切片集群,也叫分片集群,就是指启动多个 Redis 实例组成一个集群,然后按照一定的规则,把收到的数据划分成多份,每一份用一个实例来保存。回到我们刚刚的场景中,如果把 25GB 的数据平均分成 5 份(当然,也可以不做均分),使用 5 个实例来保存,每个实例只需要保存 5GB 数据。如下图所示:
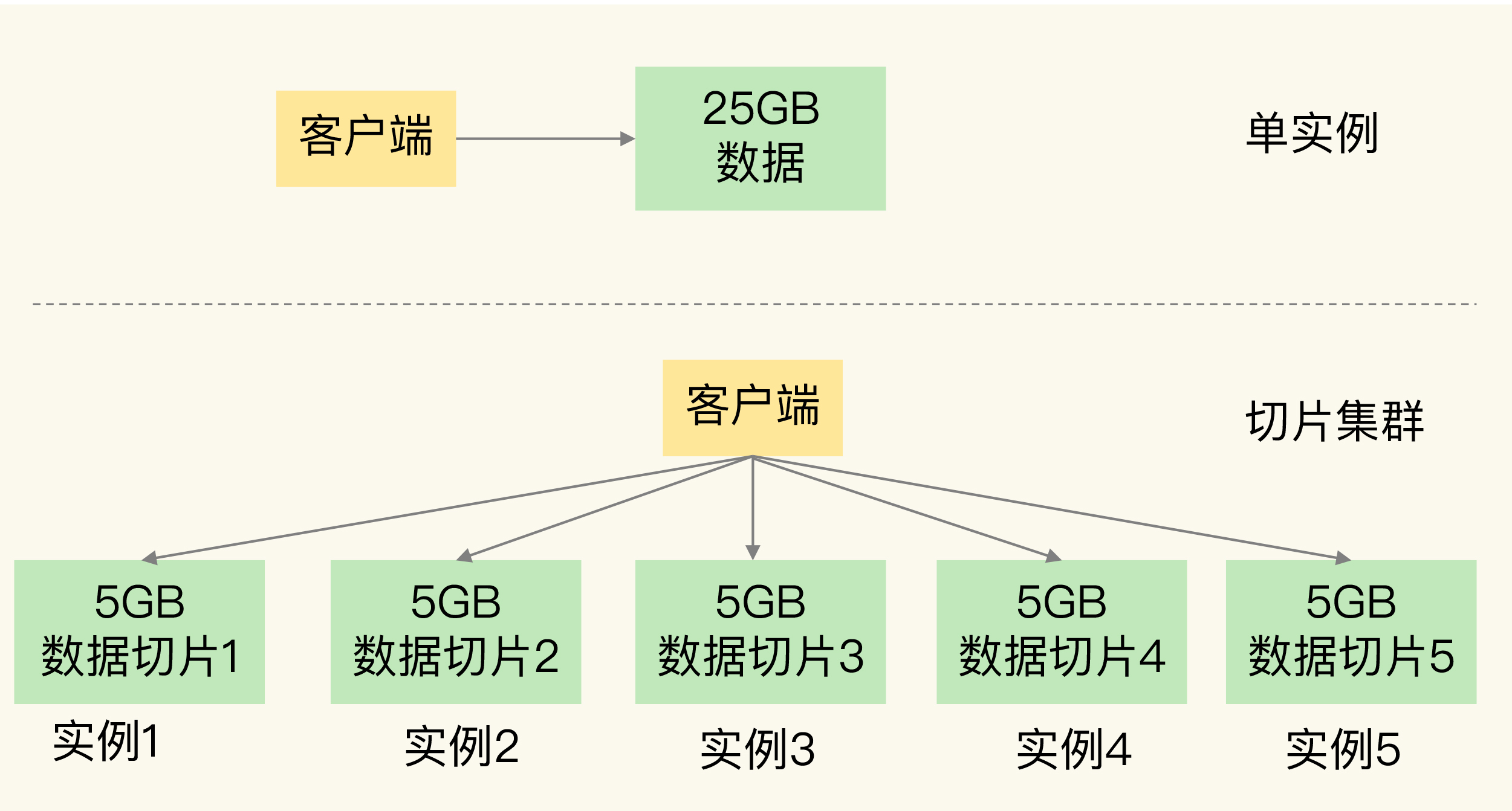
实际上,切片集群是一种保存大量数据的通用机制,这个机制可以有不同的实现方案。在 Redis 3.0 之前,官方并没有针对切片集群提供具体的方案。从 3.0 开始,官方提供了一个名为 **Redis Cluster 的方案,用于实现切片集群。**Redis Cluster 方案中就规定了数据和实例的对应规则。
具体来说,Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
那么,这些哈希槽又是如何被映射到具体的 Redis 实例上的呢?
我们在部署 Redis Cluster 方案时,可以使用 cluster create 命令创建集群,此时,Redis 会自动把这些槽平均分布在集群实例上。例如,如果集群中有 N 个实例,那么,每个实例上的槽个数为 16384/N 个。
当然, 我们也可以使用 cluster meet 命令手动建立实例间的连接,形成集群,再使用 cluster addslots 命令,指定每个实例上的哈希槽个数。
另外,我再给你一个小提醒,在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
客户端如何定位数据的?
在定位键值对数据时,它所处的哈希槽是可以通过计算得到的,这个计算可以在客户端发送请求时来执行。但是,要进一步定位到实例,还需要知道哈希槽分布在哪个实例上。
客户端和集群实例建立连接之后,实例就会把自己的哈希槽信息上报给客户端,每个实例在创建集群之初是不知道其他实例的哈希槽的。
**那么,客户端为什么可以在访问任何一个实例时,都能获得所有的哈希槽信息呢?**这是因为,Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了。
**客户端收到哈希槽信息后,会把哈希槽信息缓存在本地。**当客户端请求键值对时,会先计算键所对应的哈希槽,然后就可以给相应的实例发送请求了。
但是,在集群中,实例和哈希槽的对应关系并不是一成不变的,最常见的变化有两个:
-
在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;
-
为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍。
两个error
当客户端把一个键值对的操作请求发给一个实例时,如果这个实例上并没有这个键值对映射的哈希槽,那么,这个实例就会给客户端返回下面的 MOVED 命令响应结果,这个结果中就包含了新实例的访问地址。
GET hello:key
(error) MOVED 13320 172.16.19.5:6379
其中,MOVED 命令表示,客户端请求的键值对所在的哈希槽 13320,实际是在 172.16.19.5 这个实例上。通过返回的 MOVED 命令,就相当于把哈希槽所在的新实例的信息告诉给客户端了。这样一来,客户端就可以直接和 172.16.19.5 连接,并发送操作请求了。
GET hello:key
(error) ASK 13320 172.16.19.5:6379
这个结果中的 ASK 命令就表示,客户端请求的键值对所在的哈希槽 13320,在 172.16.19.5 这个实例上,但是这个哈希槽正在迁移。此时,客户端需要先给 172.16.19.5 这个实例发送一个 ASKING 命令。这个命令的意思是,让这个实例允许执行客户端接下来发送的命令。然后,客户端再向这个实例发送 GET 命令,以读取数据。
ASK 命令表示两层含义:第一,表明 Slot 数据还在迁移中;第二,ASK 命令把客户端所请求数据的最新实例地址返回给客户端,此时,客户端需要给实例 3 发送 ASKING 命令,然后再发送操作命令。
和 MOVED 命令不同,ASK 命令并不会更新客户端缓存的哈希槽分配信息。ASK 命令的作用只是让客户端能给新实例发送一次请求,而不像 MOVED 命令那样,会更改本地缓存,让后续所有命令都发往新实例。