一、业务介绍
商品详情页,简单说就是以购物者的角度展现一个sku的详情信息。
这个页面不同于传统的crud的详情页,使用者并不是管理员,需要对信息进行查删改查,取而代之的是点击购买、放入购物车、切换颜色等等。
另外一个特点就是该页面的高访问量,虽然只是一个查询操作,但是由于频繁的访问所以我们必须对其性能进行最大程度的优化。
商品详情所需构建的数据如下:
- Sku基本信息
- Sku图片信息
- Sku所属分类信息
- Spu销售属性相关信息
- Sku对应的销售属性默认选中
- Sku价格 实时
- 商品介绍内容主体(海报)
- sku对应的属性(平台属性,规格)
二、使用缓存实现优化
虽然咱们实现了页面需要的功能,但是考虑到该页面是被用户高频访问的,所以性能必须进行尽可能的优化。
一般一个系统最大的性能瓶颈,就是数据库的io操作。从数据库入手也是调优性价比最高的切入点。
一般分为两个层面,一是提高数据库sql本身的性能,二是尽量避免直接查询数据库。
提高数据库本身的性能首先是优化sql,包括:使用索引,减少不必要的大表关联次数,控制查询字段的行数和列数。另外当数据量巨大是可以考虑分库分表,以减轻单点压力。
重点要讲的是另外一个层面:尽量避免直接查询数据库。
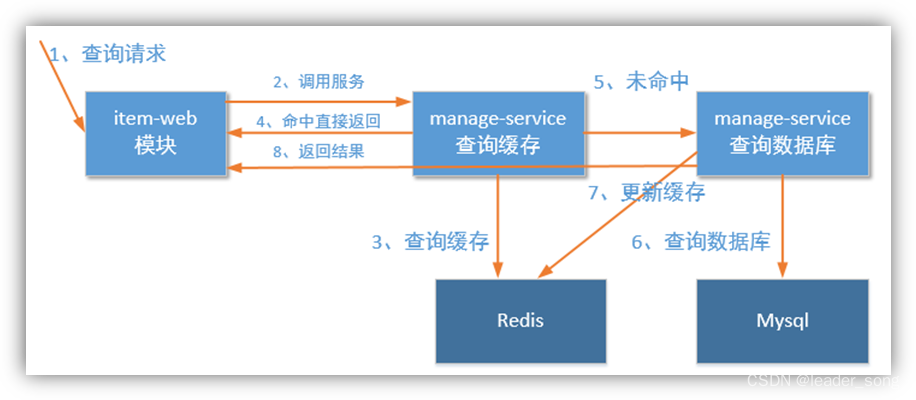
解决办法就是:缓存
缓存可以理解是数据库的一道保护伞,任何请求只要能在缓存中命中,都不会直接访问数据库。而缓存的处理性能是数据库10-100倍。
咱们就用Redis作为缓存系统进行优化。
为什么使用redis就快,使用本地缓存
本地缓存:
内存容量小
缓存数据随着项目消失而消失
内存数据库,Nosql数据库,非关系型数据
- redis基于内存存储的,减少了IO操作
- 可以根据key快速的获取对应的value
- 没有SQL语句解析的成本消耗
结构图:
三、缓存存在的问题与解决(重点中的重点)
缓存最常见的3个问题:
1.缓存穿透
概念:查询一个数据,这个数据缓存中没有,就会去查Mysql,但是mysql中也没有,这种情况就会导致 每一次访问都会穿透到Mysql数据库,给mysql造成了压力,导致缓存没起作用。
解决:
1、缓存中没有,查数据库,如果数据库中也没有这个数据,就创建一个对象,这个对象的属性没有值(就是一个 空对象),把这个对象放到redis缓存中,过期时间稍微短一些,因为这个数据没用,只是防止一段时间的缓存穿透。
2、布隆过滤器:能判断一个数据是否存在。
可以使用redisson的自带的布隆过滤器,在添加商品sku的时候,把skuid添加到布隆过滤器中。查询时,先查缓存,如果缓存没有,就根据skuid去布隆过滤器中找,看存不存在,如果存在再去查询数据库,把数据库的数据加载到缓存中,以便于后续查询可以从缓存中获取。如果布隆过滤器中没有,那就不需要查数据库了,直接返回数据不存在。
2.缓存雪崩
概念:redis缓存不可用了,大量的失效了。
- redis的数据库的服务器 不能提供访问了。
- 大量的key集体过期了。
解决: 服务器不可用的问题,需要保证redis的高可用,redis做集群部署。
Key集体过期,在设置key过期时间时,使用随机时间。
3.缓存击穿
概念: 一个热点的key,正好过期了,这时有大量的查询访问来了,导致这大量的请求瞬间击穿到数据库,让数据库压力倍增。
穿透:缓存中没有 数据库里也没有
击穿:一定是热点的数据过期了,缓存中过期了没有了,数据库中还存在。只要有访问去查数据库了,就可以把数据库中的数据 加载到redis缓存中。
解决办法:
分布式锁。
本地锁:synchronized 是JVM级别的锁,只能锁住一台服务器,跨服务就锁不了。
测试的时候 使用AB压测,进行 大量线程发送了大量请求。
分布式锁的实现:
- redis的setNX命令+key的过期时间+lua脚本
set nx命令 是只有key不存在的时候 才能添加进去数据,key如果存在了,就添加不进去
正常情况下 redis的set命令 如果key没有是新增,如果key存在了 是覆盖。
key的过期时间:是防止加锁之后 执行业务处理时出问题,不能删除锁,就需要依赖过期时间 实现锁的自动释放,防止死锁。
Lua的目的:删除锁的时候,防止自己把别的线程加的锁给删了。
- 基于redisson的分布式锁。
Redisson框架给提供了 Lock对象
Api方法 lock.lock ()或者trylock()加锁
Lock.unLock()进行解锁了。
使用redisson分布式,有一个看门狗的机制,可以实现锁的自动续期。
使用看门狗,就不能给key设置过期时间,默认30s,如果30s到了,你还没有调用解锁方法,它会认为你的业务还没有执行完,自动的给续一次过期时间。
锁有过期时间,防止锁过期了,你的业务还没执行完,导致别的线程又进来了。
查询商品数据的时候具体步骤:(使用布隆过滤器)
- sku添加的时候 把sku的id添加到布隆过滤器中
- 先查缓存,看缓存有没有
- 缓存没有,查布隆过滤器,看布隆过滤器中是否存在这个数据
- 存在 加分布式锁,去查数据库。如果不存在,直接返回空了,不需要查数据库了。
查询商品数据的时候具体步骤:(不使用布隆过滤器,使用空对象)
- 先查缓存,看缓存有没有
- 缓存没有,加分布式锁,去查数据库。判断数据库有没有
3、 数据库存在 就放入到缓存中,如果数据库没有这个数据,创建一个空对象 放入到缓存中,过期时间较短一些。
代码冗余的情况 进行优化:
自定义注解+AOP的动态代理+redisson分布式锁 业务抽取 加以复用.
设计模式的思想: 动态代理模式+模板模式
模板模式:一个类中有10个方法,其中有多个方法共用了一段代码,咱们可以把这段共用的代码 抽取成一个方法,这样的话 这段代码只需要写一次,哪个方法需要用,直接在需要使用的方法内 进行这个方法调用.抽取出来的这个方法 就是一个模板.
自定义一个注解:
作用:声明作用,只有打上这个注解的方法 就被分布式锁给控制了.
分布式锁业务处理:
写了一个切面类,这个切面类中 是加锁 查库 加入缓存 解锁的业务.
什么时候做这个加锁解锁:
切面类中 定义了一个 通知,通知的作用就是告诉方法,什么时候去动态的给做功能增强.
* AOP:面向切面编程
* 切入点:使用AOP 对哪块进行功能上的增强,自动的去帮助别人做一些事。
* 可以是一个包 或者 多个包,也可以是一个类 或者一个方法,也可以是一个注解
* 切面:要做什么事?要做的具体内容
* 通知:什么时候做这个事?
* 环绕通知、前置、后置、异常
与缓存雪崩的区别:
1. 击穿是一个热点key失效
2. 雪崩是很多key集体失效
解决方案:
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
使用分布式锁,采用redis的KEY过期时间实现
命令+key的过期时间
Redis:命令 setNX+key的过期时间
# set skuid:1:info “OK” NX PX 10000
EX second :设置键的过期时间为 second 秒。
PX millisecond :设置键的过期时间为 millisecond 毫秒。
NX :只在键(key)不存在时,才对键(key)进行设置操作。
XX :只在键(key)已经存在时,才对键(key)进行设置操作。
Redis SET命令用于设置给定key的值,如果key已经存在其他值,SET就会覆盖,且无视类型。
问题:删除操作缺乏原子性。
场景:
1. index1执行删除时,查询到的lock值确实和uuid相等
2. index1执行删除前,lock刚好过期时间已到,被redis自动释放
3. index2获取了lock
4. index1执行删除,此时会把index2的lock删除
解决:使用LUA脚本保证删除的原子性
使用redisson分布式锁
redisson : 工具
官方文档地址:https://github.com/redisson/redisson/wiki
RLock lock = redisson.getLock("anyLock");
// 最常使用
lock.lock();
// 加锁以后10秒钟自动解锁
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
4、分布式锁 + AOP实现缓存
随着业务中缓存及分布式锁的加入,业务代码变的复杂起来,除了需要考虑业务逻辑本身,还要考虑缓存及分布式锁的问题,增加了程序员的工作量及开发难度。而缓存的玩法套路特别类似于事务,而声明式事务就是用了aop的思想实现的。
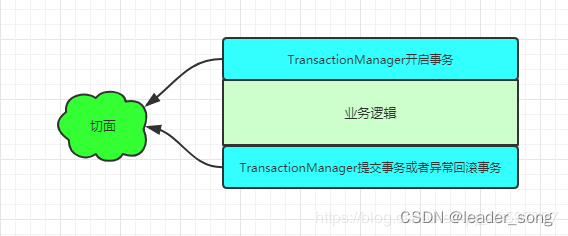
以 @Transactional 注解为植入点的切点,这样才能知道@Transactional注解标注的方法需要被代理。
@Transactional注解的切面逻辑类似于@Around
模拟事务,缓存可以这样实现:
1. 自定义缓存注解@GmallCache(类似于事务@Transactional)
2. 编写切面类,使用环绕通知实现缓存的逻辑封装
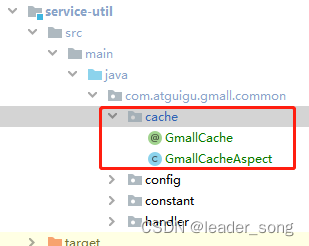
定义一个注解
|
定义一个切面类加强注解
|
使用注解完成缓存
@GmallCache(prefix = RedisConst.SKUKEY_PREFIX)
@Override
public SkuInfo getSkuInfo(Long skuId) {
return getSkuInfoDB(skuId);
}四.使用异步线程优化商品详情
面试题:
1)你们项目中有没有做过并行任务
异步编排就是
2)你们项目的并发量是多少
正式上线的数据我不清楚,但是我自己压测过我写的接口,并发量500~700之间
问题:查询商品详情页的逻辑非常复杂,数据的获取都需要远程调用,必然需要花费更多的时间。
Service-item商品详情的服务远程调用 service-product商品管理服务
假如商品详情页的每个查询,需要如下标注的时间才能完成
| // 1. 获取sku的基本信息 0.5s // 2. 获取sku的图片信息 0.5s // 3. 获取spu的所有销售属性 1s // 4. sku价格 1.5s //5、增加热度 1.0s 可能 调用评论接口 ... |
那么,用户需要4.5s后才能看到商品详情页的内容。很显然是不能接受的。
如果有多个线程同时完成这4步操作,也许只需要1.5s即可完成响应。
使用多线程 同时调用的形式,提升了接口的响应速度,执行速度.
线程资源使用自定义线程池管理,并且线程池是单例的,咱们怎么实现的单例,没有去写什么懒汉式 饿汉式,基于spring的ioc实现单例,因为spring的bean的作用域,默认就是单例的,咱们把自己创建的线程池 放入spring容器中了,使用@bean注解.
1.使用CompletableFuture实现异步线程优化商品详情
|
|
2.简历:
责任描述
- 负责商品详情模块开发与优化,具体包括详情页展示、SKU锁定、SKU切换等功能
- 负责。。。
- 负责。。
- 参与。。
- 参与。。。
技术描述
- 项目采用Redis作为分布式缓存,使用Redisson解决缓存击穿,使用。。。。
- 项目采用异步编排解决。。。。
- 项目采用AOP
- 项目采用
- 项目采用nacos
- 项目采用 gateway 跨域、鉴权、请求转发
7~8
断点调试:

1:定位到当前断点处
2:下一步或者执行下一行
3:进入到方法里,我们写的方法,不包括源码
4:强制进入方法里面,包括源码
5:跳出方法
6: 调到光标所在行
7:计算表达式并返回结果
8:放到当前断点进入一下个断点,如果没有直接放行
9:查询所有已经打的断点
10:禁止断点