目录
内容介绍
| 1、Linux下MySQL的安装与使用 2、逻辑架构 3、sql预热
扫描二维码关注公众号,回复:
16141782 查看本文章

|
Linux下MySQL的安装与使用
*查看容器
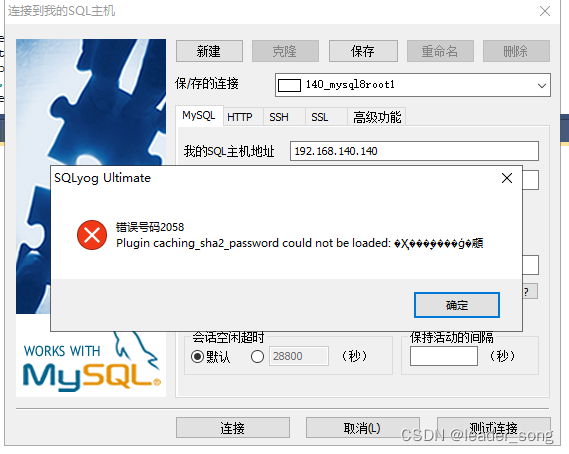
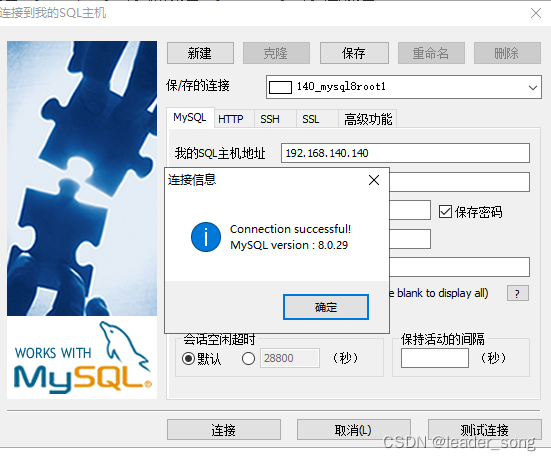
2、远程连接问题 (1)问题
(2)解决方案 #进入容器:env LANG=C.UTF-8 避免容器中显示中文乱码 docker exec -it atguigu-mysql8 env LANG=C.UTF-8 /bin/bash #进入容器内的mysql命令行 mysql -uroot -p #修改默认密码校验方式 ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
3、字符集
4、sql_mode (1)是什么 Mysql提供的sql语法规范 (2)实例 CREATE DATABASE atguigudb; USE atguigudb; CREATE TABLE employee(id INT, `name` VARCHAR(16),age INT,dept INT); INSERT INTO employee VALUES(1,'zhang3',33,101); INSERT INTO employee VALUES(2,'li4',34,101); INSERT INTO employee VALUES(3,'wang5',34,102); INSERT INTO employee VALUES(4,'zhao6',34,102); INSERT INTO employee VALUES(5,'tian7',36,102); 需求:查询每个部门年龄最大的人 #查询每个部门年龄最大的人(错误写法) SELECT e.`dept`,MAX(e.`age`),e.`name` FROM employee e GROUP BY e.`dept`; #查询每个部门年龄最大 的人 SELECT e.`dept`,MAX(e.`age`)maxage FROM employee e GROUP BY e.`dept`; SELECT ee.*,e.`name` FROM employee e INNER JOIN ( SELECT e.`dept`,MAX(e.`age`)maxage FROM employee e GROUP BY e.`dept` )ee ON e.`dept` =ee.dept AND e.`age`= ee.maxage;
|


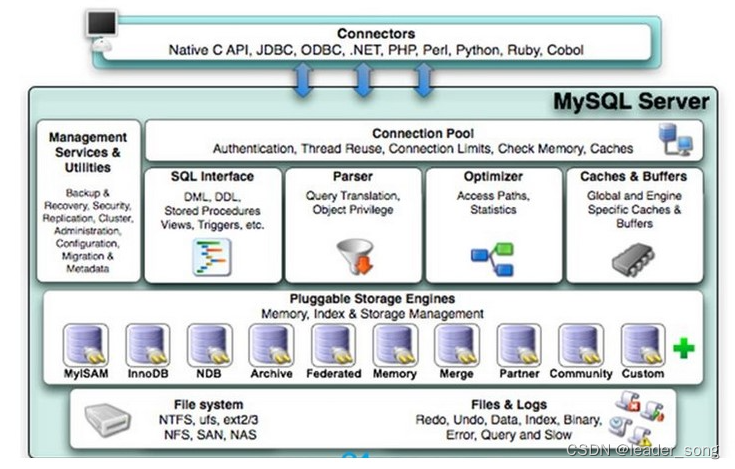
Mysql逻辑架构
| 1、逻辑架构图 下面是MySQL5.7使用的
2、客户端 MySQL服务器之外的客户端程序,与具体的语言相关,例如Java中的JDBC,图形用户界面SQLyog等。 3、服务层 (1)连接层 第一件事就是建立 TCP 连接、身份认证、权限获取 (2)服务层 Management Serveices & Utilities: 系统管理和控制工具 SQL Interface:SQL接口:接收用户的SQL命令,并且返回用户需要查询的结果。 Parser:解析器:解析器中SQL 语句进行`词法分析、语法分析、语义分析`,并为其创建`语法树`。 Optimizer:查询优化器: 不改变查询结果前提下,调整sql顺序,生成执行计划 Caches & Buffers: 查询缓存组件:在MySQL 8之后就抛弃了这个功能。 (3)引擎层 负责MySQL中数据的存储和提取,对物理服务器级别维护的底层数据执行操作,服务器通过API与存储引擎进行通信 4、存储层 所有的数据、数据库、表的定义、表的每一行的内容、索引,都是存在 5、执行顺序
6、SQL执行流程(MySQL8) (1).开启profiling
SET profiling = 1;
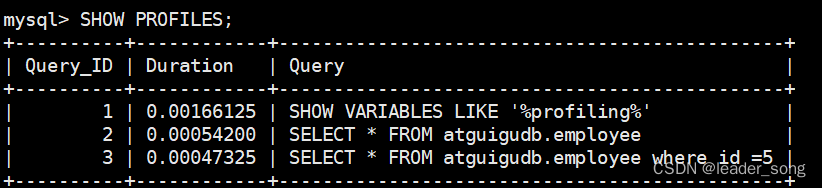
(2)显示查询` *执行sql SELECT * FROM atguigudb.employee; SELECT * FROM atguigudb.employee WHERE id = 5; *查看计划 SHOW PROFILES;
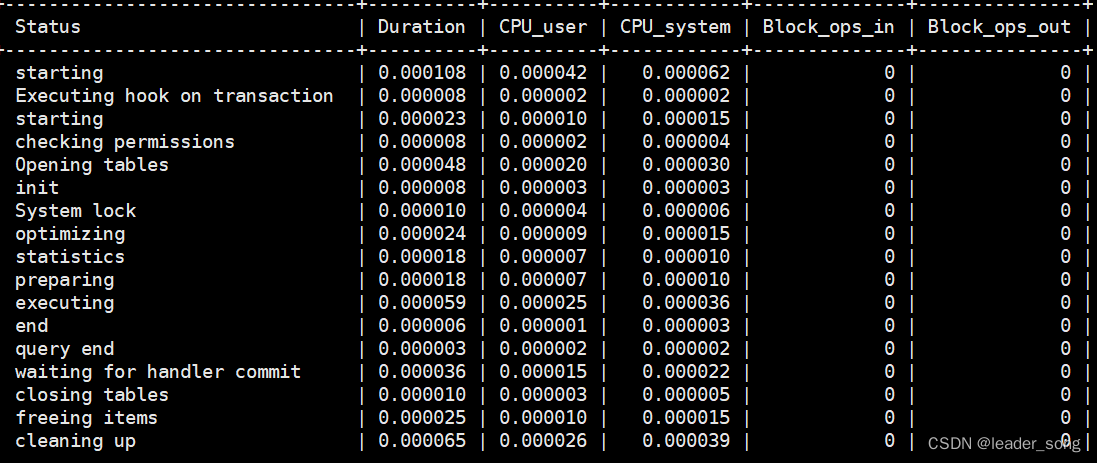
(3)查看某个查询计划流程 SHOW PROFILE cpu,block io FOR QUERY 3;
|
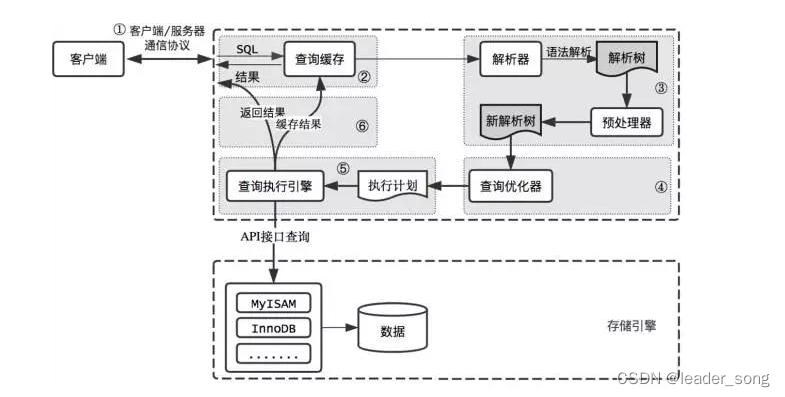


Mysql存储引擎
| 1、MyISAM和InnoDB的区别
|

Sql预热
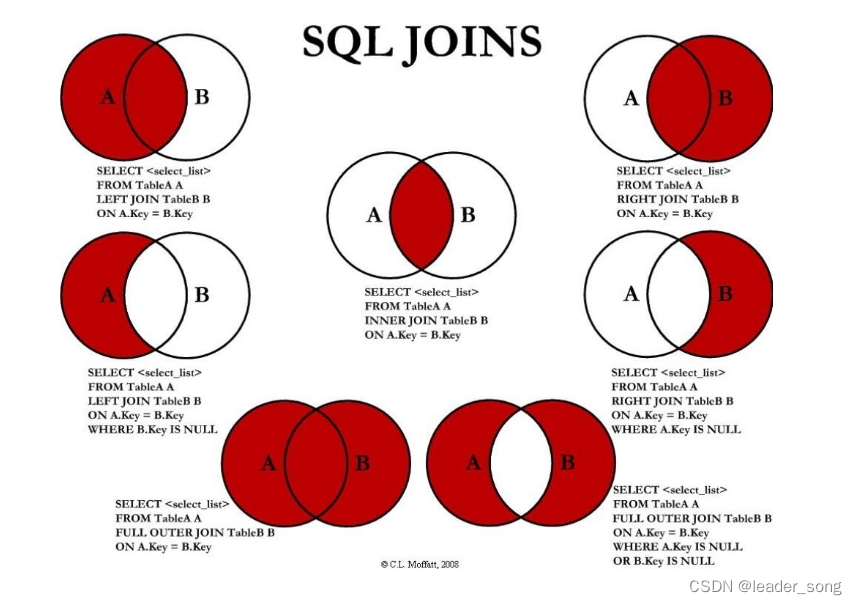
2、常见七种JOIN查询
3、修改表,增加难度 |
索引简介
| 1、是什么 索引(Index)是帮助MySQL高效获取数据的数据结构。 排好序的快速查找数据结构 2、索引优缺点 (1)优点:查询快、排序快 (2)缺点:所有写操作变慢 占用大量磁盘空间 3、索引分类
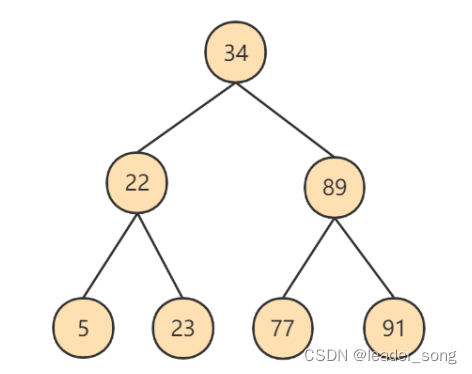
4、树 (1)二叉树 对于二叉排序树的任何一个非叶子节点,要求左子节点的值比当前节点的值小,右子节点的值比当前节点的值大。
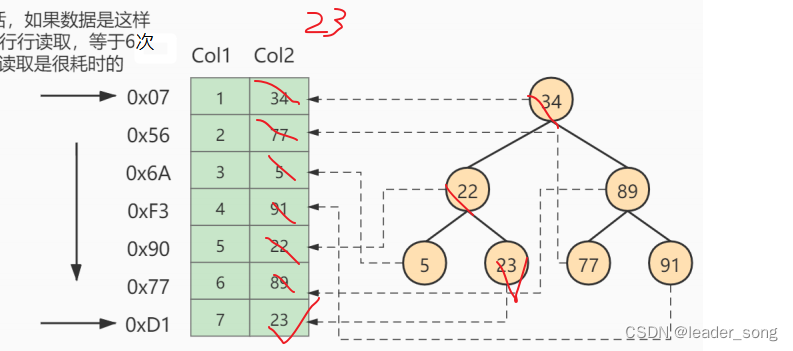
*最好情况
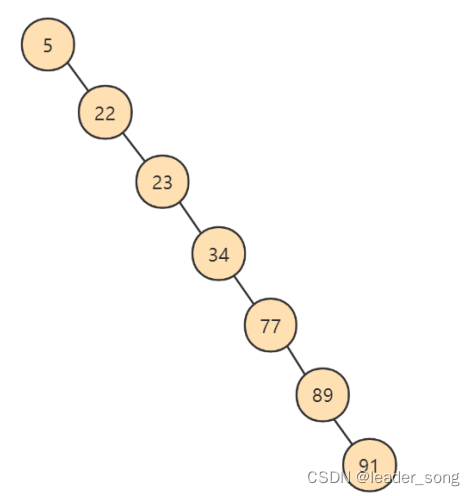
*最坏情况
(2)平衡二叉树(AVL)
缺点
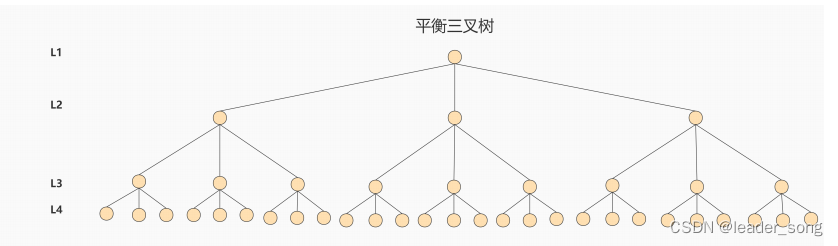
解决问题,可以使用平衡三叉树
|