论文
论文信息
题目: DROID-SLAM: Deep Visual SLAM for Monocular,Stereo, and RGB-D Cameras
作者:Zachary Teed, Jia Deng
代码地址:https://github.com/princeton-vl/DROID-SLAM
时间:2021
Abstract
我们介绍 DROID-SLAM,一种新的基于深度学习的 SLAM 系统。 DROIDSLAM 由通过密集束调整层( Dense Bundle Adjustment layer)对相机姿态和像素深度进行循环迭代更新组成。 DROID-SLAM 非常准确,比之前的工作取得了很大的改进,而且很稳健,灾难性故障的发生率大大降低。尽管使用单目视频进行训练,但它可以利用立体或 RGB-D 视频来提高测试时的性能。
Introduction
传统SLAM系统缺陷:Failures come in many forms, such as lost feature tracks, divergence in the optimization algorithm, and accumulation of drift.
Deep Learning结合的方法:可以解决部分问题,但是精度远不及经典方法
DROID-SLAM特点:
High Accuracy:TartanAir SLAM competition 、ETH-3D RGB-D、EuRoC
High Robustness: catastrophic failures更少
Strong Generalization:跨 4 个数据集和 3 种模式的所有结果都是通过单个模型实现的
DROID-SLAM核心:“Differentiable Recurrent Optimization-Inspired Design” (DROID)
基于RAFT+两个创新点
- we iteratively update camera poses and depth; are applied to an arbitrary number of frames
- each update of camera poses and depth maps in DROID-SLAM is produced by a differentiable Dense Bundle Adjustment (DBA) layer
与DeepV2D和BA-Net的不同:(等我读了这两篇论文再细看)
DROID-SLAM的设计新颖。最接近的现有深度架构是 DeepV2D [48] 和 BA-Net [47],两者都专注于深度估计并报告了有限的 SLAM 结果。 DeepV2D 在更新深度和更新相机姿势之间交替,而不是捆绑调整。 BA-Net 有一个捆绑调整层,但它们的层有很大不同:它不是“密集”的,因为它优化用于线性组合深度基础(一组预先预测的深度图)的少量系数,而我们直接优化每个像素的深度,而不会受到深度基础的阻碍。此外,BA-Net 优化了光度重投影误差(在特征空间中),而我们利用最先进的流量估计来优化几何误差。
Related Work
VSLAM
分为直接法(direct)和间接法(indirect):
间接法:检测特征进行匹配,最小化重投影误差来优化相机姿态和3D点云
直接法:对图像形成过程进行建模,并定义光度误差的目标函数,优点在于可以对有关图像的更多信息进行建模,例如间接方法不使用的线条和强度变化。然而,光度误差通常会导致更困难的优化问题,并且直接方法对于卷帘快门伪影等几何失真的鲁棒性较差。这种方法需要更复杂的优化技术,例如从粗到细的图像金字塔以避免局部最小值。
我们的方法显然不适合这两类。与直接方法一样,我们不需要预处理步骤来检测和匹配图像之间的特征。相反,我们使用完整图像,这使我们能够利用比通常仅使用角和边缘的间接方法更广泛的信息。然而,与间接方法类似,我们最小化了重投影误差。这是一个更容易的优化问题,并且避免了对更复杂的表示(例如图像金字塔)的需要。从这个意义上说,我们的方法借鉴了两种方法的优点:间接方法更平滑的目标函数和直接方法更大的建模能力。
Deep Learning
深度学习最近被应用于 SLAM 问题。许多工作都集中在特定子问题的训练系统上,例如特征检测、特征匹配和异常值拒绝以及定位。
其他工作主要集中在端到端训练 SLAM 系统 。这些方法不是完整的 SLAM 系统,而是专注于两帧到十几个帧 的小规模重建。它们缺乏现代 SLAM 系统的许多核心功能,例如闭环和全局束调整,这限制了它们执行大规模重建的能力,正如我们的实验所证明的那样。 ∇SLAM将几种现有的 SLAM 算法实现为可微分计算图,允许将重建中的误差反向传播回传感器测量。虽然这种方法是可微分的,但它没有可训练的参数,这意味着系统的性能受到它们模拟的经典算法的准确性的限制。
DeepFactors[9] 是最完整的深度 SLAM 系统,建立在早期的 CodeSLAM[1] 之上。它执行位姿和深度变量的联合优化,并且能够进行短程和长程闭环。与 BA-Net[47] 类似,DeepFactors 在推理过程中优化学习深度基础的参数。相反,我们不依赖于学习的基础,而是优化像素深度。
Approach
Representation:

Feature Extraction and Correlation
特征提取和关联这一部分与RAFT中的特征网络和相关信息体correlation volume完全一致.
特征提取网络: feature network由6个残差模块和3个下采样层组成, 生成输入图像1/8分辨率的feature map; context network提取图像全局信息, 作为下文更新算子的一个输入;
Correlation Pyramid: 对于frame-graph中的每条边, 本文使用点积计算一个4D的correlation volume:
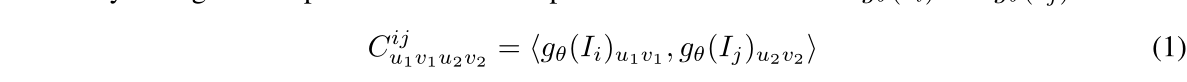
Correlation Lookup: 根据像素坐标和查找半径, 查找算子会在不同分辨率的correlation volume上查找对应的相关信息张量,最后将他们拼接为一个feature vector;
Update Operator
DROID-SLAM的核心模块
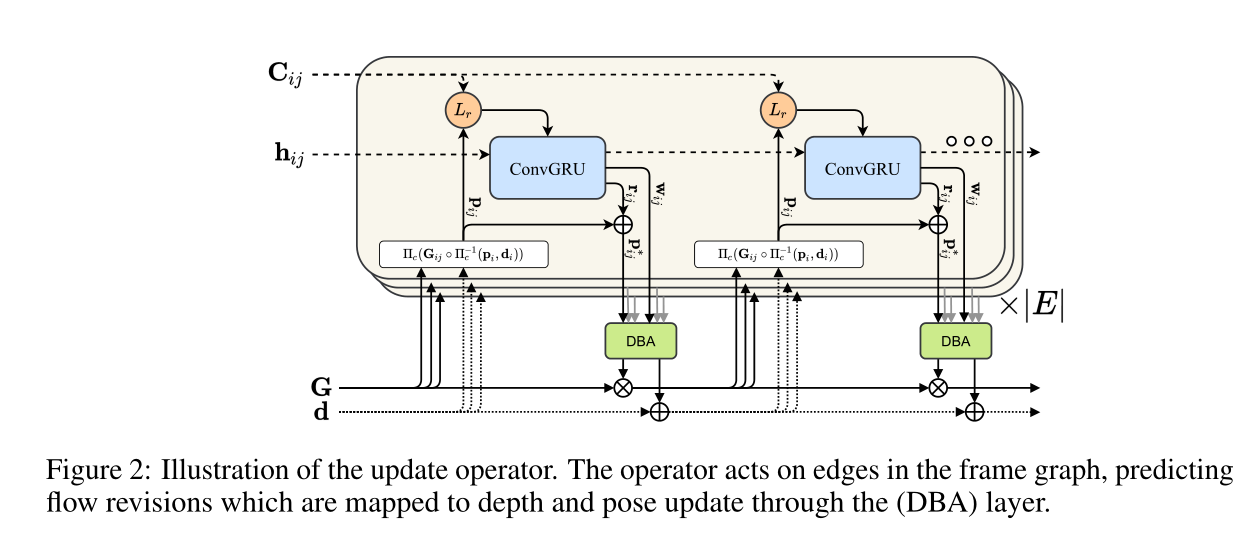
C i j C_{ij} Cij是图像 I i I_i Ii与 I j I_j Ij之间的相关信息张量,h_{ij}是隐藏状态,每轮更新之后, h i j h_{ij} hij会被更新,并且输出位姿变化 Δ ξ ( k ) \Delta \xi^{(k)} Δξ(k)和深度变化 Δ d ( k ) \Delta d^{(k)} Δd(k),然后更新下一帧的位姿和深度:
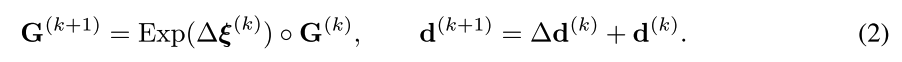 Correspondence:在每次更新前,根据当前的pose和depth,对于图像 I i I_i Ii中的每个网格,网格中的像素坐标集合 p i ∈ R H × W × 2 p_i\in \mathbb{R}^{H\times W\times 2} pi∈RH×W×2,那么它在图像 I j I_j Ij上的对应网格像素集合 p i j p_{ij} pij可以表示为:
Correspondence:在每次更新前,根据当前的pose和depth,对于图像 I i I_i Ii中的每个网格,网格中的像素坐标集合 p i ∈ R H × W × 2 p_i\in \mathbb{R}^{H\times W\times 2} pi∈RH×W×2,那么它在图像 I j I_j Ij上的对应网格像素集合 p i j p_{ij} pij可以表示为:
(这个就是光流对应的那个公式概述性的说法)
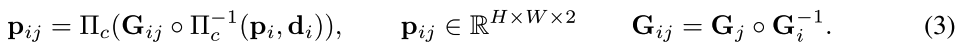
input:根据上一步计算得到的grid correspondence, 查找两张图像的correlation volume C i j C_{ij} Cij; 同时可以根据 p i p_i pi 和 p i j p_{ij} pij 计算两张图像之间的光流场flow fileds. C i j C_{ij} Cij表征的是两张图像之间的视觉一致程度, 更新模块的目标是计算相对位姿来对齐两张图像使之一致性最大化. 但是因为视觉一致性会存在奇异, 因此我们同时利用光流场来提高位姿估计的鲁棒性.
update:与RAFT网络一样, correlation features 和 flow features经过两层卷积之后, 与context feature一同送入GRU模块. 在GRU模块中, 本文对隐藏状态 h i j h_{ij} hij作average pooling来提取global context, global context对于提高剧烈运动物体的光流估计鲁棒性有帮助。
GRU模块可以同时更新隐藏状态得到 h k + 1 h^{k+1} hk+1,我们利用这个隐藏状态张量得到光流场的变化量 r i j ∈ R R × W × 2 r_{ij}\in \mathbb{R}^{R\times W \times 2} rij∈RR×W×2和对应的置信度 w i j ∈ R R × W × 2 w_{ij}\in \mathbb{R}^{R\times W \times 2} wij∈RR×W×2,则修正后的网格 p i j ∗ = r i j + p i j p_{ij}^*=r_{ij}+p_{ij} pij∗=rij+pij.
再利用 h ( k + 1 ) h_{(k+1)} h(k+1)得到pixel-wise的阻尼系数 λ \lambda λ和用于深度估计过程中的8x8的上采样mask;
Dense Bundle Adjustment Layer:
首先, DBA层将更新模块输出的稠密光流场变化量转换为相机位姿和稠密深度值: 这里的相机位姿可以使用传统方法计算得到, 深度值则是根据下面的目标函数和舒尔补公式, 迭代优化的方式得到的:
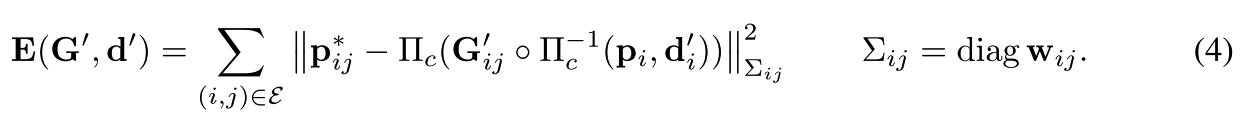
这里仍然是使用Guass-Newton法计算位姿和深度的变化量, 利用舒尔补先计算位姿变化量, 再计算深度变化量
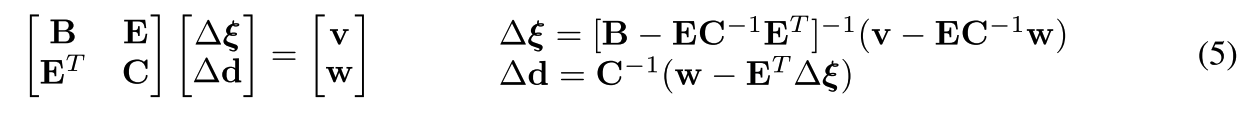
分别代表相机位姿和深度的梯度方向.
DBA 层的实现和反向传播是基于LieTorch实现的, 是一个李群李代数的pytorch实现的package.
训练过程
单目尺度问题: 为了解决单目SLAM尺度问题, 我们把前两帧图像位姿固定为ground truth.
采样视频/图像序列: 为了使我们的网络泛化能力更好, 我们通过计算图像序列中任意两张图像之间的光流场距离, 对这样的 N i × N i N_i\times N_i Ni×Ni flow distance matrix进行采样,得到采样后的新的图像序列形成的视频来输入网络进行训练.
监督和loss: 监督信息是ground truth pose和ground truth flow. loss是 网络预测的flow fileds与ground truth flow fileds的 loss. 图像位姿loss则是 
SLAM system
和以前的SLAM系统一样, 本文方法实现的SLAM系统也包括前端和后端两个线程. 前端线程提取特征、选取关键帧、局部优化. 后端线程对所有关键帧进行全局优化.
初始化: 选择视频中前部的12帧图像来完成初始化, 相邻两帧图像之间的光流必须大于16px, 12帧图像集齐后, 我们建立起一个frame-graph, 并且运行10次更新算子的迭代.
视觉前端: 前端部分选取并维护着关键帧序列. 新的图像到来时, 进行特征提取、计算光流场, 并根据光流场计算3个与之共视程度最大的关键帧, 然后根据共视关系来迭代更新当前关键帧的pose和depth. 同时, 前端部分也负责边缘化操作.
后端优化: 后端部分将所有关键帧进行BA优化. 每次进行更新迭代时,都会对所有关键帧重新构建frame-graph, 这是根据所有关键帧之间的光流场距离矩阵来构建的. 接着在frame-graph上运行更新算子, 在BA缓解我们使用的是LieTorch. 后端网络只在关键帧上运行BA优化, 对于视频中的普通帧, 只优化相机pose.
Stereo and RGB-D:
为了使我们设计的这个SLAM系统能够很好的应用到双目和RGB-D的场景中, 我们会在Stereo和RGB-D的情景中对公式(4)做一些修改. 比如在RGB-D场景中, 公式4添加一个残差项: 估计的depth map与测量的depth map之间的距离平方和. 在Stereo场景中, 公式4改为左右两个相机的位姿重投影误差.
实验结果
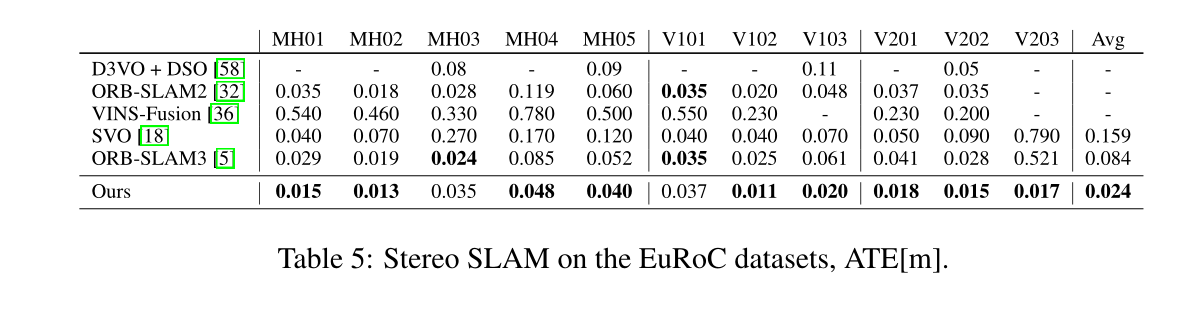
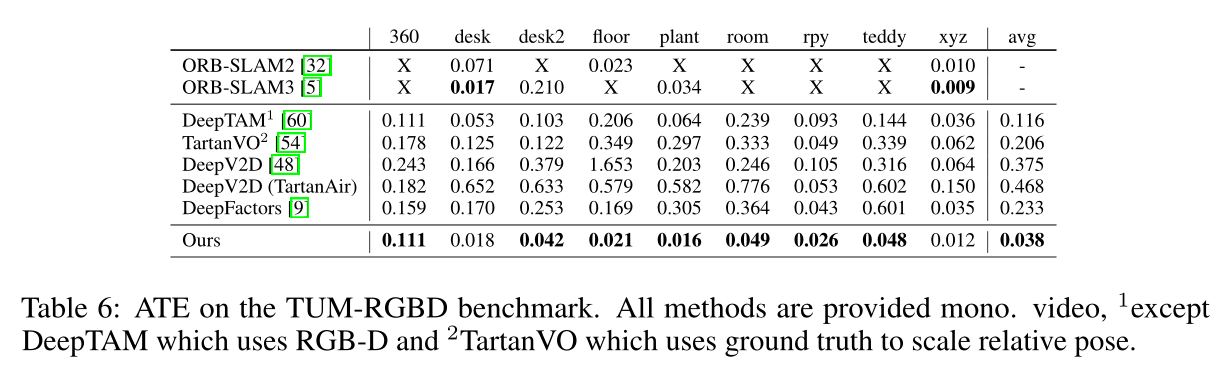
本文提出的方法在多个数据集上进行了充分的实验, 并且和其他深度学习方法以及经典的SLAM算法做了比较.
实验部分着重比较了相机轨迹的绝对轨迹误差ATE.
本文中的网络在合成的数据集TartanAir上面训练了250k次, 图像分辨率为384x512, 在4块 RTX-3090上训练了1周时间.

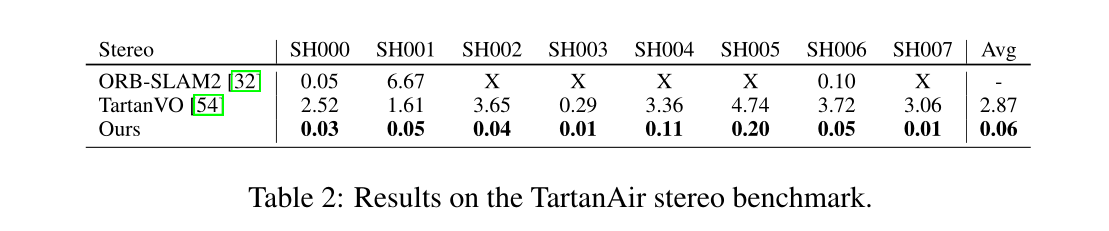

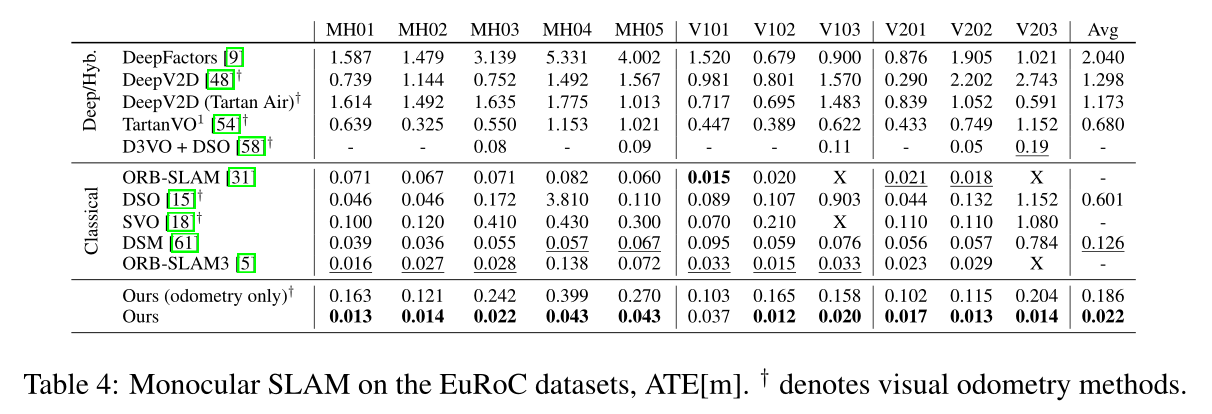
在EuRoc和TUM-RGB-D数据集上也做了充分的实验, 实验证明,本文网络可以很好的泛化到Stereo和RGB-D上,同时取得很高的精度和鲁棒性.
我的感受
从结果来看,提升很大,但是这类方法对于算力和GPU的要求都相当高呀,害怕~