ElasticSearch
1、ElasticSearch学习随笔之基础介绍
2、ElasticSearch学习随笔之简单操作
3、ElasticSearch学习随笔之java api 操作
4、ElasticSearch学习随笔之SpringBoot Starter 操作
5、ElasticSearch学习随笔之嵌套操作
6、ElasticSearch学习随笔之分词算法
7、ElasticSearch学习随笔之高级检索
8、ELK技术栈介绍
9、Logstash部署与使用
文章目录
前言
Logstash是一个收集与处理数据的引擎,就像ElasticSearch是专门用来检索的引擎一样,Logstash用于收集、处理和转换各种数据源(文件、数据库、网站等)的数据,并将其转换为统一的格式。
Logstash支持多种插件,进行数据过滤、转换和输出,可以方便地与 ES 和 Kibana 集成使用。
还支持多线程处理和事件模型,可以在大规模数据处理场景下提供高性能、高可用的服务。
一、什么是Logstash?
1.1 Logstash介绍
什么是Logstash呢,简单说就是它有很多数据处理管道,Logstash是免费开放的服务器数据处理管道,从多个来源采集数据、处理数据,再发送数据到指定的存储介质中去。
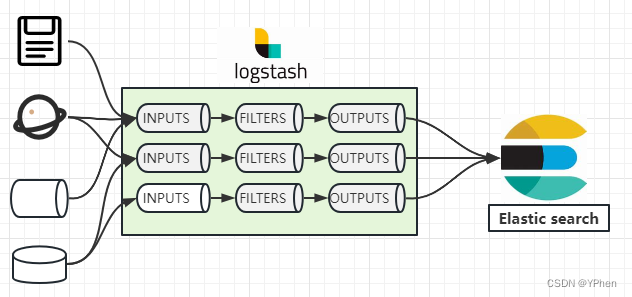
如上图所示,Logstash通过 INPUT(管道) 输入数据,通过 FILTERS(管道) 处理完成之后,再通过 OUTPUTS (管道)输出到 ES 中。
1.2 Logstash 核心概念
Pipeline :
- 包含了 input > filter > output 三个阶段的处理流程
- 插件生命周期管理
- 队列管理
Event :
数据在内部流转的一个具体表现形式,数据在 INPUT 阶段被转换成了 Event,在 OUTPUT 被转换为目标格式的数据,Event 就是一个 Java Object 对象,可在配置文件中对属性进行增删改查操作。
Codec(Code / Decode):
将原始数据 decode 成 Event, 再将 Event encode 成目标数据。

1.3 Logstash数据传输原理
- 数据采集与输入:Logstash支持各种输入选择,能够以连续的流式传输方式,轻松地从日志、指标、Web应用以及数据存储中采集数据。
- 实时解析和数据转换:通过Logstash过滤器解析各个事件,识别已命名的字段来构建结构,并将它们转换成通用格式,最终将数据从源端传输到存储库中。
- 存储与数据导出:Logstash提供多种输出选择,可以将数据发送到指定的地方。
1.4 Logstash配置文件结构
Logstash的管道配置文件对每种类型的插件都提供了一个单独的配置部分,用于处理管道事件。
input {
stdin {
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]}
stdout {
codec => rubydebug }
}
每个配置部分可以包含一个或多个插件。例如,指定多个filter插件,Logstash会按照它们在配置文件中出现的顺序进行处理。
- Input Plugins(官网文档)
一个 Pipeline可以有多个input插件:File、jdbc 等 - Output Plugins (官网文档)
将Event发送到特定的目的地,是 Pipeline 的最后一个阶段,常见的是 Elasticsearch。 - Filter Plugins (官网文档)
内置的Filter Plugins: Mutate(一操作Event的字段)、Ruby (一执行Ruby 代码 )等。 - Codec Plugins(官网文档)
将原始数据decode成Event;将Event encode成目标数据,内置的Codec Plugins: Line / Multiline、JSON 等。 - Logstash Queue
In Memory Queue:进程Crash,机器宕机,都会引起数据的丢失
Persistent Queue:机器宕机,数据也不会丢失; 数据保证会被消费; 可以替代 Kafka等消息队列缓冲区的作用,可以通过如下配置打开持久化。
queue.type: persisted (默认是memory)
queue.max_bytes: 4gb
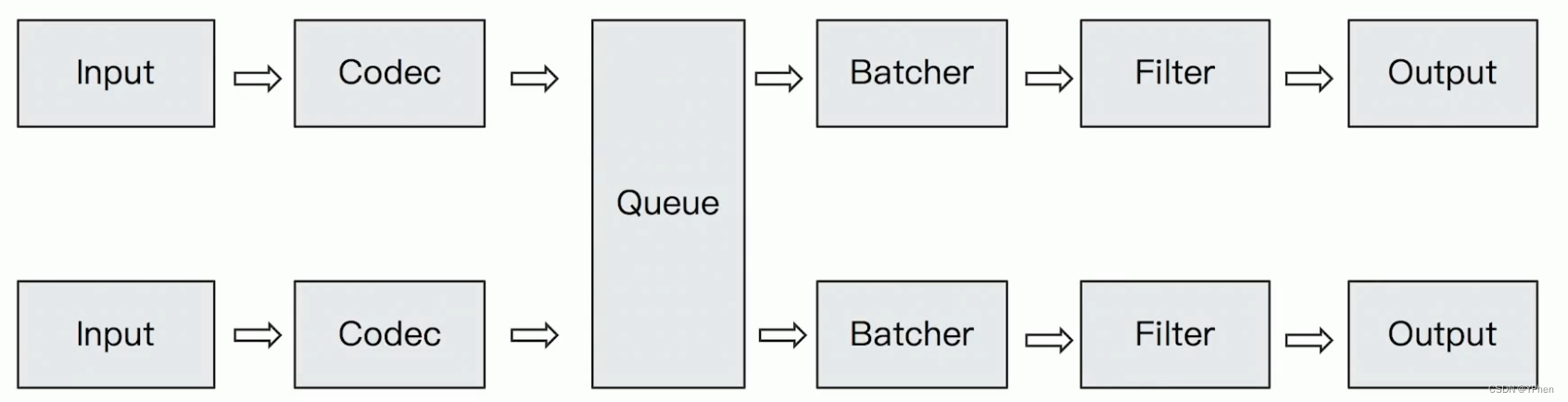
二、Logstash安装
- 从官网下载 Logstash并解压,Linux 直接用 wget 命令下载:
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.7.0-linux-x86_64.tar.gz
tar -zxvf logstash-8.7.0-linux-x86_64.tar.gz
- 通过命令测试:
//-e选项表示,直接把配置放在命令中,可以快速进行测试
bin/logstash -e 'input {
stdin {
} } output {
stdout {
} }'
当看到 Pipelines running … 表示启动完成,输入 “Hello” 测试,结果如下:
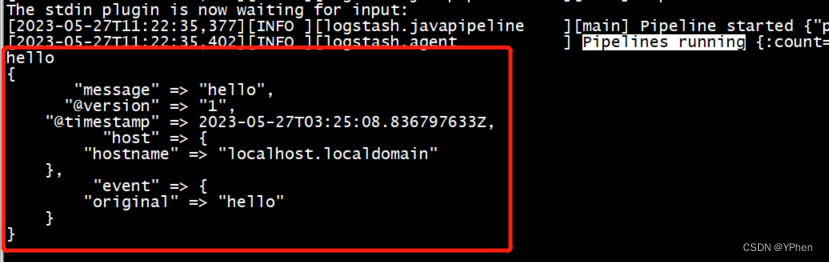
在我输入了 ‘Hello’ 之后,输入的信息通过 message 输出出来,测试成功。
- Codec Plugin测试
//此处 Codec 输入要求是json 格式的数据。
bin/logstash -e "input{stdin{codec=>json}}output{stdout{codec=> rubydebug}}"

三、管道配置
3.1 通过文件读取数据
- 管道配置:
注: 在 Logstash 的管道中,mutate 是一个插件,它可以对数据进行变换和处理,用于对数据进行了多个变换操作。
内置了很多插件,这里只做一个示例。
//输入配置,从文件中输入
input {
file {
path => "/home/movies.csv"
//从文件起始位置开始读取
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
//处理器管道配置
filter {
//CSV过滤器:该过滤器接受来自CSV格式的数据,并使用逗号(,)分割,并且定义了每个列的名称。
csv {
separator => ","
columns => ["id","content","genre"]
}
//CSV转换器:该过滤器对 genre 字段用 "|" 进行了分割;移除了 "path","host","@timestamp","message" 列。
mutate {
split => {
"genre" => "|"}
remove_field => ["path", "host", "@timestamp", "message"]
}
//对 content 字段用 "(" 进行切分,它将这些关键字用 "%{[content][0]}和 "%{[content][1]} 分别表示,增加了两个字段 title 和 year。;移除了 "path","host","@timestamp","message" 和 "content" 这些字段。
mutate {
split => ["content", "("]
add_field => {
"title" => "%{[content][0]}"}
add_field => {
"year" => "%{[content][1]}"}
}
//把 year 字段值转换为 integer 类型;移除了字段。
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
//输出:该管道的最后一个部分是将数据发送到 Elasticsearch 中的 movies index。
output {
elasticsearch {
hosts => "http://192.168.1.10:9200"
index => "movies"
document_id => "%{id}"
}
//stdout 输出:该管道的最后一个部分是将日志输出到控制台。
stdout {
}
}
- 运行管道
bin/logstash -f config/logstash-stdin.conf
- 管道运行中
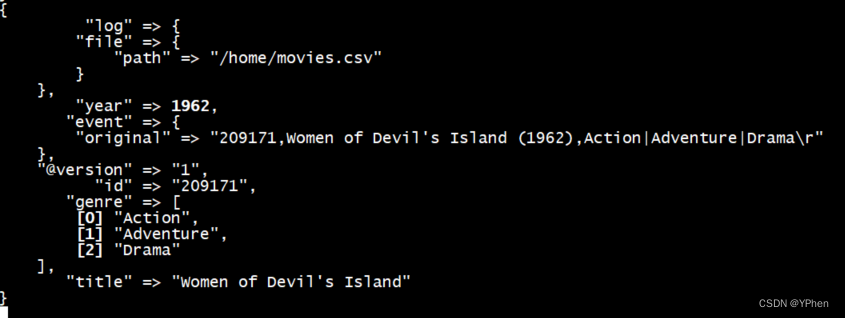
3.2 JDBC读取数据
- 管道配置
input {
jdbc {
jdbc_driver_library => "/usr/local/software/logstash-8.7.0/driver/mysql-connector-java-8.0.28.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.1.7:3306/wesh?useSSL=false"
jdbc_user => "root"
jdbc_password => "123456"
//启用追踪,如果为true,则需要指定tracking_column
use_column_value => true
//指定追踪的字段
tracking_column => "last_updated"
//追踪字段的类型,目前只有数字(numeric)和时间类型(timestamp),默认是数字类型
tracking_column_type => "numeric"
record_last_run => true
//上面运行结果的保存位置
last_run_metadata_path => "jdbc-position.txt"
statement => "SELECT * FROM user where last_updated >:sql_last_value;"
schedule => " * * * * * *"
}
}
output {
elasticsearch {
document_id => "%{id}"
document_type => "_doc"
index => "users"
hosts => ["http://192.168.1.10:9200"]
}
stdout{
codec => rubydebug
}
}
- 运行管道
bin/logstash -f config/logstash-jdbc.conf
四:总结
logstash 是用插件的方式进行配置处理器的,默认提供了各类的插件,只需要在 filter 中配置 处理插件即可,从各种数据库或者网页中拉取数据,经过处理器在输出数据到 ES 中。
logstash 可以:
- 实现日志搜索和分析,从而识别、解决和跟踪故障和安全漏洞。
- 支持复杂的数据源,包括文件、数据库、Web 应用程序和其他传感器。
- 使用自定义模板,可以快速添加新的、高度可配置的特性和功能。
特点: - 强大的日志搜索和分析能力。
- 简单的管理和配置。
- 高度可扩展性,可以在生产环境中运行。
- 可定制性强,可以添加自定义模板和脚本。
- 支持各种数据源。
- 自动化和快速添加新的特性和功能。
工作中,可以有效的使用 logstash 来收集日志,方便来排查和追踪线上的问题;可以实时监控数据更新,同步上线更新数据等。