最近在试mmseg项目中各种模型的参数调整实验,关注到一个class_weight参数,按照官网说明,这个参数是可以调节样本不平衡带来的拟合问题,提升算法精度的一个手段。一般实现在config文件中的decode_head中,默认所有类别样本的class_weight权重是一样的。下面就以例子来进行说明。
../configs/_base_/models/ann_r50-d8.py
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='ANNHead',
in_channels=[1024, 2048],
in_index=[2, 3],
channels=512,
project_channels=256,
query_scales=(1, ),
key_pool_scales=(1, 3, 6, 8),
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))可以看到,默认的numclass=19,即表示19类中每类样本的class_weight贡献值是相等的。

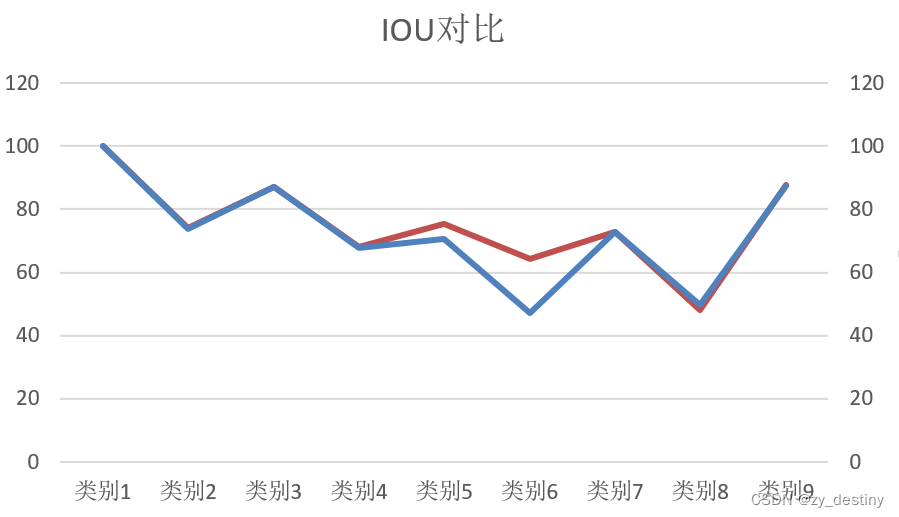
根据样本数量来 更改loss_weight的权重:假如num_classes=9,且样本分布不平衡,为下图所示这样:

即可根据样本分布来合理调整类别损失权重,样本数量越少,就增加其class_weight权重,反之样本量越大,其class_weight权重就随之减少,但是不能增加或减少的太多,会导致模型训练不收敛。不仅没有提升模型性能,反而降低了。
更改class_weight为:
decode_head=dict(
type='ANNHead',
in_channels=[1024, 2048],
in_index=[2, 3],
channels=512,
project_channels=256,
query_scales=(1, ),
key_pool_scales=(1, 3, 6, 8),
dropout_ratio=0.1,
num_classes=9,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
class_weight=[
0.8373, 0.918, 1.166, 0.9539, 1.1766, 0.1869, 0.9954, 1.1489,1.0152
])),修改class_weight的结果前后对比(红色为修改后)