前言:
MySQL 到 DM 的移植主要有以下几个方面的工作:
- 1.分析待移植系统,确定移植对象。
- 2.通过数据迁移工具 DTS 完成常规数据库对象及数据的迁移。
- 3.通过人工完成 MSQL 的移植。
- 4.移植完成后对移植的结果进行校验,确保移植的完整性和正确性。
- 5.对应用系统进行移植、测试和优化。
一、分析待移植系统,确定移植对象
- 操作系统:ky10.x86_64 GUN/Linux
- mysql版本:8.0.32
- DM版本:64 V8 0x7000c
- 应用开发平台:java
- 应用开发接口: JDBC
统计 MySQL 数据中的对象以及表数据量
--根据指定用户统计用户下的对象数目
// 表数目
SELECT
count(*) TABLES,
table_schema
FROM
information_schema.TABLES
WHERE
table_schema = '数据库名称'
GROUP BY
table_schema;
// 存储过程
SELECT
count(1) PROCEDURES
FROM
information_schema.Routines t1
WHERE
db = '数据库名称'
and
t1.ROUTINE_TYPE = 'PROCEDURE';
// 函数
SELECT
count(1) FUNCTIONS
FROM
information_schema.Routines t1
WHERE
db = '数据库名称'
and
t1.ROUTINE_TYPE = 'FUNCTION';
查询结果:
表数目 :TABLES:381
存储过程数目:PROCEDURES:28
函数数目:FUNCTIONS:24
mysql 8.0开始删除了proc表,mysql8.0之前使用proc表
// 存储过程
SELECT
count(1) PROCEDURES
FROM
MySQL.proc
WHERE
db = '数据库名称'
AND `type` = 'PROCEDURE';
// 函数
SELECT
count(1) FUNCTIONS
FROM
MySQL.proc
WHERE
db = '数据库名称'
AND `type` = 'FUNCTION'
mysql与dm之间实例和表空间的区别
梳理一下大体的区别,在迁移时,做好mysql与dm中实例与表空间的对应关系;
从 MySQL 移植到DM,要求先创建好待使用的用户和这个用户的表空间, 不要把数据移植到系统默认的管理员 SYSDBA 用户下和 MAIN 表空间下。
- MySQL:单实例多库,。
- DM7 以上:单库多实例。
- 从MySQL 迁移到达梦的时候就需要针对 MySQL 中的每一个库在达梦里面创建一个用户和表空间来对应。
例如 MySQL 中有一个库 test,达梦里面先创建一个表空间 tab_test,然后创建一个用户 test,指定默认表空间为 tab_test。
迁移 MySQL 中 test 库的数据的时候,用 root 用户连接 MySQL,指定当前
库为 test;用 test 用户连接达梦,这样就把 MySQL test 库中的数据迁移到了达梦test 用户中。
- 我们在做MySQL 移植的时候要先分析本次移植需要从源库中移植哪一个库 或者哪几个库的数据,然后为每一个库,分别在达梦中创建独立的表空间和用户;
- 大多数情况下,我们需要移植的数据所在的 MySQL 实例里面有多个库,并不是所有的库都需要移植,所以再移植准备阶段,一定要和相关技术负责人员沟通明确清楚。
二、通过数据迁移工具 DTS 完成常规数据库对象及数据的迁移
通过达梦数据库数据迁移同步工具 DTS 将原系统中结构化数据迁移到国产
化数据库,DTS支持:
- DM 数据库之间模式、表、序列、视图、存储过程/函数、包、触发器、对象权限的迁移;
- 主流大型数据库 Oracle、SQLServer、MySQL、DB2、PostgreSQL、Informix、Kingbase、Sybase的模式、表、视图、序列、索引迁移到 DM;
- DM 的模式、表、视图、序列、索引迁移到主流大型数据库 Oracle、SQLServer、MySQL;
- ODBC 数据源、JDBC 数据源的模式、表、视图迁移到 DM;
- DM 数据库模式、表、序列、视图、存储过程/函数、包、触发器、对象权限迁移到 XML 文件,SQL 脚本文件;
- DM 数据库的表、视图数据迁移到文本文件,Excel 文件,Word 文件;
- 指定格式的文本文件,Excel 文件,Word 文件,XML 文件和 SQL 脚本文件迁移到 DM 数据库。
开始迁移
打开dts工具
cd到DM 数据库安装目录下 tool 文件夹,执行./dts
cd /dm8/tool
./dts
在dts上新建迁移工程
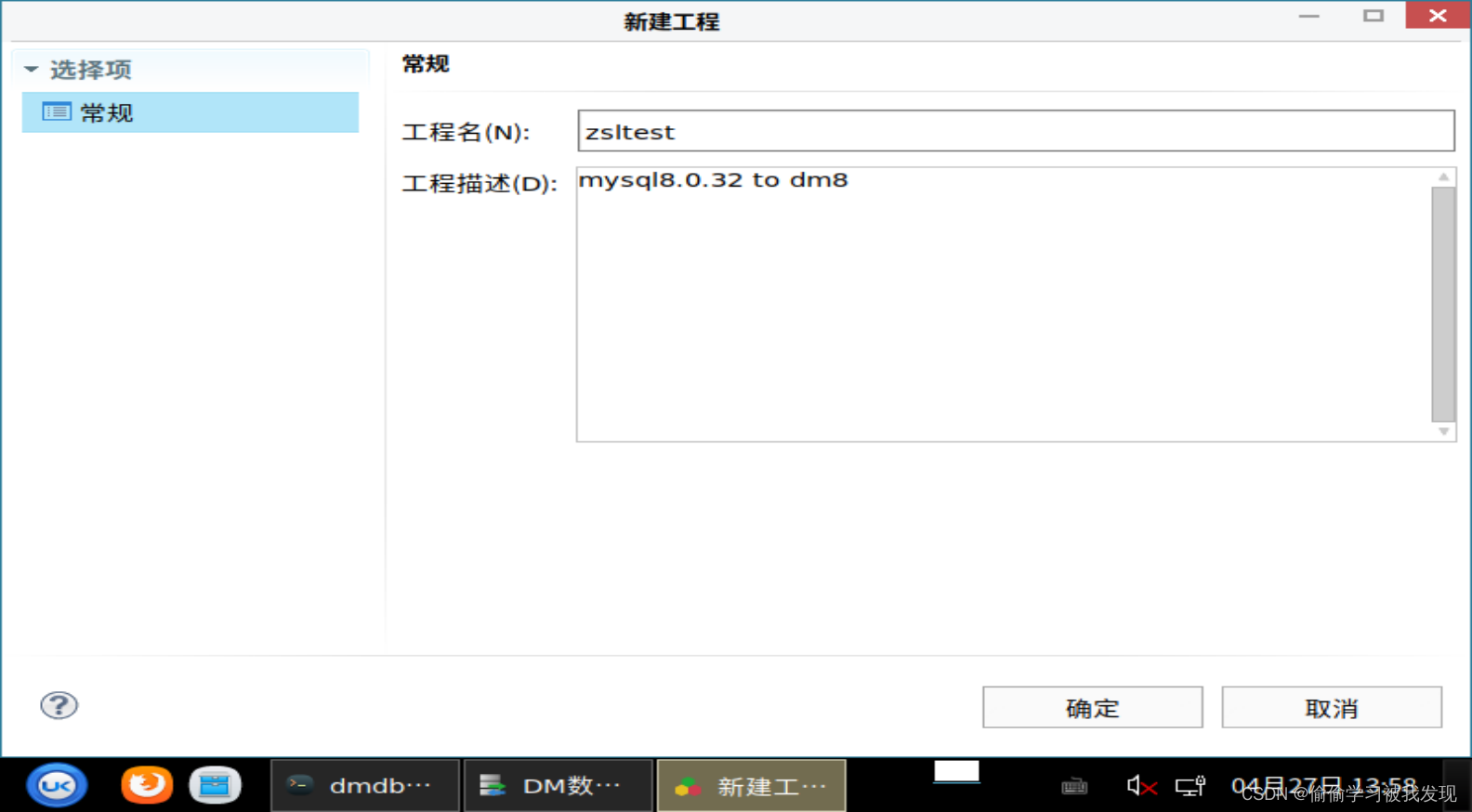
新建迁移任务
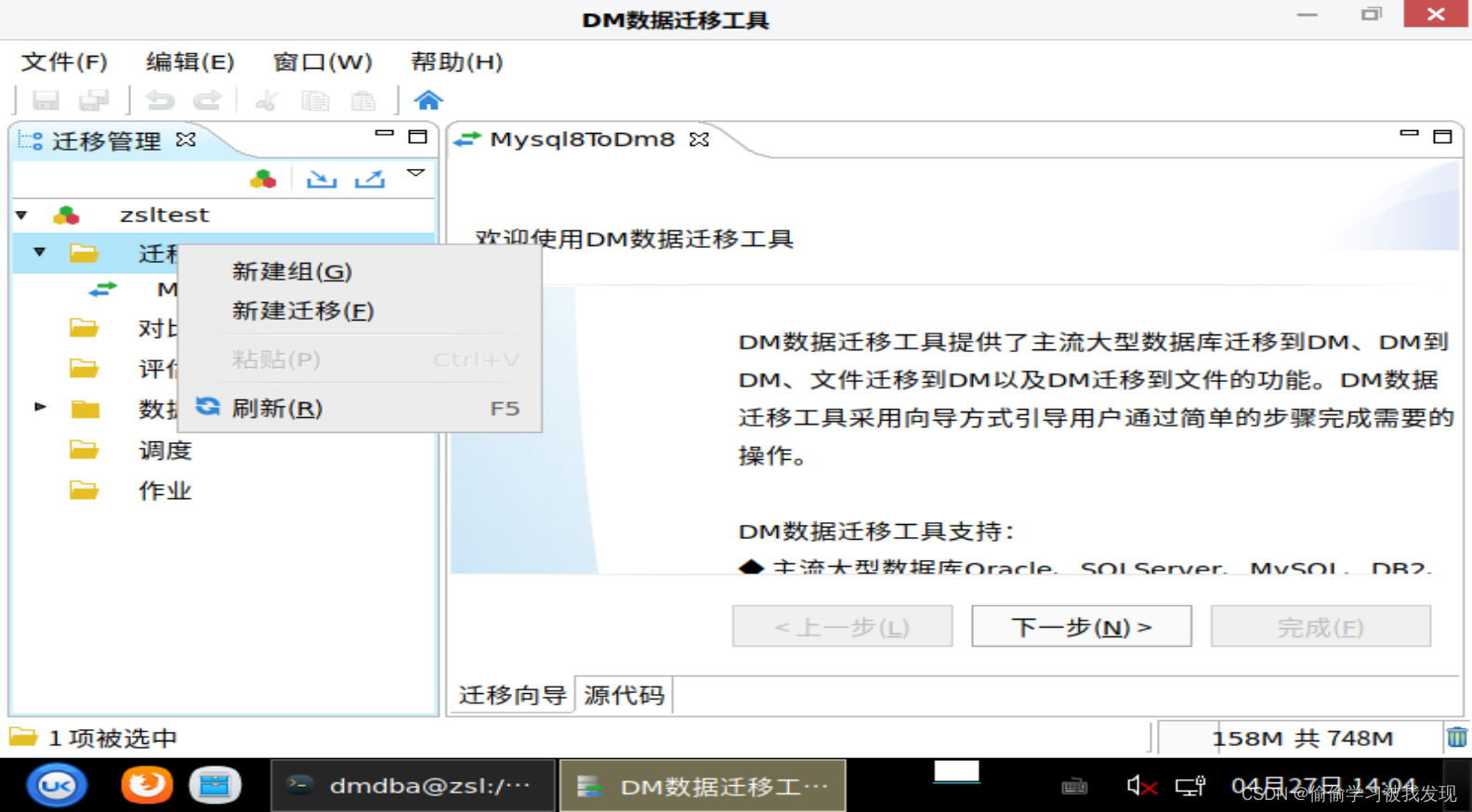

选择迁移方式
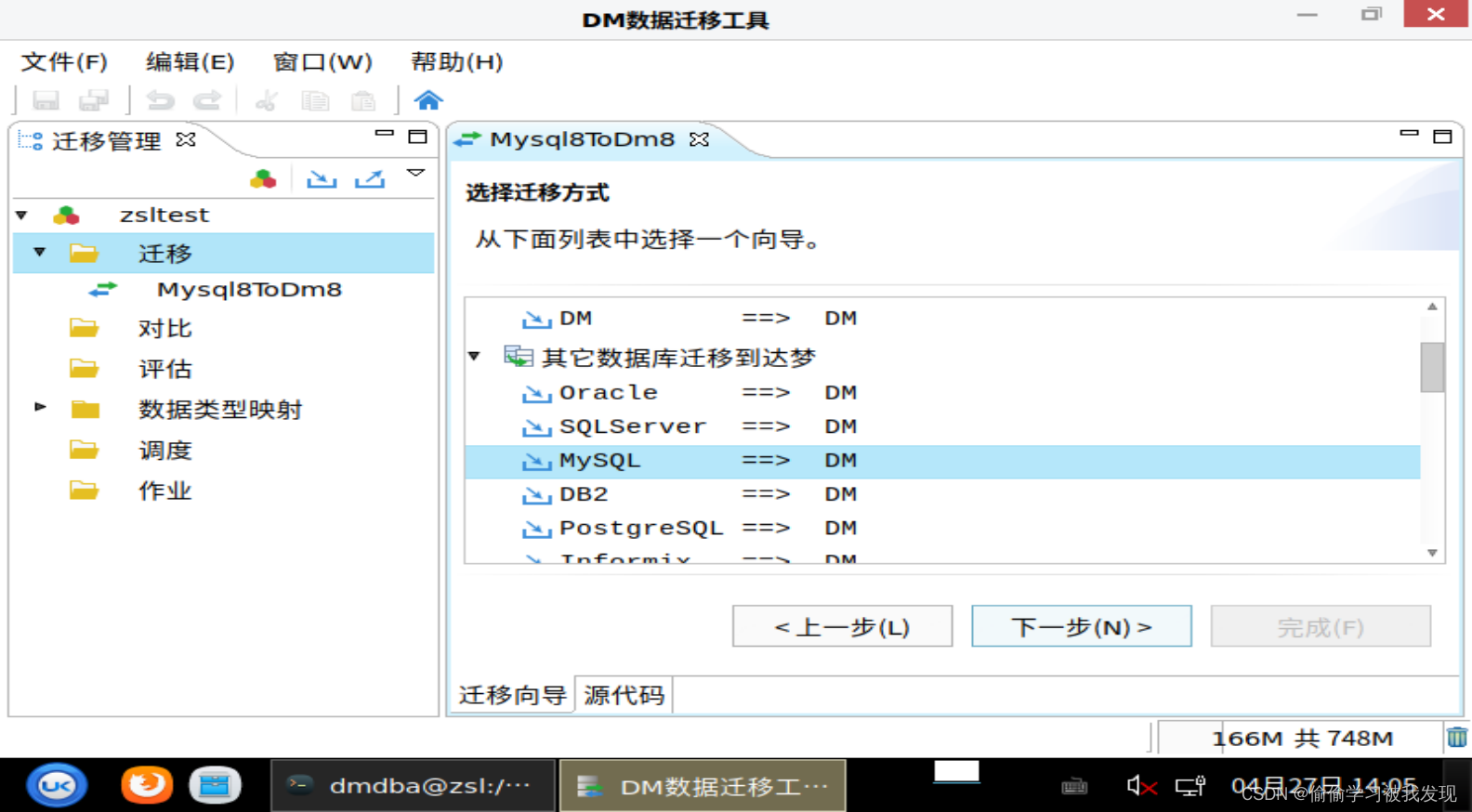
连接迁移数据源
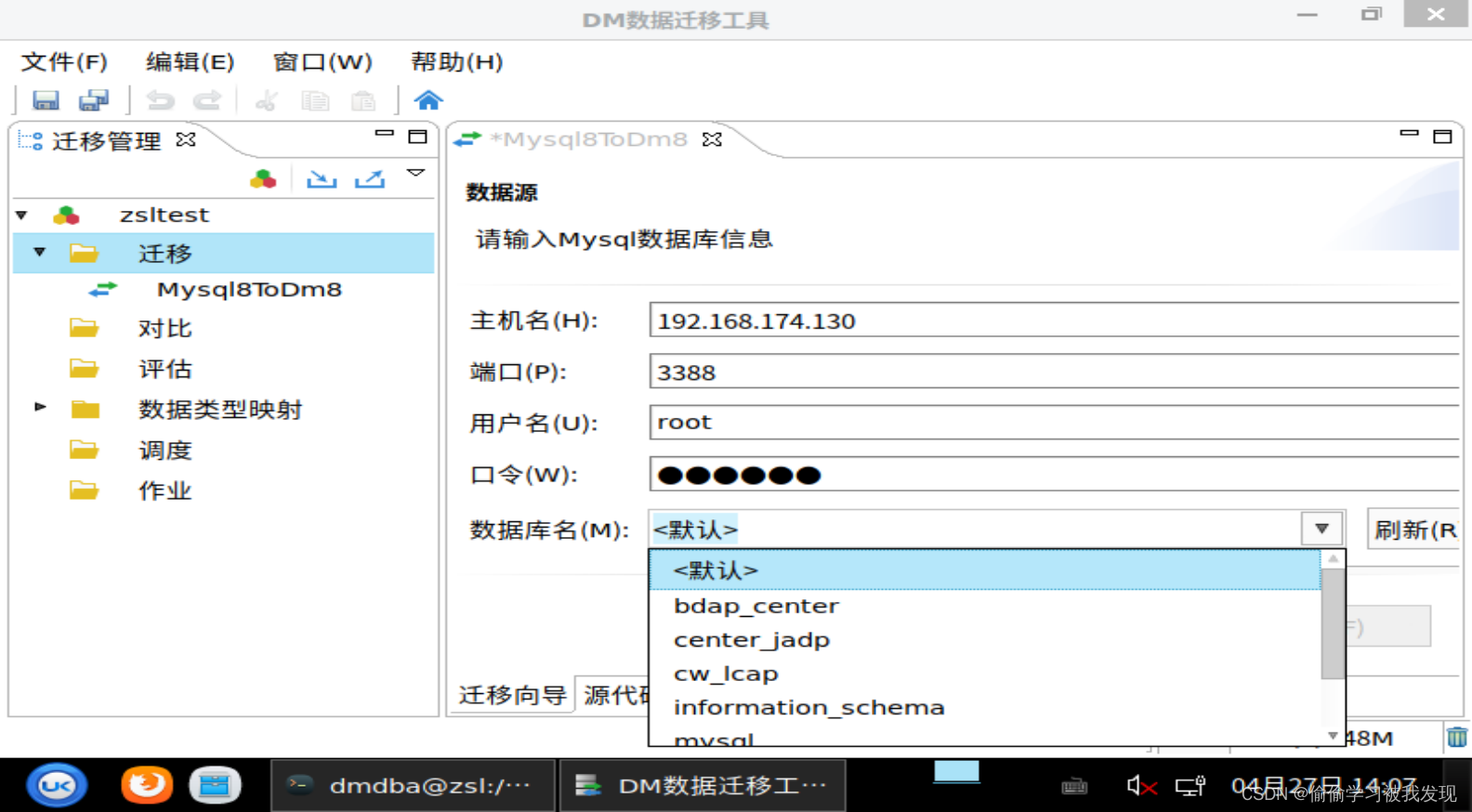
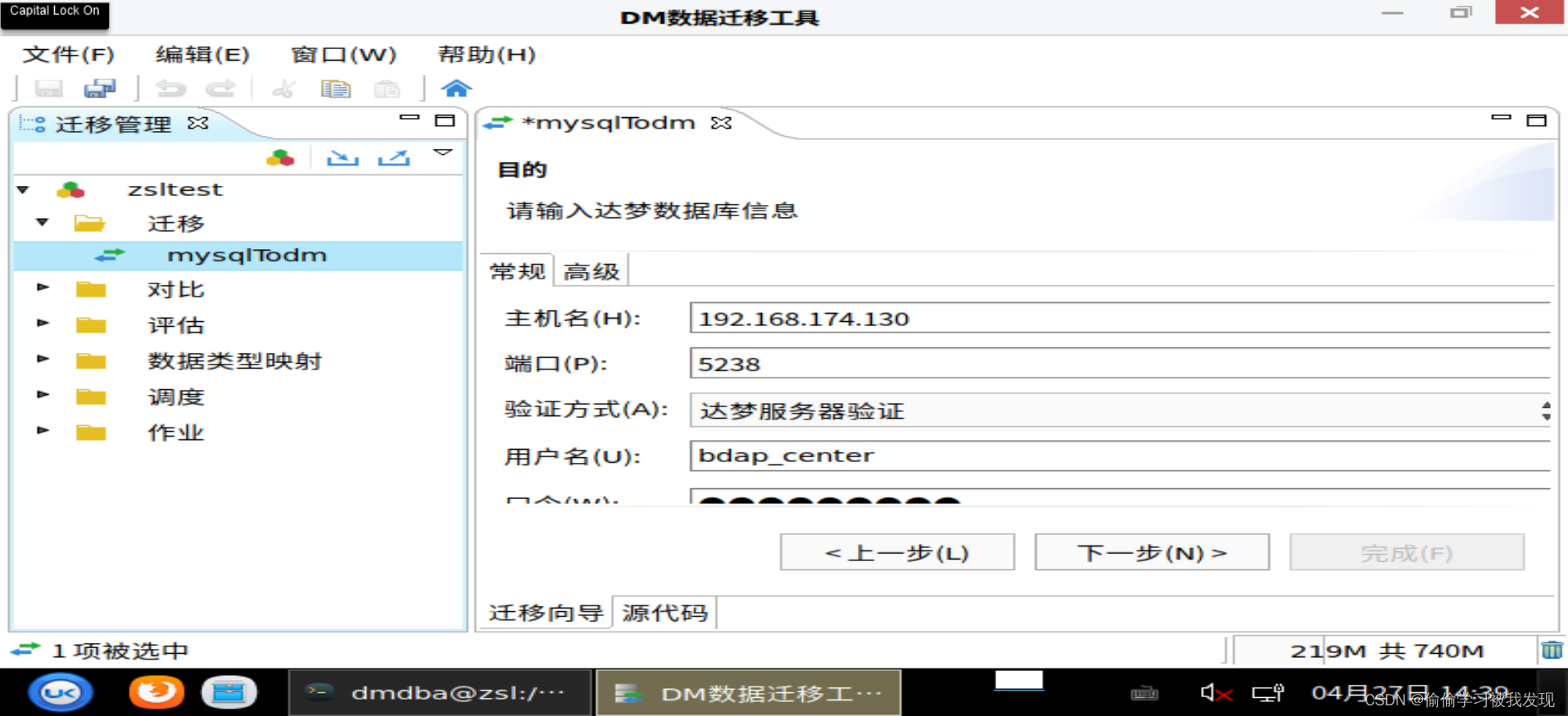
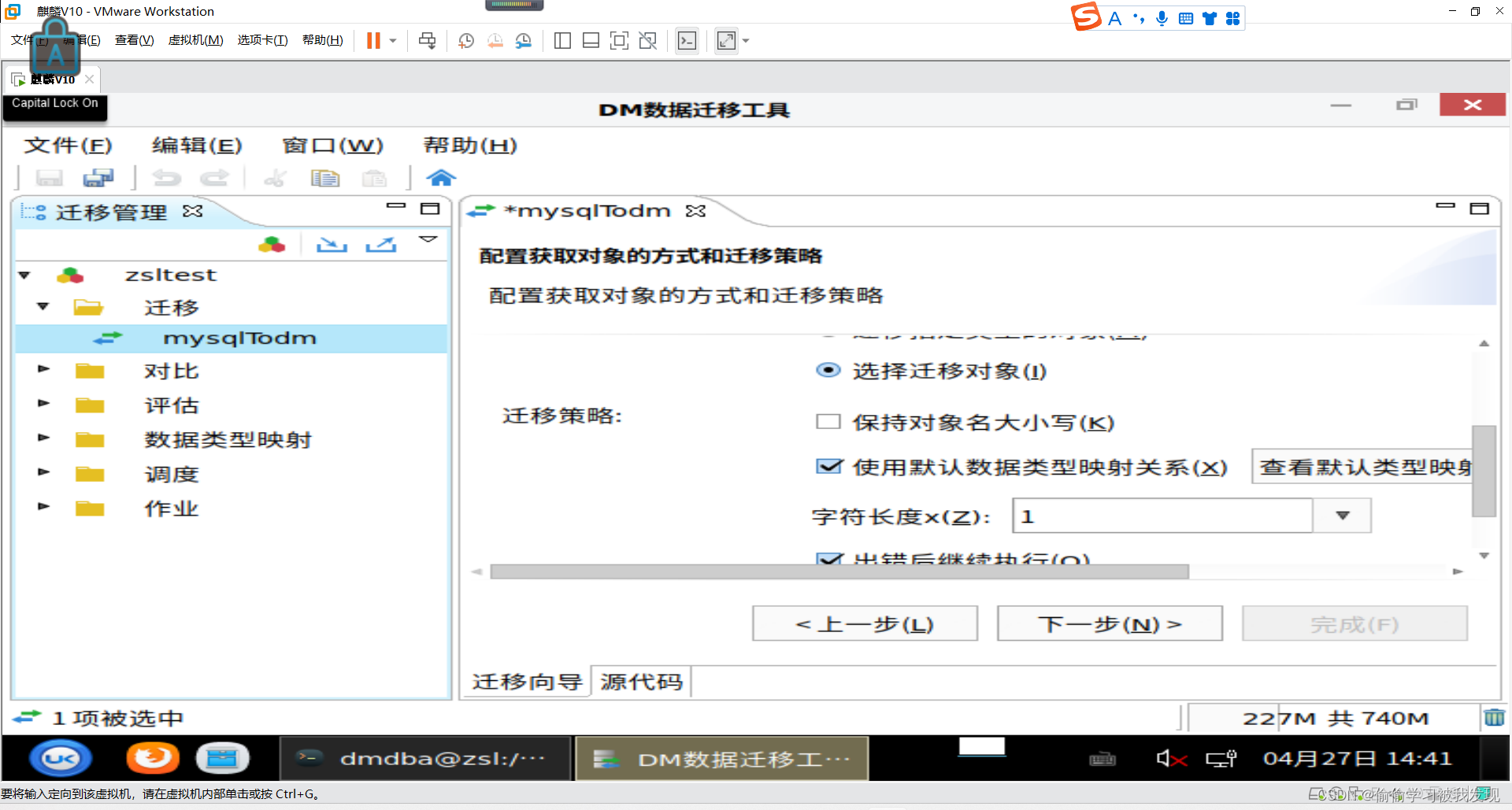
从数据源复制对象,包括模式及模式对象,目录,公共同义词或者上下
文(目的模式选择自己要用的模式)。
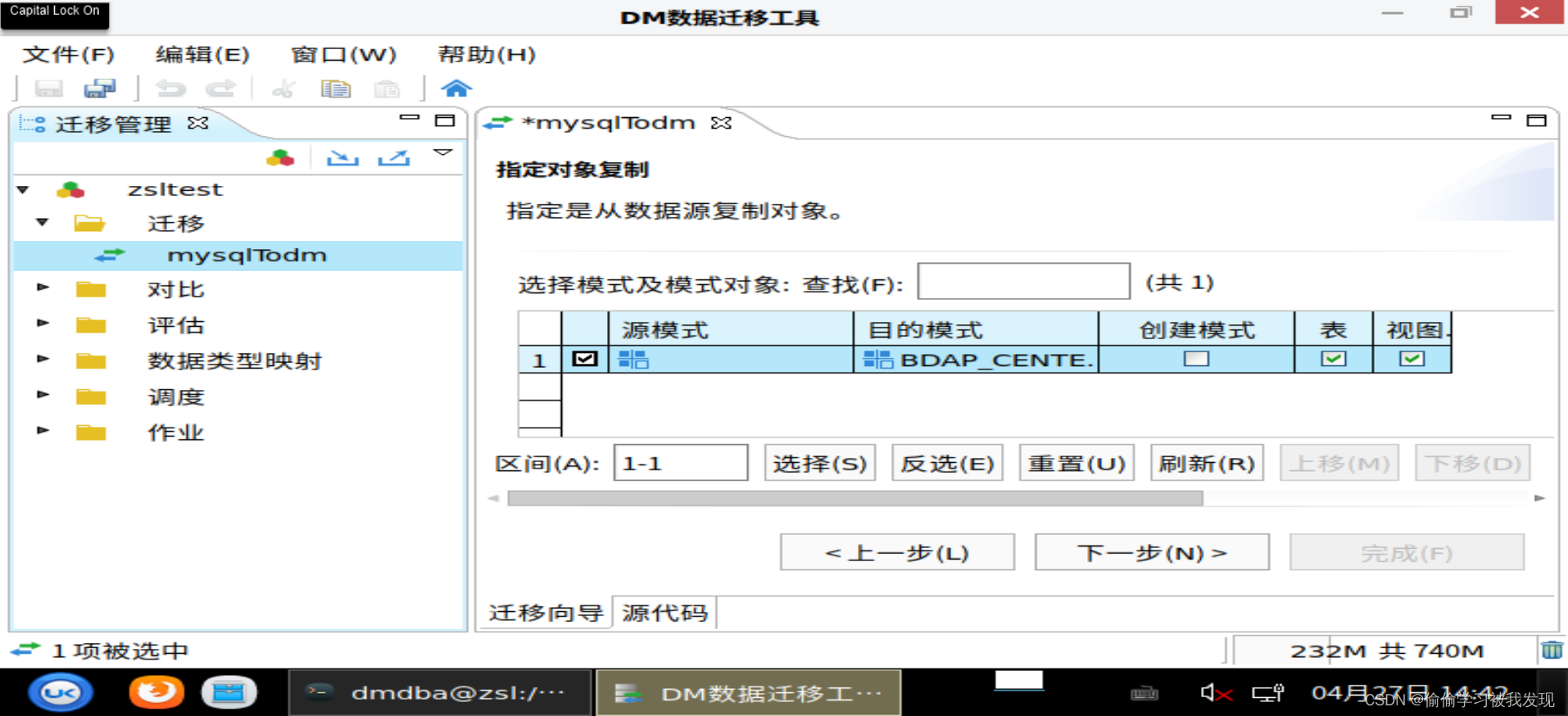
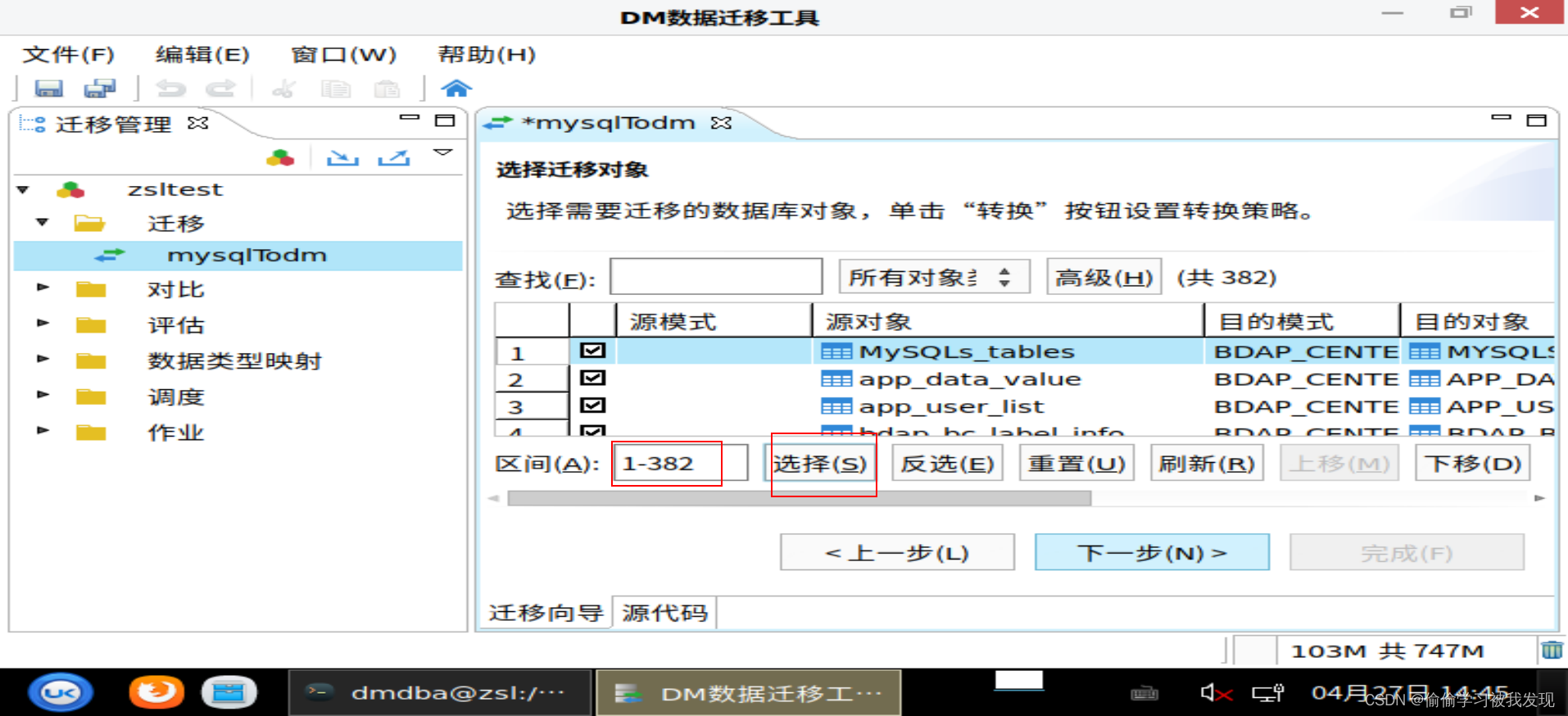
选择迁移对象
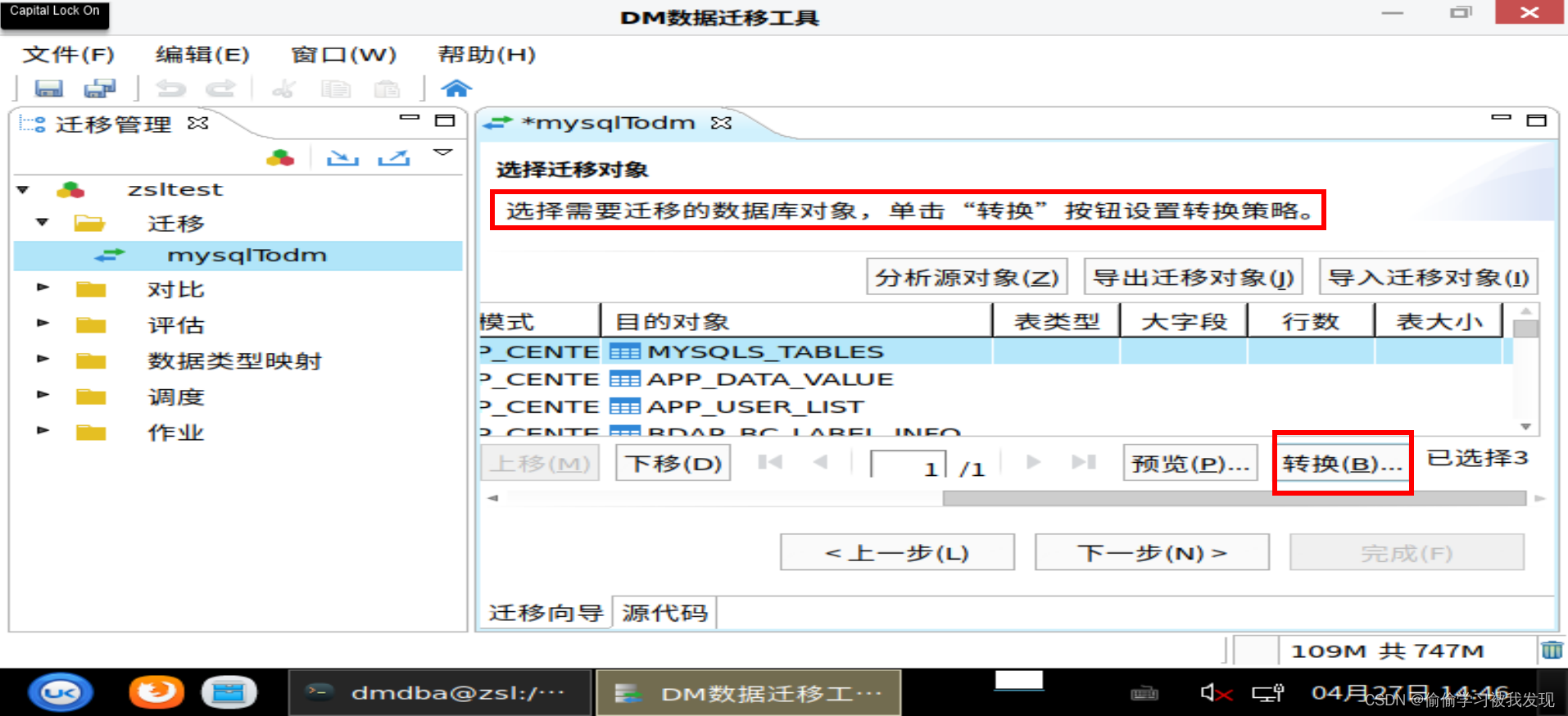
设置转换策略
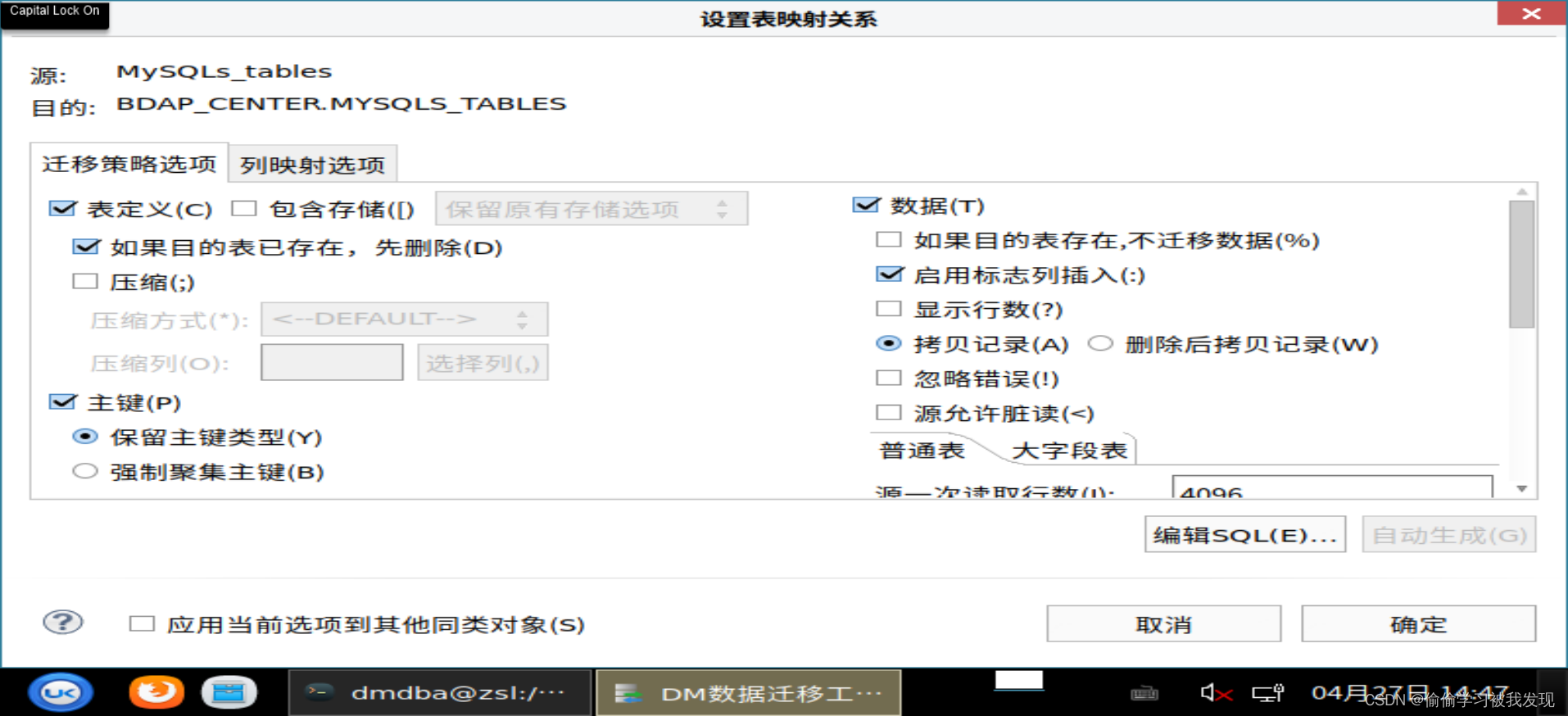
执行迁移任务
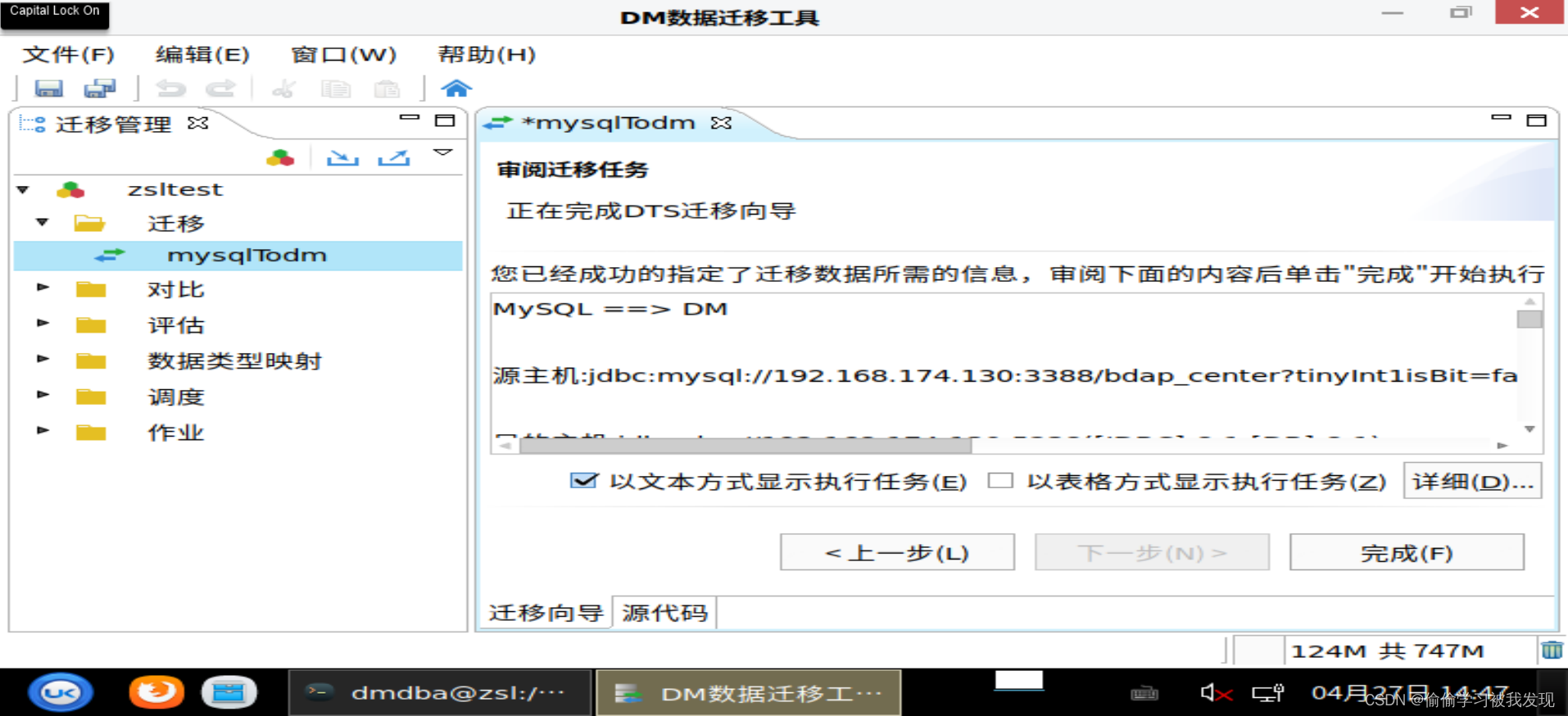
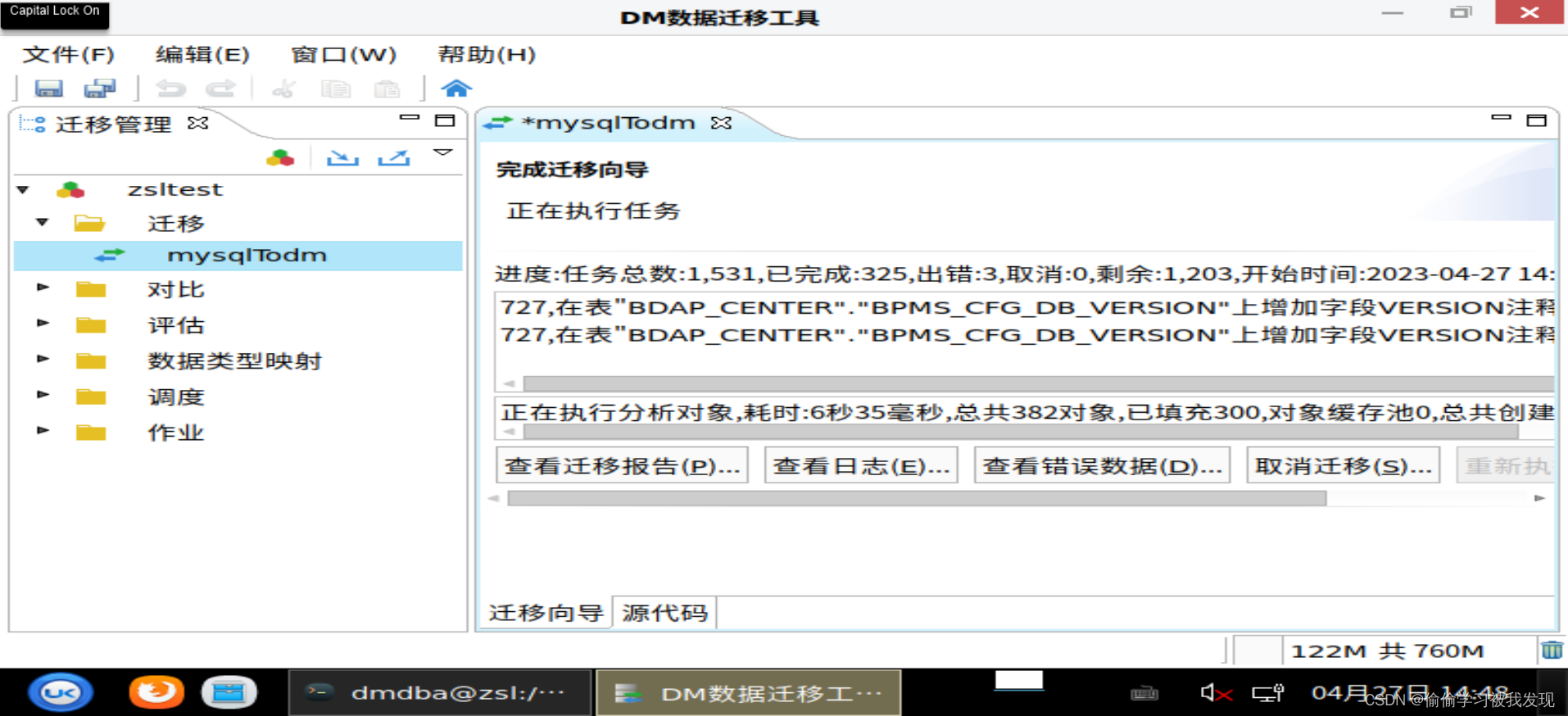
三、通过人工完成 MSQL 的移植
因为上面我们是全部对象直接全选,默认导入的dm的,肯定存在语法转换上的问题,我们可以通过查看失败对象和日志来人工完成失败对象的移植。
对系统中的表和视图,可以使用达梦 DTS 工具进行迁移。如果还用到了自
定义类型、存储过程、函数、触发器等,需要导出源端数据库上的定义,手动去修改sql脚本,再到dm执行:
首先,可以先从 MySQL 导出用户对象 sql 脚本,MySQL 导出存储过程及函
数的执行命令:
MySQLdump-hhostname-uusername-ppassword-ntd-Rdatabasename>prorandfu
nc.sql
然后,将导出的 sql 脚本,经人工修改之后,再导入到达梦数据库中运行。
数据迁移常见问题
- 1.无效的数据类型
请核查字段定义中的 int 类型,是否有精度,如果有,请直接去掉。即 int(10)需要改成 int,去掉精度。(达梦数据库的 int 类型,不需要、也不能设置精度)。
create table test1(v1 int(10),v2 varchar(20));
需要更改成
create table test1(v1 int,v2 varchar(20);
- 2.TIMESTAMP
类型 在 MySQL中时间类型TIMESTAMP 默认default 设 置 为
“ 0000-00-0000:00:00 ” , 而在 DM 中 TIMESTAMP 类型数据不能为
“0000-00-0000:00:00”,在 DM 中是不合法的,必须在
‘0001-01-0100:00:00.000000’
到’9999-12-3123:59:59.999999’之间。 可通过修改直接修改 MySQL 中的业务表数据后进行数据迁移或通过DTS的使用 SQL 进行迁移数据。
- 3.DEFAULT
设置 对于字段的 default 设置,默认的字符或字符串默认值,需要添加单引号’',如 achar(10) default ‘abc’。
- 4.TEXT 类型
对于 text 字段类型,若在多条 SQL 中存在对 text 字段类型的 distinct 处理,可根据具体情况决定是否将 text 字段类型改变为 varchar 类型,或对查询结果进行其他方式的过滤。
- 5.精度放大 3 倍
在 2019-9-18 以前的 DM 迁移工具中,如果 MySQL 源端的表字符集为utf8,迁移到达梦的时候 CHAR、VARCHAR
类型的精度会自动放大三倍。如果不能接收这种精度的放大,有两个办法:
1.把 MySQL 的表定义导出成文本,手动修改为 DM 语法。
2.去官网下载 2019-9-18 以后的版本。
- DATE_FORMAT()函数
以 date_format 函数为例,MySQL 中的 date_format 函数可以在 DM 数据库 中使用 to_char 或 to_date 函数改写,改写后在达梦中可以达到相同的效果,示例如下:
--MySQL
select date_format(sysdate(), '%Y 年%m 月') from dual
-- DM
select translate(to_char(sysdate, 'yyyy-mm#'),'-#','年月') from dua
--MySQL
select DATE_ FORMAT(C_ FIRST_TIME,'%Y-%m-%d %H') FROM DUAL;
-- DM
select TO_CHAR(C_FIRST_TIME, 'YYYY- MM- DD HH24') FROM DUAL;
- IF()函数
MySQL 中的 if()函数在当前测试版本 DM 中不支持,需采用 casewhen 进行替代,后续新版本可能会支持。
- CONVERT()函数
DM 的 convert()函数中的 type 在前,value 在后,而 MySQL 数据库中 convert()函数则恰恰相反,对于 cast()函数的用法则一致,测试示例如下:
--MySQL
CONVERT(
CASE WHEN TEMP_STA.c_data_value & lt;0
THEN NULL
ELSE TEMP_STA.c_data_value
END,SIGNED
) AS "ONLINEUSER",
-- DM
CONVERT(
INTEGER,CASE WHEN TEMP_STA.c_data_value <0
THEN NULL
ELSE TEMP_STA.c_data_value
END
) AS "ONLINEUSER"
- CAST()函数
DM 中的 cast()函数的用法虽然和 MySQL 一致,但使用效果存在不同,MySQL 中对于数值类型的 value 转 char 类型没有限制,DM 中则存在限制,会报“数据转换失败”等报错,可将 cast(数值类型的 valueaschar)转换为 cast(数值类型的valueasvarchar),对于unsigned类型可以根据实际情况做对应改变或确定是否有必要进行转换。
- FIND_IN_SET()函数
MySQL 字符串函数 find_in_set(str1,str2)函数就是查询字段(strlist)中包含(str)的结果,返回结果为 null 或记录,也就是返回 str2 中 str1 所在的位置索引,str2必须以","分割开。同 like 相比,like 是广泛的模糊匹配,字符串中没有分隔符,而 Find_IN_SET 是精确匹配,字段值以英文”,”分隔,Find_IN_SET 查询的结果要小于 like 查询的结果。而在 DM 中没有对应的函数,需要编写自定义函数,如下:
CREATE
OR REPLACE FUNCTION SYSDBA.FIND_ IN_SET (
piv_str1 varchar2,
piv_str2 varchar2,
p_sep varchar2 := ','
) RETURN NUMBER IS l_idxnumber := 0;
-- 用于计算 piv_str2 中分隔符的位置
strvarchar2 (500);
-- 根据分隔符截取的子字符串
piv_strvarchar2 (500) := piv_str2;
-- 将 piv_str2 赋值给 piv_str
resnumber := 0;
-- 返回结果
BEGIN
-- 如果 piv_str 中没有分割符,直接判断 piv_str1 和 piv_str 是否相等,相等 res=1
IF instr(piv_str,
p_sep,
1) = 0 THEN
IF piv_str = piv_str1 THEN
res := 1;
END IF;
ELSE
-- 循环按分隔符截取 piv_str
LOOP l_idx := instr(piv_str,
p_sep);
-- 当 piv_str 中还有分隔符时
IF l_idx > 0 THEN
-- 截取第一个分隔符前的字段 str
str := substr(piv_str,
1,
l_idx - 1);
-- 判断 str 和 piv_str1 是否相等,相等 res=1 并结束循环判断
IF str = piv_str1 THEN
res := 1;
EXIT;
END IF;
piv_str := substr(
piv_str,
l_idx + LENGTH(p_sep)
);
ELSE
-- 当截取后的 piv_str 中不存在分割符时,判断 piv_str 和 piv_str1 是否相等,相
等 res = 1
IF piv_str = piv_str1 THEN
res := 1;
END
IF;
-- 无论最后是否相等,都跳出循环
EXIT;
END
IF;
END
LOOP
;
-- 结束循环
END
IF;
-- 返回 res
RETURN res;
END FIND_ IN_SET;
- GROUP_CONCAT 函数
对于 group_concat 函数,可以采用 DM 的 LISTAGG 函数进行替换,如下为MySQL 和 DM 中的函数应用和效果,如下:
-- MySQL
SELECT
group_concat(
ifnull(OPEN_STEP, '10')
ORDER BY
ID ASC SEPARATOR '、、'
)
FROM
ZHZB_DEV.BID_PACKAGE BP; 10、、10、、10、、10、、10、、10、、10、、10、、10、、10、、10、、10、、10、、10、、 10、、10.... SELECT
group_concat(
ifnull(OPEN_STEP, '10')
ORDER BY
ID ASC SEPARATOR '、、'
)
FROM
ZHZB_DEV.BID_PACKAGE BP
GROUP BY
AGENT_ ID;
-- DM
SELECT
LISTAGG (
ifnull("BP"."OPEN_STEP", '10'),
' 、 、 '
) WITHIN GROUP (ORDER BY "BP"."ID" ASC)
FROM
ZHZB_DEV.BID_PACKAGE BP;
SELECT
LISTAGG (
ifnull("BP"."OPEN_STEP", '10'),
' 、 、 '
) WITHIN GROUP (ORDER BY "BP"."ID" ASC)
FROM
ZHZB_DEV.BID_PACKAGE BP
GROUP BY
"BP"."AGENT_ID";
- DATE_ADD 函数
date_add 函数若对添加时间间隔的表达式进行求值,可采用 DM 的
TIMESTAMPADD 函数进行替代,例子如下:
--MySQL
select DATE_ADD(sysdate(), INTERVAL 1 YEAR);
--2020-07-02 11:24:18
-- DM
select TIMESTAMPADD(SQL_TSI_YEAR, 1,sysdate());
--2020-07-02 11:27:56.000000
- 其他函数
对于 MySQL 独有的函数或基于 MySQL 语法创建的自定义函数,在 DM 中需要基于 DM 的 SQL 语法进行改写,实现相同的功能。
- 时间间隔表达式
对 于 类 似
date_format(("S"."CREATE_TIME" + interval 1 year),'%Y')、
date_format((now() + interval -(1) year),'%Y'))的时间间隔表达式,对于 interval 关键词后的正数需添加单引号’',如 interval ‘1’ year,对于负数,需改写,如 interval ‘-1’。
关于DM 数据库参数
- 页大小
PAGE_SIZE
在 DM 数据库中,页大小可以为 4KB、8KB、16KB 或者 32KB,从 MySQL 移植到 DM,建议设置页大小为16KB,一旦创建好了数据库,在该库的整个生命周期内,页大小都不能够改变。除了每个字段的最大长度限制外,每条记录总长度不能大于页面大小的一半。如果系统中存在或者以后可能存在含有较长的字符串类型的表,可以按需调整,最大为32KB(也可以设置为 8KB)。页大小设置越大,最后数据文件的物理大小就会越大,系统运行时,每次从磁盘调入内存的数据单位也就越大,所以此处要慎重。
- 簇大小
EXTENT_SIZE
数据文件使用的簇大小,即每次分配新的段空间时连续的页数,只能是 16 页或 32 页,缺省使用 16 页,从 MySQL 移植到 DM 使用默认值就可。
- 大小写敏感
CASE_SENSITIVE
DM为了兼容不同的数据库,在初始化数据库的时候有一个参数字符串比较大小写敏感,用于确定数据库对象及数据是否区分大小写,默认为区分,不可更改。建议 MySQL 和 SQLSERVER 迁移过来的系统,使用大小写不敏感。
- 字符集
CHARSET
建议采用默认值 GB18030,如果需要国际字符可以采用 Unicode,GB18030 数字字母占 1 个字节,普通汉字占 2 个字节,部分繁体及少数民族文字占 4 字节,Unicode 在达梦中采用 UTF-8 编码格式,欧洲的字母字符占 1 到 2个字节,亚洲的大部分字符占 3 个字节,附加字符为 4 个字节。如果只存储中文和字母数字,一般来说 GB18030 更节省空间一些。
在 INI 参数的 compatibility 部分,还有其它的一些参数,在涉及到之前,尽
量保持默认值,在移植准备的环节,先只调整这个参数就可以了,其它参数,在移植过程中再具体分析。
compatibility : COMPATIBLE_ MODE
是否兼容其他数据库模式。
- 0 :不兼容,
- 1: 兼容 SQL92 标准,
- 2 :兼容 ORACLE ,
- 3 :兼 容 MS SQL SERVER ,
- 4 :兼容 MySQL ,
- 5 :兼 容 DM6,
- 6:兼容 Teradata
从 MySQL 移植到 DM 时,修改值为 4;
统计达梦数据基础信息
--统计页大小
select page; --统计编码格式
select unicode; --统计大小写敏感参数
select case_sensitive;
移植完成后对移植的结果进行校验,确保移植的完整性和正确性
统计达梦数据中的对象以及表数据量
--根据指定用户统计用户下的各对象类型和数目
SELECT
object_type count *
FROM
all_objects
WHERE
owner = ‘OA8000_DM2015’
GROUP BY
Object_type;
--统计指定用户下所有的对象,并记录到新的记录表中
CREATE TABLE dm_objects(obj_owner varchar(100),
obj_name varchar(100),
obj_type
varchar(50));
INSERT
INTO
dm_objects
SELECT
owner,
object_name,
object_type
FROM
all_objects
WHERE
owner = 'OA8000_DM2015';
--统计每个表的数据量到表数据记录表
CREATE TABLE dm_tables(tab_owner varchar(100),
tab_name varchar(100),
tab_count int);
DECLARE
BEGIN
FOR rec IN (
SELECT
owner,
object_name
FROM
all_objects
WHERE
owner = 'OA8000_DM2015'
AND object_type = 'TABLE') loop
EXECUTE IMMEDIATE 'insert into dm_tables select ''' | |
rec.owner | | ''',''' | | rec.object_name | | ''',count(*) from ' | | rec.owner | | '.' | |
rec.object_name;
END loop;
END;
SELECT
*
FROM
dm_tables;
对比达梦数据库中对象和 MySQL 库中对象以及数据量差异
-- 比对表数据量,找出数据量不相等的表
SELECT
a.tab_owner,
a.tab_name,
a.tab_count-b.tab_count
FROM
MySQL_tables a,
dm_tables b
WHERE
a.tab_owner = b.tab_owner
AND a.tab_name = b .tab_name
AND a.tab_count-b.tab_count <> 0
;
更新统计信息
数据核对完成无问题后, 应进行一次全库的统计信息更新工作。 统计信
息更新脚本示例如下:
DBMS_STATS.GATHER_SCHEMA_STATS(
'HNSIMIS',
-- HNSIMIS 为模式名
100,
FALSE,
'FOR ALL COLUMNS SIZE AUTO');
更新统计信息的目的在于大批量迁移数据后,可能会导致数据库优化器根据
错误的统计信息得到错误的查询计划,严重影响查询性能。
数据备份
再对数据更新完统计信息后,在数据量不大,磁盘空间足够的情况下应进行
一次数据备份工作。数据备份有两种方式:正常停止数据库后,拷贝备份 data
文件夹;或者开启归档日志后,进行物理备份。