1 申请下载模型权限
https://ai.meta.com/resources/models-and-libraries/llama-downloads/
稍微认证填一填,我这次大概10分钟左右给我通过了
邮件内容如下:

2 下载llama源码
git clone [email protected]:facebookresearch/llama.git
3 下载模型
使用源码里面的download.sh进行下载
如下图

第一步让你输入邮件里面那个授权url,很长,https://download.llamameta.net开头
第二步让你输入想要下载的模型名称,这里下载的是70B-chat
之后会下载几个LICENSE和tokenizer.model等
再之后就是我们最需要的模型文件了。如下图

4 下载花絮
2023-7-22 11:20:30,开始下载的时候是2023-7-21 17:30,过去这么久,下载了不少模型了,但是刚刚发现报错了。。。。
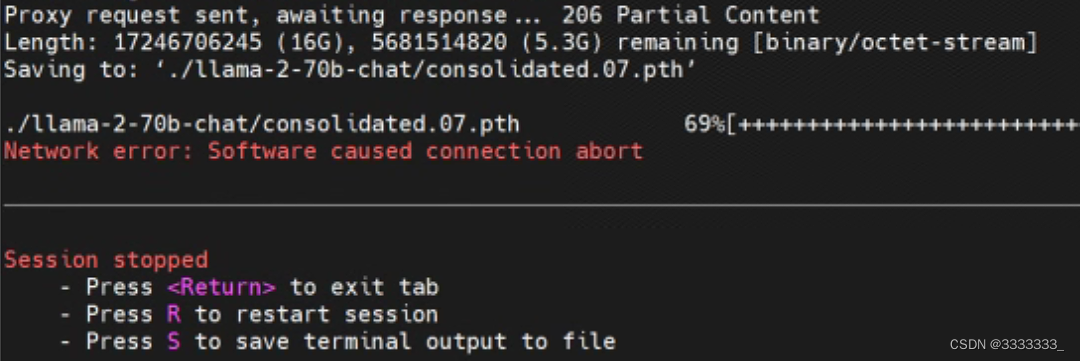
不知道能不能继续
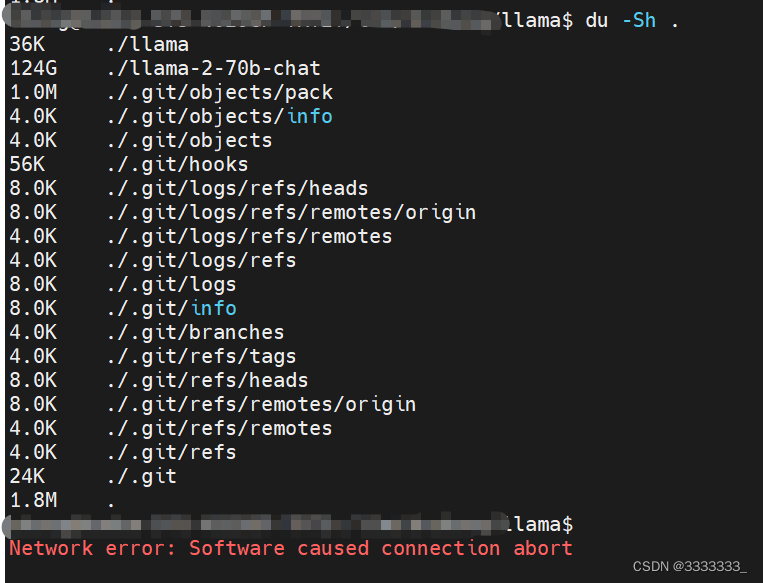
然后重新执行download.sh脚本,发现会重新下载已经下载过的模型,ε=(´ο`*)))唉!!!!
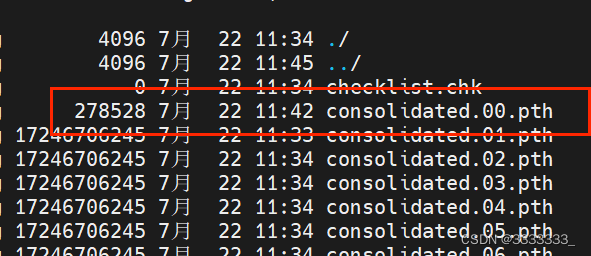
只能改下源码,跳过已经下载过的。
我这里原本下载好了00 01 02 03 04 05 06,07也有,由于07是最后一个,不确定下载完成没,所以也当做没下载,另外00在我重试download.sh脚本的时候覆盖了,也是不完整的,所以我把download.sh脚本改为如下图
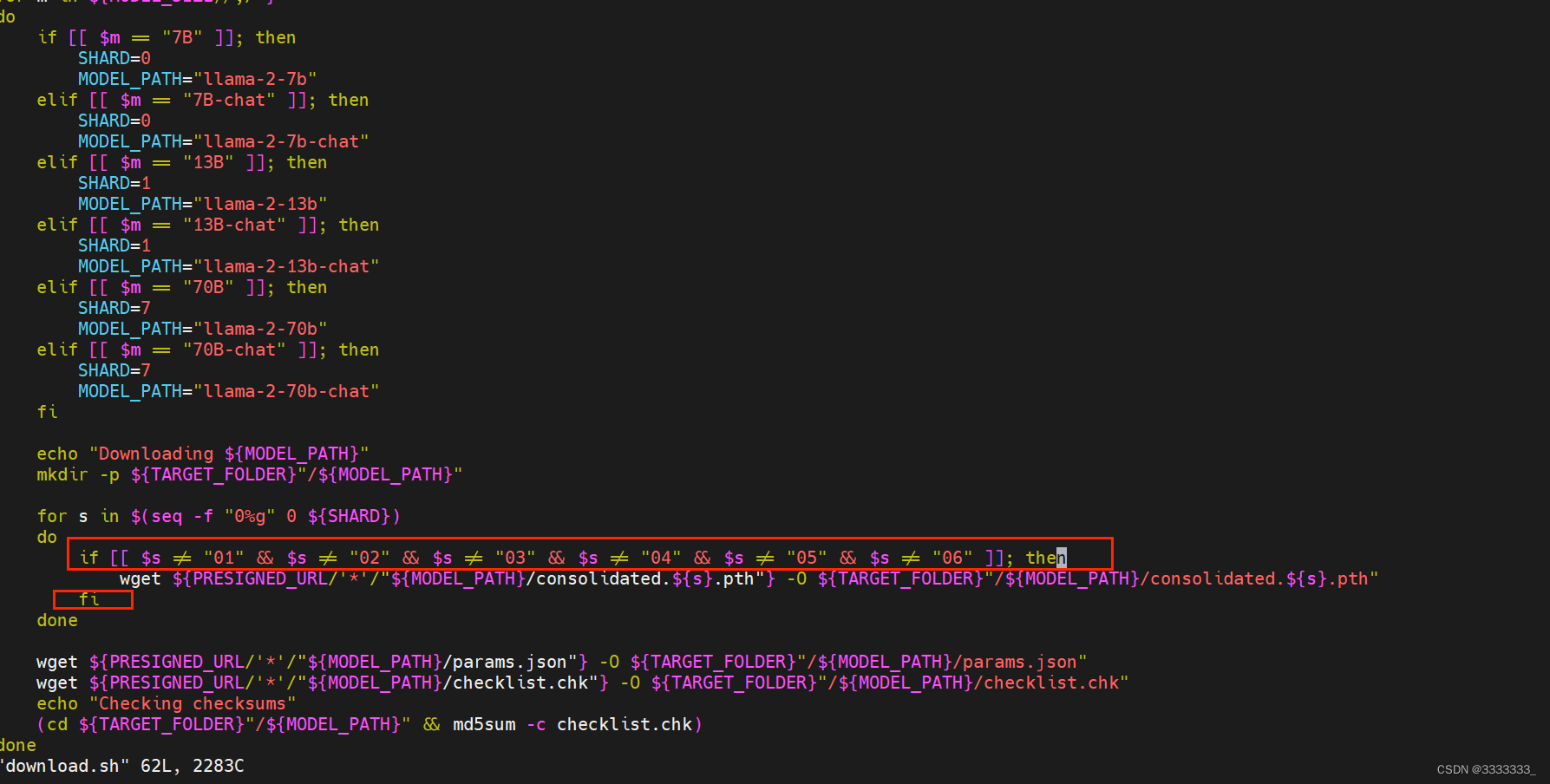
if [[ $s != "01" && $s != "02" && $s != "03" && $s != "04" && $s != "05" && $s != "06" ]]
wget xxxx
fi
2023-7-22 14:50:21总算下载完成
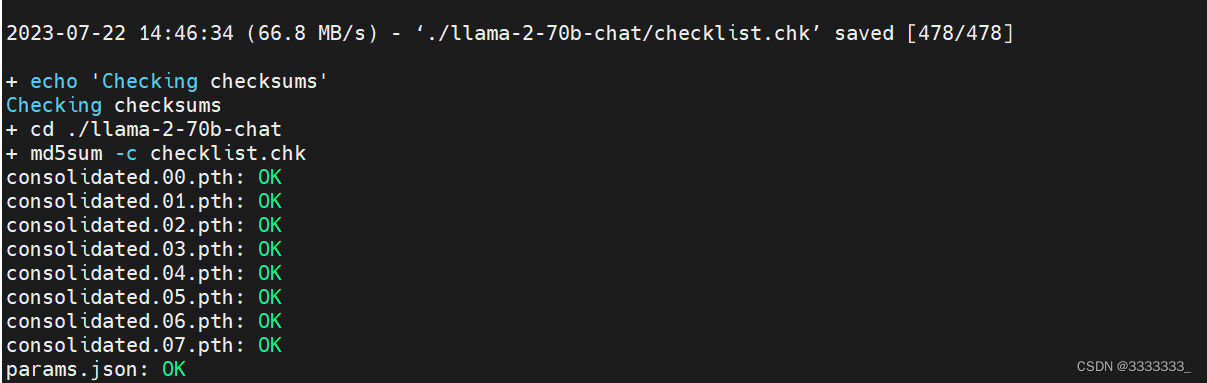
模型大概129G

5 跑官方demo
2023-7-24 22:10

官方说了这里需要8个MP,所以我跑的时候指定了8个GPU
CUDA_VISIBLE_DEVICES=1,2,3,4,6,7,8,9 torchrun --nproc_per_node 8 --master_port=29501 example_chat_completion.py --ckpt_dir llama-2-70b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
启动命令后,查看GPU状态,如下图

查看终端输出
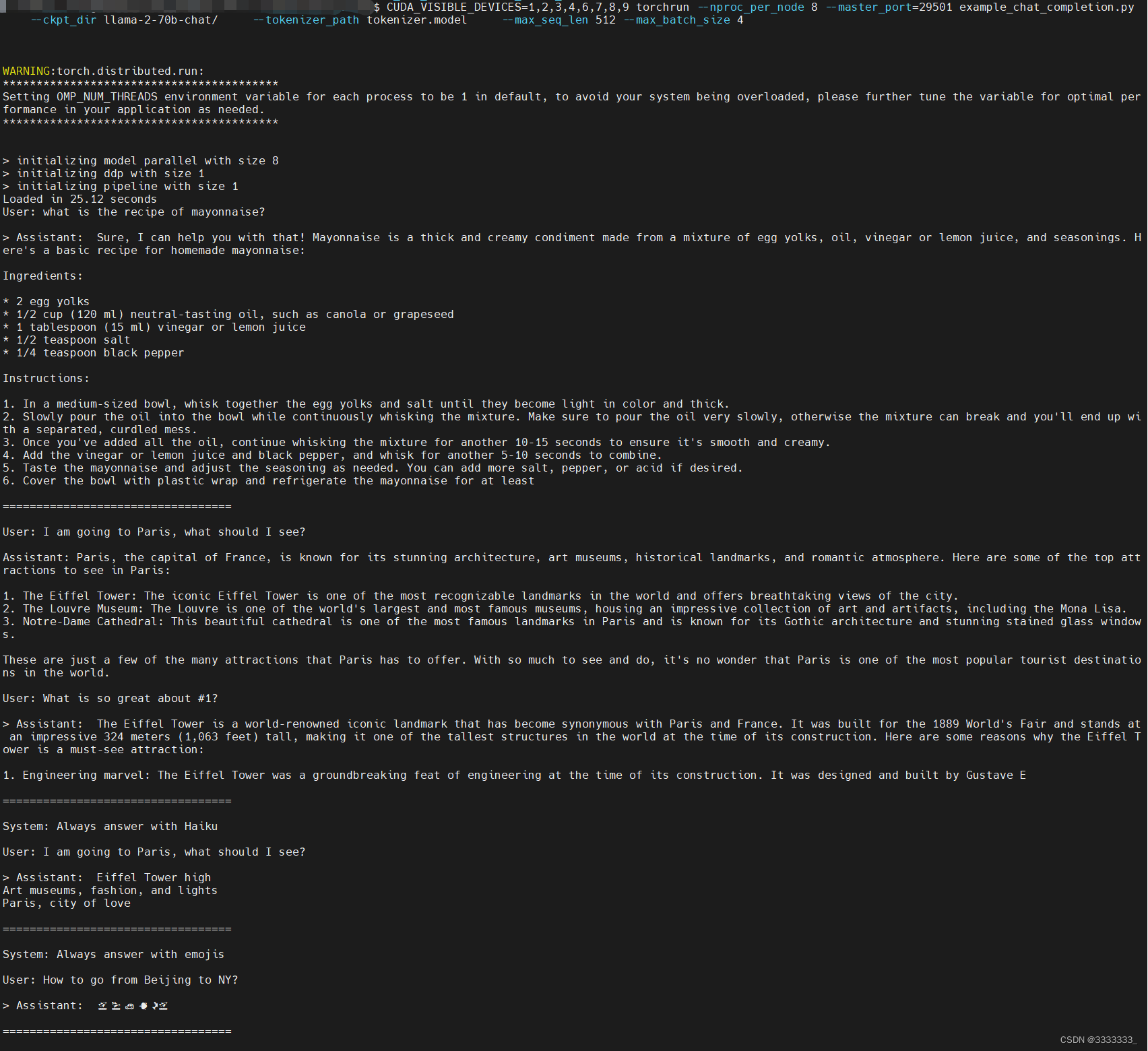
很顺利的运行了!
6 微调
后续补充