概述
物体识别(Object recognition)是一个通用术语,描述一组相关的计算机视觉任务,涉及识别图像中的物体。
图像分类涉及预测图像中一个对象的类别,对象定位是指识别图像一个或多个对象的位置,并在其周围绘制边框。物体识别将这两种任务结合起来,对图像中的一个或多个对象进行定位和分类,所以当人们提到物体检测或者目标检测时,其实指的是物体识别。
基于区域的卷积神经网络 (R-CNN) 是一系列卷积神经网络模型,专为目标检测而设计。R-CNN 是一种两阶段检测算法。第一阶段识别图像中可能包含对象的区域子集。第二阶段对每个区域中的对象进行分类。
R-CNN系列模型有四种主要变体,分别是R-CNN、Fast R-CNN、Faster R-CNN、MaskR-CNN。每个变体都试图优化、加速或增强算法过程中的一个或多个的结果,但不管变体如何变化,其算法流程是基本如一的。使用 R-CNN 进行目标检测的基本过程过程如下
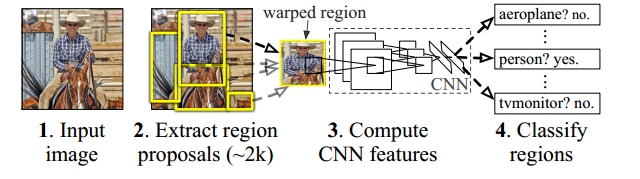
- 将图像作为输入并从图像中提取大约 2000 个region proposals(可能包含物体的边界框)。
- 将每个region proposals扭曲(重塑)到固定大小,作为 CNN 的输入传递。
- CNN 为每个region proposals提取一个固定长度的特征向量。
- 这些特征用于使用特定于类别的线性 SVM,对region proposals进行分类
CNN神经网络
R-CNN基于CNN(卷积神经网络),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。要弄清R-CNN的基本原理,就得弄清楚为何物。
那么CNN为何物?要弄清楚这个问题,首先要清楚的是CNN为何出现,CNN的出现是为了解决BP神经网络处理图像时的缺陷。BP神经网络在处理图像时会把图像的每一个像素值作为特征输入到神经网络中,这势必会丢失掉图像的二维结构信息,在用BP神经网络对图像进行分类的时候,图像中的物体不能移动、不能变形,否则会带来识别时的错误。并且BP神经网络中的神经元都采用全连接的方式,这会造成权重矩阵过大,运算量大。因为这些原因,用BP神经网络处理图像时一度遇到了瓶颈,而CNN为了解决这一系列的问题横空出世。
我们知道传统的BP神经网络是长这样的,如下图。
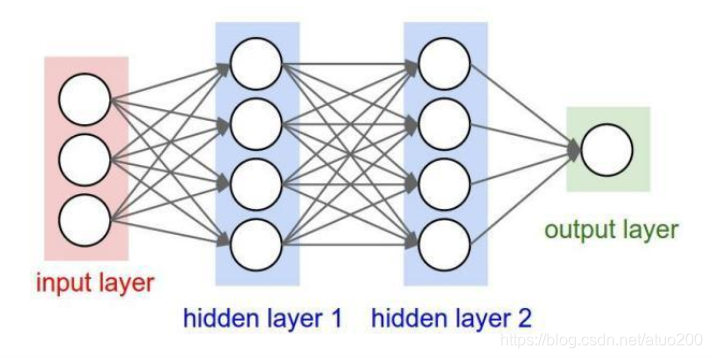
那么CNN只是在BP神经网络上的基础上对网络层级的功能和形式做了一些改变,增加了一些在BP神经网络中没有的层级,我们可以把CNN理解为是BP神经网络的一种改进体。
下图是CNN的典型结构,如图所示该CNN神经网络有7层,从左往右分别是:卷积层、池化层、卷积层、池化层、全连接层、全连接层、输出层。(请注意这里的输入特征并不算在网络的层级里)

从上图我们可以看出,卷积层和池化层实际是在做特征提取的操作,再把提取到的特征输入给全连接层(传统的BP神经网络)。
卷积层
在CNN中的第一层卷积层,先选择一个局部区域(filter)去扫描整张图片,局部区域所圈起来的所有节点会和filter做乘法累加操作,再连接到下一层的一个节点上。假设要扫描的图片是一张灰度图片(也就是只有一个颜色通道),所有的filter也是个二维的矩阵,那个该卷积过程可以用如下动图表示。
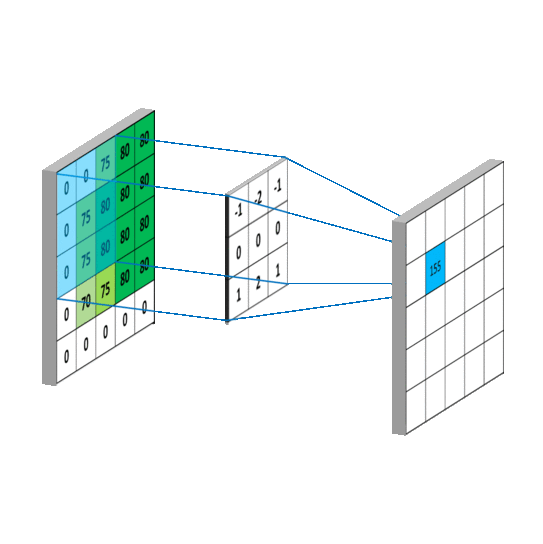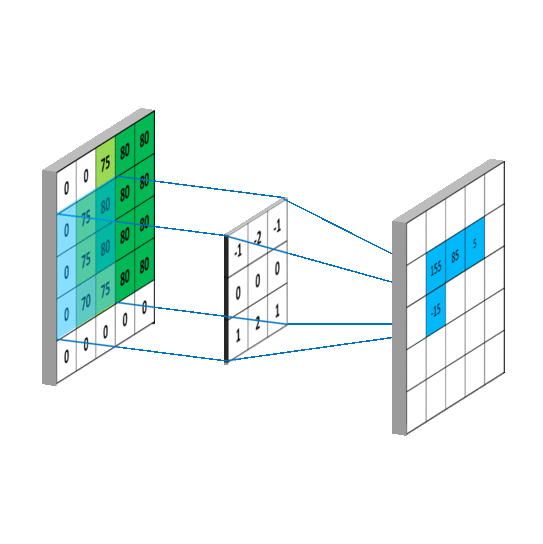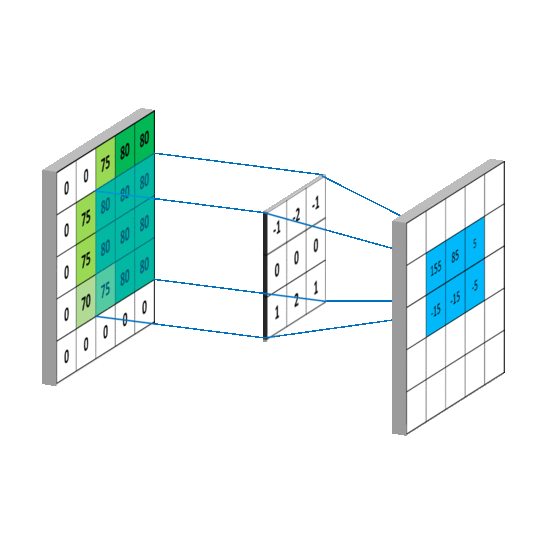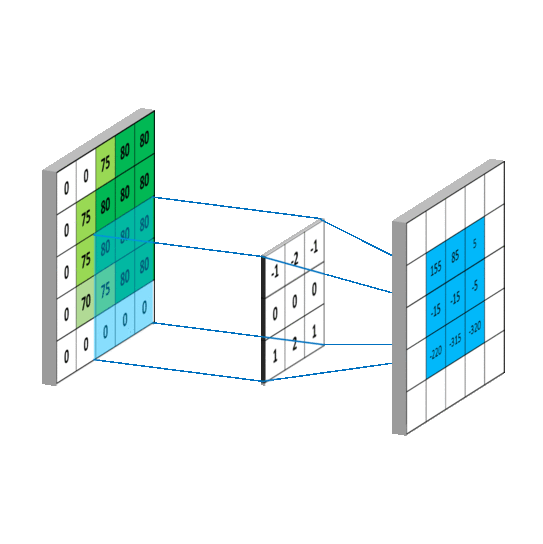
那假如卷积层要扫描的图片是张彩色图片(也就是该图片有RGB三个通道),那么图片的像素可以表示成三维结构,所选用的filter也是个三维结构,如图所示。

也用一张动图表示一下该卷积过程。
请注意一个filter卷积一张图片(无论图片是单通道还是多通道)只能得到一个面的信息,多个filter得到多个面(形象的理解可以这么理解),可以把filter扫描图片(卷积)的过程看做是提取特征的过程,一次卷积提取图片一类的特征(比如多次filter分别提取图片红通道、绿通道、蓝通道的像素特征)
池化层
如果输入是图像的话,那么池化层的最主要作用就是压缩图像。假如池化层夹在连续的卷积层中间, 那么就是用于压缩上一层卷积层卷积下来的数据(或者也可以理解为过滤),减小过拟合。
池化层的工作过程同样也可以用一张动图简单表示。
上图对于每个3 * 3的窗口选出最大的数作为输出矩阵的相应元素的值,比如输入矩阵第一个3 * 3窗口中最大的数是5,那么输出矩阵的第一个元素就是5,如此类推。请注意这里的窗口每次扫描过的像素不出现重复,避免重复过滤像素。
全连接层
通常全连接层在卷积神经网络尾部,跟传统的神经网络神经元的连接方式是一样的,全连接层把前面卷积层和池化层的输出作为特征值进行网络的训练,而利用反向传播算法修正全连接层的参数和阈值以及之前卷积层filter的权重等。
综上所述,卷积神经网络(CNN)是BP神经网络的一种变体,它不再像BP神经网络那样把图片的像素值作为模型的特征进行训练,而是把图片的像素值经过一系列的处理后(卷积、池化)输出的值作为特征喂给模型训练。这种做法的好处是能保留图片的多维信息,提高模型分类的精度。
查找图像中可能含有物体的边界框

Region proposals 是可能包含物体的边界框,由(x,y,h,w)组成的元组表示。(x,y)是边界框中心的坐标,(h,w) 分别是边界框的高度和宽度。这些region proposals是通过被称为selective search算法计算的。对于一张图像,大约提取了2000个region proposals。
从region proposals中提取CNN特征
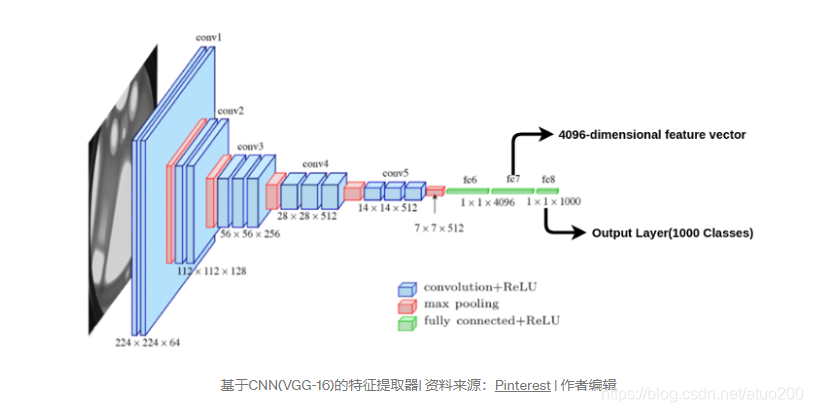
为了训练 CNN 进行特征提取,使用来自imagenet数据的预训练权重初始化 VGG-16 等架构。具有 1000 个类的输出层被切断。所以当一个region proposals图像(,由于CNN中全连接层的限制,传递之前region proposals需调整成固定的大小,以满足CNN的输入限制)被传递到网络时,我们得到一个 4096 维的特征向量
当提取所有region proposals(大约2000个region proposals)输入给CNN网络模型,最终会得到feature map(4096*2000)。得到feature map后下一步即可对每一个region进行分类,识别出每一个region里的物体是哪种物体。
使用提取的特征对物体进行分类
将feature map的每一个feature,也就是每一个region的feature都送入每一个SVM二分类器进行检测,输出属于该类的概率,假如有20个SVM二分类器,那么会得到2000*20的矩阵,该矩阵为region proposals属于每个类的概率。region proposals会被分配到获得最高概率的类别。因此,图像中的所有 2000 个region proposals都标有类标签和属于该类的概率。在这么多region proposals中,很多都是多余的和重叠的边界框,需要删除。为了实现这一点,使用了非最大抑制算法。
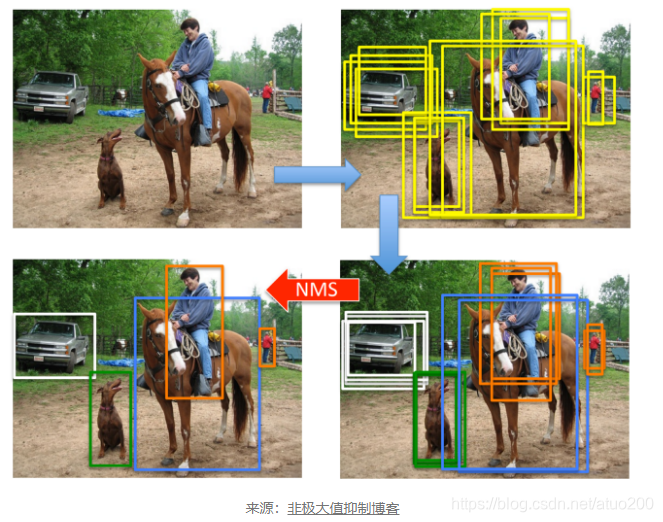
非极大值抑制是一种贪心算法。它选择使用 SVM 获得的最高概率的框。然后它计算属于该类的所有其他边界框的 IoU 分数。IoU 分数大于阈值(可自行定义阈值大小,一般来说阈值定义为0.7)的框被删除。换句话说,具有非常高重叠的边界框被移除。然后选择下一个得分最高的框,依此类推,直到删除该类的所有重叠边界框。对所有类都这样做以获得如上所示的结果。
代码实现
选用的进行物体识别的原图

这里我们选择用PyTorch中的 faster R-CNN目标检测器来进行物体识别,首先需要安装PyTorch。
pip install torch
开始编写代码,首先导入所需的包
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
import torchvision
import numpy as np
import cv2
下载预训练的模型,Resnet50 Faster R-CNN,模型里面已带有训练好的权重参数。
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.eval()
定义PyTorch官方文档给出的分类名称
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
定义一个新函数get_prediction(),用于输入图像路径,对图像中的物体进行识别。首先从图像路径中获取图像,并将图像转为为图像张量,向模型传递图像张量以得到图像物体识别结果pred
def get_prediction(img_path, threshold):
img = Image.open(img_path)
transform = T.Compose([T.ToTensor()])
img = transform(img)
pred = model([img])
从pred中提取图中每一个region proposal物体分类的类别pred_class、图中物体所在的坐标pred_boxes、图中物体所在分类的概率pred_score,进行阈值过滤之后(类别概率置信度低于阈值的region 过滤掉)再打印显示出来,最后把识别结果返回。
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_boxes = [[(i[0], i[1]), (i[2], i[3])] for i in list(pred[0]['boxes'].detach().numpy())]
pred_score = list(pred[0]['scores'].detach().numpy())
pred_t = [pred_score.index(x) for x in pred_score if x > threshold][-1]
pred_boxes = pred_boxes[:pred_t+1]
pred_class = pred_class[:pred_t+1]
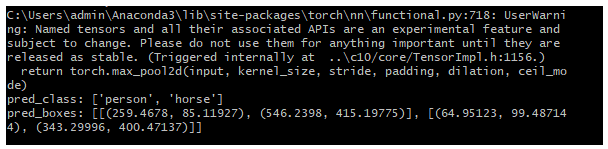
print("pred_class:",pred_class)
print("pred_boxes:",pred_boxes)
return pred_boxes, pred_class
定义一个新函数object_detection_api(),用于调用上面定义的函数get_prediction(),得到图像中的物体识别结果,并将识别结果绘制出来
def object_detection_api(img_path, threshold=0.5, rect_th=3, text_size=3, text_th=3):
boxes, pred_cls = get_prediction(img_path, threshold)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for i in range(len(boxes)):
cv2.rectangle(img, boxes[i][0], boxes[i][1],color=(0, 255, 0), thickness=rect_th)
cv2.putText(img,pred_cls[i], boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size, (0,255,0),thickness=text_th)
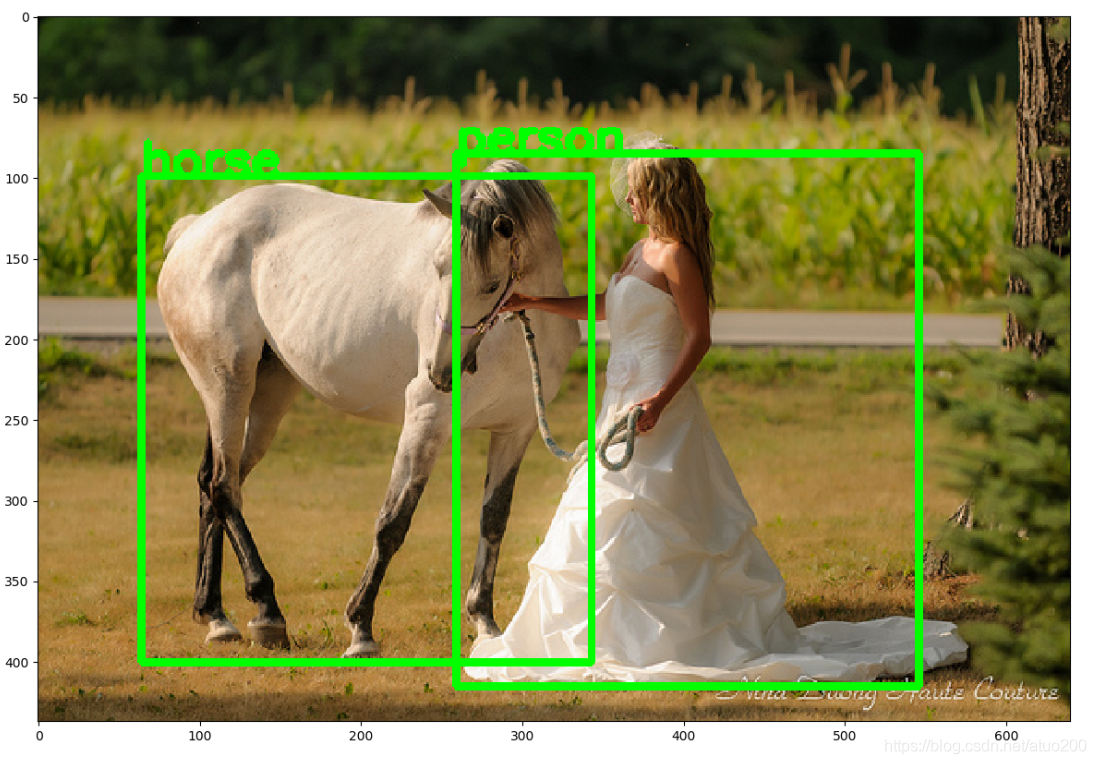
plt.imshow(img)
plt.show()
最后调用object_detection_api()函数,传入要进行物体识别的图像路径,对图像进行物体识别
if __name__ == '__main__':
object_detection_api(img_path="images/8433365521_9252889f9a_z.jpg")
得到物体识别结果打印到控制台上,并使用matplotlib把它们绘制了出来