系列文章目录
本专栏介绍基于深度学习进行图像识别的经典和前沿模型,将持续更新,包括不仅限于:AlexNet, ZFNet,VGG,GoogLeNet,ResNet,DenseNet,SENet,MobileNet,ShuffleNet,EifficientNet,Vision Transformer,Swin Transformer,Visual Attention Network,ConvNeXt, MLP-Mixer,As-MLP,ConvMixer,MetaFormer
前言
SENet,胡杰(Momenta)在2017.9提出,通过显式地建模卷积特征通道之间的相互依赖性来提高网络的表示能力,即,通道维度上的注意力机制。SE块以微小的计算成本为现有的最先进的深层架构产生了显著的性能改进,SENet block和ResNeXt结合在ILSVRC 2017赢得第一名。
论文名称:Squeeze-and-excitation networks
论文下载链接:
https://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper.pdf
pytorch代码实现:https://github.com/Arwin-Yu/Deep-Learning-Classification-Models-Based-CNN-or-Attention
一、简介
-
提出背景:卷积核通常被看做是在局部感受野上,在空间上和通道维度上同时对信息进行相乘求和的计算。现有网络很多都是主要在空间维度方面来进行特征的融合(如Inception的多尺度)。
-
通道维度的注意力机制:在常规的卷积操作中,输入信息的每个通道进行计算后的结果会进行求和输出,这时每个通道的重要程度是相同的。而通道维度的注意力机制,则通过学习的方式来自动获取到每个特征通道的重要程度(即feature map层的权重),以增强有用的通道特征,抑制不重要的通道特征。
-
说起卷积对通道信息的处理,有人或许会想到逐点卷积,即kernel大小为1X1的常规卷积。与1X1卷积相比,SENet是为每个channel重新分配一个权重(即重要程度)。而1X1卷积只是在做channel的融合计算,顺带进行升维和降维,也就是说每个channel在计算时的重要程度是相同的。
二、SE模块
SENet是一种基于注意力机制的卷积神经网络架构。其主要思想是通过自适应地重新校准卷积特征的通道响应。SENet中的"Squeeze"和"Excitation"操作分别对应着该过程的两个主要步骤。
Squeeze:压缩操作是全局信息嵌入的过程,主要用于对空间维度进行全局平均池化,得到每个通道的全局空间信息,形成一个通道描述符。换句话说,通过这个操作,我们可以获得每个特征通道的全局上下文信息。
Excitation:激励操作是通过一个全连接(Fully Connected, FC)层来学习非线性交互,以便捕获特征通道之间的依赖关系。具体来说,首先通过一个全连接层(FC)对通道描述符进行降维(通常通过一个收缩因子进行降维,例如16),然后通过ReLU激活函数进行非线性变换,接着再通过一个全连接层(FC)恢复到原始维度,并通过sigmoid激活函数将其映射到0到1之间,得到每个通道的权重。这个权重就可以用来重新校准原始特征通道。
通过这种方式,SENet可以有效地模拟特征通道之间的依赖关系,并且能够动态地调整每个特征通道的权重,从而提高模型的表现。对图5-48流程进行详细说明。
1)输入经过一系列传统卷积得到特征图,对先做一个Global Average Pooling,输出的数据,这个特征向量一定程度上可以代表之前的输入信息,论文中称之为压缩(Squeeze)操作。
2)再经过两个全连接来学习通道间的重要性,用Sigmoid限制到[0, 1]的范围,这时得到的输出可以看作每个通道重要程度的权重,论文中称之为扩展(Excitation)操作。
3)最后,把这个的权重乘到的个通道上,这时就根据权重对的通道进行了重要程度的重新分配。

三、效果
与SE 模块可以嵌入到现在几乎所有的网络结构中,而且都可以得到不错的效果提升,用过的都说好。
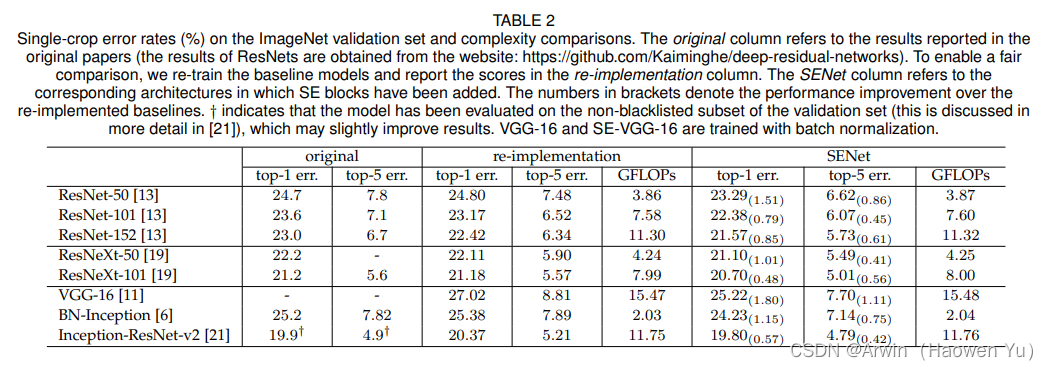
在大部分模型中嵌入SENet要比非SENet的准确率更高出1%左右,而计算复杂度上只是略微有提升,具体如下图所示。 而且SE块会使训练和收敛更容易。CPU推断时间的基准测试:224×224的输入图像,ResNet-50 164ms,SE-ResNet-50 167ms。

四、代码
这里给出模型搭建的python代码(基于pytorch实现)。完整的代码是基于图像分类问题的(包括训练和推理脚本,自定义层等)详见我的GitHub: 完整代码链接
class SqueezeExcitation(nn.Module):
def __init__(self, pervious_layer_channels, scale_channels=None, scale_ratio=4):
super().__init__()
if scale_channels is None:
scale_channels = pervious_layer_channels
# assert input_channels > 16, 'input channels too small, Squeeze-Excitation is not necessary'
squeeze_channels = make_divisible8(scale_channels//scale_ratio, 8)
self.fc1 = nn.Conv2d(pervious_layer_channels, squeeze_channels, kernel_size=1, padding=0)
self.fc2 = nn.Conv2d(squeeze_channels, pervious_layer_channels, kernel_size=1, padding=0)
def forward(self, x):
weight = F.adaptive_avg_pool2d(x, output_size=(1,1))
weight = self.fc1(weight)
weight = F.relu(weight, True)
weight = self.fc2(weight)
weight = F.hardsigmoid(weight, True)
return weight * x
五、总结
SENet模型是一种通过自适应地重新加权输入特征图的通道来增强模型表达能力的卷积神经网络结构。由胡杰等人在2018年提出。
SENet的核心思想是通过一个“Squeeze-and-Excitation”模块来学习输入特征图的通道之间的关系,从而自适应地调整特征图中每个通道的权重。具体来说,“Squeeze-and-Excitation”模块包含两个步骤。
“Squeeze”:通过全局池化操作,将输入特征图的每个通道压缩成一个标量,用于表示该通道的重要性。
“Excitation”:使用一个小型的全连接神经网络,学习一个激活函数,将上一步中得到的每个通道的重要性进行自适应调整,并重新加权输入特征图的通道。
通过这样的操作,SENet可以自适应地增强模型的表达能力,减少冗余信息的传递,并且在不增加网络复杂度的情况下提高模型的准确率。此外,SENet可以很容易地嵌入到其他深度卷积神经网络结构中,使得其更容易应用于实际的计算机视觉任务中。
SENet模型在许多视觉任务中都取得了出色的表现,比如在ImageNet图像分类任务中,SENet-154取得了迄今为止最好的单模型结果。同时,SENet还被广泛应用于各种其他视觉任务中,如目标检测、语义分割等。
六、ImageNet图片分类大赛回顾
到此为止,关于 ImageNet 图片分类大赛举办以来(2012-2017),所有的冠军模型以及介绍完了。这些模型在计算机视觉领域都是里程碑意义的工作,学习这些模型来入门基于深度学习解决方案的计算机视觉再合适不过了。以下稍作回顾:
ImageNet
- 是一个超过15 million的图像数据集,大约有22,000类。
- 是由李飞飞团队从2007年开始,耗费大量人力,通过各种方式(网络抓取,人工标注,亚马逊众包平台)收集制作而成,它作为论文在CVPR-2009发布。当时人们还很怀疑通过更多数据就能改进算法的看法。
- 深度学习发展起来有几个关键的因素,一个就是庞大的数据(比如说ImageNet),一个是GPU的出现。(还有更优的深度模型,更好的优化算法,可以说数据和GPU推动了这些的产生,这些产生继续推动深度学习的发展)。
ILSVRC
- 是一个比赛,全称是ImageNet Large-Scale Visual Recognition Challenge,平常说的ImageNet比赛指的是这个比赛。
- 使用的数据集是ImageNet数据集的一个子集,一般说的ImageNet(数据集)实际上指的是ImageNet的这个子集,总共有1000类,每类大约有1000张图像。具体地,有大约1.2 million的训练集,5万验证集,15万测试集。
- ILSVRC从2010年开始举办,到2017年是最后一届。ILSVRC-2012的数据集被用在2012-2014年的挑战赛中(VGG论文中提到)。ILSVRC-2010是唯一提供了test set的一年。
- ImageNet可能是指整个数据集(15 million),也可能指比赛用的那个子集(1000类,大约每类1000张),也可能指ILSVRC这个比赛。需要根据语境自行判断。
- 12-17年期间在ImageNet比赛上提出了一些经典网络,比如AlexNet,ZFNet,VGG,GoogLeNet,ResNet, DenseNet, SENet。我之前的博文都有相应模型及其变体的介绍。

值得注意的是ZFNet和ResNeXt,其中这两个模型都不是当年的冠军,但是知名程度却都比冠军模型多很多,主要原因如下:
ZFNet是由 Matthew D.Zeiler 和 Rob Fergus 在 AlexNet 基础上提出的大型卷积网络,在 2013年 ILSVRC 图像分类竞赛中以 11.19% 的错误率获得冠军。ZFNet 实际上并不是 ILSVLC 2013 的赢家。相反,当时刚刚成立的初创公司 Clarifai 是 ILSVLC 2013 图像分类的赢家。又刚刚好 Zeiler 是 Clarifai 的创始人兼首席执行官,而 Clarifai 对 ZFNet 的改动较小,故认为 ZFNet 是当年的冠军。
至于ResNeXt,是因为2016年的冠军模型Trimps-Soushen模型并不是开源模型,人们并不知道其模型设计的细节,所以自然没有亚军ResNeXt知名。
ImageNet的意义
ImageNet数据集的一个特点是它为分类中的每个图像都标注了一个主要的物体,这也决定了ImageNet主要用于单个物体的分类和定位。自2010年以来,每年的ImageNet挑战赛都会包括三个基本任务:图像分类、单物体定位和物体检测。
然而,ImageNet的单一标签分类方式并不符合真实世界中图像的分布特征,因此具有较大的局限性。李飞飞早在2014年便考虑取消某个任务的比赛,但由于业界的偏爱而未作出调整。直到2015年,直到2015年,ResNet模型提出了训练深度神经网络的有效方法,并通过超越人类的精度,在图像分类任务中取得了突破性进展,这几乎宣告了ImageNet挑战赛的结束。此外,算法层面的模型已经达到了过拟合的极限,继续竞争的意义已不大。例如,2016年有许多团队为了夺冠不惜花费巨资进行模型训练,其计算成本已经超出了普通人的想象,甚至有人开始研究非常规方法。实际上,这种为了夺冠而疯狂刷榜的行为已经偏离了ImageNet比赛的初衷。与其投入精力和成本来攀比,ImageNet比赛的初衷应该是在算法上的创新。
每一个比赛都承载了我们对技术发展的期望。然而,随着技术的进步,我们也逐渐发现这些数据集的局限性。虽然ImageNet挑战赛已经结束,但其中的一些任务,例如物体检测方面的研究,仍将继续下去。事实上,ImageNet挑战赛的落幕只是一个曲终人散的过程,而不是终结。在短短的十几年内,人工智能与计算机视觉研究已经发生了翻天覆地的变化。这一切都离不开ImageNet大赛的贡献。
2017年7月,太平洋上的小岛,旅游胜地檀香山(Honululu)迎来了来自世界各地的5000余名计算机视觉研究者,计算机视觉的顶级学术会议CVPR在此拉开序幕。同时,最后一届ImageNet挑战赛的研讨会也在CVPR 2017上举行。在6月26日,ImageNet挑战赛的研讨会召开,李飞飞进行了题为IMAGENET—Where Have We Been?Where Are We Going?(ImageNet:我们来自何方,我们去向何处)的演讲,回顾了ImageNet从2010年首次举办以来的8年历程。
李飞飞认为,ImageNet对AI研究最大的贡献是改变了人们的思维模式。越来越多的研究者意识到,数据可能是迈向人类水平的人工智能过程中的关键因素,而不是模型。“数据重新定义了我们对模型的思考方式。”她表示,尽管ImageNet挑战赛结束了,但ImageNet数据集的维护和相关研究仍将会继续。在单标签识别问题基本得到解决后,近年来,她开始关注视觉理解、视觉关系的预测等视觉之外的内容,并开始着手建立相关的数据集。