第一种:配置问题
这是别人的图片,据楼主排查解决是因为hosts配置问题…
现象:各种无法运行、启动
解决办法:
1、修改日志级别
export HADOOP_ROOT_LOGGER=DEBUG,console
查看下详细信息,定位到具体问题解决
第二种:服务器问题

**现象:**运行到job时卡住不动
**原因:**服务器配置低下,内存小或磁盘小
**解决办法:**修改yarn.site.xml配置
<!--每个磁盘的磁盘利用率百分比-->
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>95.0</value>
</property>
<!--集群内存-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<!--调度程序最小值-分配-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<!--比率,具体是啥比率还没查...-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
除了服务器集群配置低,也有可能是服务器被攻击或恶意程序占用内存Hadoop的MapReduce进程卡住job/云服务器被矿工挖矿
戏剧的是,我今天还遇到一种情况…现象也是Map后卡在Job,原因是:我运行了计算圆周率程序,刚开始测试没问题后手贱执行1000次,掷10000次…Map过程还好,Job开始便无法运行…
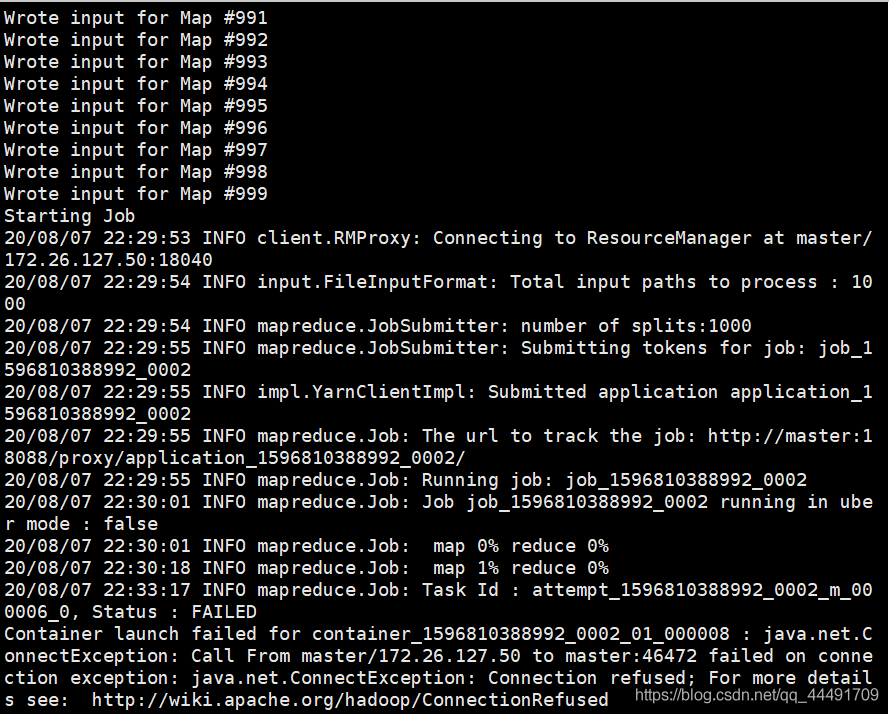
可能是任务太大了,可以尝试换小的执行
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar pi 20 20