1.SpringBoot处理url需要用到哪些注解?
@RequestMappin
是 Spring Web 应用程序中最常被用到的注解之一。这个注解会将 HTTP 请求映射到 MVC 和 REST 控制器的处理方法上@GetMapping用于将HTTP get请求映射到特定处理程序的方法注解
@RequestBody
通过HttpMessageConverter读取Request Body并反序列化为Object(泛指)对象@PathVariable:获取url中的数据
@RequestParam:获取请求参数的值
@RequestHeader 把Request请求header部分的值绑定到方法的参数上
@CookieValue 把Request header中关于cookie的值绑定到方法的参数上
2.说出一种springboot注解的作用和底层实现
@springbootApplication用于注明springboot启动类。
@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Documented @Inherited @SpringBootConfiguration @EnableAutoConfiguration @ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class), @Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) }) public @interface SpringBootApplication { @AliasFor(annotation = EnableAutoConfiguration.class) Class<?>[] exclude() default {}; @AliasFor(annotation = EnableAutoConfiguration.class) String[] excludeName() default {}; @AliasFor(annotation = ComponentScan.class, attribute = "basePackages") String[] scanBasePackages() default {}; @AliasFor(annotation = ComponentScan.class, attribute = "basePackageClasses") Class<?>[] scanBasePackageClasses() default {}; }其中@SpringBootConfiguration注解上又标注了@Configuration注解,@Configuration注解上也标注了@Component注解即Spring的模式注解。SpringBootConfiguration注解的作用就是把类变成可以被Spring管理的Bean。
@EnableAutoConfiguration,从名字上我们就可以看到“启用自动装配”的意思。其中包含@AutoConfigurationPackage和@Import注解。@AutoConfigurationPackage注解中,发现该注解又启用了一个模块装配@Import(AutoConfigurationPackages.Registrar.class)(上一章节有讲到);所以又点进去AutoConfigurationPackages.Registrar.class这个类,发现这个类又实现了两个接口ImportBeanDefinitionRegistrar和DeterminableImports 在该类的实现方法中的PackageImport()
@Import注解,是模块装配的接口实现方式。AutoConfigurationImportSelector > AutoConfigurationImportSelector.selectImports() ->getAutoConfigurationEntry() -> getCandidateConfigurations() >SpringFactoriesLoader.loadFactoryNames() -> loadFactoryNames() ->loadSpringFactories() ;
3.sql语句查询学生表中所有有着相同的名字的人的信息
select *
from 学生表
where 姓名 in
(selecct 姓名
from 学生表
group by 姓名
having count(*)>1 )4.Hadoop原生的Mapreduce过程
MapReduce 就是将输入进行分片,交给不同的 Map 任务进行处理,然后由 Reduce 任务合并成最终的解。
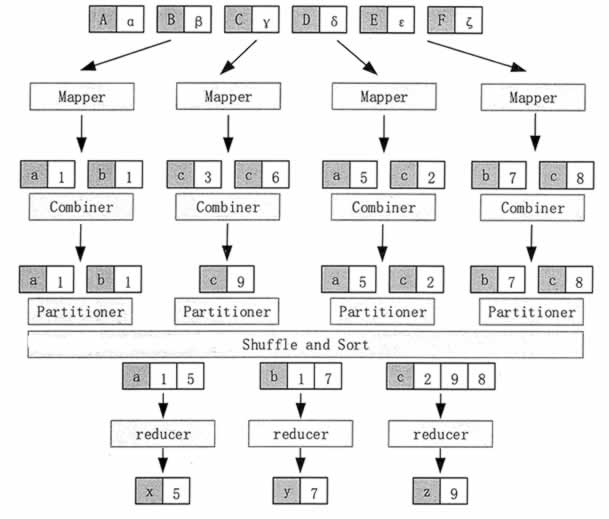
MapReduce 的实际处理过程可以分解为 Input、Map、Sort、Combine、Partition、Reduce、Output 等阶段,具体的工作流程如图 1 所示。
图 MapReduce 的工作流程
在 Input 阶段,框架根据数据的存储位置,把数据分成多个分片(Splk),在多个结点上并行处理。
Map 任务通常运行在数据存储的结点上,也就是说,框架是根据数据分片的位置来启动 Map 任务的,而不是把数据传输到 Map 任务的位置上。这样,计算和数据就在同一个结点上,从而不需要额外的数据传输开销。
在 Map 阶段,框架调用 Map 函数对输入的每一个 <key,value> 进行处理,也就是完成 Map<K1,V1>→List(<K2,V2>) 的映射操作。图 1 为找每个文件块中每个字母出现的次数,其中,K1 表示字母,V2 表示该字母出现的次数。
在 Sort 阶段,当 Map 任务结束以后,会生成许多 <K2,V2>形式的中间结果,框架会对这些中间结果按照键进行排序。图 1 就是按照字母顺序进行排序的。
在 Combine 阶段,框架对于在 Sort 阶段排序之后有相同键的中间结果进行合并。合并所使用的函数可以由用户进行定义。在图 1 中,就是把 K2 相同(也就是同一个字母)的 V2 值相加的。这样,在每一个 Map 任务的中间结果中,每一个字母只会出现一次。
在 Partition 阶段,框架将 Combine 后的中间结果按照键的取值范围划分为 R 份,分别发给 R 个运行 Reduce 任务的结点,并行执行。分发的原则是,首先必须保证同一个键的所有数据项发送给同一个 Reduce 任务,尽量保证每个 Reduce 任务所处理的数据量基本相同。
在图 1 中,框架把字母 a、b、c 的键值对分别发给了 3 个 Reduce 任务。框架默认使用 Hash 函数进行分发,用户也可以提供自己的分发函数。
在 Reduce 阶段,每个 Reduce 任务对 Map 函数处理的结果按照用户定义的 Reduce 函数进行汇总计算,从而得到最后的结果。在图 1 中,Reduce 计算每个字母在整个文件中出现的次数。只有当所有 Map 处理过程全部结束以后,Reduce 过程才能开始。
在 Output 阶段,框架把 Reduce 处理的结果按照用户指定的输出数据格式写入 HDFS 中。
在 MapReduce 的整个处理过程中,不同的 Map 任务之间不会进行任何通信,不同的 Reduce 任务之间也不会发生任何信息交换。用户不能够显式地从一个结点向另一个结点发送消息,所有的信息交换都是通过 MapReduce 框架实现的。
5.RDD两种操作及区别
转化操作(transformation),即从现有的数据集创建一个新的数据集;行为操作(action),即在数据集上进行计算后,返回一个值给程序。
RDD 的转化操作是返回一个新的 RDD 的操作,比如 map() 和 filter() ,而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如 count() 和 first() 。Spark 对待转化操作和行动操作的方式很不一样,因此理解你正在进行的操作的类型是很重要的。如果对于一个特定的函数是属于转化操作还是行动操作感到困惑,你可以看看它的返回值类型:转化操作返回的是 RDD,而行动操作返回的是其他的数据类型。