进程(process)。数据存储在节点,多个节点组成集群。节点还参与集群的索引、搜索和分析功能。
与集群一样,节点由一个名称标识。默认情况下,节点名称是启动时分配给节点的随机通用唯一标识符(UUID)。如果不想用默认值,可以自定义节点名称(谨记配置有意义的节点名称)。
可以通过集群名称将节点配置为加入特定集群。默认情况下,每个节点都被设置为加入一个名为Elasticsearch的集群(这意味着,如果在网络上启动了多个节点,并且它们可以发现彼此的话,那么它们将自动形成并加入一个名为Elasticsearch的集群)。
索引(index):
索引是Elasticsearch数据管理的顶层单位,是具有某种相似特性的文档集合(相当于MySQL、MongoDB等中的“数据库”这个概念)。
索引由一个名称(必须全部小写)标识,当对其中的文档执行索引、搜索、更新和删除操作时,该名称指向这个特定的索引。
在单个集群中,可以定义任意多个索引。
类型(Type):
这个概念在7.0版本以后已被彻底移除。
文档(document):
文档是可以被索引的基本信息单元,并以JSON表示(JSON是一种普遍存在的Internet数据交换格式)。在单个索引中,理论上可以存储任意多的文档。
字段(Fields):
每个文档中都包含许多字段,每个字段都有其对应的值。
3.准备工作
【必须】配置Elasticsearch:https://www.elastic.co/cn/downloads/elasticsearch
【必须】安装Python库(对接Elasticsearch操作):pip install elasticsearch
【建议】配置kibana(配套的可视化管理工具):https://www.elastic.co/cn/start
【可选】安装IK Analysis(中文分词插件):https://github.com/medcl/elasticsearch-analysis-ik
注意三个工具的版本要保持一致!!
配置Elasticsearch:
1.下载并解压zip文件;
2.点击.\bin\elasticsearch.bat启动(在打开的命令窗口点击Ctrl+C关闭Elasticsearch);
3.在CMD中运行:curl http://localhost:9200
或在PowerShell中运行:Invoke-RestMethod http://localhost:9200
或在浏览器中打开:http://localhost:9200
配置kibana:
1.下载并解压zip文件;
2.编辑.\config\kibana.yml;

3.点击.\bin\kibana.bat启动(在打开的命令窗口点击Ctrl+C关闭kibana);
4.在浏览器中打开:http://localhost:5601
安装IK Analysis
在.\bin打开命令窗口,输入:
.\elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.16.3/elasticsearch-analysis-ik-7.16.3.zip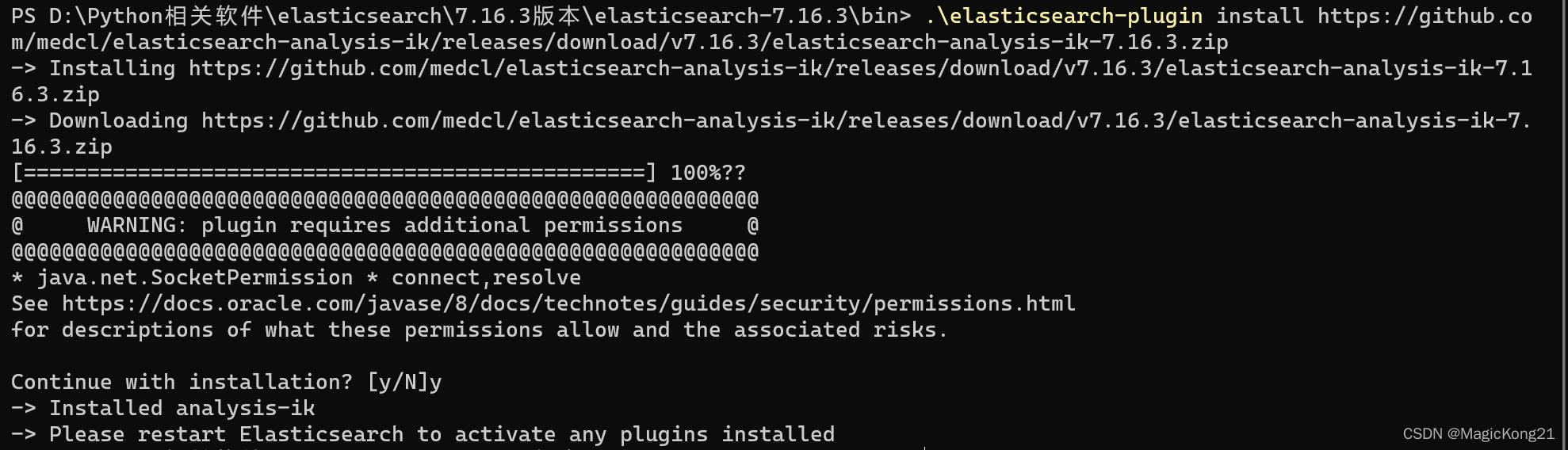
最新版本地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
确保版本号和Elasticsearch一致!!
4.创建索引
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 声明一个Elasticsearch对象es
result = es.indices.create(index='it_news')
# 调用es的indices对象的create方法,传入index的名称“it_news”
print(result){'acknowledged': True, 'shards_acknowledged': True, 'index': 'it_news'}
返回结果是JSON格式,其中的acknowledged字段表示创建操作执行成功。
如果把代码再执行一遍,会报错:
raise HTTP_EXCEPTIONS.get(status_code, TransportError)(
elasticsearch.exceptions.RequestError: RequestError(400, 'resource_already_exists_exception', 'index [it_news/VQIJEDvjRzaqknxEHdQ6lA] already exists')
所以一般会加入ignore参数,把一些意外情况排除,来保证程序正常执行而不会中断。
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 声明一个Elasticsearch对象es
result = es.indices.create(index='it_news',ignore=400)
# 调用es的indices对象的create方法传入index的名称“it_news”
print(result)此时把代码再执行一遍,返回的结果同样是JSON格式,这表明程序没有中断(这是因为添加的ignore参数忽略了400状态码,因此程序正常执行输出JSON结果,而不是抛出异常。)。
{'error': {'root_cause': [{'type': 'resource_already_exists_exception', 'reason': 'index [it_news/VQIJEDvjRzaqknxEHdQ6lA] already exists', 'index_uuid': 'VQIJEDvjRzaqknxEHdQ6lA', 'index': 'it_news'}], 'type': 'resource_already_exists_exception', 'reason': 'index [it_news/VQIJEDvjRzaqknxEHdQ6lA] already exists', 'index_uuid': 'VQIJEDvjRzaqknxEHdQ6lA', 'index': 'it_news'}, 'status': 400}
创建完之后,还可以设置一下索引的字段映射定义(内容待补充)。
5.删除索引
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 声明一个Elasticsearch对象es
result = es.indices.delete(index='it_news',ignore=[400, 404])
# 调用es的indices对象的delete方法删除名为“it_news”的index
print(result)返回结果:
{'acknowledged': True}
如果再执行一遍,返回结果:
{'error': {'root_cause': [{'type': 'index_not_found_exception', 'reason': 'no such index [it_news]', 'resource.type': 'index_or_alias', 'resource.id': 'it_news', 'index_uuid': '_na_', 'index': 'it_news'}], 'type': 'index_not_found_exception', 'reason': 'no such index [it_news]', 'resource.type': 'index_or_alias', 'resource.id': 'it_news', 'index_uuid': '_na_', 'index': 'it_news'}, 'status': 404}
由于delete方法里面也使用了ignore参数,所以即使删除失败,也只是会返回一个JSON格式,而不会导致程序中断。
6.插入数据
用create方法:
Elasticsearch跟MongoDB一样,在插入数据的时候可以直接插入结构化字典数据,插入数据可以调用create方法或者index方法(create方法内部其实也是调用了index方法,是对index方法的封装)。
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 声明一个Elasticsearch对象es
es.indices.create(index='it_news',ignore=400)
# 调用es的indices对象的create创建名为“it_news”的index(已创建就忽略)
data = {'title': '微软大手笔:Xbox 宣布 687 亿美元收购动视暴雪为打造“元宇宙”添砖加瓦,后者盘前大涨 37%',
'url': 'https://www.ithome.com/0/599/223.htm'}
# 声明一条新闻数据(包含标题和链接)
result = es.create(index='it_news', id='1', document=data)
# 调用es的create方法插入,在调用时传入3个参数:
# index代表索引名称,id是数据的唯一标识,document代表文档的具体内容
print(result)返回的同样是JSON格式,其中result字段为created,代表数据插入成功。
{'_index': 'it_news', '_type': '_doc', '_id': '1', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 0, '_primary_term': 1}
用index方法:
另外也可以用index方法插入数据(区别在于index方法不需要指定id,会自动生成)
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 声明一个Elasticsearch对象es
es.indices.create(index='it_news', ignore=400)
# 调用es的indices对象的create创建名为“it_news”的index(已创建就忽略)
data = {'title': '三星 Exynos 2200 GPU 跑分首次出炉:AMD RDNA2 加持,紧追骁龙 8 Gen 1',
'url': 'https://www.ithome.com/0/599/261.htm'}
# 声明一条新闻数据(包含标题和链接)
result = es.index(index='it_news', document=data)
# 调用es的create方法插入,在调用时传入2个参数:
# index代表索引名称,document代表文档的具体内容
print(result){'_index': 'it_news', '_type': '_doc', '_id': 'QDE_cX4Bw_xw4x789mmU', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 1, '_primary_term': 1}
在返回信息里面可以看到,data已经插入成功,并自动生成了id。
7.更新数据
用update方法(局部更新):
效率更高!可以看作是先删除后index的原子操作,省略了返回的过程,节省了来回传输的网络流量,同时避免了中间时间造成的文档修改冲突。(注意在body的参数中,需要添加doc或者script变量来指定修改的内容)
<此处参考:这4种Python更新Elasticsearch数据的方法你都会吗?>
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 声明一个Elasticsearch对象es
data = {
'doc': {
'title': '微软大手笔:Xbox 宣布 687 亿美元收购动视暴雪为打造“元宇宙”添砖加瓦,后者盘前大涨 37%',
'url': 'https://www.ithome.com/0/599/223.htm',
'data': '2022-01-19'
}
}
# 声明一条新闻数据(在原本基础上,新增日期)
result = es.update(index='it_news', id='1', body=data)
# 调用es的update方法插入,在调用时传入3个参数:
# index代表索引名称,id表示ID标识,body代表文档的具体内容
# 注意在body的参数中,需要添加doc或者script变量来指定修改的内容
print(result){'_index': 'it_news', '_type': '_doc', '_id': '2', '_version': 2, 'result': 'updated', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 4, '_primary_term': 1}
用index方法(全局更新):
兼具插入与更新功能,更加便捷!本质上是进行了一次reindex的操作,所以当数据量或者document很庞大的时候,效率非常的低。
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 声明一个Elasticsearch对象es
data = {
'title': '微软大手笔:Xbox 宣布 687 亿美元收购动视暴雪为打造“元宇宙”添砖加瓦,后者盘前大涨 37%',
'url': 'https://www.ithome.com/0/599/223.htm',
'date': '2022-01-19'
}
# 声明一条新闻数据(在原本基础上,新增日期)
result = es.index(index='it_news', id='1', document=data)
# 调用es的index方法插入,在调用时传入3个参数:
# index代表索引名称,id表示ID标识,document代表文档的具体内容
print(result){'_index': 'it_news', '_type': '_doc', '_id': '1', '_version': 2, 'result': 'updated', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 2, '_primary_term': 1}
这里同样使用index方法进行更新操作。(如果数据不存在就执行插入操作,如果数据存在就执行更新操作,非常方便)在返回结果中,可以看到result字段为updated,表示更新成功。version字段为2,表示这是第二个版本(对比一下前面插入操作返回的信息,当时是1,每次更新后都会加1)。
8.删除数据
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 声明一个Elasticsearch对象es
result = es.delete(index='it_news', id='1')
# 调用es的delete方法删除指定数据,在调用时传入3个参数:
# index代表索引名称,id表示ID标识
print(result){'_index': 'it_news', '_type': '_doc', '_id': '1', '_version': 3, 'result': 'deleted', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 3, '_primary_term': 1}
返回结果同样是JSON格式,result字段的deleted表示删除成功,此时version字段的值又加了1变成3。
9.查询数据
对于中文语境下的查询操作,必须先安装分词插件,这里用的是前面提及的IK Analysis。
初始化测试环境1(删除之前的索引,新建索引并更新索引的mapping信息)
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.delete(index='it_news', ignore=[400, 404])
# 删除之前创建的索引
es.indices.create(index='it_news', ignore=400)
# 新建一个it_news索引
mapping = {
# 声明一个mapping信息
'properties': {
'title': {
# 指定分词字段为“title”
'type': 'text',
# 指定字段类型为text
'analyzer': 'ik_max_word',
# 指定分词器为IK(如果不指定,则会使用默认的英文分词器)
'search_analyzer': 'ik_max_word'
# 指定搜索分词器为IK
}
}
}
result = es.indices.put_mapping(index='it_news', body=mapping)
# 更新索引的mapping信息
print(result){'acknowledged': True}
初始化测试环境2(导入四条document):
from elasticsearch import Elasticsearch
es = Elasticsearch()
datas = [
{
'title': '微软大手笔:Xbox 宣布 687 亿美元收购动视暴雪为打造“元宇宙”添砖加瓦,后者盘前大涨 37%',
'url': 'https://www.ithome.com/0/599/223.htm',
},
{
'title': '三星 Exynos 2200 GPU 跑分首次出炉:AMD RDNA2 加持,紧追骁龙 8 Gen 1',
'url': 'https://www.ithome.com/0/599/261.htm',
},
{
'title': '三星晶圆代工客户超过 100 家,目标 2030 年超过台积电',
'url': 'https://www.ithome.com/0/599/403.htm',
},
{
'title': '微软收购动视暴雪,游戏圈“大地震”:索尼在日本股市跌近 10%,创 2020 年 3 月以来最大跌幅',
'url': 'https://www.ithome.com/0/599/265.htm',
},
]
for data in datas:
es.index(index='it_news', document=data)基于索引名进行搜索查询:
from elasticsearch import Elasticsearch
es = Elasticsearch()
result = es.search(index='it_news')
print(result){'took': 1020, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 4, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'it_news', '_type': '_doc', '_id': 'QTFKcn4Bw_xw4x78kmlW', '_score': 1.0, '_source': {'title': '微软大手笔:Xbox 宣布 687 亿美元收购动视暴雪为打造“元宇宙”添砖加瓦,后者盘前大涨 37%', 'url': 'https://www.ithome.com/0/599/223.htm'}}, {'_index': 'it_news', '_type': '_doc', '_id': 'QjFKcn4Bw_xw4x78k2k3', '_score': 1.0, '_source': {'title': '三星 Exynos 2200 GPU 跑分首次出炉:AMD RDNA2 加持,紧追骁龙 8 Gen 1', 'url': 'https://www.ithome.com/0/599/261.htm'}}, {'_index': 'it_news', '_type': '_doc', '_id': 'QzFKcn4Bw_xw4x78k2lt', '_score': 1.0, '_source': {'title': '三星晶圆代工客户超过 100 家,目标 2030 年超过台积电', 'url': 'https://www.ithome.com/0/599/403.htm'}}, {'_index': 'it_news', '_type': '_doc', '_id': 'RDFKcn4Bw_xw4x78k2mg', '_score': 1.0, '_source': {'title': '微软收购动视暴雪,游戏圈“大地震”:索尼在日本股市跌近 10%,创 2020 年 3 月以来最大跌幅', 'url': 'https://www.ithome.com/0/599/265.htm'}}]}}
▲ 这里查询出来了4条数据(在hits字段里面),其中total字段标明了查询结果的条目数,max_score代表了匹配结果中的最大分数。
基于全文信息进行检索:
from elasticsearch import Elasticsearch
es = Elasticsearch()
query = {
'match': {
'title': '微软 索尼'
}
}
result = es.search(index='it_news', query=query)
print(result) 这里使用Elasticsearch支持的Query语句进行查询,使用match指定全文检索,检索的字段是title,内容是“微软 索尼”,搜索结果如下:
这里使用Elasticsearch支持的Query语句进行查询,使用match指定全文检索,检索的字段是title,内容是“微软 索尼”,搜索结果如下:
{'took': 2, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 1.7566946, 'hits': [{'_index': 'it_news', '_type': '_doc', '_id': 'RDFKcn4Bw_xw4x78k2mg', '_score': 1.7566946, '_source': {'title': '微软收购动视暴雪,游戏圈“大地震”:索尼在日本股市跌近 10%,创 2020 年 3 月以来最大跌幅', 'url': 'https://www.ithome.com/0/599/265.htm'}}, {'_index': 'it_news', '_type': '_doc', '_id': 'QTFKcn4Bw_xw4x78kmlW', '_score': 0.67722493, '_source': {'title': '微软大手笔:Xbox 宣布 687 亿美元收购动视暴雪为打造“元宇宙”添砖加瓦,后者盘前大涨 37%', 'url': 'https://www.ithome.com/0/599/223.htm'}}]}}
▲返回了两条结果,第一条分数为1.7566946,第二条分数为0.67722493,这是因为第一条匹配到了两个关键词(微软+索尼),第二条只匹配到了一个关键词(微软)。可以看到,检索时会对对应字段进行全文检索,并且还会根据检索关键词的相关性进行排序——这其实就是一个基本的搜索引擎的雏形了。
补充一些文字:
ElasticSearch 是一个分布式的,高性能,高可用的,可伸缩的搜索和分析系统
(1)可以作为大型分布式集群(数百台服务器)技术,处理 PB 级的数据,服务大公司;也可以运行在单机上服务于小公司
(2)Elasticsearch 不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的 ES:lucene (全文检索),商用的数据分析软件,分布式数据库
(3)对用户而言,是开箱即用的,非常简单,作为中小型应用,直接 3 分钟部署一下 ES,就可以作为生产环境的系统来使用了,此时的场景是数据量不大,操作不是太复杂
(4)数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);
特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理,Elasticsearch 作为传统数据库的一个补充,提供了数据库所不能提供的很多功能。
<完>