net_device 结构体
Linux 内核使用 net_device 结构体表示一个具体的网络设备,net_device 是整个网络驱动的
灵魂。网络驱动的核心就是初始化 net_device 结构体中的各个成员变量,然后将初始化完成以
后的 net_device 注册到 Linux 内核中。net_device 结构体定义在 include/linux/netdevice.h 中,
net_device 是一个庞大的结构体,内容如下(有缩减):
struct net_device {
char name[IFNAMSIZ];
struct hlist_node name_hlist;
char *ifalias;
/*
* I/O specific fields
* FIXME: Merge these and struct ifmap into one
*/
unsigned long mem_end;
unsigned long mem_start;
unsigned long base_addr;
int irq;
atomic_t carrier_changes;
/*
* Some hardware also needs these fields (state,dev_list,
* napi_list,unreg_list,close_list) but they are not
* part of the usual set specified in Space.c.
*/
unsigned long state;
struct list_head dev_list;
struct list_head napi_list;
struct list_head unreg_list;
struct list_head close_list;
......
const struct net_device_ops *netdev_ops;
const struct ethtool_ops *ethtool_ops;
#ifdef CONFIG_NET_SWITCHDEV
const struct swdev_ops *swdev_ops;
#endif
const struct header_ops *header_ops;
unsigned int flags;
......
unsigned char if_port;
unsigned char dma;
unsigned int mtu;
unsigned short type;
unsigned short hard_header_len;
unsigned short needed_headroom;
unsigned short needed_tailroom;
/* Interface address info. */
unsigned char perm_addr[MAX_ADDR_LEN];
unsigned char addr_assign_type;
unsigned char addr_len;
......
/*
* Cache lines mostly used on receive path (including
eth_type_trans())
*/
unsigned long last_rx;
/* Interface address info used in eth_type_trans() */
unsigned char *dev_addr;
#ifdef CONFIG_SYSFS
struct netdev_rx_queue *_rx;
unsigned int num_rx_queues;
unsigned int real_num_rx_queues;
#endif
......
/*
* Cache lines mostly used on transmit path
*/
struct netdev_queue *_tx ____cacheline_aligned_in_smp;
unsigned int num_tx_queues;
unsigned int real_num_tx_queues;
struct Qdisc *qdisc;
unsigned long tx_queue_len;
spinlock_t tx_global_lock;
int watchdog_timeo;
......
/* These may be needed for future network-power-down code. */
/*
* trans_start here is expensive for high speed devices on SMP,
* please use netdev_queue->trans_start instead.
*/
unsigned long trans_start;
......
struct phy_device *phydev;
struct lock_class_key *qdisc_tx_busylock;
};下面介绍一些关键的成员变量,如下:
name 是网络设备的名字。
mem_end 是共享内存结束地址。
mem_start 是共享内存起始地址。
base_addr 是网络设备 I/O 地址。
irq 是网络设备的中断号。
dev_list 是全局网络设备列表。
napi_list 是 napi 网络设备的列表入口。
unreg_list 是注销(unregister)的网络设备列表入口。
close_list 是关闭的网络设备列表入口。
netdev_ops 是网络设备的操作集函数,包含了一系列的网络设备操作回调函数,
类似字符设备中的 file_operations,稍后会讲解 netdev_ops 结构体。
ethtool_ops 是网络管理工具相关函数集,用户空间网络管理工具会调用此结构体
中的相关函数获取网卡状态或者配置网卡。
header_ops 是头部的相关操作函数集,比如创建、解析、缓冲等。
flags 是网络接口标志,标志类型定义在 include/uapi/linux/if.h 文件中,为一个枚
举类型,内容如下:
enum net_device_flags {
IFF_UP = 1<<0, /* sysfs */
IFF_BROADCAST = 1<<1, /* volatile */
IFF_DEBUG = 1<<2, /* sysfs */
IFF_LOOPBACK = 1<<3, /* volatile */
IFF_POINTOPOINT = 1<<4, /* volatile */
IFF_NOTRAILERS = 1<<5, /* sysfs */
IFF_RUNNING = 1<<6, /* volatile */
IFF_NOARP = 1<<7, /* sysfs */
IFF_PROMISC = 1<<8, /* sysfs */
IFF_ALLMULTI = 1<<9, /* sysfs */
IFF_MASTER = 1<<10, /* volatile */
IFF_SLAVE = 1<<11, /* volatile */
IFF_MULTICAST = 1<<12, /* sysfs */
IFF_PORTSEL = 1<<13, /* sysfs */
IFF_AUTOMEDIA = 1<<14, /* sysfs */
IFF_DYNAMIC = 1<<15, /* sysfs */
IFF_LOWER_UP = 1<<16, /* volatile */
IFF_DORMANT = 1<<17, /* volatile */
IFF_ECHO = 1<<18, /* volatile */
};继续回到示例代码接着看 net_device 结构体。
if_port 指定接口的端口类型,如果设备支持多端口的话就通过 if_port 来指定所使用的端口类型。可选的端口类型定义在 include/uapi/linux/netdevice.h 中,为一个枚举类型,如下所示:
enum {
IF_PORT_UNKNOWN = 0,
IF_PORT_10BASE2,
IF_PORT_10BASET,
IF_PORT_AUI,
IF_PORT_100BASET,
IF_PORT_100BASETX,
IF_PORT_100BASEFX
};dma 是网络设备所使用的 DMA 通道,不是所有的设备都会用到 DMA。
mtu 是网络最大传输单元,为 1500。
type 用于指定 ARP 模块的类型,以太网的 ARP 接口为 ARPHRD_ETHER,Linux
内核所支持的 ARP 协议定义在 include/uapi/linux/if_arp.h 中,大家自行查阅。
perm_addr 是永久的硬件地址,如果某个网卡设备有永久的硬件地址,那么就会填充 perm_addr
addr_len 是硬件地址长度。
last_rx 是最后接收的数据包时间戳,记录的是 jiffies。
dev_addr 也是硬件地址,是当前分配的 MAC 地址,可以通过软件修改。
_rx 是接收队列。
num_rx_queues 是接收队列数量,在调用 register_netdev 注册网络设备的时候会
分配指定数量的接收队列。
real_num_rx_queues 是当前活动的队列数量。
_tx 是发送队列。
num_tx_queues 是发送队列数量,通过 alloc_netdev_mq 函数分配指定数量的发
送队列。
real_num_tx_queues 是当前有效的发送队列数量。
trans_start 是最后的数据包发送的时间戳,记录的是 jiffies。
phydev 是对应的 PHY 设备。
1 、申请 net_device
编写网络驱动的时候首先要申请 net_device,使用 alloc_netdev 函数来申请 net_device,这
是一个宏,宏定义如下:
define alloc_netdev(sizeof_priv, name, name_assign_type, setup) \
alloc_netdev_mqs(sizeof_priv, name, name_assign_type, setup, 1, 1)可以看出 alloc_netdev 的本质是 alloc_netdev_mqs 函数,此函数原型如下
struct net_device * alloc_netdev_mqs ( int sizeof_priv,
const char *name,void (*setup) (struct net_device *)),unsigned int txqs,
unsigned int rxqs);函数参数和返回值含义如下:
sizeof_priv :私有数据块大小。
name :设备名字。
setup :回调函数,初始化设备的设备后调用此函数。
txqs :分配的发送队列数量。
rxqs :分配的接收队列数量。
返回值:如果申请成功的话就返回申请到的 net_device 指针,失败的话就返回 NULL。
事实上网络设备有多种,大家不要以为就只有以太网一种。Linux 内核内核支持的网络接
口有很多,比如光纤分布式数据接口(FDDI)、以太网设备(Ethernet)、红外数据接口(InDA)、高
性能并行接口(HPPI)、CAN 网络等。内核针对不同的网络设备在 alloc_netdev 的基础上提供了
一层封装,比如我们本章讲解的以太网,针对以太网封装的 net_device 申请函数是 alloc_etherdev
和,这也是一个宏,内容如下:
#define alloc_etherdev(sizeof_priv) alloc_etherdev_mq(sizeof_priv, 1)
#define alloc_etherdev_mq(sizeof_priv, count)
alloc_etherdev_mqs(sizeof_priv, count, count)可以看出,alloc_etherdev 最终依靠的是 alloc_etherdev_mqs 函数,此函数就是对alloc_netdev_mqs 的简单封装,函数内容如下:
struct net_device *alloc_etherdev_mqs(int sizeof_priv,
unsigned int txqs,
unsigned int rxqs)
{
return alloc_netdev_mqs(sizeof_priv, "eth%d", NET_NAME_UNKNOWN,
ether_setup, txqs, rxqs);
}第 5 行调用 alloc_netdev_mqs 来申请 net_device,注意这里设置网卡的名字为“eth%d”,这
是格式化字符串,大家进入开发板的 linux 系统以后看到的“eth0”、“eth1”这样的网卡名字就
是从这里来的。同样的,这里设置了以太网的 setup 函数为 ether_setup,不同的网络设备其 setup
函数不同,比如 CAN 网络里面 setup 函数就是 can_setup
ether_setup 函数会对 net_device 做初步的初始化,函数内容如下所示:
void ether_setup(struct net_device *dev)
{
dev->header_ops = ð_header_ops;
dev->type = ARPHRD_ETHER;
dev->hard_header_len = ETH_HLEN;
dev->mtu = ETH_DATA_LEN;
dev->addr_len = ETH_ALEN;
dev->tx_queue_len = 1000; /* Ethernet wants good queues */
dev->flags = IFF_BROADCAST|IFF_MULTICAST;
dev->priv_flags |= IFF_TX_SKB_SHARING;
eth_broadcast_addr(dev->broadcast);
}关于 net_device 的申请就讲解到这里,对于网络设备而言,使用 alloc_etherdev alloc_etherdev_mqs 来申请 net_device。NXP 官方编写的网络驱动就是采用 alloc_etherdev_mqs来申请 net_device。
2、删除net_device
当我们注销网络驱动的时候需要释放掉前面已经申请到的 net_device,释放函数为free_netdev,函数原型如下:
void free_netdev(struct net_device *dev)
函数参数和返回值含义如下:
dev:要释放掉的 net_device 指针。
返回值:无。
3、注册net_device
net_device 申请并初始化完成以后就需要向内核注册 net_device,要用到函数 register_netdev,函数原型如下:
int register_netdev(struct net_device *dev)
函数参数和返回值含义如下:
dev:要注册的 net_device 指针。
返回值:无
net_device_ops 结构体
net_device 有个非常重要的成员变量:netdev_ops,为 net_device_ops 结构体指针类型,这就是网络设备的操作集。net_device_ops 结构体定义在 include/linux/netdevice.h 文件中,net_device_ops 结构体里面都是一些以“ndo_”开头的函数,这些函数就需要网络驱动编写人员去实现,不需要全部都实现,根据实际驱动情况实现其中一部分即可。结构体内容如下所示(结构体比较大,这里有缩减):
示例代码 69.3.2.1 net_device_ops 结构体
struct net_device_ops {
int (*ndo_init)(struct net_device *dev);
void (*ndo_uninit)(struct net_device *dev);
int (*ndo_open)(struct net_device *dev);
int (*ndo_stop)(struct net_device *dev);
netdev_tx_t (*ndo_start_xmit) (struct sk_buff *skb, struct net_device *dev);
u16 (*ndo_select_queue)(struct net_device *dev, struct sk_buff *skb,
void *accel_priv,select_queue_fallback_t fallback);
void (*ndo_change_rx_flags)(struct net_device *dev,int flags);
void (*ndo_set_rx_mode)(struct net_device *dev);
int (*ndo_set_mac_address)(struct net_device *dev,void *addr);
int (*ndo_validate_addr)(struct net_device *dev);
int (*ndo_do_ioctl)(struct net_device *dev,struct ifreq *ifr, int cmd);
int (*ndo_set_config)(struct net_device *dev,struct ifmap *map);
int (*ndo_change_mtu)(struct net_device *dev,int new_mtu);
int (*ndo_neigh_setup)(struct net_device *dev,struct neigh_parms *);
void (*ndo_tx_timeout) (struct net_device *dev);
#ifdef CONFIG_NET_POLL_CONTROLLER
void (*ndo_poll_controller)(struct net_device *dev);
int (*ndo_netpoll_setup)(struct net_device *dev,struct netpoll_info *info);
void (*ndo_netpoll_cleanup)(struct net_device *dev);
#endif
int (*ndo_set_features)(struct net_device *dev,netdev_features_t features);
}第 3 行:ndo_init 函数,当第一次注册网络设备的时候此函数会执行,设备可以在此函数中做一些需要推后初始化的内容,不过一般驱动中不使用此函数,虚拟网络设备可能会使用。
第 4行:ndo_uninit 函数,卸载网络设备的时候此函数会执行。
第 5行:ndo_open 函数,打开网络设备的时候此函数会执行,网络驱动程序需要实现此函数,非常重要!以 NXP 的 I.MX 系列 SOC 网络驱动为例,会在此函数中做如下工作:
·使能网络外设时钟。
·申请网络所使用的环形缓冲区。
·初始化 MAC 外设。
·绑定接口对应的 PHY。
·如果使用 NAPI 的话要使能 NAPI 模块,通过 napi_enable 函数来使能。
·开启 PHY。·调用 netif_tx_start_all_queues 来使能传输队列,也可能调用 netif_start_queue 函数。
·……
第 6行:ndo_stop 函数,关闭网络设备的时候此函数会执行,网络驱动程序也需要实现此函数。以 NXP 的 I.MX 系列 SOC 网络驱动为例,会在此函数中做如下工作:
·停止 PHY。 ·停止 NAPI 功能。 ·停止发送功能。 ·关闭 MAC。 ·断开 PHY 连接。 ·关闭网络时钟。 ·释放数据缓冲区。 ·……
第 7 行:ndo_start_xmit 函数,当需要发送数据的时候此函数就会执行,此函数有一个参数为 sk_buff 结构体指针,sk_buff 结构体在 Linux 的网络驱动中非常重要,sk_buff 保存了上层传递给网络驱动层的数据。也就是说,要发送出去的数据都存在了 sk_buff 中,关于 sk_buff 稍后会做详细的讲解。如果发送成功的话此函数返回 NETDEV_TX_OK,如果发送失败了就返回NETDEV_TX_BUSY,如果发送失败了我们就需要停止队列。
第 8 行:ndo_select_queue 函数,当设备支持多传输队列的时候选择使用哪个队列。
第11行:ndo_set_rx_mode 函数,此函数用于改变地址过滤列表,根据 net_device 的 flags成员变量来设置 SOC 的网络外设寄存器。比如 flags 可能为 IFF_PROMISC、IFF_ALLMULTI 或IFF_MULTICAST,分别表示混杂模式、单播模式或多播模式。
第 12 行:ndo_set_mac_address 函数,此函数用于修改网卡的 MAC 地址,设置 net_device的 dev_addr 成员变量,并且将 MAC 地址写入到网络外设的硬件寄存器中
第 13 行:ndo_validate_addr 函数,验证 MAC 地址是否合法,也就是验证 net_device 的dev_addr中的 MAC 地址是否合法,直接调用 is_valid_ether_addr 函数。
第 14行:ndo_do_ioctl 函数,用户程序调用 ioctl 的时候此函数就会执行,比如 PHY 芯片 相关的命令操作,一般会直接调用 phy_mii_ioctl 函数。
第 16行:ndo_change_mtu 函数,更改 MTU 大小。
第 18行:ndo_tx_timeout 函数,当发送超时的时候函数会执行,一般都是网络出问题了导致发送超时。一般可能会重启 MAC 和 PHY,重新开始数据发送等.
第 20行:ndo_poll_controller 函数,使用查询方式来处理网卡数据的收发.
第 24 行:ndo_set_features 函数,修改 net_device 的 features 属性,设置相应的硬件属性
sk_buff 结构体
网络是分层的,对于应用层而言不用关心具体的底层是如何工作的,只需要按照协议将要发送或接收的数据打包好即可。打包好以后都通过 dev_queue_xmit 函数将数据发送出去,接收数据的话使用 netif_rx 函数即可,我们依次来看一下这两个函数。
dev_queue_xmit 函数
此函数用于将网络数据发送出去,函数定义在 include/linux/netdevice.h 中,函数原型如下:static inline int dev_queue_xmit(struct sk_buff *skb)
函数参数和返回值含义如下:
skb:要发送的数据,这是一个 sk_buff 结构体指针,sk_buff 是 Linux 网络驱动中一个非常重要的结构体,网络数据就是以 sk_buff 保存的,各个协议层在 sk_buff 中添加自己的协议头,最终由底层驱动将 sk_buff 中的数据发送出去。网络数据的接收过程恰好相反,网络底层驱动将接收到的原始数据打包成 sk_buff,然后发送给上层协议,上层会取掉相应的头部,然后将最终的数据发送给用户。
返回值:0 发送成功,负值 发送失败。
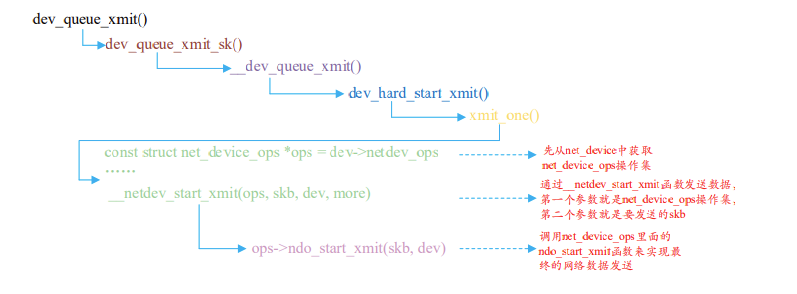
dev_queue_xmit 函数太长,这里就不详细的分析了,dev_queue_xmit 函数最终是通过net_device_ops 操作集里面的 ndo_start_xmit 函数来完成最终发送了,ndo_start_xmit 就是网络驱动编写人员去实现的,整个流程如图所示:
netif_rx 函数
上层接收数据的话使用 netif_rx 函数,但是最原始的网络数据一般是通过轮询、中断或 NAPI的方式来接收。netif_rx 函数定义在 net/core/dev.c 中,函数原型如下:
int netif_rx(struct sk_buff *skb)
函数参数和返回值含义如下:
skb:保存接收数据的 sk_buff,。
返回值:NET_RX_SUCCESS 成功,NET_RX_DROP 数据包丢弃。
我们重点来看一下 sk_buff 这个结构体,sk_buff 是 Linux 网络重要的数据结构,用于管理 接收或发送数据包,sk_buff 结构体定义在 include/linux/skbuff.h 中,结构体内容如下(由于结构 体比较大,为了缩小篇幅只列出部分重要的内容):
struct sk_buff {
union {
struct {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
union {
ktime_t tstamp;
struct skb_mstamp skb_mstamp;
};
};
struct rb_node rbnode; /* used in netem & tcp stack */
};
struct sock *sk;
struct net_device *dev;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48] __aligned(8);
unsigned long _skb_refdst;
void (*destructor)(struct sk_buff *skb);
unsigned int len, data_len;
__u16 mac_len, hdr_len;
__be16 protocol;
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
__u32 headers_end[0];
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head, *data;
unsigned int truesize;
atomic_t users;
};第 5~6 行:next 和 prev 分别指向下一个和前一个 sk_buff,构成一个双向链表。
第 9 行:tstamp 表示数据包接收时或准备发送时的时间戳。
第 14 行:sk 表示当前 sk_buff 所属的 Socket。
第 15行:dev 表示当前 sk_buff 从哪个设备接收到或者发出的.
第 22行:cb 为控制缓冲区,不管哪个层都可以自由使用此缓冲区,用于放置私有数据。
第 24行:destructor 函数,当释放缓冲区的时候可以在此函数里面完成某些动作。
第 25行:len 为实际的数据长度,包括主缓冲区中数据长度和分片中的数据长度。data_len为数据长度,只计算分片中数据的长度。
第 26行:mac_len 为连接层头部长度,也就是 MAC 头的长度。
第 27行:protocol 协议。
第 28行:transport_header 为传输层头部。
第 29行:network_header 为网络层头部.
第 30行:mac_header 为链接层头部。
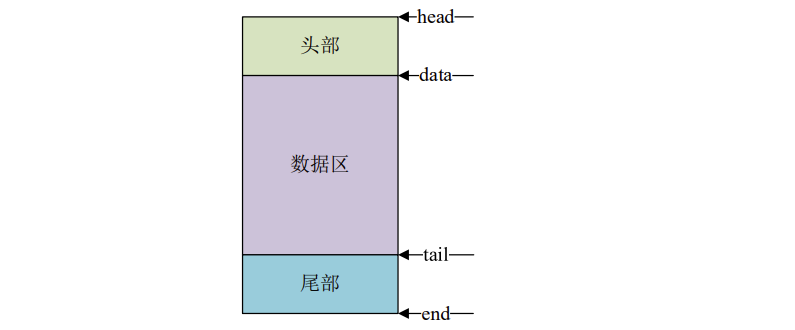
第 32行:tail 指向实际数据的尾部。
第 33行:end 指向缓冲区的尾部。
第 34行:head 指向缓冲区的头部,data 指向实际数据的头部。data 和 tail 指向实际数据 的头部和尾部,head 和 end 指向缓冲区的头部和尾部。结构如图所示:
针对 sk_buff 内核提供了一系列的操作与管理函数,我们简单看一些常见的 API 函数:
3、分配 sk_buff
要使用 sk_buff 必须先分配,首先来看一下 alloc_skb 这个函数,此函数定义在 include/linux/skbuff.h 中,函数原型如下:
static inline struct sk_buff *alloc_skb(unsigned int size,gfp_t priority)
函数参数和返回值含义如下:
size:要分配的大小,也就是 skb 数据段大小。
priority:为 GFP MASK 宏,比如 GFP_KERNEL、GFP_ATOMIC 等。
返回值:分配成功的话就返回申请到的 sk_buff 首地址,失败的话就返回 NULL。
在网络设备驱动中常常使用 netdev_alloc_skb 来为某个设备申请一个用于接收的 skb_buff,此函数
也定义在 include/linux/skbuff.h 中,函数原型如下:
static inline struct sk_buff *netdev_alloc_skb(struct net_device *dev,unsigned int length)
函数参数和返回值含义如下:
dev:要给哪个设备分配 sk_buff。
length:要分配的大小。
返回值:分配成功的话就返回申请到的 sk_buff 首地址,失败的话就返回 NULL。
4、释放 sk_buff
当使用完成以后就要释放掉 sk_buff,释放函数可以使用 kfree_skb,函数定义在include/linux/skbuff.c 中,函数原型如下:
void kfree_skb(struct sk_buff *skb);
函数参数和返回值含义如下:
skb:要释放的 sk_buff。
返回值:无。
对于网络设备而言最好使用如下所示释放函数:
void dev_kfree_skb (struct sk_buff *skb)
函数只要一个参数 skb,就是要释放的 sk_buff。
返回值:无。
对于网络设备而言最好使用如下所示释放函数:
void dev_kfree_skb (struct sk_buff *skb)
函数只要一个参数 skb,就是要释放的 sk_buff。
5、skb_put、skb_push、sbk_pull 和 skb_reserve
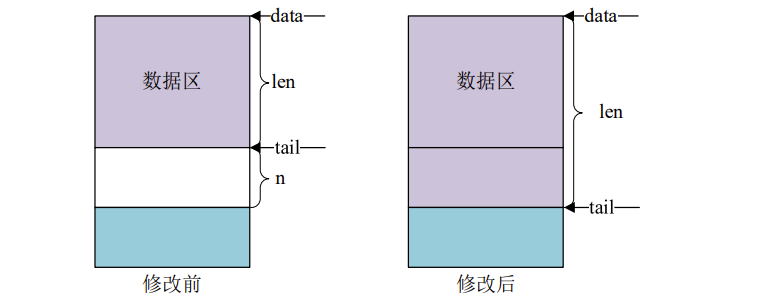
这四个函数用于变更 sk_buff,先来看一下 skb_put 函数,此函数用于在尾部扩展 skb_buff的数据区,也就将 skb_buff 的 tail 后移 n 个字节,从而导致 skb_buff 的 len 增加 n 个字节,原型如下:
unsigned char *skb_put(struct sk_buff *skb, unsigned int len)
函数参数和返回值含义如下:
skb:要操作的 sk_buff。
len:要增加多少个字节。
返回值:扩展出来的那一段数据区首地址。
skb_put 操作之前和操作之后的数据区如图所示:
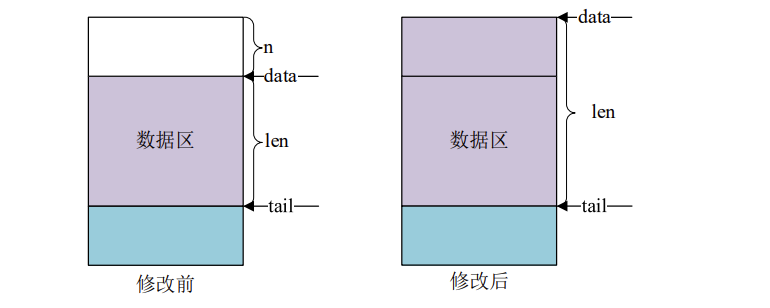
skb_push 函数用于在头部扩展 skb_buff 的数据区,函数原型如下所示:
unsigned char *skb_push(struct sk_buff *skb, unsigned int len)
函数参数和返回值含义如下:
skb:要操作的 sk_buff
len:要增加多少个字节
返回值:扩展完成以后新的数据区首地址
skb_push 操作之前和操作之后的数据区如图所示
sbk_pull 函数用于从 sk_buff 的数据区起始位置删除数据,函数原型如下所示:
unsigned char *skb_push(struct sk_buff *skb, unsigned int len)
函数参数和返回值含义如下:
skb:要操作的 sk_buff。
len:要增加多少个字节。
返回值:扩展完成以后新的数据区首地址。
skb_push 操作之前和操作之后的数据区如图所示:
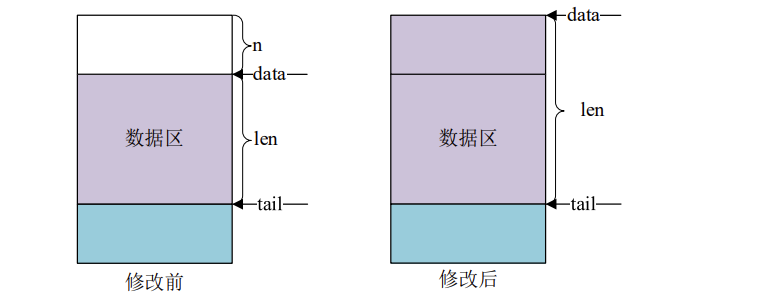
sbk_reserve 函数用于调整缓冲区的头部大小,方法很简单将 skb_buff 的 data 和 tail 同时后移 n 个字节即可,函数原型如下所示:
static inline void skb_reserve(struct sk_buff *skb, int len)
函数参数和返回值含义如下:
skb:要操作的 sk_buff。
len:要增加的缓冲区头部大小。
返回值:无。
网络 NAPI 处理机制
如果玩过单片机的话应该都知道,像 IIC、SPI、网络等这些通信接口,接收数据有两种方 法:轮询或中断。Linux 里面的网络数据接收也轮询和中断两种,中断的好处就是响应快,数据 量小的时候处理及时,速度快,但是一当数据量大,而且都是短帧的时候会导致中断频繁发 生,消耗大量的 CPU 处理时间在中断自身处理上。轮询恰好相反,响应没有中断及时,但是在 处理大量数据的时候不需要消耗过多的 CPU 处理时间。Linux 在这两个处理方式的基础上提出 了另外一种网络数据接收的处理方法:NAPI(New API),NAPI 是一种高效的网络处理技术。 NAPI 的核心思想就是不全部采用中断来读取网络数据,而是采用中断来唤醒数据接收服务程 序,在接收服务程序中采用 POLL 的方法来轮询处理数据。这种方法的好处就是可以提高短数 据包的接收效率,减少中断处理的时间。目前 NAPI 已经在 Linux 的网络驱动中得到了大量的 应用,NXP 官方编写的网络驱动都是采用的 NAPI 机制。 关于 NAPI 详细的处理过程本章节不讨论,本章节就简单讲解一下如何在驱动中使用 NAPI, Linux 内核使用结构体 napi_struct 表示 NAPI,在使用 NAPI 之前要先初始化一个 napi_struct 实 例。
1、初始化 NAPI
首先要初始化一个 napi_struct 实例,使用 netif_napi_add 函数,此函数定义在 net/core/dev.c
中,函数原型:
void netif_napi_add(struct net_device *dev,struct napi_struct *napi,int (*poll)(struct napi_struct *, int), int weight)
函数参数和返回值含义如下:
dev:每个 NAPI 必须关联一个网络设备,此参数指定 NAPI 要关联的网络设备
napi:要初始化的 NAPI 实例。
poll:NAPI 所使用的轮询函数,非常重要,一般在此轮询函数中完成网络数据接收的工作。
weight:NAPI 默认权重(weight),一般为 NAPI_POLL_WEIGHT。
返回值:无。
2、删除 NAPI
如果要删除 NAPI,使用 netif_napi_del 函数即可,函数原型如下:
void netif_napi_del(struct napi_struct *napi)
函数参数和返回值含义如下:
napi:要删除的 NAPI。
返回值:无。
3、使能 NAPI
初始化完 NAPI 以后,必须使能才能使用,使用函数 napi_enable,函数原型如下:
inline void napi_enable(struct napi_struct *n)
函数参数和返回值含义如下:
n:要使能的 NAPI。
返回值:无。
4、关闭 NAPI
关闭 NAPI 使用 napi_disable 函数即可,函数原型如下:
void napi_disable(struct napi_struct *n)
函数参数和返回值含义如下:
n:要关闭的 NAPI。
返回值:无。
5、检查 NAPI 是否可以进行调度
使用 napi_schedule_prep 函数检查 NAPI 是否可以进行调度,函数原型如下:
inline bool napi_schedule_prep(struct napi_struct *n)
函数参数和返回值含义如下:
n:要检查的 NAPI。
返回值:如果可以调度就返回真,如果不可调度就返回假。
6、NAPI 调度
如果可以调度的话就进行调度,使用__napi_schedule 函数完成 NAPI 调度,函数原型如下:
void __napi_schedule(struct napi_struct *n)
函数参数和返回值含义如下:
n:要调度的 NAPI。
返回值:无。
我们也可以使用 napi_schedule 函数来一次完成 napi_schedule_prep 和__napi_schedule 这两个函数的工作,napi_schedule 函数内容如下所示:
static inline void napi_schedule(struct napi_struct *n)
{
if (napi_schedule_prep(n))
__napi_schedule(n);
}从上面的示例代码可以看 出 ,napi_schedule 函 数 就 是 对 napi_schedule_prep 和__napi_schedule 的简单封装,一次完成判断和调度。
7、NAPI 处理完成
NAPI 处理完成以后需要调用 napi_complete 函数来标记 NAPI 处理完成,函数原型如下:
inline void napi_complete(struct napi_struct *n)
函数参数和返回值含义如下:
n:处理完成的 NAPI。
返回值:无。