Python
python有哪些数据类型?
Python支持多种数据类型,包括以下常见的数据类型:
-
数字类型:整数(int)、浮点数(float)和复数(complex)。
-
字符串类型:由字符组成的不可变序列,使用引号(单引号或双引号)括起来。
-
列表(List):有序的可变序列,可以包含不同类型的元素,用方括号括起来。
-
元组(Tuple):有序的不可变序列,可以包含不同类型的元素,用小括号括起来。
-
集合(Set):无序且元素唯一的容器,用大括号括起来。
-
字典(Dictionary):键值对的无序集合,用大括号括起来,键和值之间使用冒号分隔。
-
布尔类型(Bool):表示真或假的值,只有两个取值,True和False。
-
空值(None):表示一个不存在的值或空对象。
除了以上常见的数据类型,Python还提供了其他一些特殊的数据类型,如日期时间类型(datetime)、字节类型(bytes)、字节数组类型(bytearray)等。
Python是一种动态类型的语言,变量的类型是根据值而确定的,可以根据需要在不同的数据类型之间进行转换。同时,Python还支持用户自定义的数据类型,通过类(class)来创建对象、定义属性和方法,实现更复杂的数据结构和行为。
怎么将两个字典合并?
在Python中,可以使用update()方法或**运算符将两个字典合并为一个字典。以下是具体的示例和说明:
- 使用
update()方法:update()方法用于将一个字典的键值对更新或添加到另一个字典中。如果两个字典有相同的键,那么被合并的字典中的值将被更新为新字典中的值。
dict1 = {
'a': 1, 'b': 2}
dict2 = {
'b': 3, 'c': 4}
dict1.update(dict2)
print(dict1)
# 输出: {'a': 1, 'b': 3, 'c': 4}
在上面的例子中,dict1和dict2被合并,结果存储在dict1中。由于dict2中有一个键’b’与dict1中的键重复,所以原dict1中的’b’键对应的值被更新为新值3,同时新键值对’c’: 4被添加到dict1中。
- 使用
**运算符:**运算符可以在函数调用时将字典键值对解包为参数传递。在合并字典时,可以将两个字典解包传递给一个新的字典。
dict1 = {
'a': 1, 'b': 2}
dict2 = {
'b': 3, 'c': 4}
dict_merged = {
**dict1, **dict2}
print(dict_merged)
# 输出: {'a': 1, 'b': 3, 'c': 4}
在上面的例子中,dict1和dict2被解包传递给一个新的字典dict_merged,**运算符将两个字典的键值对合并到dict_merged中。与update()方法类似,键’b’的值被更新为3,并添加了新的键值对’c’: 4。
无论是使用update()方法还是**运算符,都可以将两个字典合并成一个新的字典,根据需要选择适合的方法。
python如何将json写到文件里?
要将 JSON 数据写入文件,你可以使用 Python 的 json 模块来实现。下面是一个简单的示例:
import json
data = {
"name": "John",
"age": 30,
"city": "New York"
}
# 将数据写入 JSON 文件
with open("data.json", "w") as file:
json.dump(data, file)
在上面的示例中,我们创建了一个字典 data,其中包含要写入 JSON 文件的数据。然后,我们使用 open() 函数以写入模式打开文件,并使用 json.dump() 函数将数据写入文件中。
其中,json.dump() 函数有两个参数:要写入的数据(在本例中为 data)和要写入的文件对象(在本例中为 file)。通过执行 json.dump(data, file),JSON 数据将被写入到指定的文件中(在本例中为 data.json)。
请注意,在使用 with open() as file 语法时,with 代码块结束后,文件将自动关闭,因此你不需要进行显式地关闭文件。
运行上述代码后,将在当前目录下生成名为 data.json 的文件,并将字典 data 写入该文件中的 JSON 数据。
在except语句中return后还会不会执行finally中的代码?
在 except 语句块中执行 return 语句后,即使有 finally 语句块存在,finally 中的代码仍然会执行。
finally 块中的代码总是会在 try 块中的代码执行完毕后执行,无论是否发生了异常,或者是否在 except 语句中执行了 return 语句。即使在 except 中执行了 return,finally 仍然会被执行。
以下是一个示例来说明这一点:
def test_function():
try:
print("Inside try block")
return 1
except:
print("Inside except block")
return 2
finally:
print("Inside finally block")
result = test_function()
print("Returned value:", result)
输出结果为:
Inside try block
Inside finally block
Returned value: 1
在上述例子中,try 块中打印 “Inside try block”,然后执行了 return 1。然后,finally 块中的代码打印 “Inside finally block” 被执行。最后,函数返回值为 1。
因此,无论在 try 或 except 块中执行了 return,finally 中的代码总是会被执行。
什么是可变、不可变类型?
在 Python 中,可变(Mutable)和不可变(Immutable)是用来描述对象是否可以被修改的概念。可变对象是指可以被修改或更改其内部状态的对象,而不可变对象则是指其内部状态是不可更改的。
Python 中的不可变类型包括整数(int)、浮点数(float)、布尔值(bool)、字符串(str)、元组(tuple)等。这些对象在创建后不能更改其值或内部结构。如果尝试修改不可变对象,实际上会创建一个新的对象。
例如:
x = 5 # 整数是不可变类型
x += 1 # 修改 x,实际上创建了一个新的整数对象
print(x) # 输出:6
而可变类型包括列表(list)、字典(dict)、集合(set)等。这些对象在创建后可以修改其值、添加或删除元素等。
例如:
my_list = [1, 2, 3] # 列表是可变类型
my_list.append(4) # 直接修改 my_list
print(my_list) # 输出:[1, 2, 3, 4]
需要注意的是,不可变对象在进行某些操作时(例如字符串的拼接),可能会创建新的对象,而不是在原地修改原始对象。
了解对象的可变性对于正确地处理对象的赋值、传递和修改非常重要,可以帮助避免出现意外的行为和错误。
python函数调用时参数的传递是值传递还是引用传递?
在 Python 中,函数调用时参数的传递是"值传递"。具体来说,Python 使用的是"传递对象的引用值"的方式。
当我们调用一个函数并将参数传递给它时,实际上是将对象的引用作为参数传递给函数。这意味着在函数内部,函数参数和原始对象都引用了相同的内存地址。
在函数内部如果对传递的可变对象进行修改,会对原始对象产生影响,因为它们引用同一个对象。而对于不可变对象,由于不可更改其值,因此函数内部的操作会创建一个新的对象,而原始对象不会受到影响。
例如:
def modify_list(lst, number):
lst.append(number) # 修改传递的列表对象
number += 1 # 对传递的数字进行操作,但不会影响原始对象
my_list = [1, 2, 3]
my_number = 5
modify_list(my_list, my_number)
print(my_list) # 输出:[1, 2, 3, 5]
print(my_number) # 输出:5
可以看到,对于可变对象的修改在函数外部是可见的,而对于不可变对象的修改则没有影响。
需要注意的是,尽管参数传递的方式是"值传递",但对于可变对象,我们可以通过引用修改对象的值。这和"引用传递"有些相似,但又是不同的概念。实际上,在 Python 中并没有真正意义上的"引用传递"。
python深浅拷贝的区别
在 Python 中,深拷贝(deep copy)和浅拷贝(shallow copy)是用来复制对象的两种不同方式。(影响的是子对象)
深拷贝是在内存中创建一个全新的对象副本,包括其所有子对象,而不仅仅是复制引用。这意味着如果原对象或其子对象发生改变,深拷贝后的对象不会受到影响。深拷贝可以通过 copy.deepcopy() 函数来实现。
浅拷贝则是创建一个新对象,但是它只复制了原对象的引用而不复制子对象本身。如果原对象的子对象发生改变,浅拷贝后的对象也会相应地改变。浅拷贝可以通过 copy.copy() 函数或者切片操作来实现。
以下是深拷贝和浅拷贝的示例代码:
import copy
# 深拷贝示例
list1 = [1, 2, [3, 4]]
list2 = copy.deepcopy(list1) # 深拷贝 list1,创建了一个全新的对象副本
list2[0] = 5
list2[2][0] = 6
print(list1) # 输出:[1, 2, [3, 4]]
print(list2) # 输出:[5, 2, [6, 4]]
# 浅拷贝示例
list1 = [1, 2, [3, 4]]
list2 = copy.copy(list1) # 浅拷贝 list1,创建了一个新对象,但仍然共享其中的子对象
list2[0] = 5
list2[2][0] = 6
print(list1) # 输出:[1, 2, [6, 4]]
print(list2) # 输出:[5, 2, [6, 4]]
可以看到,深拷贝后的对象是完全独立的副本,对其进行修改不会影响原对象。而浅拷贝后的对象在某些情况下会共享原对象中的子对象,因此对子对象的修改会影响到两个对象。
需要根据具体情况来选择深拷贝还是浅拷贝,以确保程序的正确性和预期的行为。
python为什么使用*args和**kwargs
在 Python 中,*args 和 **kwargs 是两个特殊的参数,用于处理函数的可变数量的参数。它们的使用可以使函数更加灵活和通用。
*args 是一个用于传递任意数量的非关键字参数(位置参数)的参数。它允许函数接受任意数量的参数,并将其作为一个元组传递给函数体内的参数。这在函数定义时不确定要接收多少个参数时非常有用。
例如:
def sum_numbers(*args):
result = 0
for num in args:
result += num
return result
print(sum_numbers(1, 2, 3, 4)) # 输出:10
print(sum_numbers(1, 2, 3, 4, 5, 6)) # 输出:21
**kwargs 则是用于传递任意数量的关键字参数的参数。它允许函数接受任意数量的关键字参数,并将其作为一个字典传递给函数体内的参数。这在函数定义时不确定要接收多少个关键字参数时非常有用。
例如:
def build_person(**kwargs):
person = {
}
for key, value in kwargs.items():
person[key] = value
return person
print(build_person(name='Alice', age=25, city='New York'))
# 输出:{'name': 'Alice', 'age': 25, 'city': 'New York'}
使用 *args 和 **kwargs 可以简化函数的调用,并且使函数能够处理任意数量的参数。同时,它们也提供了更灵活的接口,使函数具有更高的通用性和适应性。
对Python的继承和多态的了解?父类可以用子类的方法吗?
在面向对象编程中,Python 支持继承和多态的概念。
继承是指一个类(称为子类或派生类)可以继承另一个类(称为父类或基类)的属性和方法。子类可以在不修改父类的情况下,自动获得父类的功能。子类可以重载(覆盖)继承的方法,或者添加自己独特的方法。
下面是一个简单的继承示例:
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
print("Animal speaks!")
class Cat(Animal):
def speak(self):
print("Meow!")
animal = Animal("Generic animal")
animal.speak() # 输出:Animal speaks!
cat = Cat("Tom")
cat.speak() # 输出:Meow!
在上述示例中,Animal 是父类,Cat 是子类。Cat 类继承了 Animal 类的属性和方法,并重写(覆盖)了父类的 speak 方法。
多态是指对象在不同的类之间表现出不同的行为,即同一个方法可以根据不同的对象执行不同的操作。多态允许我们以统一的方式操作多个不同的对象,提高了灵活性和可维护性。
下面是一个简单的多态示例:
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
print("Woof!")
class Cat(Animal):
def speak(self):
print("Meow!")
def animal_speak(animal):
animal.speak()
animal = Animal()
dog = Dog()
cat = Cat()
animal_speak(animal) # 输出:(什么都不输出)
animal_speak(dog) # 输出:Woof!
animal_speak(cat) # 输出:Meow!
在上述示例中,animal_speak 函数接受一个 Animal 对象作为参数,并调用其 speak 方法。根据传递的不同对象,speak 方法会表现出不同的行为,实现了多态。通过多态,我们可以在不修改函数代码的情况下,对不同的对象进行处理。
继承和多态是面向对象编程中重要的概念,它们帮助我们实现代码的重用性、可扩展性和可维护性。在 Python 中,通过继承和多态,我们可以编写更具有灵活性和可扩展性的代码。
说说你对封装的了解
封装(Encapsulation)是面向对象编程的一个重要概念,它是将数据(属性)和操作(方法)封装在一个单位(类)中,并对外界隐藏内部的实现细节,只提供有限的接口来访问和操作内部数据。
在 Python 中,封装通过使用访问控制符来实现。Python 提供了三种访问控制符:
-
公有访问控制符(Public Access Modifier):没有特殊的标记或符号,默认情况下所有的属性和方法都是公有的,可以被类的内部和外部访问。
-
私有访问控制符(Private Access Modifier):在属性和方法前添加双下划线 “__”,表示该属性或方法是私有的,只能在类的内部访问,外部无法直接访问。
-
受保护的访问控制符(Protected Access Modifier):在属性和方法前添加单下划线 “_”,表示该属性或方法是受保护的,只能在类的内部和子类中访问,外部无法直接访问。
下面是一个简单的封装示例:
class Car:
def __init__(self):
self.__max_speed = 200 # 私有属性
self._current_speed = 0 # 受保护属性
def accelerate(self, speed):
if self._current_speed + speed <= self.__max_speed:
self._current_speed += speed
else:
self._current_speed = self.__max_speed
def get_speed(self):
return self._current_speed
car = Car()
car.accelerate(100)
print(car.get_speed()) # 输出:100
# 在类的外部访问私有属性会引发错误
print(car.__max_speed) # 报错:AttributeError: 'Car' object has no attribute '__max_speed'
# 在类的外部访问受保护属性是合法的,但不建议直接访问
print(car._current_speed) # 输出:100
在上述示例中,__max_speed 是私有属性,外部无法直接访问。_current_speed 是受保护属性,外部可以访问但不建议直接访问。通过提供公共的方法(如 accelerate 和 get_speed)来访问和操作属性,从而实现了封装。
封装有助于隐藏内部实现细节,提供了良好的接口,使代码更加可维护、安全和易于理解。通过封装,我们可以限制对属性和方法的直接访问,减少了意外的修改和错误的可能性,同时也提高了代码的可重用性和灵活性。
Python中的self参数有什么作用?
在 Python 中,self 参数是一个约定俗称的名字,用于表示对象自身。它是类中的方法的第一个参数,通常在方法定义中的所有其他参数之前出现。
self 参数的作用是将类的实例(对象)传递给类中的方法,从而让方法能够访问并操作该实例的属性和方法。
当我们调用一个类的方法时,会自动将调用该方法的实例作为 self 参数传递给方法。
下面是一个使用 self 的示例:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
print("My name is", self.name, "and I am", self.age, "years old.")
person = Person("Alice", 25)
person.introduce() # 输出:My name is Alice and I am 25 years old.
在上述示例中,self 参数被用于 __init__ 和 introduce 方法中。在 __init__ 方法中,self 参数将传递给新创建的对象,用于初始化对象的属性。在 introduce 方法中,self 参数表示方法是属于该对象的,可以通过 self 访问对象的属性。
需要注意的是,self 只是一个惯用的名字,你可以使用其他名字代替它。但约定俗称的做法是使用 self 来表示对象自身,这有助于更清晰地理解代码。
总而言之,self 参数允许方法访问并操作类的实例的属性和方法。它是面向对象编程中一个重要的概念,帮助我们在类中定义和使用方法时建立起与实例的联系。
工作中使用python去做过哪些事情?为什么要使用?
1)进行接口和UI自动化测试。
2)写提效工具如接口测试用例生成工具。
3)写爬虫脚本获取需要的信息。
4)写批量执行任务脚本。
python装饰器
装饰器是 Python 中一种强大且灵活的语法特性,它允许在不修改被装饰函数源代码的情况下,向函数添加额外的功能。装饰器通常使用 @ 符号来应用于函数或方法,它本质上是一个高阶函数,接收一个函数作为参数,并返回一个新的函数或可调用对象。
下面是一个简单的装饰器示例,展示了如何定义和应用装饰器:
def decorator(func):
def wrapper(*args, **kwargs):
# 在被装饰函数执行前的操作
print("Before function execution")
# 执行被装饰函数
result = func(*args, **kwargs)
# 在被装饰函数执行后的操作
print("After function execution")
# 返回被装饰函数的结果
return result
# 返回装饰后的函数
return wrapper
@decorator
def some_function():
print("Inside the function")
# 调用装饰后的函数
some_function()
Before function execution
Inside the function
After function execution
在上述示例中,decorator 是一个装饰器函数,它接收一个函数作为参数,并返回一个新的函数 wrapper。wrapper 函数在被装饰函数执行前后添加了额外的操作,然后调用被装饰函数,并返回其结果。
通过在被装饰函数前使用 @decorator,我们将装饰器应用于 some_function(),使其在执行前后打印额外的信息。因此,当调用 some_function() 时,实际上调用了装饰后的函数 wrapper。
装饰器可以用于许多场景,例如日志记录、性能分析、异常处理等。你可以根据具体需求定义自己的装饰器函数,并将其应用于需要添加功能的函数或方法,以实现代码的复用和灵活性。
Python 中的 os 模块常见方法?
在 Python 中,os 模块是一个用于与操作系统进行交互的内置模块。它提供了许多方法来执行与文件和目录操作、进程管理、环境变量等相关的操作。以下是 os 模块中一些常见的方法:
- 文件和目录操作:
os.getcwd():获取当前工作目录的路径。os.chdir(path):改变当前工作目录到指定的路径。os.listdir(path):返回指定路径下所有文件和目录的列表。os.mkdir(path):创建指定路径的目录。os.makedirs(path):递归地创建多级目录。os.remove(path):删除指定路径的文件。os.rmdir(path):删除指定路径的目录,仅当目录为空时才能删除。os.removedirs(path):递归地删除多级目录。os.path.isfile(path):检查路径是否为文件。os.path.isdir(path):检查路径是否为目录。
- 进程管理:
os.system(command):在子shell中运行给定的命令。os.spawnl(mode, path, ...): 在新进程中执行指定的程序。os.kill(pid, signal):向指定的进程发送信号。
- 环境变量:
os.environ:一个包含环境变量的字典。os.getenv(key):根据给定的键获取环境变量的值。os.putenv(key, value):设置环境变量的值。
- 其他常见方法:
os.name:获取当前操作系统的名称。os.path.join(path1, path2):拼接两个路径。os.path.exists(path):检查路径是否存在。os.path.abspath(path):返回指定路径的绝对路径。
需要注意的是,os 模块的一些方法在不同的操作系统上可能会有差异,因为它们是与底层操作系统交互的。因此,当使用 os 模块时,最好对不同操作系统的差异性进行考虑。
这只是 os 模块提供的一些常见方法的示例。你可以查阅官方文档或使用 help(os) 命令来获取更详细的信息和了解其他方法。
你工作中使用了哪些python的内置库,和第三方库?
time
requests
random
selenium
httprunner
你对python的熟练度和应用度如何。
比如做接口自动化测试的同学,就可以很快的列出常用的库:openpyxl,pymysql,unittest,pytest,allure,os,loggging…
在工作当中,可以用python来做自动化测试,也可以写些脚本来改善工作效率。
什么是PEP 8?
PEP 8(Python Enhancement Proposal 8)是 Python 社区为了统一 Python 代码风格和提高代码可读性而制定的一份官方风格指南。
PEP 8 中包含了一系列关于 Python 代码规范的建议和规则,涵盖了命名约定、代码布局、注释、导入语句等多个方面。它的目的是使不同开发者编写的 Python 代码风格保持一致,使代码更易于阅读、理解和维护。
以下是 PEP 8 中一些常见的规范和建议:
- 缩进和空格:
- 使用 4 个空格进行缩进。
- 不要使用制表符进行缩进。
- 在二进制操作符周围、逗号后面以及冒号后面使用空格。
- 命名规范:
- 使用小写字母和下划线来命名变量、函数和模块。
- 类名使用驼峰命名法,每个单词首字母大写。
- 注释:
- 使用文档字符串(Docstring)注释函数、类或模块。
- 使用 # 进行行注释。
- 导入语句:
- 每个导入语句应单独占一行。
- 推荐按照约定的顺序导入模块(先标准库模块,然后第三方模块,最后是自定义模块)。
这只是 PEP 8 中的一部分规范,完整的 PEP 8 指南有更多的内容和细节,可以在 Python 官方文档(https://www.python.org/dev/peps/pep-0008/)中找到。
遵循 PEP 8 的规范可以使你的代码更易于阅读、理解和维护,并提高与其他 Python 开发者之间的协作效率。在编写 Python 代码时,遵循 PEP 8 是一个良好的实践。许多开发工具和编辑器都提供了对 PEP 8 的自动检查和格式化功能,帮助你保持一致的代码风格。
编程
请用python脚本实现从1到100的求和。
你可以使用 Python 脚本中的循环和累加变量来实现从1到100的求和。下面是一个简单的示例:
total = 0
for num in range(1, 101):
total += num
print("从1到100的求和结果为:", total)
在上述示例中,我们首先初始化 total 变量为 0,然后使用 for 循环遍历从 1 到 100 的数字。在每次循环中,将当前的数字加到 total 变量上,并更新 total 的值。最后,使用 print 函数输出结果。
运行上述代码将输出:
从1到100的求和结果为: 5050
以上是一种常见的方法来完成从1到100的求和。你也可以使用其他方法,比如使用数学公式求解等。
编写一个匿名函数,使其能够进行加法运算,例如说输入1,2能计算结果为3
add=lambda x,y:x+y
print(add(2,3))
在 Python 中,匿名函数是一种没有名字的函数,也被称为lambda函数。它是一种简洁的定义函数的方式,适用于只有一行代码的简单函数。
匿名函数使用lambda关键字定义,后面跟着参数列表和冒号,再接着是函数体。函数体只能是一条表达式,表达式的结果将作为匿名函数的返回值。
以下是匿名函数的一些示例:
- 求两个数之和:
add = lambda x, y: x + y
print(add(2, 3)) # 输出:5
- 求一个数的平方:
square = lambda x: x ** 2
print(square(5)) # 输出:25
- 根据姓和名返回全名:
full_name = lambda first, last: first.title() + " " + last.title()
print(full_name("alice", "smith")) # 输出:Alice Smith
匿名函数通常用于在需要函数对象的地方定义简单的函数。它们可以作为参数传递给其他函数,或者在列表解析、map、filter 等函数中使用。
需要注意的是,由于匿名函数只能包含单个表达式,所以它们的功能有限,不适用于复杂的逻辑或多行代码的函数。在这种情况下,最好使用普通的命名函数来实现。
总结起来,匿名函数是一种简洁的定义函数的方式,适用于简单的函数场景。它使用lambda关键字定义,并可以在需要函数对象的地方使用。
list_1=[1,2,1,2,15,4,3,2,1,2], 去除list_1的重复值,并且从大到小排序。
你可以使用集合(set)和排序函数来去除列表的重复值并按从大到小的顺序进行排序。下面是实现的示例代码:
list_1 = [1, 2, 1, 2, 15, 4, 3, 2, 1, 2]
# 去除重复值
unique_list = list(set(list_1))
# 从大到小排序
sorted_list = sorted(unique_list, reverse=True)
print(sorted_list)
在上述代码中,我们首先使用 set(list_1) 将列表转换为集合,因为集合的特性是不允许有重复元素的。然后,再将集合转回列表,得到不重复的列表 unique_list。
接下来,我们使用 sorted 函数对 unique_list 进行排序。通过设置 reverse=True 参数,可实现从大到小的顺序排序。
最后,使用 print 函数输出排序后的列表。
运行上述代码将得到如下输出:
[15, 4, 3, 2, 1]
以上代码完成了去除 list_1 的重复值并将结果按照从大到小排序的需求。
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。请注意,你可以假定字符串里不包括任何不可打印的字符。
【输出】输入: “Hello, my name is John” 输出: 5
解释: 这里的单词是指连续的不是空格的字符,所以 “Hello,” 算作 1 个单词。
a= "Hello, my name is John"
i=0
for Char in a:
if Char==" ":
i=i+1
print(i+1)
用python实现斐波那契数列
斐波那契数列是一个经典的数列,前两个数为 0 和 1,从第三个数开始,每个数都是前两个数的和。数列的前几个数字是:0, 1, 1, 2, 3, 5, 8, 13, 21, …
以下是一个使用 Python 编写的计算斐波那契数列的函数:
def fibonacci(n):
sequence = [0, 1] # 前两个数
for i in range(2, n):
next_num = sequence[i-1] + sequence[i-2] # 计算下一个数
sequence.append(next_num)
return sequence
# 示例用法,计算前10个斐波那契数:
fib_nums = fibonacci(10)
print(fib_nums)
在上述示例中,我们定义了一个 fibonacci 函数,它接受一个参数 n 表示要计算的斐波那契数列的长度。我们首先定义了数列的前两个数字 [0, 1],然后使用循环计算并添加下一个数字到数列中,直到达到指定的长度。最后,返回完整的斐波那契数列。
在示例中,我们调用 fibonacci(10) 来计算前10个斐波那契数,并将结果存储在 fib_nums 变量中。然后,使用 print 函数输出结果。
运行上述代码将输出:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
以上是一个简单的示例来计算斐波那契数列。你可以根据需要调整 n 的值来计算更长的数列。
请获取列表中重复元素最多的元素,以及重复的次数
例子1: 参数 [‘a’, ‘b’, ‘a’, ‘b’, ‘c’, ‘d’, ‘1’, ‘d’, ‘2’] 结果: 重复最多的是:[‘d’, ‘a’, ‘b’],重复个数:2
例子2: 参数 [‘a’,‘a’,‘a’, ‘b’, ‘a’, ‘b’, ‘c’, ‘d’, ‘1’, ‘d’, ‘2’] 结果:重复最多的是:[‘a’],重复个数:4
可以通过使用 collections.Counter 来实现获取列表中重复元素最多的元素和重复的次数。Counter 是一个字典的子类,用于统计可哈希对象的出现次数。
试看下面的示例代码,展示了如何获取列表中重复元素最多的元素和重复次数:
from collections import Counter
def get_most_frequent_element(lst):
counter = Counter(lst)
max_count = max(counter.values())
most_frequent = [item for item, count in counter.items() if count == max_count]
return most_frequent, max_count
# 测试示例
lst = ['a', 'b', 'a', 'b', 'c', 'd', '1', 'd', '2']
result = get_most_frequent_element(lst)
print("重复最多的是:", result[0])
print("重复个数:", result[1])
运行以上代码,将得到输出结果:
重复最多的是: ['a', 'b', 'd']
重复个数: 2
以上代码中,Counter(lst) 创建了一个计数器对象,统计了列表中元素的出现次数。使用 max() 函数找到最大的计数值,然后使用列表推导式遍历计数器的项,将出现次数等于最大计数值的元素添加到 most_frequent 列表中。
最后,将 most_frequent 和最大计数值作为结果返回。这样,我们即可获取到列表中重复元素最多的元素以及重复的次数。
在这句代码中,[] 是列表推导式(List comprehension)的语法。列表推导式是一种简洁的语法,用于创建一个新列表,并根据特定的条件或逻辑对原始列表中的元素进行筛选、转换或处理。
-
counter.items():这是一个计数器对象counter调用的方法,返回一个包含计数器键值对的迭代器。在这个上下文中,返回的键值对表示列表中的元素及其出现次数。 -
for item, count in counter.items():这是一个遍历迭代器的循环结构。它将迭代器中的每个键值对解包成item和count两个变量,这样我们可以分别访问元素和它的计数。 -
if count == max_count:这是一个条件语句,用于筛选元素。只有当元素出现的次数count等于最大计数值max_count时,条件才会为真。 -
item:这是一个列表推导式的表达式部分,它定义了在满足条件时要包含在结果列表中的元素。
通过这个列表推导式,我们可以根据给定条件快速筛选出需要的元素,并将它们组成一个新的列表 most_frequent。
def func(data):
# 重复最多的次数
mv = max([data.count(i) for i in set(data)])
# 获取重复最多的元素
ns = [k for k in set(data) if data.count(k) == mv]
print("重复最多的是:{},重复个数:{}".format(ns, mv))
if __name__ == '__main__':
data = ['a', 'b', 'a', 'b', 'c', 'd', '1', 'd', '2']
func(data)
python统计字符串中指定字符出现次数的方法
python统计字符串中指定字符出现次数的方法
s = "Count, the number of spaces."
print(s.count(" "))
x = "I like to program in Python"
print(x.count("i"))
对list去重并找出列表list中的重复元素
from collections import Counter #引入Counter
a = [1, 2, 3, 3, 4, 4]
b = dict(Counter(a))
print(b)
print([key for key,value in b.items() if value > 1]) #只展示重复元素
print({
key:value for key,value in b.items() if value > 1}) #展现重复元素和重复次数
统计列表(list)中每个元素出现的次数
lista = [1, 2, 3, 4, 12, 22, 15, 44, 3, 4, 4, 4, 7, 7, 44, 77, 100]
new_dict = {
}
for item in lista:
if item not in new_dict.keys():
new_dict[item] = lista.count(item)
print(new_dict)
列表推导式求列表所有奇数并构造新列表 a = [1,2,3,4,5,6,7,8,9,10]
a = [1,2,3,4,5,6,7,8,9,10]
b=[item for item in a if (item%2!=0)]
print(b)
用 python 写个冒泡排序 a = [1, 3, 10, 9, 21, 35, 4, 6]
当然,我可以帮你编写冒泡排序算法来对给定的列表进行排序。以下是使用Python实现的冒泡排序算法:
def bubble_sort(arr):
n = len(arr)
for i in range(n-1):
for j in range(n-1-i):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
# 测试示例
a = [1, 3, 10, 9, 21, 35, 4, 6]
sorted_a = bubble_sort(a)
print(sorted_a)
在这个代码中,bubble_sort 函数接受一个列表 arr 作为参数,并对其进行冒泡排序。算法的基本思想是通过多次遍历列表,将较大的元素逐步交换到列表的末尾。(每一轮都将最大的值移到末尾)
外层循环 for i in range(n-1) 控制遍历的轮数,其中 n 是列表的长度。内层循环 for j in range(n-1-i) 在每一轮遍历中,比较相邻的两个元素,并根据大小关系交换它们的位置。
最后,将排序后的列表返回,并打印输出结果。在这个示例中,sorted_a 将会是 [1, 3, 4, 6, 9, 10, 21, 35]。
用 python 写个冒泡排序
a = [1, 3, 10, 9, 21, 35, 4, 6]
for _ in range(1,len(a)):
for i in range(0,len(a)-j):
# 前一位数 > 后一位数。交换位置。
if a[i] > a[i+1]:
a[i],a[i+1] = a[i+1],a[i]
print(a)
幂的递归 计算 x 的 n 次方,如:3 的 4 次方 为 333*3=81
def fun(a,n):
i=1
for j in range(0,n):
i=i*a
print(i)
fun(3,4)
#递归的方式
def mi(x, n):
if n == 0:
return 1
else:
return x*mi(x, n-1)
print(mi(3, 4))
#非递归的方式:
def mix(x,n):
result = 1
for count in range(n):
result *= x
return result
print(mi(3,4))
给定字符串,找出有重复的字符串,并输出其位置 。输入: abcaaXY12ab12 输出: a, 1; a, 4; a, 5; a, 10; b, 2; b, 11; 1, 8; 1, 12; 2, 9; 2, 13
要找出给定字符串中的重复字符串,并输出其位置,我们可以使用字典来记录每个字符出现的位置。以下是实现这个功能的Python代码:
def find_duplicate_positions(s):
positions = {
}
duplicates = set()
result = []
for i, c in enumerate(s):
if c in positions:
duplicates.add(c)
result.append((c, positions[c]))
positions[c] = i + 1
return result
# 测试示例
input_string = "abcaaXY12ab12"
duplicate_positions = find_duplicate_positions(input_string)
for char, position in duplicate_positions:
print(f"{
char}, {
position}")
在这个代码中,find_duplicate_positions 函数接受一个字符串 s 作为参数,并返回重复字符的位置列表。
首先,创建一个空字典 positions 来记录每个字符出现的位置。同时,创建一个空集合 duplicates 来存储重复的字符。
然后,我们遍历字符串 s 中的每个字符。使用 enumerate 函数可以同时获取字符的索引和值。对于每个字符 c,我们检查它是否已经在 positions 字典中出现过。如果已经出现过,说明它是重复字符,我们将其加入到 duplicates 集合中,并将它的位置添加到结果列表 result 中。最后,更新该字符 c 的最新位置为当前索引加1。
最后,返回结果列表,并在主程序中进行测试。在给定的示例中,将会打印输出:
a, 1
a, 4
a, 5
a, 10
b, 2
b, 11
1, 8
1, 12
2, 9
2, 13
def find_repeat_char(s):
data = {
}
for index, char in enumerate(s):
temp = data.get(char, [])
temp.append('{}, {}'.format(char, index+1))
data[char] = temp
print(data)
res = []
for value in data.values():
if len(value) > 1:
res.extend(value)
return '; '.join(res)
print(find_repeat_char('abcaaXY12ab12'))
自动化基础能力评估
json和字典的区别
格式:JSON是一种数据交换格式,采用文本形式表示数据,使用键值对的方式存储数据。字典是一种Python数据类型,采用键值对的形式存储数据。
unittest框架包括哪几个模块?
unittest框架是Python的标准测试框架,它包含以下几个模块:
-
unittest.TestCase:TestCase是一个基类,用于创建测试用例。测试用例是测试过程中的最小单元,包含测试方法和相关断言。 -
unittest.TestLoader:TestLoader用于加载测试用例。它提供了一些方法,例如loadTestsFromModule()、loadTestsFromTestCase()和discover(),用于从模块、测试类或目录中加载测试用例。 -
unittest.TestSuite:TestSuite是测试用例的集合。可以使用它来组织和管理多个测试用例。 -
unittest.TextTestRunner:TextTestRunner是一个文本测试运行器,用于执行测试用例并生成测试结果的文本报告。它提供了方法run()用于运行测试。 -
unittest.mock:mock模块是unittest框架的一个附属模块,用于创建测试中的模拟对象和断言。它提供了与测试相关的功能,如创建虚拟对象、模拟函数的返回值等。
以上是 unittest 框架的一些关键模块。使用这些模块,你可以编写和执行单元测试,进行测试用例的加载与管理,并生成测试结果报告。
__all__ = ['TestResult', 'TestCase', 'TestSuite',
'TextTestRunner', 'TestLoader', 'FunctionTestCase', 'main',
'defaultTestLoader', 'SkipTest', 'skip', 'skipIf', 'skipUnless',
'expectedFailure', 'TextTestResult', 'installHandler',
'registerResult', 'removeResult', 'removeHandler']
jemeter或postman实现多接口关联测试?怎么做关联?
http://t.csdn.cn/qlJG7
在 JMeter 中,接口关联通常是指将一个接口的响应数据中的某些值提取出来,然后将它们作为参数传递给后续的请求。这在模拟一些动态交互场景时非常有用,例如登录后获取到的认证令牌需要在后续请求中使用。
以下是在 JMeter 中实现接口关联的一般步骤:
-
发送第一个请求并获取响应:首先,你需要发送接口的第一个请求,并获取到其响应。你可以使用 HTTP Sampler(例如 HTTP Request)来发送请求,并在结果树监听器中查看响应数据。
-
使用提取器提取关联值:接下来,你需要使用 JMeter 提供的提取器来提取响应数据中所需的值。JMeter 提供了多种提取器,如正则表达式提取器(Regular Expression Extractor)、CSS/JQuery 提取器(CSS/JQuery Extractor)、XPath2 提取器等。你可以根据响应数据的类型和格式选择合适的提取器,并设置提取规则以提取所需的值。
-
添加后续请求并使用关联值:在后续的请求中,你可以使用 JMeter 的参数化功能将提取的关联值作为参数传递给请求。你可以在请求参数中使用
${}表达式来引用关联值,例如${token}。 -
配置线程组参数:如果你的测试中使用了多个线程,需要确保每个线程都能正确使用关联值。你可以在线程组中设置用户变量,将关联值存储到用户变量中,并在后续请求中引用该变量。
通过以上步骤,你可以在 JMeter 中实现接口关联,将一个接口的响应数据提取出来并传递给后续的请求。这样可以模拟真实场景的动态交互,并有效地测试接口的功能性。
接口自动化的断言怎么做
在接口自动化测试中,断言是验证接口的响应结果是否符合预期的重要步骤。以下是一些常见的断言方法:
- 断言状态码:通过断言响应的状态码来验证接口的执行是否成功。通常,状态码为2xx表示成功,4xx表示客户端错误,5xx表示服务器错误。
import requests
import unittest
class APITestCase(unittest.TestCase):
def test_get_user(self):
url = "http://example.com/api/user/1"
response = requests.get(url)
# 断言状态码为200
self.assertEqual(response.status_code, 200, "接口返回状态码错误")
- 断言响应头:通过断言响应的特定头信息来验证接口的返回内容。
import requests
import unittest
class APITestCase(unittest.TestCase):
def test_get_user(self):
url = "http://example.com/api/user/1"
response = requests.get(url)
# 断言Content-Type头信息为application/json
self.assertEqual(response.headers["Content-Type"], "application/json", "响应头信息错误")
- 断言响应体:通过断言响应体中的数据来验证接口的返回内容。可以使用断言库提供的方法进行具体的比较,如相等断言(assertEqual)、包含断言(assertIn)等。
import requests
import unittest
class APITestCase(unittest.TestCase):
def test_get_user(self):
url = "http://example.com/api/user/1"
response = requests.get(url)
# 断言响应体中是否包含期望的字段值
self.assertIn("John Doe", response.json()["name"], "响应体中的字段值错误")
- 断言响应时间:通过断言接口的响应时间来验证接口的性能是否符合预期。
import requests
import unittest
class APITestCase(unittest.TestCase):
def test_get_user(self):
url = "http://example.com/api/user/1"
response = requests.get(url)
# 断言响应时间小于1秒
self.assertLess(response.elapsed.total_seconds(), 1, "接口响应时间过长")
以上是一些常见的接口自动化测试断言方法,根据接口的具体需求和预期结果,可以选择适合的断言方式。使用断言可以帮助我们在自动化测试中验证接口的正确性和稳定性。
如果需要用自动化测删除接口,断言怎么做
1)获取请求接口后的响应,断言状态码,返回字段,确保接口正确返回。
2)进行数据库操作,看数据是否被删除。
3)调用查询接口,断言被删除的数据是否不存在了。
做自动化的过程中如何处理验证码
处理验证码是Web自动化测试中常见的挑战之一。以下是一些处理验证码的方法:
-
手动处理:对于开发和测试环境中的验证码,可以临时手动输入验证码,以便自动化测试继续进行。这样做虽然不是完全自动化,但可以继续进行测试流程。
-
绕过验证码:如果测试环境或开发环境中的验证码对于自动化测试来说不是必需的,你可以与开发团队商讨是否可以临时绕过验证码,以便让自动化测试流程正常进行。
-
预置验证码:在一些特定的情况下,你可以与开发团队合作,在测试环境中预置一个固定的验证码,以便在自动化测试中使用该固定验证码来绕过验证码的检测。
-
使用第三方解决方案:有一些第三方工具或服务可以用于解决验证码问题。这些服务可以帮助你自动识别或绕过验证码。常见的第三方验证码解决方案包括使用图像识别(OCR)库,如Tesseract、Google Cloud Vision等,或使用验证码识别服务,如Anti-Captcha、2Captcha等。
请注意,在使用第三方解决方案时,需要了解服务提供商的条款和价格,并且一些解决方案可能无法适用于所有类型的验证码。
无论你选择哪种方式,重要的是与开发和测试团队保持密切沟通,并根据具体情况选择最适合的解决方案。同时,需要谨慎处理验证码问题,确保在自动化测试中遵循相关法律法规和道德准则。
python当中如何操作数据库?
在 Python 中,可以使用多种库来操作数据库,最常见的是使用以下几个库:
-
SQLite3:Python 自带的标准库,适用于轻量级数据库操作。
import sqlite3 # 连接到数据库 conn = sqlite3.connect('your_database.db') # 创建游标对象 cursor = conn.cursor() # 执行 SQL 查询 cursor.execute('SELECT * FROM your_table') # 获取查询结果 results = cursor.fetchall() # 关闭游标和连接 cursor.close() conn.close() -
MySQL:通过安装 PyMySQL 或 mysql-connector-python 等第三方库,可以在 Python 中连接 MySQL 数据库。
import pymysql # 连接到数据库 conn = pymysql.connect(host='your_host', user='your_user', password='your_password', database='your_database') # 创建游标对象 cursor = conn.cursor() # 执行 SQL 查询 cursor.execute('SELECT * FROM your_table') # 获取查询结果 results = cursor.fetchall() # 关闭游标和连接 cursor.close() conn.close() -
PostgreSQL:通过安装 psycopg2 或类似的库,可以在 Python 中连接到 PostgreSQL 数据库。
import psycopg2 # 连接到数据库 conn = psycopg2.connect(host='your_host', user='your_user', password='your_password', database='your_database') # 创建游标对象 cursor = conn.cursor() # 执行 SQL 查询 cursor.execute('SELECT * FROM your_table') # 获取查询结果 results = cursor.fetchall() # 关闭游标和连接 cursor.close() conn.close()
以上代码仅给出了连接数据库、执行查询和关闭连接的基本操作示例,具体的数据库操作取决于你要执行的操作,包括插入、更新、删除等。根据不同的数据库类型和操作需求,您可能需要查阅相应库的文档来了解更多详细信息和示例。
自动化测试用例如何编写
1、在Testcase文件中,定义类,在类中实现前置操作。
2、在类的方法中出现每一个test方法,test方法包含测试步骤,调用测试数据,断言和后置处理操作。
pytest的前置实现有哪几种方式?
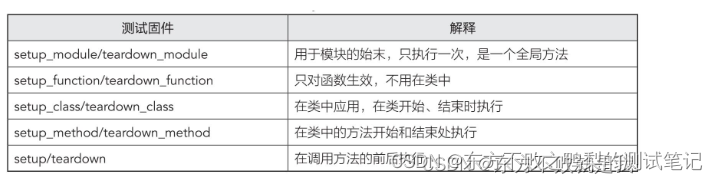
在pytest中,可以使用fixture来实现测试用例的前置操作。以下是pytest中常用的几种前置实现方式:
- 函数级别的fixture:可以使用@pytest.fixture装饰器定义一个函数级别的fixture,它可以在单个测试函数执行前后执行一些前置或后置操作。
import pytest
@pytest.fixture
def setup():
# 执行前置操作
yield
# 执行后置操作
def test_example(setup):
# 测试代码
- 类级别的fixture:可以使用@pytest.fixture装饰器定义一个类级别的fixture,它可以在测试类中的每个测试方法执行前后执行一些前置或后置操作。
import pytest
@pytest.fixture(scope="class")
def setup_class():
# 执行前置操作
yield
# 执行后置操作
@pytest.mark.usefixtures("setup_class")
class TestExample:
def test_method1(self):
# 测试代码
def test_method2(self):
# 测试代码
- 模块级别的fixture:可以使用@pytest.fixture装饰器定义一个模块级别的fixture,它可以在整个测试模块中的所有测试函数执行前后执行一些前置或后置操作。
import pytest
@pytest.fixture(scope="module")
def setup_module():
# 执行前置操作
yield
# 执行后置操作
def test_example1(setup_module):
# 测试代码
def test_example2(setup_module):
# 测试代码
- 会话级别的fixture:可以使用@pytest.fixture(scope=“session”)装饰器定义一个会话级别的fixture,它可以在整个pytest会话中的所有测试模块执行前后执行一些前置或后置操作。
import pytest
@pytest.fixture(scope="session")
def setup_session():
# 执行前置操作
yield
# 执行后置操作
def test_example(setup_session):
# 测试代码
以上是pytest中常见的几种前置实现方式。根据测试用例的需求和作用范围,选择适合的fixture级别来实现前置操作,以保证在测试执行前进行必要的准备工作。
Appium 都有哪些启动方式
Appium是用于移动端自动化测试的工具,它支持多种启动方式以适应不同的测试需求和场景。以下是Appium的常见启动方式:
-
通过Appium Desktop启动:Appium Desktop是一个可视化界面的Appium工具,提供了简单易用的界面来启动Appium服务器。你可以通过选择设备、设置相关参数,然后点击启动按钮来启动Appium服务器。
-
通过命令行启动:你可以通过命令行界面使用
appium命令来启动Appium服务器。例如,在终端中运行appium命令即可启动默认设置的Appium服务器。 -
使用Appium Server启动:你可以在自己的代码中使用Appium Server库来启动Appium服务器。这种方式可以更加灵活地自定义启动参数。
from appium import webdriver
desired_caps = {
'platformName': 'Android',
'deviceName': 'device',
'appPackage': 'com.example.app',
'appActivity': 'com.example.app.MainActivity'
}
# 启动Appium服务器,建立会话
driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)
- 使用Appium Service启动:你可以使用Appium的Python库中提供的Appium Service来启动Appium服务器。这种方式可以让你在代码中启动和停止Appium服务器,更好地集成到自动化测试框架中。
from appium import webdriver
from appium.webdriver.appium_service import AppiumService
# 创建Appium Service实例
appium_service = AppiumService()
# 启动Appium服务
appium_service.start()
desired_caps = {
'platformName': 'Android',
'deviceName': 'device',
'appPackage': 'com.example.app',
'appActivity': 'com.example.app.MainActivity'
}
# 建立会话
driver = webdriver.Remote(appium_service.service_url, desired_caps)
# 执行测试
# 停止Appium服务
appium_service.stop()
以上是Appium的主要启动方式,你可以根据自己的需求和测试框架的要求选择合适的启动方式。无论使用哪种方式,都需要确保设备或模拟器已经正确设置并连接到Appium服务器。
web ui自动化中显式等待、隐式等待有什么区别
显示等待是调用webdriverWait方法,等待元素是否存在或者是否出现。显示等待的灵活性高。
隐式等待是一个全局的等待方法,对于所有的元素在定位的时候如果未定位到,就可以使用隐式等待进行等待。
显式等待和隐式等待是在Web UI自动化测试中用于等待页面加载和元素出现的两种常见等待方式,它们有以下区别:
显式等待(Explicit Wait):
- 通过在代码中显式地指定等待条件,直到满足条件或超过最大等待时间,进行等待。
- 可以使用WebDriverWait类来实现显式等待,结合Expected Conditions来定义等待条件。
- 可以根据不同的等待条件进行灵活的等待,如等待元素可见、等待元素存在、等待元素可点击等。
- 显式等待的灵活性更高,适用于特定场景下需要等待条件发生时才继续执行的情况。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 创建WebDriverWait对象,等待10秒,每0.5秒检查一次
wait = WebDriverWait(driver, 10, 0.5)
# 等待直到元素可见
element = wait.until(EC.visibility_of_element_located((By.ID, "element_id")))
隐式等待(Implicit Wait):
- 在实例化WebDriver对象时,设置一个全局的等待时间,然后在执行每个命令时都会检查是否满足等待时间。
- 在查找元素时,如果元素不立即可用,WebDriver将等待指定的时间,然后再抛出异常。
- 隐式等待将等待应用于所有的查找操作,对于所有的元素查找都会等待一段时间,直到找到元素或超出指定的等待时间。
- 隐式等待的等待时间对整个Driver的生命周期都起作用,因此需要在实例化Driver时设置一次即可。
from selenium import webdriver
# 创建WebDriver对象,并设置隐式等待时间为10秒
driver = webdriver.Chrome()
driver.implicitly_wait(10)
# 查找元素时会等待10秒,如果找到元素则立即返回,否则抛出异常
element = driver.find_element_by_id("element_id")
总结:
显式等待和隐式等待在等待机制和使用方式上有一些区别。显式等待更加灵活,可以根据特定的条件进行等待,适用于需要在特定条件出现后才继续执行的情况。隐式等待则是设置一个全局的等待时间,适用于整个页面的元素查找操作,对于所有的元素查找都会等待预设的时间。在选择等待方式时,可以根据具体的需求和场景来决定使用哪种等待方式。
有没有遇到元素定位不到情况?如何处理的?
在Web自动化测试中,如果无法定位到元素,可能是由于以下原因导致的:
-
元素未加载或延迟加载:等待元素出现的时间不够长,可以使用
WebDriverWait等待一段时间,直到元素可见或可操作。 -
元素定位方法不准确:使用的定位方法不正确,可以尝试使用其他定位方法来定位元素,如使用不同的选择器(如id、class、Xpath、CSS选择器等)。
-
元素定位器发生变化:网页结构或动态内容导致元素的定位信息发生变化,需要更新定位器。可以使用浏览器开发者工具确认元素的属性或使用更稳定的定位方法。
-
元素处于iframe或frame中:如果要定位的元素位于iframe或frame中,需要先切换到对应的iframe或frame中,再进行定位。
-
异步加载或动态渲染:某些页面使用了异步加载或动态渲染技术,元素的出现可能是在页面加载完成后的某个时间点。可以使用等待方法(如显式等待、隐式等待)来等待元素的出现。
-
元素存在于多个位置:如果页面中存在多个相同或类似的元素,可以通过索引或其他属性来精确定位到需要的元素。
-
页面未完全加载:页面尚未完全加载或网络延迟等原因导致元素无法及时出现,可以增加适当的等待时间或调整网络设置。
当遇到无法定位到元素的情况时,可以通过打印日志、观察页面状态、调试工具等手段来分析问题原因,并根据具体情况采取相应的解决方案。在测试过程中,灵活应用不同的定位方法和等待策略,可以提高元素定位的准确性和稳定性。
如果元素没有id,而且有很多iframe,所以写xpath也是有问题的,就是id和xpath都用不了,你用什么方式去定位?
如果元素既没有id,也无法使用XPath进行准确定位,并且页面中存在多个iframe,可以尝试使用以下方式进行元素定位:
- 使用class属性:如果元素具有唯一的class属性,可以使用
driver.find_element_by_class_name()方法来定位元素。
element = driver.find_element_by_class_name("class_name")
- 使用name属性:如果元素具有唯一的name属性,可以使用
driver.find_element_by_name()方法来定位元素。
element = driver.find_element_by_name("element_name")
- 使用CSS选择器:如果元素具有唯一的CSS属性,可以使用
driver.find_element_by_css_selector()方法来定位元素。
element = driver.find_element_by_css_selector("css_selector")
- 使用父元素进行定位:可以先定位元素所在的父元素,然后再在父元素的范围内继续定位目标元素。
parent_element = driver.find_element_by_xpath("parent_xpath")
element = parent_element.find_element_by_xpath("child_xpath")
在使用这些方法时,需要确保所选取的属性或元素是唯一的,以充分准确定位目标元素。同时,建议使用显示等待(WebDriverWait)等待元素的出现,以确保元素已加载并可见。
如果以上方式仍无法定位到元素,可以考虑与开发团队合作,让他们为元素添加唯一标识,以便进行准确定位。
如果同一个浏览器打开两个窗口,要用selenium里面哪个指令进行切换?
如果你使用Selenium来自动化测试,在同一个浏览器中切换窗口,可以使用switch_to.window()方法来实现。
具体步骤如下:
-
获取当前窗口的句柄(handle):可以使用
current_window_handle属性获取当前窗口的句柄,例如current_window = driver.current_window_handle。 -
获取所有窗口的句柄:可以使用
window_handles属性获取所有窗口的句柄,例如all_windows = driver.window_handles。 -
切换到另一个窗口:使用
switch_to.window()方法,将要切换的窗口句柄作为参数传入,例如driver.switch_to.window(handle),其中handle是要切换到的窗口句柄。
下面是一个简单的示例代码:
# 定位到当前窗口的句柄
current_window = driver.current_window_handle
# 打开一个新的窗口(可以是通过点击链接或其它操作打开的新窗口)
# 获取所有窗口的句柄
all_windows = driver.window_handles
# 切换到新窗口
for window in all_windows:
if window != current_window:
driver.switch_to.window(window)
break
# 现在处于新的窗口进行操作
# 切回到原窗口
driver.switch_to.window(current_window)
在切换窗口前,注意保存当前窗口的句柄,并使用循环语句切换到另一个窗口。最后,可以再次使用switch_to.window()方法切回原窗口。
App自动化有做过吗?知道用到哪些技术框架吗?
https://blog.csdn.net/spasvo_dr/article/details/131131861
只知道Appium
App自动化用的是真机还是虚拟机?
什么 PO 模式,什么是 page factory?
Page Factory 是一个设计模式,用于在自动化测试中管理页面对象。它是 Selenium WebDriver 的一个扩展,旨在简化页面对象模型(Page Object Model)的实现。
Page Object Model 是一种测试设计模式,它将页面抽象为对象,每个页面代表一个类。每个类包含页面中的元素和相应的操作。这样可以通过实例化页面对象并调用其方法来操作页面。
Page Factory 提供了一种更高级的方式来初始化页面对象。它通过使用注解和反射机制,自动初始化页面对象的元素,无需手动查找和定位元素。
在 Page Factory 中,需要使用 @FindBy 注解在页面对象类中标注页面元素。 @FindBy 注解接收定位元素的信息,例如使用 CSS 选择器、XPath 或其他定位方式。使用 @FindBys 注解可以组合多个定位条件。当测试代码使用 Page Factory 创建页面对象时,注解会自动初始化页面对象中的元素。
下面是一个示例代码,展示使用 Page Factory 初始化页面对象的过程:
public class LoginPage {
@FindBy(id = "username")
private WebElement usernameInput;
@FindBy(id = "password")
private WebElement passwordInput;
@FindBy(id = "login-button")
private WebElement loginButton;
public LoginPage(WebDriver driver) {
PageFactory.initElements(driver, this);
}
public void login(String username, String password) {
usernameInput.sendKeys(username);
passwordInput.sendKeys(password);
loginButton.click();
}
}
在上述示例中,LoginPage 类表示登录页面。使用 @FindBy 注解标注了用户名输入框、密码输入框和登录按钮。在构造函数中调用 PageFactory.initElements(driver, this) 来初始化页面对象中的元素。
通过使用 Page Factory,可以更便捷地实现页面对象模型,提高测试代码的可读性和可维护性。它简化了查找和定位元素的过程,使得测试代码更加清晰和易于编写。
简述selenium的原理
提供webdriver控制浏览器的API,通过浏览器驱动与浏览器进行交互。
UI自动化测试用例在运行过程中经常会出现不稳定的情况,也就是说这次可以通过,下次就没有办法通过了,如何去提升用例的稳定性?
- 合理运用显示等待
2)元素定位方式不要写死。
3)测试复原,后置数据处理。
chatgpt:
在提升UI自动化测试用例稳定性方面,以下是一些常见的建议和技巧:
-
显式等待:使用显式等待机制来等待页面元素出现或操作完成。显式等待允许测试代码等待特定条件的发生,而不是简单地使用固定的等待时间。这可以增加用例的稳定性,避免因网络延迟、页面加载等因素导致的不可预测行为。
-
定位策略:选择合适的定位策略来定位页面元素。基于ID或唯一的CSS选择器进行定位,可以提高用例的稳定性。避免使用易变的属性或Xpath表达式进行定位,因为页面结构的变化可能会导致定位失败。
-
独立的测试环境:为UI自动化测试创建一个独立的测试环境,这样可以减少外部因素对用例稳定性的影响。例如,使用专门的测试数据库,避免与真实的生产环境数据进行交互。
-
数据驱动测试:将测试数据从测试用例代码中分离出来,使用数据驱动的方式执行测试。这样可以隔离测试数据的变化,灵活地更新测试数据,而不影响测试用例的稳定性。
-
异常处理:合理处理可能发生的异常情况,例如元素未找到、超时等。使用try-catch语句来捕获异常,并在异常发生时处理和记录错误信息,以便更好地诊断问题。
-
充分的等待时间:确保在执行操作之前,给页面足够的时间来加载和渲染。如果页面在使用元素之前需要一些时间进行初始化,可以添加适当的等待时间以确保元素可用。
-
适当的测试环境复原:在执行测试用例后,对测试环境进行适当的复原操作。这可以确保每个测试用例在相同的环境下运行,减少因环境问题导致的不稳定性。
-
并行执行测试:考虑使用并行执行的方式来运行自动化测试,以减少测试时间并提高稳定性。通过同时执行多个测试用例,可以更好地模拟真实用户的行为,更快地发现潜在问题。
综上所述,通过使用合适的等待机制、稳定的定位策略、独立的测试环境和恰当的异常处理等方法,可以提高UI自动化测试用例的稳定性。要记住,在编写测试用例时,考虑到各种场景和边界条件,并及时修复用例中的漏洞和问题,以确保其可靠性和稳定性。
自动化项目实战能力评估
自动化是自己搭的框架还是本来就有的框架,只是往里面写的一些用例?
讲一下在工作中怎么做的自动化测试?
UI自动化:
1)首先进行自动化框架选型,搭建自动化框架。
2)梳理需要进行自动化的测试用例,优先级别高的用例。
3)编写页面对象
4)编写测试用例。
5)将自动化项目集成于jenkins持续运行。
6)自动化测试维护。
假如公司想要做自动化,让你去做,你会从那些方面考虑入手?
在自动化测试过程中上下游接口有数据依赖如何处理,请详细说明你的框架中,这一部分设计逻辑细节。
在测试用例的前置步骤中进行数据准备,从数据库进行数据查询,或者使用接口返回的数据,或者使用模拟数据。
处理自动化测试中上下游接口的数据依赖是一个重要的问题,下面提供几种常用的方法来处理这种情况:
-
数据预置:在自动化测试运行之前,先预置测试数据。这可以通过手动或自动化脚本的方式来实现。预置数据包括所需的依赖数据,在测试开始之前,确保这些数据在相应的接口中已经存在。
-
接口数据回滚:在测试之前,通过调用接口的删除或恢复功能,将数据回滚到所需要的初始状态。可以使用接口的提供的特定功能来删除或恢复测试过程中创建或修改的数据。
-
数据生成:对于测试中需要的数据,可以通过编写代码或使用数据生成工具来自动生成。这样可以保证每次运行测试时都有新的独立数据。例如,可以使用随机数生成器或是根据指定的规则生成测试数据。
-
接口之间的数据传递:如果上游接口的输出数据需要用于下游接口的测试,则需要确保正确地传递数据。这可以通过将上游接口的响应数据提供给下游接口,或者将上游接口的输出数据存储到共享数据库或文件中,然后由下游接口读取和使用。
-
数据模拟和Stubbing:对于无法直接控制的上游接口,可以使用数据模拟或Stubbing的技术来模拟依赖数据的返回。这可以通过使用模拟工具、创建虚拟服务器或使用代理服务器来实现。模拟的数据可以根据测试需求进行设置。
-
依赖管理工具:使用依赖管理工具(如Maven、Gradle)可以简化对相关接口和依赖的管理。通过在构建配置文件中定义依赖关系,可以确保所需的接口和数据在测试运行之前得到正确的准备和配置。
以上方法可以根据具体的测试需求和环境来选择和组合使用。重要的是在自动化测试开始之前,考虑并解决好上下游接口的数据依赖问题,以确保测试的可重复性和稳定性。
多套环境,pytest如何切换环境?
在 Pytest 中切换不同的环境可以通过自定义命令行参数、配置文件或环境变量来实现。下面是一些常用的方法:
- 命令行参数:通过添加自定义的命令行参数来指定测试运行的环境。可以使用
pytest.addoption方法定义一个新的命令行参数,并在测试代码中读取该参数的值。例如,可以添加--env参数来指定环境:
# conftest.py
def pytest_addoption(parser):
parser.addoption("--env", action="store", default="dev", help="Specify the test environment")
# test_module.py
def test_function(request):
env = request.config.getoption("--env")
if env == "dev":
# 执行针对开发环境的测试逻辑
elif env == "staging":
# 执行针对演示环境的测试逻辑
elif env == "prod":
# 执行针对生产环境的测试逻辑
# ...
运行测试时,可以使用 --env 参数来指定所需的环境,例如 pytest --env dev。
- 配置文件:使用配置文件来定义不同环境的配置选项。可以使用
pytest.ini或者pytest.cfg文件来定义测试的配置选项,并根据不同的环境配置来运行测试。在配置文件中,可以定义不同环境的变量,例如:
# pytest.ini
[pytest]
env = dev
然后,在测试代码中读取配置选项的值:
# test_module.py
def test_function(pytestconfig):
env = pytestconfig.getoption("env")
if env == "dev":
# 执行针对开发环境的测试逻辑
elif env == "staging":
# 执行针对演示环境的测试逻辑
elif env == "prod":
# 执行针对生产环境的测试逻辑
# ...
- 环境变量:通过设置环境变量来指定使用的环境。可以设置一个名为
PYTEST_ENV或其他自定义的环境变量,在测试代码中读取该环境变量的值来确定所用的环境。例如:
# test_module.py
import os
def test_function():
env = os.environ.get("PYTEST_ENV")
if env == "dev":
# 执行针对开发环境的测试逻辑
elif env == "staging":
# 执行针对演示环境的测试逻辑
elif env == "prod":
# 执行针对生产环境的测试逻辑
# ...
使用以上方法,可以根据需要在 Pytest 中灵活切换不同的环境,使测试代码能够在不同环境下运行。根据具体需求,选择最适合的方法来切换环境。
pytest运行完所有case以后,如何清理数据库?
在 Pytest 中,可以使用 Fixture 来进行数据库清理操作。Fixture 是在测试运行之前和之后执行的函数,用于提供测试运行所需的资源和环境。你可以通过编写一个 Fixture 来清理数据库。
下面是一个示例代码,展示如何使用 Fixture 清理数据库:
import pytest
import your_database_module
@pytest.fixture(scope='session')
def db_cleanup():
# 初始化数据库连接
db = your_database_module.Database()
# 清理数据库操作
db_cleanup()
# 关闭数据库连接
db.close()
def test_example():
# 测试逻辑
# 在测试运行之后执行 Fixture
def pytest_sessionfinish():
db_cleanup()
在上述代码中,我们定义了一个 Fixture db_cleanup(),这个 Fixture 会在整个测试过程中只执行一次。在 db_cleanup() 中,我们执行了清理数据库的操作。然后我们在 pytest_sessionfinish() 中调用了 db_cleanup(),以保证即使测试运行发生异常,数据库也能得到清理。
当你运行所有的测试用例时,Pytest 会自动处理 Fixture 的执行逻辑,确保在每个测试用例运行之前和之后,都会执行相应的 Fixture。
注意,上述代码中的 your_database_module 需要替换为你实际使用的数据库模块。具体的数据库清理操作需要根据你所使用的数据库和数据结构来编写。
通过自定义 Fixture,你可以在 Pytest 运行完所有测试用例后进行数据库清理或其他清理任务,从而确保测试的独立性和准确性。