性能测试分析与使用
一.为什么要做性能测试?
xx系统已经成功发布,依据之前项目的规划,计划服务1000+客户,未来势必会出现业务系统中信息大量增长的趋势。
随着该系统在生产状态下日趋稳定,也让我们可以更静下心来去关注性能方面的问题:
-
能够承受多大的数据量?
-
系统的瓶颈是什么?
-
代码的质量怎么样?
这些问题都需要通过性能测试来给出答案
二.需要注意什么?
1.明确测试目的
性能测试的目的分为两种:
-
验证:验证系统是否符合相关的性能需求。 如:满足500人的并发请求
-
定位调优:通过测试获取相关数据,针对数据进行分析、定位、调优。
2.确定测试内容
-
明确业务点与优先级
-
要根据功能、性能的优先级去划分业务的优先级别,确定待测和不测业务
-
针对不同的业务和场景确定相关的性能需求:吞吐量、响应时间等。
3.了解性能测试类别
-
网络级别的测试 当前测试
吞吐量和响应时间
-
操作系统的测试
cpu利用率, 磁盘交换率
-
数据库级别的测试
数据库并发连接数 ,锁资源的使用数, I/O的流量大小
4.受影响的因素
-
网络带宽 如:阿里50M 100M
-
服务器数量 如:阿里云服务器
-
服务器CPU,内存等性能 如:阿里的 2G 8G 固态硬盘,机械硬盘
-
服务器操作系统版本
-
代码质量
三.基本使用操作
Jmeter使用文档在线地址: [https://blog.csdn.net/r657225738/article/details/114981779]{.underline}
1. 简单的http请求
2. 自定义用户变量
3. 提取请求数据,并存入文件中
场景: 批量新增,批量查询
所需组件: [正则表达式提取器->BeanShell 后置处理程序] 注意点:
文字编码: utf-8
4. 使用CSV文件,读取数据
场景: 批量编辑,批量删除
所需组件: [CSV 数据文件设置]
四.用数据说话
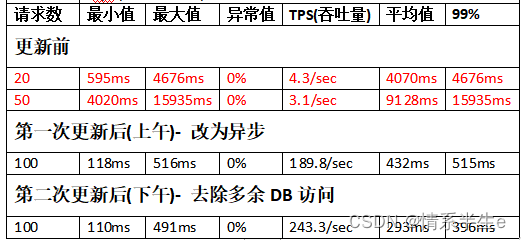
1.代码优化前后对比
问题列表-我的问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0yyMHUCf-1659577421964)(media/image1.png)]{width="5.751388888888889in" height="1.7034722222222223in"}](https://img-blog.csdnimg.cn/70094306e5ae40c78f48b8a75c2c5ba8.png)
2.单双副本的性能差距
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H2vrPJ0r-1659577421966)(media/image2.png)]{width="5.760416666666667in" height="2.071527777777778in"}](https://img-blog.csdnimg.cn/589ce2c84ffd46ab971c8c7e9e07e100.png)
五.经验总结
1.代码优化思路
通过APM链路跟踪 查看API的操作日志
-
1.减少不必要的访库操作
2.减少不必要的数据调用
例: 问题列表-我的问题 更新前与更新后
通过测试和代码调优,有两点需要大家注意
-
1.测试工具: Jemter进行并发测试
2.问题定位: 具体API通过内网APM链路跟踪来找到优化代码方向
得出结果:
-
并发测试中,API异步会直接提升性能.未写异步的API 20个并发, 吞吐量可能低至个位数. API改为Task异步 之后,100个并发, 吞吐量能到150-200
-
去掉代码中不必要的API访问可继续提升性能, 性能 提升明显. (和去掉的无关API访问数量有关) 测试 中,100个并发,吞吐量能到200-250
2.性能测试时API报错解答
在保证API地址与参数填写正确的情况下,如还报错则为以下两种情况
1. API报500
1.1数据库崩溃,卡死,需要重启
2. API报404
2.1所在企业Api服务卡死,需要重启
六.小知识
6.1聚合报告中的参数含义
-
最小值:指请求到服务器后返回数据所需最少时间
-
最大值:指请求到服务器后返回数据所需最多时间
-
异常值:指请求会出现断开或连接异常的比例
-
TPS(吞吐量):指每秒可处理多少请求,如120/sec,即每秒可处理120个网络请求. 20/min,即每分钟
-
平均值:指所有请求响应时间总和的平均值
-
99%:指有99%的请求在此范围之下,如354ms / 99%,即有99%的请求在354ms之前就完成了响应
6.2增加Replicated(副本) /Scale(规模)的作用
1.自己理解: Docker会在发生故障时花费更少的时间在另一个节点上创建新实例,这有助于提高性能,减少故障率.如目前有三个副本(replicated),当其中一个副本(服务器)承受不住时,会自动转移至可用的副本上。
2.专业解释: 让我们以包含单个实例的副本为例。现在,假设有一个失败。Docker Swarm将注意到该服务失败并重新启动它。该服务将重新启动,但是重新启动不是即时的。假设重新启动需要5秒钟。在这5秒钟内,您的服务不可用。单点故障。
如果您的副本包含3个实例怎么办。现在,当其中一个发生故障(没有完美的服务)时,Docker Swarm将注意到其中一个实例不可用,并创建一个新实例。在这段时间内,您仍然有2个运行正常的实例来处理请求。对于您的服务的用户,似乎没有停机时间。该组件不再是单点故障。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FgJWL6sr-1659577421968)(media/image3.png)]{width="5.754166666666666in" height="0.6125in"}](https://img-blog.csdnimg.cn/b62e5b7a72c6447990ef181eeb8b1bf9.png)
6.3 Scale调度规则
将node1宕机后或将node1的docker服务关闭,那么它上面的task实例就会转移到别的节点上。当node1节点恢复后,它转移出去的task实例不会主动转移回来,只能等别的节点出现故障后转移task实例到它的上面。使用命令\"docker node ls\",发现node1节点已不在swarm集群中了。
6.4 高并发的通俗含义
打个比方说,好比你开小吃店。
你有3个收银(web请求处理线程),5个厨师(数据库连接)。
一开始,生意没开多久。客人比较少。1个收银都能搞定。另外的人还闲着。
后来生意越来越好。于是得3个收银都干活(并发)。
结果过了一段时间来了个网红,突然店就火了,一大群人(高并发)慕名而来。
结果3个收银跟前大牌长龙(请求阻塞排队),而且收银也不是机器人,有的时候也会搞错单子(并发异常)。
再看后面厨师,单子越来越多,厨师一直做菜一直做菜,越来越来累,就越做越慢(数据库压力大,请求响应时间变长)。
菜出得越慢,后面排队的人就越多(请求阻塞后恶性循环)。
有的客人等不及了就直接走了(服务超时),顺手还给了你一个差评,影响自身的心情(影响上层服务)。
而后面的厨师呢,做了N道菜之后终于扛不住了,再也做不动了(数据库连接耗尽)。
于是乎小店只能暂停接客(服务器拒绝请求,报错502)。
6.5吞吐率和并发数通俗意思
案例一: 吞吐率和并发数是两个完全独立的概念。拿银行柜台来举个例子,并发数指同时有多少人往银行柜台涌来。吞吐率则指银行柜台在一段时间内可以服务多少个人
案例二: 一个水龙头开一天一夜,流出10吨水;10个水龙头开1秒钟,流出0.1吨水。当然是一个水龙头的吞吐量大。你能说1个水龙头的出水能力比10个水龙头的强?所以,我们要加单位时间,看谁1秒钟的出水量大。这就是吞吐率 0.1吨水/秒
,报错502)。