pwd #显示当前目录的路径
cd / # 跳转到根目录
cd ~ # 跳转到家目录
cd .. # 跳转到上级目录
cd ./home # 跳转到当前目录的home目录下
cd /home/lion # 跳转到根目录下的home目录下的lion目录
cd # 不添加任何参数,也是回到家目录
# 注意:输入cd /ho + 单次 tab 键会自动补全路径 + 两次 tab 键会列出所有可能的目录列表。
ls
ls -a #显示所有文件和目录包括隐藏的
ls -l #显示详细列表
ls -h #适合人类阅读的
ls -t #按文件最近一次修改时间排序
ls -i #显示文件的 inode ( inode 是文件内容的标识)
cat myLog.log #一次性显示文件myLog.log所有内容,更适合查看小的文件。
cat -n myLog.log #显示行号。
touch new_file #创建一个文件
mkdir new_folder #创建一个目录(文件夹)
mkdir -p one/two/three #-p 递归的创建目录结构
cp file file_copy # file 是目标文件,file_copy 是拷贝出来的文件
cp file one # 把 file 文件拷贝到 one 目录下,并且文件名依然为 file
cp file one/file_copy # 把 file 文件拷贝到 one 目录下,文件名为file_copy
cp *.txt folder # 把当前目录下所有 txt 文件拷贝到 folder 目录下
mv file one # 将 file 文件移动到 one 目录下
mv new_folder one # 将 new_folder 文件夹移动到one目录下
mv *.txt folder # 把当前目录下所有 txt 文件移动到 folder 目录下
mv file new_file # file 文件重命名为 new_file
rm new_file # 删除 new_file 文件
rm f1 f2 f3 # 同时删除 f1 f2 f3 3个文件
# -i 向用户确认是否删除;
# -f 文件强制删除;
# -r 递归删除文件夹,如 :著名的删除操作 rm -rf 。
head cloud-init.log #显示文件的开头几行(默认是10行)
head cloud-init.log -n 2 #-n 指定行数
tail cloud-init.log #显示文件的结尾几行(默认是10行)
tail cloud-init.log -n 2 #-n 指定行数
tail -f -s 4 xxx.log #-f 会每过1秒检查下文件是否有更新内容,也可以用 -s 参数指定间隔时间
less myLog.log #分页显示文件内容,更适合查看大的文件。
#【快捷操作】
# 空格键:前进一页(一个屏幕);
# b键:后退一页;
# 回车键:前进一行;
# y键:后退一行;
# 上下键:回退或前进一行;
# d 键:前进半页;
# u 键:后退半页;
# q 键:停止读取文件,中止 less 命令;
# = 键:显示当前页面的内容是文件中的第几行到第几行以及一些其它关于本页内容的详细信息;
# h 键:显示帮助文档;
# / 键:进入搜索模式后,按 n 键跳到一个符合项目,按 N 键跳到上一个符合项目,同时也可以输入正则表达式匹配。
##########文件压缩解压##########################################################################
#我们常常使用 tar 将多个文件归档为一个总的文件,称为 archive 。然后用 gzip 或 bzip2 命令将 archive 压缩为更小的文件。
#tar 打包/创建归档
tar -cvf sort.tar sort/ # 将sort文件夹归档(又称打包、压缩)为sort.tar
tar -cvf archive.tar file1 file2 file3 # 将 file1 file2 file3 归档为archive.tar
#常用参数
#-cvf 表示 create(创建)+ verbose(细节)+ file(文件),创建归档文件并显示操作细节;
#-tf 显示归档里的内容,并不解开归档;
tar -rvf archive.tar file.txt #-rvf 追加文件到归档
tar -xvf archive.tar#-xvf 解开归档
#gzip / gunzip “压缩/解压”归档,默认用 gzip 命令,压缩后的文件后缀名为 .tar.gz 。
gzip archive.tar # 压缩
gunzip archive.tar.gz # 解压复
#tar 归档+压缩 可以用 tar 命令同时完成归档和压缩的操作,就是给 tar 命令多加一个选项参数,使之完成归档操作后,还是调用 gzip 或 bzip2 命令来完成压缩操作。
tar -zcvf archive.tar.gz archive/ # 将archive文件夹归档并压缩
tar -zxvf archive.tar.gz # 将archive.tar.gz归档压缩文件解压
#zcat、zless、zmore 查看压缩文件
#使用 cat less more 可以查看文件内容,但是压缩文件的内容是不能使用这些命令进行查看的,而要使用 zcat、zless、zmore 进行查看
zcat archive.tar.gz #查看压缩文件
#zip/unzip “压缩/解压” zip 文件 “压缩/解压” zip 文件( zip 压缩文件一般来自 windows 操作系统)。
## Red Hat 一族中的安装方式 yum install zip yum install unzip
unzip archive.zip # 解压 .zip 文件
unzip -l archive.zip # 不解开 .zip 文件,只看其中内容
zip -r sort.zip sort/ # 将sort文件夹压缩为 sort.zip,其中-r表示递归
##########进程管理#############################################################################
w #查看进程
ps #静态获取当前系统中的进程, ps 命令显示的进程列表不会随时间而更新,是静态的,是运行 ps 命令那个时刻的状态或者说是一个进程快照。
#常用参数
# -ef 列出所有进程;
# -efH 以乔木状列举出所有进程;
# -u 列出此用户运行的进程;
# -aux 通过 CPU 和内存使用来过滤进程 ps -aux | less ;
# -aux --sort -pcpu 按 CPU 使用降序排列, -aux --sort -pmem 表示按内存使用降序排列;
# -axjf 以树形结构显示进程, ps -axjf 它和 pstree 效果类似。
top #(动态获取)进程的动态列表,展示的这些进程是按照使用处理器 %CPU 的使用率来排序的。
#进程状态
#主要是切换进程的状态。我们先了解下 Linux 下进程的五种状态:
#状态码 R :表示正在运行的状态;
#状态码 S :表示中断(休眠中,受阻,当某个条件形成后或接受到信号时,则脱离该状态);
#状态码 D :表示不可中断(进程不响应系统异步信号,即使用kill命令也不能使其中断);
#状态码 Z :表示僵死(进程已终止,但进程描述符依然存在,直到父进程调用 wait4() 系统函数后将进程释放);
#状态码 T :表示停止(进程收到 SIGSTOP 、 SIGSTP 、 SIGTIN 、 SIGTOU 等停止信号后停止运行)。
#结束(杀死)一个进程, kill + PID 。
kill 956 # 结束进程号为956的进程
kill 956 957 # 结束多个进程
kill -9 7291 # 强制结束进程
#前台进程 与 后台进程
#默认情况下,用户创建的进程都是前台进程,前台进程从键盘读取数据,并把处理结果输出到显示器。
#例如运行 top 命令,这就是一个一直运行的前台进程。
#后台进程的优点是不必等待程序运行结束,就可以输入其它命令。在需要执行的命令后面添加 & 符号,就表示启动一个后台进程。
cp name.csv name-copy.csv & #后台启动进程,它的缺点是后台进程与终端相关联,一旦关闭终端,进程就自动结束了。
nohup cp name.csv name-copy.csv #nohup 不受挂断,使进程不受挂断(关闭终端等动作)的影响。
nohup cp name.csv name-copy.csv & #nohup 命令也可以和 & 结合使用。
#bg 使一个“后台暂停运行”的进程,状态改为“后台运行”。
bg %1 #不加任何参数的情况下,bg命令会默认作用于最近的一个后台进程,如果添加参数则会作用于指定标号的进程
#使用案例1:
#1. 执行 grep -r "log" / > grep_log 2>&1 命令启动一个前台进程,并且忘记添加 & 符号
#2. ctrl + z 使进程状态转为后台暂停
#3. 执行 bg 将命令转为后台运行
#使用案例2:
#前端开发时我们经常会执行 yarn start 启动项目,此时我们执行 ctrl + z 先使其暂停,然后执行 bg 使其转为后台运行。
#这样当前终端就空闲出来可以干其它事情了,如果想要唤醒它就使用 fg 命令即可(后面会讲)Linux的软件仓库
Linux 下软件是以包的形式存在,一个软件包其实就是软件的所有文件的压缩包,是二进制的形式,包含了安装软件的所有指令。
Linux 的包都存在一个仓库,叫做软件仓库,它可以使用 yum 来管理软件包。(还有其他同类型的包管理软件rpm、npm等)
yum 是 CentOS 中默认的包管理工具,适用于 Red Hat 一族。可以理解成 Node.js 的 npm 。
yum 常用命令
yum update | yum upgrade #更新软件包
yum search xxx #搜索相应的软件包
yum install xxx #安装软件包
yum remove xxx #删除/卸载软件包切换 CentOS 软件源
CentOS 默认的 yum 源不一定是国内镜像,导致 yum 在线安装及更新速度不是很理想。
需要将 yum 源设置为国内镜像站点。国内主要开源的镜像站点是网易和阿里云。
首先备份系统自带 yum 源配置文件
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup2、下载阿里云的 yum 源配置文件到 /etc/yum.repos.d/CentOS7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo3、生成缓存
yum makecache对文件内容操作(文本内容)
grep对文件内的内容进行全局搜索
全局搜索一个正则表达式,并且打印到屏幕。简单来说就是,在文件中查找关键字,并显示关键字所在行。
grep text file # text代表要搜索的文本,file代表供搜索的文件#
#常用参数
# -i 忽略大小写, grep -i path /etc/profile
# -n 显示行号,grep -n path /etc/profile
# -v 只显示搜索文本不在的那些行,grep -v path /etc/profile
# -r 递归查找, grep -r hello /etc ,Linux 中还有一个 rgrep 命令,作用相当于 grep -rgrep 可以配合正则表达式使(高级用法)
grep -E path /etc/profile # 完全匹配path
grep -E ^path /etc/profile # 匹配path开头的字符串
grep -E [Pp]ath /etc/profile # 匹配path或Path复制代码sort 对文件内的内容进行文本内容排序
sort name.txt # 对name.txt文件内容进行排序
# 常用参数
# -o 将排序后的文件写入新文件, sort -o name_sorted.txt name.txt ;
# -r 倒序排序, sort -r name.txt ;
# -R 随机排序, sort -R name.txt ;
# -n 对数字进行排序,默认是把数字识别成字符串的,因此 138 会排在 25 前面,如果添加了 -n 数字排序的话,则 25 会在 138 前面。实例用法
为了演示方便,我们首先创建一个文件 name.txt ,放入以下内容:
ChristopherShawnTedRockNoahZacharyBella
执行 sort name.txt 命令,会对文本内容进行排序。
wc 对文件内的内容进行统计
word count 的缩写,用于文件的统计。它可以统计单词数目、行数、字符数,字节数等。
wc name.txt # 统计name.txt
wc -l name.txt # -l 只统计行数,
wc -w name.txt # -w 只统计单词数,
wc -c name.txt # -c 只统计字节数,
wc -m name.txt # -m 只统计字符数,
#实例
wc name.txt 13 13 91 name.txt
#第一个13,表示行数;
#第二个13,表示单词数;
#第三个91,表示字节数。uniq 删除文件内的重复内容
uniq name.txt # 去除name.txt重复的行数,并打印到屏幕上
uniq name.txt uniq_name.txt # 把去除重复后的文件保存为 uniq_name.txt
#常用参数
uniq -c name.txt #-c 统计重复行数
uniq -d name.txt #-d 只显示重复的行数【注意】它只能去除连续重复的行数。
cut 剪切文件的一部分内容
cut -c 2-4 name.txt # 剪切每一行第二到第四个字符
# 常用参数
cut -d , name.txt # -d 用于指定用什么分隔符(比如逗号、分号、双引号等等)
cut -d , -f 1 name.txt # -f 表示剪切下用分隔符分割的哪一块或哪几块区域重定向
Linux重定向是指修改原来默认的一些东西,对原来系统命令的默认执行方式进行改变,比如说简单的我不想看到在显示器的输出而是希望输出到某一文件中就可以通过Linux重定向来进行这项工作。
> 输出重定向
表示重定向到新的文件, cut -d , -f 1 notes.csv > name.csv ,它表示通过逗号剪切 notes.csv 文件(剪切完有3个部分)获取第一个部分,重定向到 name.csv 文件。
假设我们有一个文件 notes.csv ,文件内容如下:
Mark1,951/100,很不错1Mark2,952/100,很不错2Mark3,953/100,很不错3Mark4,954/100,很不错4Mark5,955/100,很不错5Mark6,956/100,很不错6
执行命令:
cut -d , -f 1 notes.csv > name.csv最后输出如下内容:
Mark1Mark2Mark3Mark4Mark5Mark6
【注意】使用 > 要注意,如果输出的文件不存在它会新建一个,如果输出的文件已经存在,则会覆盖。因此执行这个操作要非常小心,以免覆盖其它重要文件。
>> 输出重定向(追加)
表示重定向到文件末尾,因此它不会像 > 命令这么危险,它是追加到文件的末尾(当然如果文件不存在,也会被创建)。
再次执行命令
cut -d , -f 1 notes.csv >> name.csv 则会把名字追加到 name.csv 里面。
Mark1Mark2Mark3Mark4Mark5Mark6Mark1Mark2Mark3Mark4Mark5Mark6
我们平时读的 log 日志文件其实都是用这个命令输出的。
2> 标准错误输出重定向
cat not_exist_file.csv > res.txt 2> errors.log当我们 cat 一个文件时,会把文件内容打印到屏幕上,这个是标准输出;
当使用了 > res.txt 时,则不会打印到屏幕,会把标准输出写入文件 res.txt 文件中;
2> errors.log 当发生错误时会写入 errors.log 文件中。
2>> 标准错误输出(追加到文件末尾)同 >> 相似。
2>&1 标准输出和标准错误输出都重定向都一个地方
cat not_exist_file.csv > res.txt 2>&1 # 覆盖输出
cat not_exist_file.csv >> res.txt 2>&1 # 追加输出目前为止,我们接触的命令的输入都来自命令的参数,其实命令的输入还可以来自文件或者键盘的输入。
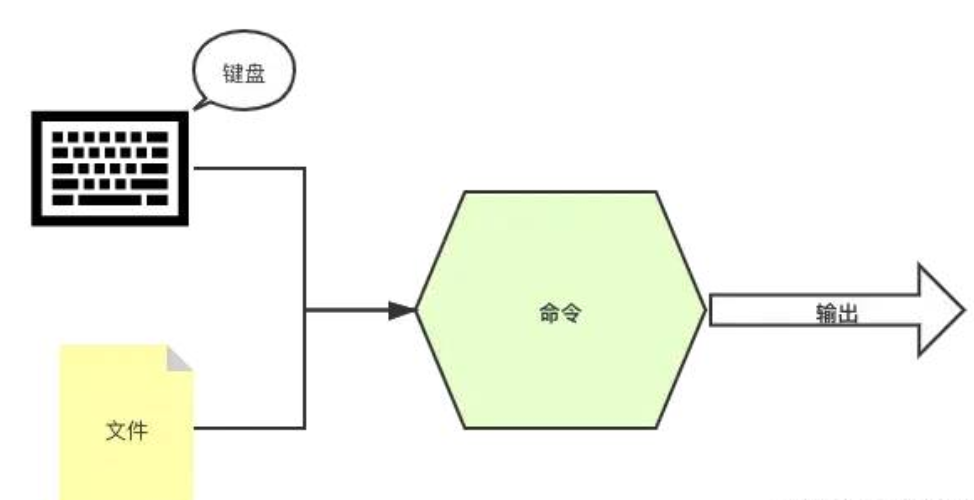
< 输入重定向
用于指定命令的输入。
cat < name.csv # 指定命令的输入为 name.csv虽然它的运行结果与 cat name.csv 一样,但是它们的原理却完全不同。
cat name.csv #表示 cat 命令接收的输入是 notes.csv 文件名,那么要先打开这个文件,然后打印出文件内容。
cat < name.csv #表示 cat 命令接收的输入直接是 notes.csv 这个文件的内容, cat 命令只负责将其内容打印,打开文件并将文件内容传递给 cat 命令的工作则交给终端完成。<< 输入重定向
将键盘的输入重定向为某个命令的输入。
sort -n << END # 输入这个命令之后,按下回车,终端就进入键盘输入模式,其中END为结束命令(这个可以自定义)wc -m << END # 统计输入的单词| 管道 (命令连接用)
把两个命令连起来使用,一个命令的输出作为另外一个命令的输入,英文是 pipeline ,可以想象一个个水管连接起来,管道算是重定向流的一种。
cut -d , -f 1 name.csv | sort > sorted_name.txt
# 第一步获取到的 name 列表,通过管道符再进行排序,最后输出到sorted_name.txt
du | sort -nr | head
# du 表示列举目录大小信息
# sort 进行排序,-n 表示按数字排序,-r 表示倒序
# head 前10行文件
grep log -Ir /var/log | cut -d : -f 1 | sort | uniq
grep log -Ir /var/log #表示在log文件夹下搜索 /var/log 文本,-r 表示递归,-I 用于排除二进制文件
cut -d : -f 1 #表示通过冒号进行剪切,获取剪切的第一部分
# sort 进行排序
# uniq 进行去重复制代码流
流并非一个命令,在计算机科学中,流 stream 的含义是比较难理解的,
记住一点即可:流就是读一点数据, 处理一点点数据。其中数据一般就是二进制格式。
上面提及的重定向或管道,就是把数据当做流去运转的。
到此我们就接触了,流、重定向、管道等 Linux 高级概念及指令。其实你会发现关于流和管道在其它语言中也有广泛的应用。Angular 中的模板语法中可以使用管道。Node.js 中也有 stream 流的概念。
locate、find 查找文件
locate 命令
#需要先安装 locate命令包
yum -y install mlocate # 安装包
updatedb # 更新数据库
locate file.txtlocate fil*.txt[注意] locate 命令会去文件数据库中查找命令,而不是全磁盘查找,因此刚创建的文件并不会更新到数据库中,所以无法被查找到,可以执行 updatedb 命令去更新数据库。
find 命令
用于查找文件,它会去遍历你的实际硬盘进行查找,而且它允许我们对每个找到的文件进行后续操作,功能非常强大。
find <何处> <何物> <做什么>
何处:指定在哪个目录查找,此目录的所有子目录也会被查找。
何物:查找什么,可以根据文件的名字来查找,也可以根据其大小来查找,还可以根据其最近访问时间来查找。
做什么:找到文件后,可以进行后续处理,如果不指定这个参数
####find 根据文件名查找######
find -name "file.txt" # 当前目录以及子目录下通过名称查找文件
find . -name "syslog" # 当前目录以及子目录下通过名称查找文件
find / -name "syslog" # 整个硬盘下查找syslog
find /var/log -name "syslog" # 在指定的目录/var/log下查找syslog文件
find /var/log -name "syslog*" # 查找syslog1、syslog2 ... 等文件,通配符表示所有
find /var/log -name "*syslog*" # 查找包含syslog的文件
#[注意] find 命令只会查找完全符合 “何物” 字符串的文件,而 locate 会查找所有包含关键字的文件。
####find 根据文件大小查找######
find /var -size +10M # /var 目录下查找文件大小超过 10M 的文件
find /var -size -50k # /var 目录下查找文件大小小于 50k 的文件
find /var -size +1G # /var 目录下查找文件大小查过 1G 的文件
find /var -size 1M # /var 目录下查找文件大小等于 1M 的文件复制代码find
####根据文件最近访问时间查找######
find -name "*.txt" -atime -7 # 近 7天内访问过的.txt结尾的文件find 仅查找目录或文件
find . -name "file" -type f # 只查找当前目录下的file文件
find . -name "file" -type d # 只查找当前目录下的file目录find
####操作查找结果######
find -name "*.txt" -printf "%p - %u\n"# 找出所有后缀为txt的文件,并按照 %p - %u\n 格式打印,其中%p=文件名,%u=文件所有者
find -name "*.jpg" -delete# 删除当前目录以及子目录下所有.jpg为后缀的文件,不会有删除提示,因此要慎用
find -name "*.c" -exec chmod 600 {} \;# 对每个.c结尾的文件,都进行 -exec 参数指定的操作,{} 会被查找到的文件替代,\; 是必须的结尾
find -name "*.c" -ok chmod 600 {} \; # 和上面的功能一样,会多一个确认提示网络
ifconfig
ifconfig 查看 ip 网络相关信息,如果命令不存在的话, 执行命令 yum install net-tools 安装。
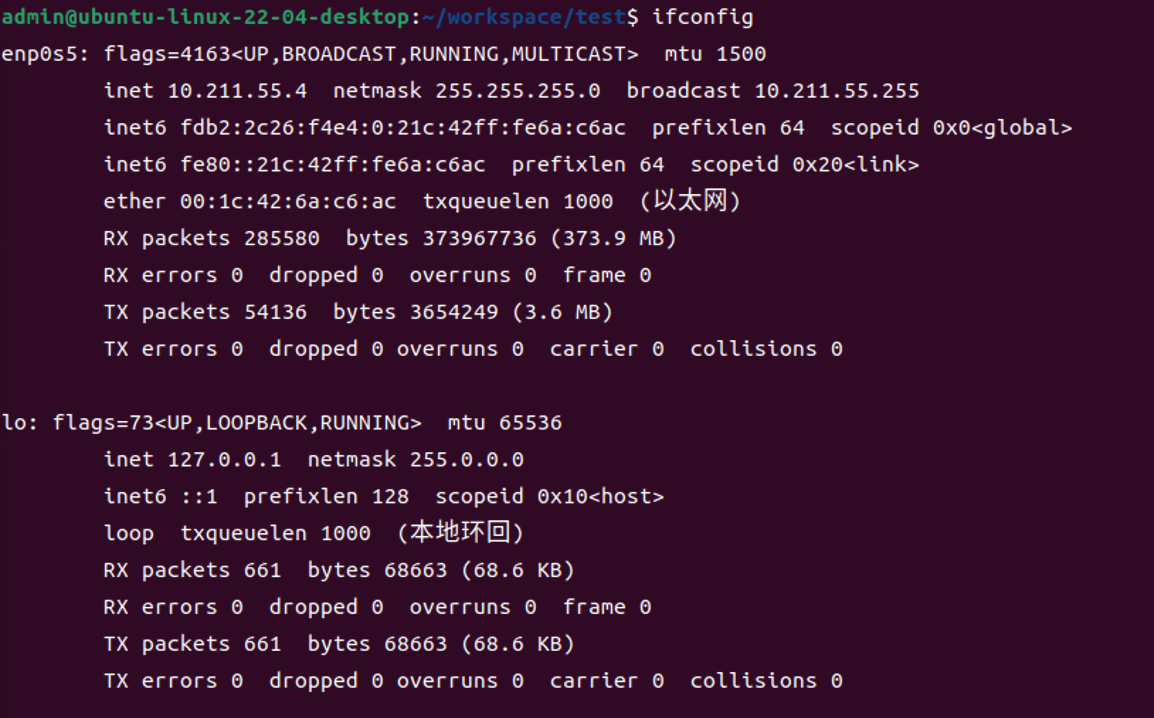
参数解析:
eth0 对应有线连接(对应你的有线网卡),就是用网线来连接的上网。eth 是 Ethernet 的缩写,表示“以太网”。有些电脑可能同时有好几条网线连着,例如服务器,那么除了 eht0 ,你还会看到 eth1 、 eth2 等。
lo 表示本地回环( Local Loopback 的缩写,对应一个虚拟网卡)可以看到它的 ip 地址是 127.0.0.1 。每台电脑都应该有这个接口,因为它对应着“连向自己的链接”。这也是被称之为“本地回环”的原因。所有经由这个接口发送的东西都会回到你自己的电脑。看起来好像并没有什么用,但有时为了某些缘故,我们需要连接自己。例如用来测试一个网络程序,但又不想让局域网或外网的用户查看,只能在此台主机上运行和查看所有的网络接口。例如在我们启动一个前端工程时,在浏览器输入 127.0.0.1:3000 启动项目就能查看到自己的 web 网站,并且它只有你能看到。
wlan0 表示无线局域网(上面案例并未展示)。
host
host 实现ip 地址和主机名的互相转换。
软件安装
yum install bind-utils基础用法
host github.combaidu.com has address 13.229.188.59
host 13.229.188.5959.188.229.13.in-addr.arpa domain name pointer ec2-13-229-188-59.ap-southeast-1.compute.amazonaws.com.ssh 连接远程服务器
通过非对称加密以及对称加密的方式(同 HTTPS 安全连接原理相似)连接到远端服务器。
ssh 用户@ip:port1、ssh [email protected]:22
# 端口号可以省略不写,默认是22端口
#输入连接密码后就可以操作远端服务器了配置 ssh
config 文件可以配置 ssh ,方便批量管理多个 ssh 连接。
配置文件分为以下几种:
全局 ssh 服务端的配置:/etc/ssh/sshd_config ;
全局 ssh 客户端的配置:/etc/ssh/ssh_config(很少修改);
当前用户 ssh 客户端的配置:~/.ssh/config 。
【服务端 config 文件的常用配置参数】
服务端 config 参数 |
作用 |
Port |
sshd 服务端口号(默认是22) |
PermitRootLogin |
是否允许以 root 用户身份登录(默认是可以) |
PasswordAuthentication |
是否允许密码验证登录(默认是可以) |
PubkeyAuthentication |
是否允许公钥验证登录(默认是可以) |
PermitEmptyPasswords |
是否允许空密码登录(不安全,默认不可以) |
[注意] 修改完服务端配置文件需要重启服务 systemctl restart sshd
【客户端 config 文件的常用配置参数】
客户端 config 参数 |
作用 |
Host |
别名 |
HostName |
远程主机名(或 IP 地址) |
Port |
连接到远程主机的端口 |
User |
用户名 |
配置当前用户的 config :
# 创建config
vim ~/.ssh/config填写一下以下内容
Host lion # 别名
HostName 172.x.x.x # ip 地址
Port 22 # 端口
User root # 用户这样配置完成后,下次登录时,可以这样登录 ssh lion 会自动识别为 root 用户。
[注意] 这段配置不是在服务器上,而是你自己的机器上,它仅仅是设置了一个别名。
免密登录
ssh 登录分两种,一种是基于口令(账号密码),另外一种是基于密钥的方式。
基于口令,就是每次登录输入账号和密码,显然这样做是比较麻烦的,今天主要学习如何基于密钥实现免密登录。
基于密钥验证原理
客户机生成密钥对(公钥和私钥),把公钥上传到服务器,每次登录会与服务器的公钥进行比较,这种验证登录的方法更加安全,也被称为“公钥验证登录”。
具体实现步骤
1、在客户机中生成密钥对(公钥和私钥) ssh-keygen(默认使用 RSA 非对称加密算法)
运行完 ssh-keygen 会在 ~/.ssh/ 目录下,生成两个文件:
id_rsa.pub :公钥
id_rsa :私钥
2、把客户机的公钥传送到服务
执行 ssh-copy-id [email protected](ssh-copy-id 它会把客户机的公钥追加到服务器 ~/.ssh/authorized_keys 的文件中)。
执行完成后,运行 ssh [email protected] 就可以实现免密登录服务器了。
配合上面设置好的别名,直接执行 ssh lion 就可以登录,是不是非常方便。
wget 从终端控制台下载文件
可以使我们直接从终端控制台下载文件,只需要给出文件的HTTP或FTP地址。
命令格式:
wget [参数][URL地址]如:
wget http://www.minjieren.com/wordpress-3.1-zh_CN.zipwget 非常稳定,如果是由于网络原因下载失败, wget 会不断尝试,直到整个文件下载完毕。
常用参数
-c 继续中断的下载。
备份
scp 安全拷贝
它是 Secure Copy 的缩写,表示安全拷贝。scp 可以使我们通过网络,把文件从一台电脑拷贝到另一台电脑。
scp 是基于 ssh 的原理来运作的, ssh 会在两台通过网络连接的电脑之间创建一条安全通信的管道, scp 就利用这条管道安全地拷贝文件。
scp source_file destination_file
# source_file 表示源文件,destination_file 表示目标文件其中 source_file 和 destination_file 都可以这样表示:user@ip:file_name , user 是登录名, ip 是域名或 ip 地址。file_name 是文件路径。
scp file.txt [email protected]:/root
# 表示把我的电脑中当前文件夹下的 file.txt 文件拷贝到远程电脑
scp [email protected]:/root/file.txt file.txt
# 表示把远程电脑上的 file.txt 文件拷贝到本机rsync 远程同步文件
rsync 命令主要用于远程同步文件。它可以同步两个目录,不管它们是否处于同一台电脑。它应该是最常用于“增量备份”的命令了。它就是智能版的 scp 命令。
软件安装
yum install rsync基础用法
rsync -arv Images/ backups/
# 将Images 目录下的所有文件备份到 backups 目录下
rsync -arv Images/ [email protected]:backups/
# 同步到服务器的backups目录下常用参数
-a 保留文件的所有信息,包括权限,修改日期等;
-r 递归调用,表示子目录的所有文件也都包括;
-v 冗余模式,输出详细操作信息。
默认地, rsync 在同步时并不会删除目标目录的文件,
例如你在源目录中删除一个文件,但是用 rsync 同步时,它并不会删除同步目录中的相同文件。
如果想删除也可以这么做:
rsync -arv --delete Images/ backups/ 。系统关闭、重启、直接运行关机
halt #关闭系统,需要 root 身份。
reboot #重启系统,需要 root 身份
poweroff #直接运行即可关机,不需要 root 身份。