Traditional APIs have evolved toward issuing fewer calls that each do more [443, 451]. The new generation of APIs—DirectX 12, Vulkan, Metal—take a different strategy.For these APIs the drivers are streamlined and minimal, with much of the complexity and responsibility for validating the state shifted to the calling application, as well as memory allocation and other functions [249, 1438, 1826]. This redesign in good part was done to minimize draw call and state change overhead, which comes from having to map older APIs to modern GPUs. The other element these new APIs encourage is using multiple CPU processors to call the API.
传统的API已经朝着发出更少的调用而每个调用都做得更多的方向发展[443451]。新一代API DirectX 12、Vulkan、Metal采取了不同的策略。对于这些API,驱动程序是精简和最小化的,验证状态的复杂性和责任大部分转移到调用应用程序,以及内存分配和其他功能[24914381826]。这种重新设计在很大程度上是为了最小化绘制调用和状态更改开销,这是因为必须将旧API映射到现代GPU。这些新API鼓励的另一个元素是使用多个CPU处理器来调用API。
Around 2003 the trend of ever-rising clock speeds for CPUs flattened out at around 3.4 GHz, due to several physical issues such as heat dissipation and power consumption [1725]. These limits gave rise to multiprocessing CPUs, where instead of higher clock rates, more CPUs were put in a single chip. In fact, many small cores provide the best performance per unit area [75], which is the major reason why GPUs themselves are so effective. Creating efficient and reliable programs that exploit concurrency has been the challenge ever since. In this section we will cover the basic concepts of efficient multiprocessing on CPU cores, at the end discussing how graphics APIs have evolved to enable more concurrency within the driver itself.
2003年前后,由于散热和功耗等物理问题,CPU时钟速度不断上升的趋势在3.4GHz左右趋于平稳[1725]。这些限制导致了多处理器CPU,在这种情况下,更多的CPU被放在单个芯片中,而不是更高的时钟速率。事实上,许多小内核提供了最佳的单位面积性能[75],这是GPU本身如此有效的主要原因。从那时起,创建利用并发性的高效可靠的程序一直是一项挑战。在本节中,我们将介绍CPU核上高效多处理的基本概念,最后讨论图形API如何发展以实现驱动程序本身的更多并发性。
Multiprocessor computers can be broadly classified into message-passing architectures and shared memory multiprocessors. In message-passing designs, each processor has its own memory area, and messages are sent between the processors to communicate results. These are not common in real-time rendering. Shared memory multiprocessors are just as they sound; all processors share a logical address space of memory among themselves. Most popular multiprocessor systems use shared memory, and most of these have a symmetric multiprocessing (SMP) design. SMP means that all the processors are identical. A multicore PC system is an example of a symmetric multiprocessing architecture.
多处理器计算机可以大致分为消息传递架构和共享内存多处理器。在消息传递设计中,每个处理器都有自己的存储区域,并且在处理器之间发送消息以传达结果。这些在实时渲染中并不常见。共享内存多处理器就像它们听起来一样;所有处理器在它们之间共享存储器的逻辑地址空间。大多数流行的多处理器系统使用共享内存,其中大多数都有对称多处理器(SMP)设计。SMP意味着所有处理器都是相同的。多核PC系统是对称多处理架构的一个示例。
Here, we will present two general methods for using multiple processors for realtime graphics. The first method—multiprocessor pipelining, also called temporal parallelism— will be covered in more detail than the second—parallel processing, also called spatial parallelism. These two methods are illustrated in Figure 18.8. These two types of parallelism are then brought together with task-based multiprocessing,where the application creates jobs that can each be picked up and processed by an individual core.
在这里,我们将介绍两种使用多个处理器进行实时图形处理的通用方法。第一种方法多处理器流水线(也称为时间并行)将比第二种并行处理(也称为空间并行)更详细地介绍。这两种方法如图18.8所示。然后,这两种类型的并行性与基于任务的多处理结合在一起,应用程序创建作业,每个作业都可以由单个核心拾取和处理。

Figure 18.8. Two different ways of using multiple processors. At the top we show how three processors (CPUs) are used in a multiprocessor pipeline, and at the bottom we show parallel execution on three CPUs. One of the differences between these two implementations is that lower latency can be achieved if the configuration at the bottom is used. On the other hand, it may be easier to use a multiprocessor pipeline. The ideal speedup for both of these configurations is linear, i.e., using n CPUs would give a speedup of n times.
图18.8.使用多个处理器的两种不同方式。在顶部,我们展示了如何在多处理器流水线中使用三个处理器(CPU),在底部,我们展示三个CPU上的并行执行。这两种实现之间的区别之一是,如果使用底部的配置,可以实现更低的延迟。另一方面,使用多处理器流水线可能更容易。这两种配置的理想加速都是线性的,即使用n个CPU可以实现n倍的加速。
18.5.1 Multiprocessor Pipelining多处理器流水线
As we have seen, pipelining is a method for speeding up execution by dividing a job into certain pipeline stages that are executed in parallel. The result from one pipeline stage is passed on to the next. The ideal speedup is n times for n pipeline stages, and the slowest stage (the bottleneck) determines the actual speedup. Up to this point, we have seen pipelining used with a single CPU core and a GPU to run the application,geometry processing, rasterization, and pixel processing in parallel. Pipelining can also be used when multiple processors are available on the host, and in these cases, it is called multiprocess pipelining or software pipelining.
正如我们所看到的,流水线是一种通过将作业划分为并行执行的特定流水线阶段来加快执行速度的方法。来自一个流水线阶段的结果被传递到下一个。理想的加速是n个流水线级的n倍,最慢的级(瓶颈)决定了实际的加速。到目前为止,我们已经看到流水线与单个CPU内核和GPU一起使用,以并行运行应用程序、几何处理、光栅化和像素处理。当主机上有多个处理器可用时,也可以使用流水线,在这些情况下,称为多处理器流水线或软件流水线。
Here we describe one type of software pipelining. Endless variations are possible and the method should be adapted to the particular application. In this example, the application stage is divided into three stages [1508]: APP, CULL, and DRAW. This is coarse-grained pipelining, which means that each stage is relatively long. The APP stage is the first stage in the pipeline and therefore controls the others. It is in this stage that the application programmer can put in additional code that does, for example, collision detection. This stage also updates the viewpoint. The CULL stage can perform:
这里我们描述一种类型的软件流水线。无限变化是可能的,并且该方法应适合特定应用。在本例中,应用阶段分为三个阶段[1508]:APP、CULL和DRAW。这是粗粒度流水线,这意味着每个阶段都相对较长。APP阶段是管道中的第一阶段,因此控制其他阶段。正是在这一阶段,应用程序程序员可以添加额外的代码,例如进行碰撞检测。此阶段还更新视点。CULL阶段可以执行:
• Traversal and hierarchical view frustum culling on a scene graph (Section 19.4).
• Level of detail selection (Section 19.9).
• State sorting, as discussed in Section 18.4.5.
• Finally (and always performed), generation of a simple list of all objects that should be rendered.
•场景图上的遍历和层次视图截头体剔除(第19.4节)。
•详细程度选择(第19.9节)。
•状态分类,如第18.4.5节所述。
•最后(并始终执行),生成应渲染的所有对象的简单列表。
The DRAW stage takes the list from the CULL stage and issues all graphics calls in this list. This means that it simply walks through the list and feeds the GPU.Figure 18.9 shows some examples of how this pipeline can be used.
DRAW阶段从CULL阶段获取列表,并发出该列表中的所有图形调用。这意味着它只需遍历列表并向GPU提供信息。图18.9显示了如何使用该管道的一些示例。
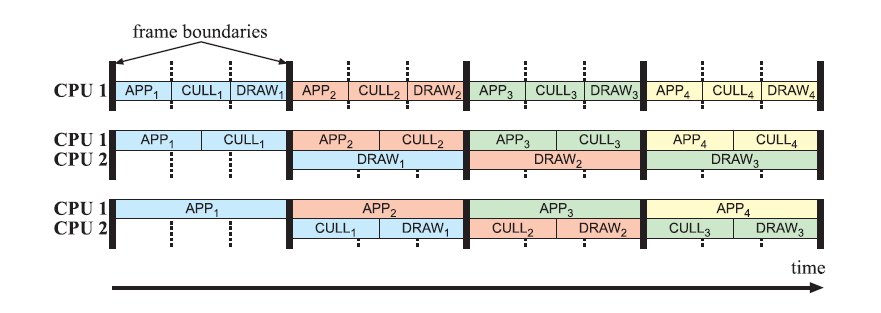
Figure 18.9. Different configurations for a multiprocessor pipeline. The thick lines represent synchronization between the stages, and the subscripts represent the frame number. At the top, a single CPU pipeline is shown. In the middle and at the bottom are shown two different pipeline subdivisions using two CPUs. The middle has one pipeline stage for APP and CULL and one pipeline stage for DRAW. This is a suitable subdivision if DRAW has much more work to do than the others. At the bottom, APP has one pipeline stage and the other two have another. This is suitable if APP has much more work than the others. Note that the bottom two configurations have more time for the APP, CULL, and DRAW stages.
图18.9.多处理器流水线的不同配置。粗线表示阶段之间的同步,下标表示帧号。在顶部,显示了单个CPU管道。中间和底部显示了使用两个CPU的两个不同的管道细分。中间有一个管道级用于APP和CULL,一个管道阶段用于DRAW。如果DRAW要做的工作比其他工作多得多,这是一个合适的细分。在底部,APP有一个流水线阶段,其他两个有另一个。如果应用程序比其他应用程序有更多的工作,这是合适的。请注意,底部两个配置有更多的时间用于APP、CULL和DRAW阶段。
If one processor core is available, then all three stages are run on that core. If two CPU cores are available, then APP and CULL can be executed on one core and DRAW on the other. Another configuration would be to execute APP on one core and CULL and DRAW on the other. Which is the best depends on the workloads for the different stages. Finally, if the host has three cores available, then each stage can be executed on a separate core. This possibility is shown in Figure 18.10.
如果一个处理器内核可用,那么所有三个阶段都在该内核上运行。如果有两个CPU内核可用,则可以在一个内核上执行APP和CULL,在另一个内核中执行DRAW。另一种配置是在一个核心上执行APP,在另一个核心执行CULL和DRAW。哪个最佳取决于不同阶段的工作负载。最后,如果主机有三个可用的核心,那么每个阶段都可以在单独的核心上执行。这种可能性如图18.10所示。

Figure 18.10. At the top, a three-stage pipeline is shown. In comparison to the configurations in Figure 18.9, this configuration has more time for each pipeline stage. The bottom illustration shows a way to reduce the latency: The CULL and the DRAW are overlapped with FIFO buffering in between.
图18.10.顶部显示了三级管道。与图18.9中的配置相比,该配置在每个管道阶段有更多的时间。下图显示了一种减少延迟的方法:CULL和DRAW重叠,中间有FIFO缓冲。
The advantage of this technique is that the throughput, i.e., the rendering speed, increases. The downside is that, compared to parallel processing, the latency is greater. Latency, or temporal delay, is the time it takes from the polling of the user’s actions to the final image [1849]. This should not be confused with frame rate, which is the number of frames displayed per second. For example, say the user is using an untethered head mounted display. The determination of the head’s position may take 10 milliseconds to reach the CPU, then it takes 15 milliseconds to render the frame. The latency is then 25 milliseconds from initial input to display. Even though the frame rate is 66.7 Hz (1/0.015 seconds), if no location prediction or other compensation is performed, interactivity can feel sluggish because of the delay in sending the position changes to the CPU. Ignoring any delay due to user interaction (which is a constant under both systems), multiprocessing has more latency than parallel processing because it uses a pipeline. As is discussed in detail in the next section, parallel processing breaks up the frame’s work into pieces that are run concurrently.
这种技术的优点是吞吐量(即渲染速度)增加。缺点是,与并行处理相比,延迟更大。延迟或时间延迟是指从轮询用户动作到最终图像所需的时间[1849]。这不应与帧速率混淆,帧速率是每秒显示的帧数。例如,假设用户使用的是无限制的头戴式显示器。头部位置的确定可能需要10毫秒才能到达CPU,然后渲染帧需要15毫秒。从初始输入到显示,等待时间为25毫秒。即使帧速率为66.7 Hz(1/0.015秒),如果不执行位置预测或其他补偿,由于向CPU发送位置变化的延迟,交互性可能会感觉迟缓。忽略由于用户交互引起的任何延迟(这在两种系统下都是常数),多处理比并行处理具有更大的延迟,因为它使用流水线。正如在下一节中详细讨论的,并行处理将框架的工作分解为并行运行的部分。
In comparison to using a single CPU on the host, multiprocessor pipelining gives a higher frame rate and the latency is about the same or a little greater due to the cost of synchronization. The latency increases with the number of stages in the pipeline. For a well-balanced application the speedup is n times for n CPUs.
与在主机上使用单个CPU相比,多处理器流水线提供了更高的帧速率,由于同步成本的原因,延迟大约相同或稍大。延迟随着管道中阶段的数量而增加。对于一个平衡良好的应用程序,n个CPU的加速是n倍。
One technique for reducing the latency is to update the viewpoint and other latency-critical parameters at the end of the APP stage [1508]. This reduces the latency by (approximately) one frame. Another way to reduce latency is to execute CULL and DRAW overlapped. This means that the result from CULL is sent over to DRAW as soon as anything is ready for rendering. For this to work, there has to be some buffering, typically a FIFO, between those stages. The stages are stalled on empty and full conditions; i.e., when the buffer is full, then CULL has to stall, and when the buffer is empty, DRAW has to starve. The disadvantage is that techniques such as state sorting cannot be used to the same extent, since primitives have to be rendered as soon as they have been processed by CULL. This latency reduction technique is visualized in Figure 18.10.
减少延迟的一种技术是在APP阶段结束时更新视点和其他延迟关键参数[1508]。这将延迟减少(大约)一帧。另一种减少延迟的方法是重叠执行CULL和DRAW。这意味着一旦准备好进行渲染,就将CULL的结果发送到DRAW。为了实现这一点,这些阶段之间必须有一些缓冲,通常是FIFO。在空载和满载条件下,各阶段均处于停滞状态;i、 例如,当缓冲区已满时,CULL必须暂停,而当缓冲区为空时,DRAW必须饥饿。缺点是,诸如状态排序之类的技术不能在相同程度上使用,因为基本体必须在CULL处理后立即呈现。这种延迟减少技术如图18.10所示。
The pipeline in this figure uses a maximum of three CPUs, and the stages have certain tasks. However, this technique is in no way limited to this configuration—rather, you can use any number of CPUs and divide the work in any way you want.The key is to make a smart division of the entire job to be done so that the pipeline tends to be balanced. The multiprocessor pipelining technique requires a minimum of synchronization in that it needs to synchronize only when switching frames. Additional processors can also be used for parallel processing, which needs more frequent synchronization.
此图中的管道最多使用三个CPU,各个阶段都有特定的任务。然而,这种技术绝不局限于这种配置,相反,您可以使用任意数量的CPU,并以您想要的任何方式分配工作。关键是要对要完成的整个工作进行明智的划分,以便管道趋于平衡。多处理器流水线技术需要最少的同步,因为它只需要在切换帧时进行同步。额外的处理器也可以用于并行处理,这需要更频繁的同步。
18.5.2 Parallel Processing并行处理
A major disadvantage of using a multiprocessor pipeline technique is that the latency tends to increase. For some applications, such as flight simulators, first person shooters,and virtual reality rendering, this is not acceptable. When moving the viewpoint,you usually want instant (next-frame) response but when the latency is long this will not happen. That said, it all depends. If multiprocessing raised the frame rate from 30 FPS with 1 frame latency to 60 FPS with 2 frames latency, the extra frame delay would have no perceptible difference.
使用多处理器流水线技术的一个主要缺点是延迟往往会增加。对于一些应用程序,如飞行模拟器、第一人称射击游戏和虚拟现实渲染,这是不可接受的。移动视点时,通常需要即时(下一帧)响应,但当延迟很长时,这不会发生。也就是说,这一切都取决于。如果多处理将帧速率从1帧延迟的30 FPS提高到2帧延迟的60 FPS,则额外的帧延迟将没有明显的差异。
If multiple processors are available, one can also try to run sections of the code concurrently, which may result in shorter latency. To do this, the program’s tasks must possess the characteristics of parallelism. There are several different methods for parallelizing an algorithm. Assume that n processors are available. Using static assignment [313], the total work package, such as the traversal of an acceleration structure, is divided into n work packages. Each processor then takes care of a work package, and all processors execute their work packages in parallel.When all processors have completed their work packages, it may be necessary to merge the results from the processors. For this to work, the workload must be highly predictable.
如果有多个处理器可用,也可以尝试并发运行代码部分,这可能会缩短延迟。要做到这一点,程序的任务必须具有并行性的特点。有几种不同的算法并行化方法。假设有n个处理器可用。使用静态赋值[313],将整个工作包(如加速结构的遍历)划分为n个工作包。然后,每个处理器处理一个工作包,所有处理器并行执行其工作包。当所有处理者都完成其工作包后,可能需要合并处理者的结果。为了实现这一点,工作量必须是高度可预测的。
When this is not the case, dynamic assignment algorithms that adapt to different workloads may be used [313]. These use one or more work pools. When jobs are generated, they are put into the work pools. CPUs can then fetch one or more jobs from the queue when they have finished their current job. Care must be taken so that only one CPU can fetch a particular job, and so that the overhead in maintaining the queue does not damage performance. Larger jobs mean that the overhead for maintaining the queue becomes less of a problem, but, on the other hand, if the jobs are too large, then performance may degrade due to imbalance in the system—i.e.,one or more CPUs may starve.
当情况并非如此时,可以使用适应不同工作负载的动态分配算法[313]。它们使用一个或多个工作池。生成作业后,它们将被放入工作池。CPU完成当前作业后,可以从队列中提取一个或多个作业。必须注意,只有一个CPU可以获取特定的作业,并且维护队列的开销不会损害性能。更大的作业意味着维护队列的开销问题更小,但另一方面,如果作业太大,则性能可能会由于系统中的不平衡而降低,即一个或多个CPU可能会不足。
As for the multiprocessor pipeline, the ideal speedup for a parallel program running on n processors would be n times. This is called linear speedup. Even though linear speedup rarely happens, actual results can sometimes be close to it.
对于多处理器流水线,在n个处理器上运行的并行程序的理想速度是n倍。这称为线性加速。尽管线性加速很少发生,但实际结果有时可能接近于此。
In Figure 18.8 on page 807, both a multiprocessor pipeline and a parallel processing system with three CPUs are shown. Temporarily assume that these should do the same amount of work for each frame and that both configurations achieve linear speedup.This means that the execution will run three times faster in comparison to serial execution (i.e., on a single CPU). Furthermore, we assume that the total amount of work per frame takes 30 ms, which would mean that the maximum frame rate on a single CPU would be 1/0.03 ≈ 33 frames per second.
在第807页的图18.8中,显示了多处理器流水线和具有三个CPU的并行处理系统。暂时假设这些应该为每个帧做相同的工作量,并且两种配置都实现了线性加速。这意味着与串行执行(即,在单个CPU上)相比,执行速度将快三倍。此外,我们假设每帧的总工作量需要30毫秒,这意味着单个CPU上的最大帧速率为1/0.03≈ 每秒33帧。
The multiprocessor pipeline would (ideally) divide the work into three equal-sized work packages and let each of the CPUs be responsible for one work package. Each work package should then take 10 ms to complete. If we follow the work flow through the pipeline, we will see that the first CPU in the pipeline does work for 10 ms (i.e.,one third of the job) and then sends it on to the next CPU. The first CPU then starts working on the first part of the next frame. When a frame is finally finished, it has taken 30 ms for it to complete, but since the work has been done in parallel in the pipeline, one frame will be finished every 10 ms. So, the latency is 30 ms, and the speedup is a factor of three (30/10), resulting in 100 frames per second.
多处理器流水线(理想情况下)将工作分成三个大小相等的工作包,并让每个CPU负责一个工作包。然后,每个工作包需要10毫秒才能完成。如果我们遵循流水线中的工作流程,我们将看到流水线中第一个CPU工作了10毫秒(即作业的三分之一),然后将其发送到下一个CPU。然后,第一CPU开始处理下一帧的第一部分。当一帧最终完成时,它需要30毫秒才能完成,但由于这项工作是在流水线中并行完成的,因此每10毫秒就会完成一帧。因此,延迟是30毫秒,加速是三倍(30/10),导致每秒100帧。
A parallel version of the same program would also divide the jobs into three work packages, but these three packages will execute at the same time on the three CPUs.This means that the latency will be 10 ms, and the work for one frame will also take 10 ms. The conclusion is that the latency is much shorter when using parallel processing than when using a multiprocessor pipeline.
同一程序的并行版本也会将作业分为三个工作包,但这三个包将在三个CPU上同时执行。这意味着延迟将为10毫秒,一帧的工作也将花费10毫秒。结论是,使用并行处理时的延迟比使用多处理器流水线时的延迟要短得多。
18.5.3 Task-Based Multiprocessing基于任务的多处理
Knowing about pipelining and parallel processing techniques, it is natural to combine both in a single system. If there are only a few processors available, it might make sense to have a simple system of explicitly assigning systems to a particular core.However, given the large number of cores on many CPUs, the trend has been to use task-based multiprocessing. Just as one can create several tasks (also called jobs) for a process that can be parallelized, this idea can be broadened to include pipelining.Any task generated by any core is put into the work pool as it is generated. Any free processor gets a task to work on.
了解流水线和并行处理技术,很自然地将两者结合在一个系统中。如果只有几个处理器可用,那么使用一个简单的系统将系统显式地分配给特定的核心可能是有意义的。然而,考虑到许多CPU上有大量内核,趋势是使用基于任务的多处理。正如可以为一个可以并行化的流程创建多个任务(也称为作业)一样,这个想法可以扩展到包括流水线。任何核心生成的任何任务都会在生成时放入工作池。任何空闲的处理器都有一个任务要处理。
One way to convert to multiprocessing is to take an application’s workflow and determine which systems are dependent on others. See Figure 18.11.
转换为多处理的一种方法是采用应用程序工作流,并确定哪些系统依赖于其他系统。如图18.11所示。

Figure 18.11. Frostbite CPU job graph, with one small zoomed-in part inset [45]. (Figure courtesy of Johan Andersson—Electronic Arts.)
图18.11.Frostbite CPU作业图,一个小的放大部分插图[45]。(图片由Johan Andersson Electronic Arts提供)
Having a processor stall while waiting for synchronization means a task-based version of the application could even become slower due to this cost and the overhead for task management [1854]. However, many programs and algorithms do have a large number of tasks that can be performed at the same time and can therefore benefit.
在等待同步时处理器暂停意味着应用程序的基于任务的版本甚至可能会因为此成本和任务管理开销而变得更慢[1854]。然而,许多程序和算法确实有大量可以同时执行的任务,因此可以受益。
The next step is to determine what parts of each system can be decomposed into tasks. Characteristics of a piece of code that is a good candidate to become a task include [45, 1060, 1854]:
下一步是确定每个系统的哪些部分可以分解为任务。适合成为任务候选的一段代码的特征包括[4510601854]:
• The task has a well-defined input and output.
• The task is independent and stateless when run, and always completes.
• It is not so large a task that it often becomes the only process running.
•任务具有明确定义的输入和输出。
•任务在运行时是独立的、无状态的,并且始终完成。
•任务不是那么大,它往往成为唯一运行的流程。
Languages such as C++11 have facilities built into them for multithreading [1445].On Intel-compatible systems, Intel’s open-source Threading Building Blocks (TBB) is an efficient library that simplifies task generation, pooling, and synchronization [92].
C++11等语言内置了多线程功能[1445]。在与英特尔兼容的系统上,英特尔的开源线程构建块(TBB)是一个高效的库,可以简化任务生成、池化和同步[92]。
Having the application create its own sets of tasks that are multiprocessed, such as simulation, collision detection, occlusion testing, and path planning, is a given when performance is critical [45, 92, 1445, 1477, 1854]. We note here again that there are also times when the GPU cores tend to be idle. For example, these are usually underused during shadow map generation or a depth prepass. During such idle times, compute shaders can be applied to other tasks [1313, 1884]. Depending on the architecture, API, and content, it is sometimes the case that the rendering pipeline cannot keep all the shaders busy, meaning that there is always some pool available for compute shading. We will not tackle the topic of optimizing these, as Lauritzen makes a convincing argument that writing fast and portable compute shaders is not possible, due to hardware differences and language limitations [993]. How to optimize the core rendering pipeline itself is the subject of the next section.
当性能至关重要时,让应用程序创建自己的多处理任务集,如模拟、碰撞检测、遮挡测试和路径规划,这是一个给定的条件[45,92,1445,1477,1854]。我们在此再次注意到,有时GPU内核趋于空闲。例如,这些通常在阴影贴图生成或深度预处理期间使用不足。在这种空闲时间期间,计算着色器可以应用于其他任务[13131884]。根据体系结构、API和内容,有时渲染管道无法使所有着色器保持忙碌,这意味着总有一些池可用于计算着色。我们不会讨论优化这些着色器的问题,因为Lauritzen提出了一个令人信服的论点,即由于硬件差异和语言限制,编写快速和可移植的计算着色器是不可能的[993]。如何优化核心渲染管道本身是下一节的主题。
18.5.4 Graphics API Multiprocessing Support图形API多处理支持
Parallel processing often does not map to hardware constraints. For example, DirectX 10 and earlier allow only one thread to access the graphics driver at a time, so parallel processing for the actual draw stage is more difficult [1477].
并行处理通常不会映射到硬件约束。例如,DirectX 10和更早版本一次只允许一个线程访问图形驱动程序,因此实际绘制阶段的并行处理更加困难[1477]。
There are two operations in a graphics driver that can potentially use multiple processors: resource creation and render-related calls. Creating resources such as textures and buffers can be purely CPU-side operations and so are naturally parallelizable.That said, creation and deletion can also be blocking tasks, as they might trigger operations on the GPU or need a particular device context. In any case, older APIs were created before consumer-level multiprocessing CPUs existed, so needed to be rewritten to support such concurrency.
图形驱动程序中有两种操作可能使用多个处理器:资源创建和渲染相关调用。创建诸如纹理和缓冲区之类的资源可以是纯粹的CPU端操作,因此自然是可并行的。也就是说,创建和删除也可能是阻塞任务,因为它们可能会触发GPU上的操作或需要特定的设备上下文。无论如何,旧的API是在消费者级多处理CPU存在之前创建的,因此需要重写以支持这种并发性。
A key construct used is the command buffer or command list, which harks back to an old OpenGL concept called the display list. A command buffer (CB) is a list of API state change and draw calls. Such lists can be created, stored, and replayed as desired.They may also be combined to form longer command buffers. Only a single CPU processor communicates with the GPU via the driver and so can send it a CB for execution. However, every processor (including this single processor) can create or concatenate stored command buffers in parallel.
使用的一个关键结构是命令缓冲区或命令列表,它可以追溯到旧的OpenGL概念,称为显示列表。命令缓冲区(CB)是API状态更改和绘制调用的列表。可以根据需要创建、存储和重放这些列表。它们也可以组合起来形成更长的命令缓冲区。只有一个CPU处理器通过驱动程序与GPU通信,因此可以向其发送CB以供执行。但是,每个处理器(包括这个单个处理器)都可以并行创建或连接存储的命令缓冲区。
In DirectX 11, for example, the processor that communicates with the driver sends its render calls to what is called the immediate context. The other processors each use a deferred context to generate command buffers. As the name implies, these are not directly sent to the driver. Instead, these are sent to the immediate context for rendering. See Figure 18.12. Alternately, a command buffer can be sent to another deferred context, which inserts it into its own CB. Beyond sending a command buffer to the driver for execution, the main operations that the immediate context can perform that the deferred cannot are GPU queries and readbacks. Otherwise, command buffer management looks the same from either type of context.
例如,在DirectX 11中,与驱动程序通信的处理器将其渲染调用发送到所谓的即时上下文。其他处理器都使用延迟上下文来生成命令缓冲区。顾名思义,这些信息不会直接发送给驾驶员。相反,它们被发送到直接上下文进行渲染。参见图18.12。或者,可以将命令缓冲区发送到另一个延迟上下文,后者将其插入到自己的CB中。除了将命令缓冲区发送给驱动程序以供执行之外,直接上下文可以执行的延迟无法执行的主要操作是GPU查询和读回。否则,命令缓冲区管理在两种类型的上下文中看起来都是一样的。

Figure 18.12. Command buffers. Each processor uses its deferred context, shown in orange, to create and populate one or more command buffers, shown in blue. Each command buffer is sent to Process #1, which executes these as desired, using its immediate context, shown in green. Process #1 can do other operations while waiting for command buffer N from Process #3. (After Zink et al. [1971].)
图18.12.命令缓冲区。每个处理器都使用其延迟上下文(以橙色显示)来创建和填充一个或多个命令缓冲区(以蓝色显示)。每个命令缓冲区都被发送到进程#1,进程#1根据需要使用其直接上下文执行这些命令,如绿色所示。进程#1可以在等待来自进程#3的命令缓冲区N时执行其他操作
An advantage of command buffers, and their predecessor, display lists, is that they can be stored and replayed. Command buffers are not fully bound when created, which aids in their reuse. For example, say a CB contains a view matrix. The camera moves, so the view matrix changes. However, the view matrix is stored in a constant buffer. The constant buffer’s contents are not stored in the CB, only the reference to them. The contents of the constant buffer can be changed without having to rebuild the CB. Determining how best to maximize parallelism involves choosing a suitable granularity—per view, per object, per material—to create, store, and combine command buffers [1971].
命令缓冲区及其前身显示列表的一个优点是可以存储和重放它们。命令缓冲区在创建时没有完全绑定,这有助于它们的重用。例如,假设CB包含视图矩阵。相机移动,因此视图矩阵发生变化。然而,视图矩阵存储在恒定缓冲区中。常量缓冲区的内容不存储在CB中,只有对它们的引用。可以更改常量缓冲区的内容,而无需重建CB。确定如何最好地最大化并行性涉及到为每个视图、每个对象、每个材质选择合适的粒度来创建、存储和组合命令缓冲区[1971]。
Such multithreading draw systems existed for years before command buffers were made a part of modern APIs [1152, 1349, 1552, 1554]. API support makes the process simpler and lets more tools work with the system created. However, command lists do have creation and memory costs associated with them. Also, the expense of mapping an API’s state settings to the underlying GPU is still a costly operation with DirectX 11 and OpenGL, as discussed in Section 18.4.2. Within these systems command buffers can help when the application is the bottleneck, but can be detrimental when the driver is.
在命令缓冲区成为现代API的一部分之前,这种多线程绘制系统已经存在多年[1152134915521554]。API支持使流程更简单,并允许更多工具与创建的系统一起工作。然而,命令列表确实有与之相关的创建和内存成本。此外,使用DirectX 11和OpenGL,将API的状态设置映射到底层GPU的开销仍然是一项昂贵的操作,如第18.4.2节所述。在这些系统中,命令缓冲区可以在应用程序遇到瓶颈时有所帮助,但在驱动程序遇到瓶颈的情况下可能会有害。
Certain semantics in these earlier APIs did not allow the driver to parallelize various operations, which helped motivate the development of Vulkan, DirectX 12, and Metal. A thin draw submission interface that maps well to modern GPUs minimizes the driver costs of these newer APIs. Command buffer management, memory allocation, and synchronization decisions become the responsibility of the application instead of the driver. In addition, command buffers with these newer APIs are validated once when formed, so repeated playback has less overhead than those used with earlier APIs such as DirectX 11. All these elements combine to improve API efficiency,allow multiprocessing, and lessen the chances that the driver is the bottleneck.
这些早期API中的某些语义不允许驱动程序并行化各种操作,这有助于推动Vulkan、DirectX 12和Metal的开发。一个可以很好地映射到现代GPU的精简绘图提交界面将这些新API的驱动程序成本降至最低。命令缓冲区管理、内存分配和同步决策由应用程序而不是驱动程序负责。此外,这些更新的API的命令缓冲区在形成时会被验证一次,因此重复播放的开销比以前的API(如DirectX 11)要小。所有这些元素结合起来可以提高API效率,允许多处理,并减少驱动程序成为瓶颈的机会。
Further Reading and Resources
Mobile devices can have a different balance of where time is spent, especially if they use a tile-based architecture. Merry [1200] discusses these costs and how to use this type of GPU effectively. Pranckeviˇcius and Zioma [1433] provide an in-depth presentation on many aspects of optimizing for mobile devices. McCaffrey [1156] compares mobile versus desktop architectures and performance characteristics. Pixel shading is often the largest cost on mobile GPUs. Sathe [1545] and Etuaho [443] discuss shader precision issues and optimization on mobile devices.
移动设备可以有不同的时间平衡,特别是如果它们使用基于瓦片的架构。Merry[1200]讨论了这些成本以及如何有效地使用这类GPU。Pranckeviís和Zioma[1433]对移动设备优化的许多方面进行了深入介绍。McCaffrey[1156]比较了移动与桌面架构和性能特征。像素着色通常是移动GPU上的最大成本。Sathe[1545]和Etuaho[443]讨论了移动设备上的着色器精度问题和优化。
For the desktop, Wiesendanger [1882] gives a thorough walkthrough of a modern game engine’s architecture. O’Donnell [1313] presents the benefits of a graph-based rendering system. Zink et al. [1971] discuss DirectX 11 in depth. De Smedt [331] provides guidance as to the common hotspots found in video games, including optimizations for DirectX 11 and 12, for multiple-GPU configurations, and for virtual reality.Coombes [291] gives a rundown of DirectX 12 best practices, and Kubisch [946] provides a guide for when to use Vulkan. There are numerous presentations about porting from older APIs to DirectX 12 and Vulkan [249, 536, 699, 1438]. By the time you read this, there will undoubtedly be more. Check IHV developer sites, such as NVIDIA, AMD, and Intel; the Khronos Group; and the web at large, as well as this book’s website.
对于桌面,Wiesendanger[1882]对现代游戏引擎的架构进行了全面的介绍。O'Donnell[1313]介绍了基于图形的渲染系统的优点。Zink等人[1971]深入讨论了DirectX 11。De Smedt[331]为视频游戏中常见的热点提供了指导,包括DirectX 11和12、多GPU配置和虚拟现实的优化。Coombes[291]简要介绍了DirectX 12的最佳实践,Kubisch[946]提供了何时使用Vulkan的指南。有许多关于从旧API移植到DirectX 12和Vulkan的演示[249、536、699、1438]。当你读到这篇文章时,毫无疑问会有更多。查看IHV开发者网站,如NVIDIA、AMD和Intel;Khronos集团;以及本书的网站。
Though a little dated, Cebenoyan’s article [240] is still relevant. It gives an overview of how to find the bottleneck and techniques to improve efficiency. Some popular optimization guides for C++ are Fog’s [476] and Isensee’s [801], free on the web. Hughes et al. [783] provide a modern, in-depth discussion of how to use trace tools and GPUView to analyze where bottlenecks occur. Though focused on virtual reality systems, the techniques discussed are applicable to any Windows-based machine.Sutter [1725] discusses how CPU clock rates leveled out and multiprocessor chipsets arose. For more on why this change occurred and for information on how chips are designed, see the in-depth report by Asanovic et al. [75]. Foley [478] discusses various forms of parallelism in the context of graphics application development. Game Engine Gems 2 [1024] has several articles on programming multithreaded elements for game engines. Preshing [1445] explains how Ubisoft uses multithreading and gives specifics on using C++11’s threading support. Tatarchuk [1749, 1750] gives two detailed presentations on the multithreaded architecture and shading pipeline used for the game Destiny.
尽管有点过时,Cebenoyan的文章[240]仍然相关。它概述了如何找到瓶颈和提高效率的技术。一些流行的C++优化指南是Fog的[476]和Isensee的[801],在网上免费提供。Hughes等人[783]对如何使用跟踪工具和GPUView分析瓶颈发生的位置进行了现代深入的讨论。尽管关注于虚拟现实系统,但所讨论的技术适用于任何基于Windows的机器。Sutter[1725]讨论了CPU时钟速率如何均衡以及多处理器芯片组的产生。有关这种变化发生的原因以及芯片设计方式的更多信息,请参见Asanovic等人的深入报告。[75]。Foley[478]讨论了图形应用程序开发背景下的各种并行形式。Game Engine Gems 2[1024]有几篇关于为游戏引擎编程多线程元素的文章。Preshing[1445]解释了育碧如何使用多线程,并给出了使用C++11的线程支持的细节。Tatarchuk[17491750]对游戏《命运》中使用的多线程架构和着色管道进行了两次详细介绍。