1、一致性hash算法?
以分布式缓存为例,假设现在有3台缓存服务器(S0,S1,S2),要将一些图片尽可能平均地分配到不同的服务器上,hash算法的做法是:
(1) 以图片的名称作为key,然后对其做hash运算。
(2) 将hash值对服务器数量进行求余,得到服务器编号,最后存入即可。
举个栗子:
csdn.jpg 需要存入, 我们就得到hash(csdn.jpg) = 5 -------> 5%3 = 2 得到数据存入S2
思考:
上面的算法好像可以把图片均衡地分配到不同的服务器,当获取数据的时候也可以根据同样的思路访问对应的服务器,避免全局扫描。但是,这个时候服务器进行了扩容,加入了S4,我们还能否正常获取数据呢?
假设还是根据同样的思路获取csdn.jpg,我们就会得到 hash(csdn.jpg)%4 = 1。显然,我们去S1是无法获取数据的,这个时候就有可能会引发缓存的血崩,大量的请求落到数据库上。
那应该怎么办呢?
一致性hash算法
一致性hash算法会建立一个有2^32个槽点(0 - 232-1)的hash环,假设现在有A、B、C三台服务器,以A为栗,会进行hash(A)%232,得到一个0 - 2^32-1之间的数,然后映射到hash环上,如图所示:
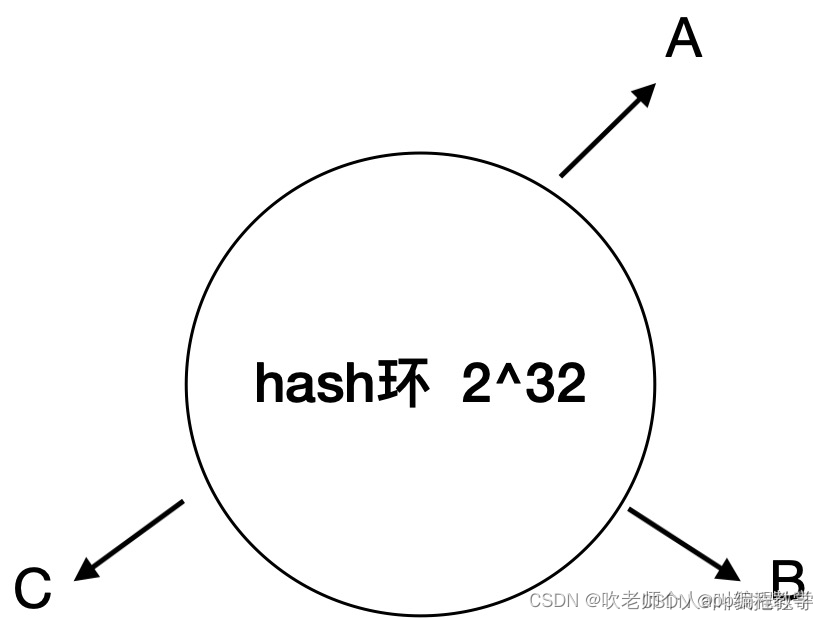
接下来,我们同样以csdn.jpg为例,我们照样算出hash(csdn.jpg)%2^32的值,然后映射到hash环上,然后以该点出发,顺时针遇到的第一个服务器,即为数据即将存储的服务器。
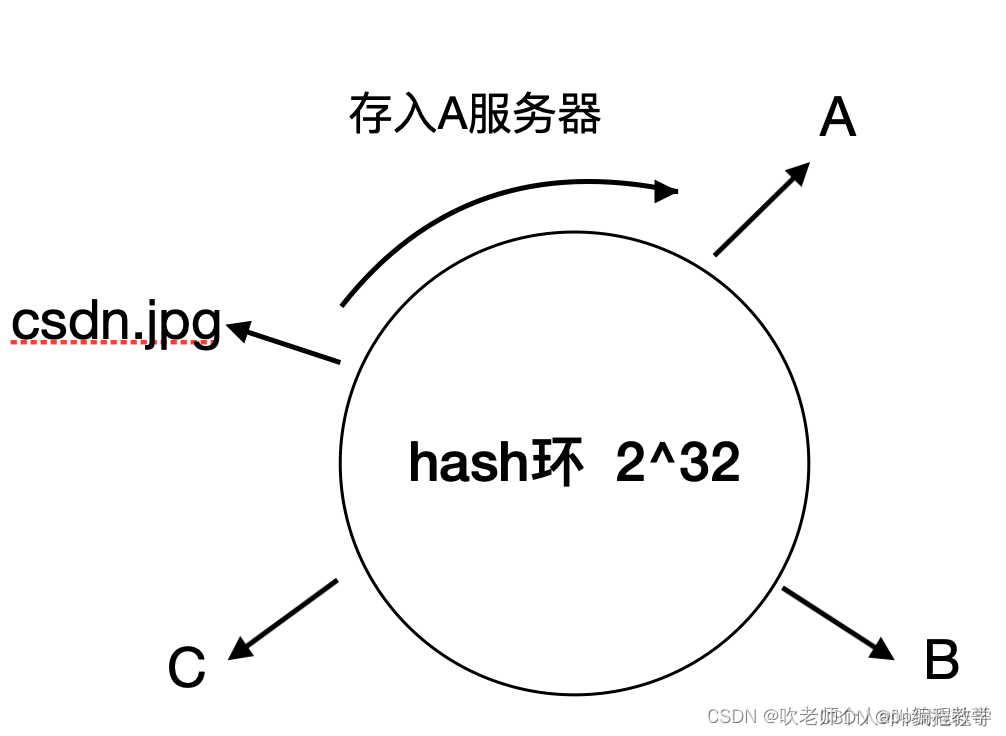
这时增加了服务器D又会发生什么事情呢?
如果这个时候在A - C之间插入了服务器D,请求获取getKey(csdn.jpg)时,顺时针获得的服务器是D,从D上获取数据理所当然会失败,因为数据存在A上缓存。这样看缓存好像还是失效了。
那么做成hash环有什么好处呢?
虽然增加了节点D后,csdn.jpg的缓存失效了,但是,分布在 A-B,B-C 以及 D-A上面的数据仍然有效,失效的只是C-D段的数据(数据存在A节点,但是顺时针获取的服务器是D)。这样就保证了缓存数据不会像hash算法那样大面积失效,同样起到减轻数据库压力的效果。
思考:
既然hash环能保证在服务器节点发生变化的情况下,数据只会部分失效,那一致性hash是不是就结束了呢?
什么是hash偏斜?
A、B、C服务节点,如果像上图那样接近于将hash环平均分配那固然理想,但是如果他们hash值十分相近,会发生什么呢?
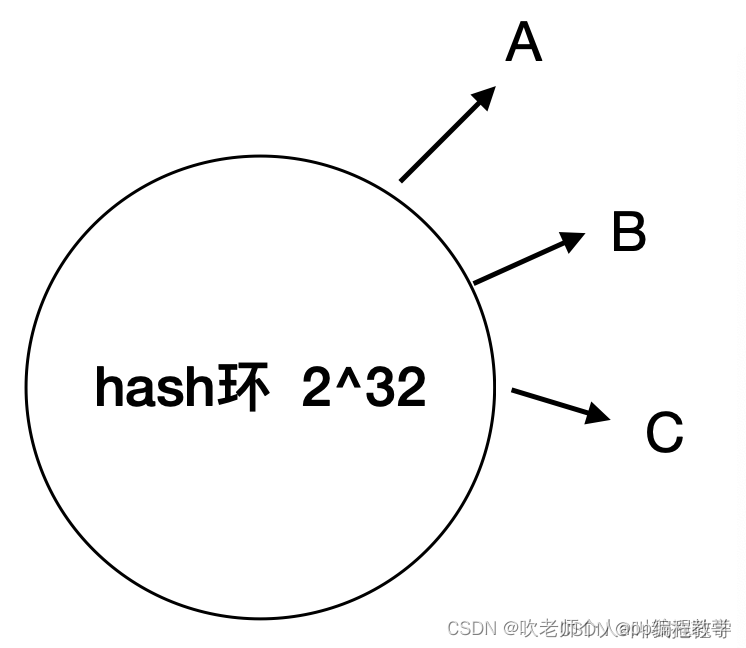
上图这种情况称之为hash偏斜,在这种情况下,大部分数据都会分部在C-A段,这个时候去A节点被删除,会有大量请求涌向B节点,给B节点带来巨大的压力,同时这部分缓存也会全部失效,有可能引发缓存雪崩。
怎么办呢?
这个时候我们可能会想到一句老话: 人多力量大。
如果我们的节点足够多,就应该可以防止服务器节点分布不均的问题了。
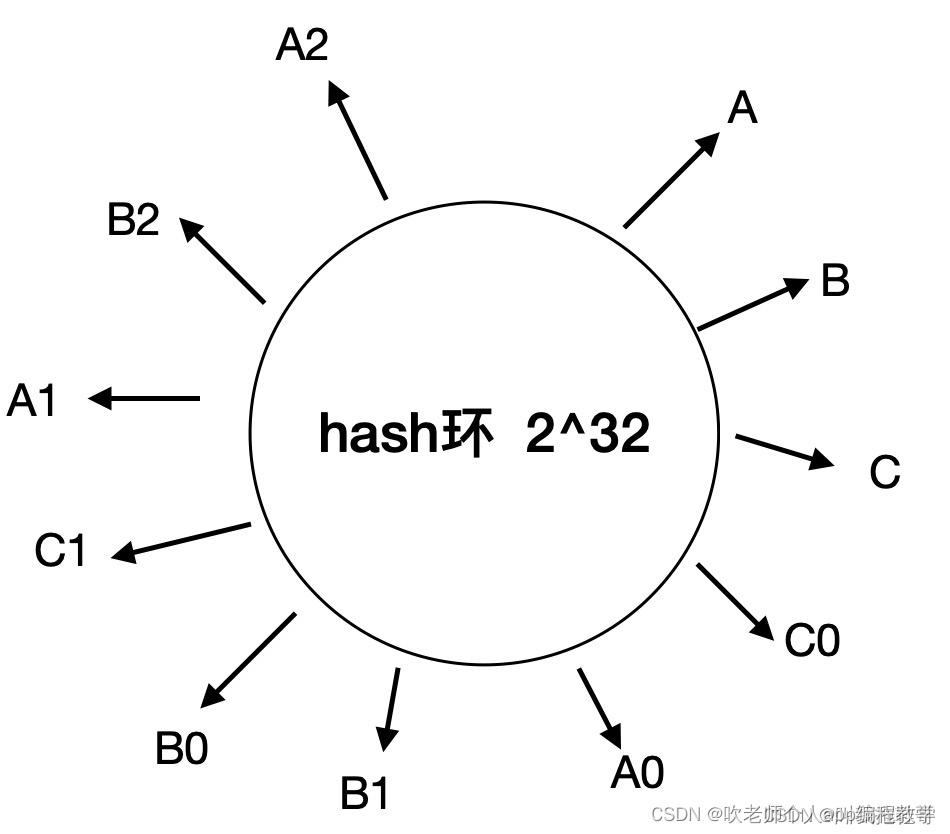
所以引入了虚拟节点的概念,以A节点为例,虚拟构造出(A0,A1,A2…AN),只要是落在这些虚拟节点上的数据,都存入A节点。读取时也相同,顺时针获取的是A0虚拟节点,就到A节点上获取数据,这样就能解决数据分布不均的问题。如图所示:
2、Redis Cluster 哈希槽
redis cluster采用数据分片的哈希槽来进行数据存储和数据的读取。redis cluster一共有2^14(16384)个槽,所有的master节点都会有一个槽区比如0~1000,槽数是可以迁移的。master节点的slave节点不分配槽,只拥有读权限。但是注意在代码中redis cluster执行读写操作的都是master节点,并不是你想 的读是从节点,写是主节点。第一次新建redis cluster时,16384个槽是被master节点均匀分布的。
和一致性哈希相比
它并不是闭合的,key的定位规则是根据CRC-16(key)%16384的值来判断属于哪个槽区,从而判断该key属于哪个节点,而一致性哈希是根据hash(key)的值来顺时针找第一个hash(ip)的节点,从而确定key存储在哪个节点。
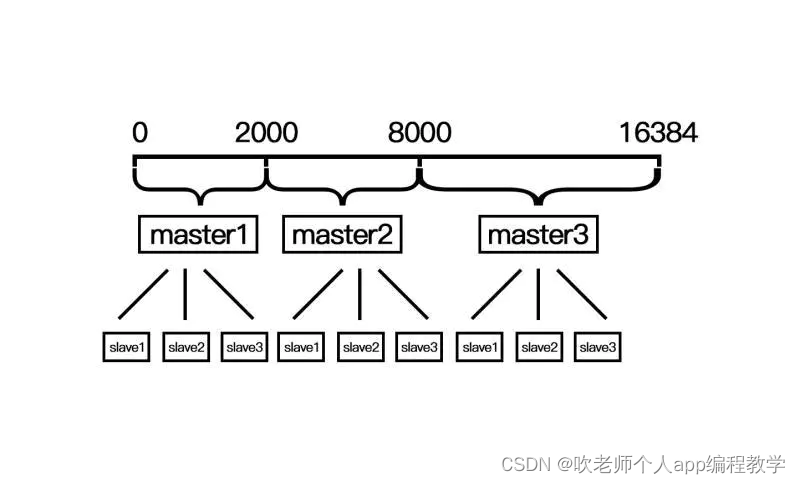
一致性哈希是创建虚拟节点来实现节点宕机后的数据转移并保证数据的安全性和集群的可用性的。
redis cluster是采用master节点有多个slave节点机制来保证数据的完整性的,master节点写入数据,slave节点同步数据。当master节点挂机后,slave节点会通过选举机制选举出一个节点变成master节点,实现高可用。但是这里有一点需要考虑,如果master节点存在热点缓存,某一个时刻某个key的访问急剧增高,这时该mater节点可能操劳过度而死,随后从节点选举为主节点后,同样宕机,一次类推,造成缓存雪崩
扩容和缩容
可以看到一致性哈希算法在新增和删除节点后,数据会按照顺时针来重新分布节点。而redis cluster的新增和删除节点都需要手动来分配槽区。
新建master节点
使用redis-trib.rb工具来创建master节点
./redis-trib.rb add-node 172.60.0.7:6379 172.60.0.5:6379
注释:
192.168.10.219:6378是新增的节点
192.168.10.219:6379集群任一个旧节点
注意:新建的master节点是没有槽区的,需要给master节点分配槽,不然缓存无法命中。分配槽的方法自行百度。
删除master节点
1).如果主节点有从节点,需要将从节点转移到别的主节点上。
2).转移后 如果主节点有哈希槽,将哈希槽转移到别的master节点上,然后在删除master节点
注意:redis cluster的动态扩容和缩容并不会影响集群的使用。
3、总结
1):Hash slot(slot 空间)对比一致性哈希(环空间) 可以做到数据分配更均匀
有 N 个节点,每个节点是准确的承担 1/N 的容量
一致性哈希,它使用的是hash函数返回的值是随机的。
2):Hash slot 更便捷的新增/删除节点
假设已有R1、R2、R3 节点
若新增 R4 节点,只需要从 R1、R2、R3 挪一部分 slot 到 R4 上
若删除 R1 节点,只需将 R1 中 slot 移到 R2 和 R3 节点上, 节点之间的槽移动不会停止服务,集群是一直可用状态。
当一致性哈希增删节点时,会导致部分数据无法命中,严重的甚至会导致缓存雪崩。