
作者 | 曾浩辰 责编 | 袁滚滚
出品 | CSDN(ID:CSDNnews)
“机器人技术将是我们在人工智能领域征服的最后一道护城河。一个给机器人使用的GPT模型,它的应用程序接口是什么样的?”
——英伟达资深 AI 科学家 Jim Fan,师从李飞飞。
工程师们一直在试图搭建更智能、可靠的机器人,比如之前火爆全网、来自波士顿动力公司的机器狗Spot。它可以轻松上下楼梯、搬运重物、巡查街道,等等。

波士顿动力公司机器狗Spot按下把手开门通过
机器狗由一个运行着Android系统的遥控手柄控制,人们可以通过摄像头随时查看它的状态,并提供指引爬上爬下、行走翻身。这当然很棒,但当我们想给机器人传达更复杂的动作指令时,在手柄上相应的操作就繁琐了很多。能不能开发出一种更易用、直观的人机交互方法,能让我们更轻松地发送指令给机器人呢?与其在一个小屏幕上戳来戳去控制不同的机械参数,能不能直接告诉机器人具体的指令,让它去做什么呢?
近日,由李飞飞教授及来自斯坦福大学、加州理工、清华大学和英伟达的几位学者组成的团队(Yunfan Jiang,Agrim Gupta,Zichen Zhang,Guanzhi Wang,Yongqiang Dou,Yanjun Chen,Li Fei-Fei,Anima Anandkumar,Yuke Zhu,Linxi Fan)发推,分享他们全新的研究结果:VIMA(Vision-and-Language Navigation with Multi-Modal Transformers),一个使用多模态提示执行各类任务的机械体操作系统。
也就是说,在Prompt中输入文字、图片、视频,或任意的组合,VIMA就可以控制机械臂执行相应的动作。
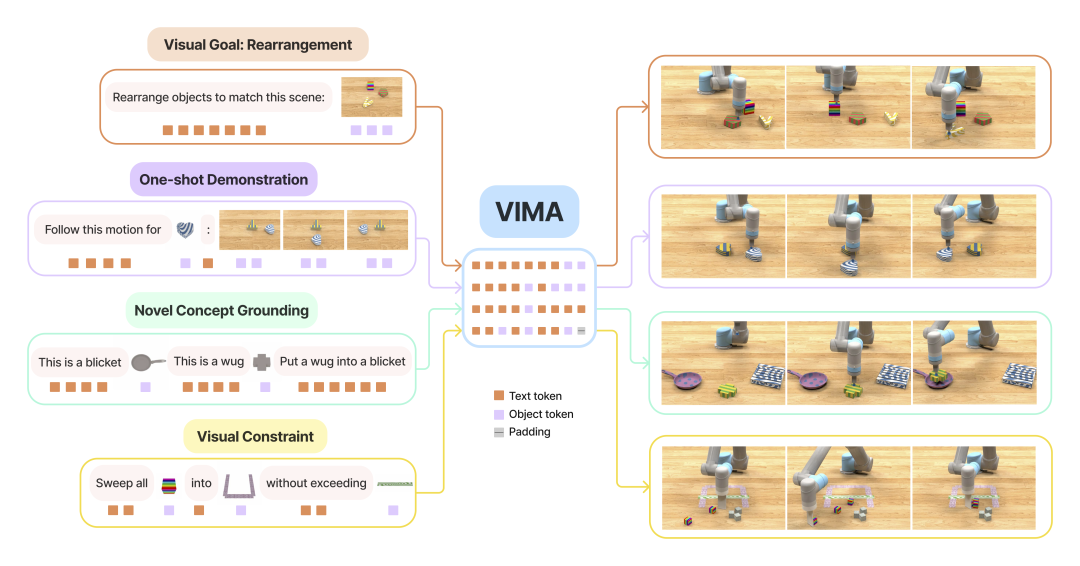
VIMA将多模态提示用于任务规范

VIMA能做什么?场景事例
如下图,输入指令「把形状一样的物品放到绿色碗(图片)里」给VIMA。
VIMA通过分析自然语言提示和图像提示,识别出所有物品的位置,找到形状一样的两个圆柱体,再找到和绿色碗,最后操作机械臂一次一次把两个圆柱体放到了碗里。

如下图,输入指令「把图示物品(彩虹方块)扫到图示物品(红框)内,不触碰图示物品(黄线)。」给VIMA,系统识别出所有物件的位置,随后按照指示操作机械臂把彩虹方块扫到红框里,不触碰黄线。

最后来看这个例子。
我们甚至可以在prompt教给它新的视觉概念,输入指令「这是一个zup <灰色方框图片>,这是一个blicket <灰色十字图片>。将blicket放进zup里。」
VIMA识别到所有物体后,操作机械臂执行相应动作。


机械臂系统的组成结构
VIMA主要由以下几个部分组成:
Transformer编码器和解码器:用于对多模态提示进行编码和机器人臂的控制进行解码。
视觉和语言模块:用于处理视觉和语言输入,并将它们转换为Transformer可以处理的令牌序列。
动作执行器:用于将机器人臂的控制信号转换为物理动作,并将其发送到机器人控制器。
数据集和基准:用于评估和比较不同的机器人学习方法,并提供训练和测试数据。
物理仿真器:用于在虚拟环境中模拟机器人的行为,并提供快速的反馈和调试机制。
这些组件共同构成了VIMA的核心部分,使得它能够接收多模态提示并执行各种机器人任务。
在VIMA中,GPT-3模型在第一部分被用作解码器,用于生成导航指令,以指导机器人在环境中执行导航任务。具体来说,VIMA-GPT是一个仅包含解码器的架构,它通过对多模态提示进行编码,自回归地解码给定指令和交互历史的下一个动作,控制机器臂的运动。连接硬件后的VIMA成为了“一个具有体现性的AI代理:它可以感知环境并逐步在物理世界中采取行动。”Fan说到。

软硬件结合的AI系统能做什么
团队共实现了17个不同的任务,分为6大类:简单物体操作(Simple object manipulation)、视觉目标达成(Visual goal reaching)、新概念理解(Novel concept grounding)、单次视频模仿(One-shot video imitation)、视觉约束满足(Visual constraint satisfaction)、视觉推理(Visual reasoning)。
Fan在他的推文中提及:“多模态提示使得任务规范对用户来说更加容易和灵活。通过一个单一的模型,VIMA将视觉目标达成、从视频演示中进行一次性模仿、学习新概念以及满足安全约束等多种任务统一起来。而在以前的工作中,每个任务都需要不同的训练流程。”
作为一个机器人控制的框架,VIMA可以扩展成为极其强大的工具。像是一个实体的小爱同学,在学习完所有的步骤和物品之后,它可以你成为现实生活里的左膀右臂,例如:
家务。告诉它你想吃西红柿炒鸡蛋,VIMA在厨房里找到材料、开火、放糖(北方同学大喜),自动化炒菜。
教育。在学校的自习课替老师回答问题,并在黑板上拿粉笔写笔记,为学生提供定制练习和反馈。
娱乐。投篮后每次替你捡球送水的女同学,一个VIMA机器人就能替代,甚至更体贴。
当然,上面的例子过于理想了,但并不是不可能实现。
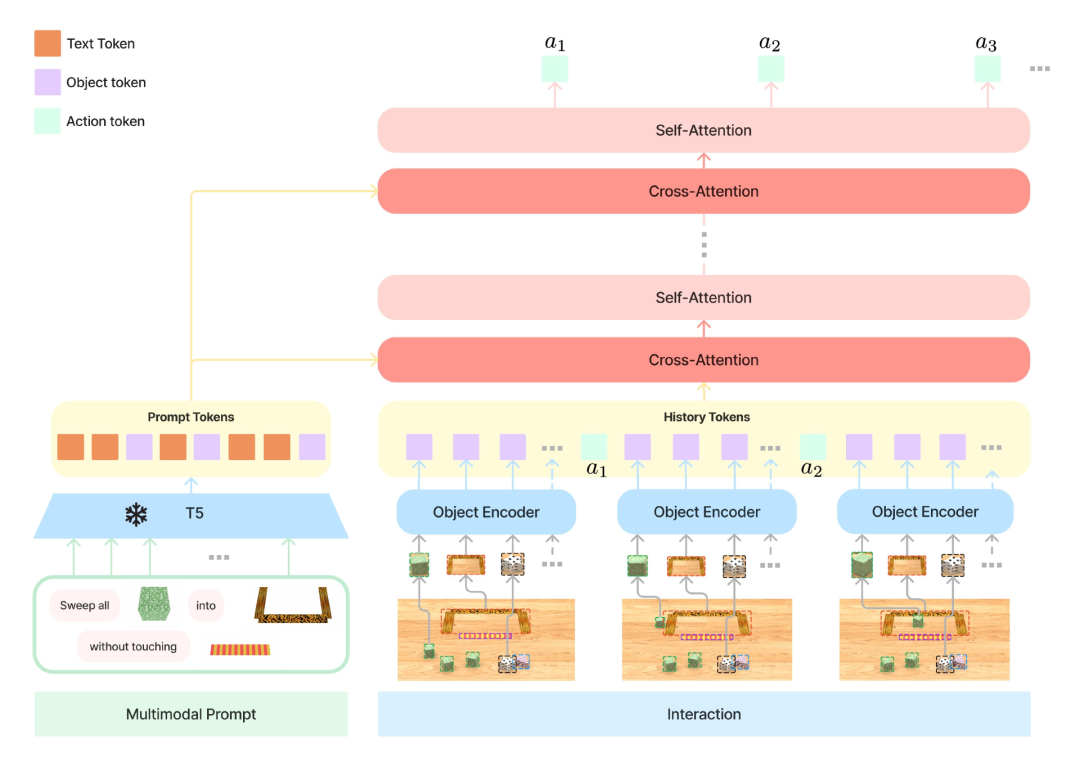
模型结构:编码-解码转换器

结语
VIMA作为一个仍在开发中的基础模型,为智能机械体的发展方向指明了更切实的发展方向。它有可能使机器人更智能、更有用。而如此强大的工具将其所有内容全部开源:代码、预训练模型、数据集和物理仿真基准都可以免费获取和使用!代码的透明度和可重复性被提高,更多的人可以使用和改进VIMA框架,促进了合作和知识共享,这对推动机器人学习领域的发展起到了巨大的作用。
将机器人和LLM整合,相当于让机器人有了大脑!长期来说,利好智能设备的功能增强,短期来说,B站上如稚晖君的一批知名UP主,又可以整活了。
参考链接:
https://arxiv.org/abs/2210.03094
https://vimalabs.github.io
https://twitter.com/DrJimFan/status/1683517085731913729
