在学习Transformer中的注意力时有了新的感悟,在这里记录一下,首先我们来看一下Transformer中注意力的计算流程。如下图所示。
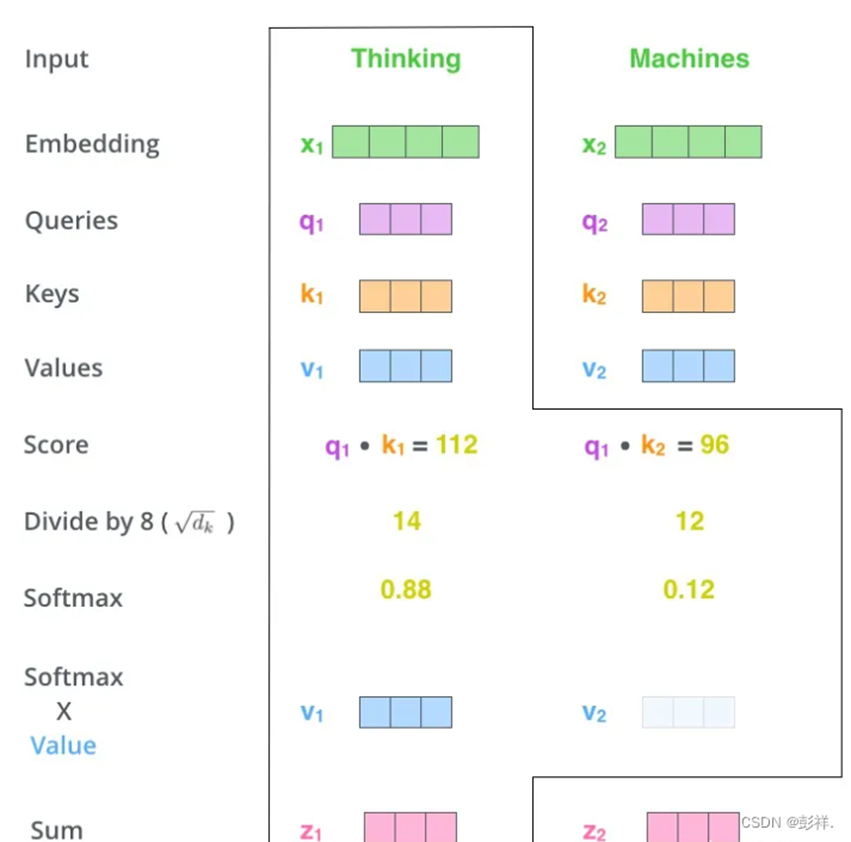
上面的过程其实就是执行下面这个公式的计算过程。
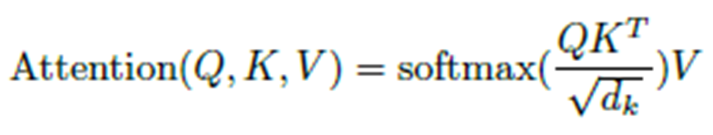
那么到底该如何理解这个Q,K,V呢?
下面我们以购物为例,来理解下Q,K,V的含义,并将其迁移到目标检测中。
Q即检索条件,K则为特征属性,比如有的K主打价格便宜,有的K主打质量,有的K主打设计
V则是K所代表的特征属性的一个具体值。
我们在进行检索时,就要看检索条件与属性的相关性,而在矩阵这相关性的计算是通过点乘来实现的。
除以dk是使这个值小一些,计算起来方便些。
随后使用softmax进行一个归一化与属性比例,将相关性量化。(以上图为例,K1更符合我们预想描述,故其值就越大些)
接下来乘以V则是要看看不同K描述的属性具体值到底是多少,也就是计算出我们以后要对这组K,V要施加的注意力为多少。可以看到注意力要想变大是Q,K,V共同努力的结果。
对Q而言,要想让自己更快速的找到自己想要的,那么Q就需要不断让自己的检索条件更加明确。
而K,V指的就是一个属性特征,其为了被注意到(在一次epoch中,K,V通过Encoder构建的特征值不再变化,但放眼多次epoch,其也是有改变的),也会让自己逐步将自己的无关属性逐步消失,来让自己更具有辨别性。这样在下次购物时,由于注意力的存在,Q变为直接去找K,从而学得更多的特征描述,Q的描述也就越清楚,条件越严格。
拓展到目标检测领域,Q就是要找的物体,最开始Q1说自己要找马,K1说我这是马,K2说我这也是马,他们都有马的属性,K1可能由遮挡,导致只有马蹄特征,而K2有马蹄,有马尾,马头,那么计算相关性时Q1与k2的相关性便会大些,随后再看看具体值是多少,随着这样不断的学习,Q1负责找马,其对自己所要找寻的马的特征也就越来越明显,在DETR中,要训练的便是这个Q,那么Q1便会以后负责去找马,其余的也就如法炮制。