一、啥是HyperLogLog
一、初始HyperLogLog
Redis中的HyperLogLog是一种基于基数估算的算法,所谓基数估算就是在一批数据中不重复的元素个数有多少个。
基数计数(cardinality counting),则是指计算一个集合的基数,意即count-discint。 基数计算的场景很广泛,例如计算网站的访问uv,计算网络流量网络包请求header中的源地址的distinct数来作为网络攻击的重要指标。想要实现基数计数最直接想到的方式就是通过字典/HashSet,每条数据流入后直接保存相应的key,最后统一次集合的size就得到集合的基数。但是,这种方法的空间复杂度很高,在面对大数据的场景下做这样的统计代价很高。在近几十年有学者提出了很多基数估算的算法,在容许一定的误差的情况下,基于统计概率进行估算,本文的HyperLogLog就是一种基于基数估算的算法实现了不保存数据却可以实现去重计数。
二、HyperLogLog能干啥
- 统计注册ip数
- 统计每日访问 IP 数
- 统计页面实时 UV 数
- 统计在线用户数
- 统计用户每天搜索不同词条的个数
三、Redis中HyperLogLog
千呼万唤始出来,描述了半天介绍下Redis中HyperLogLog的使用,HyperLogLog目前有三个方法PFADD(添加元素),PFCOUNT(返回指定基数估算值),PFMERGE(将多个HyperLogLog合并为一个HyperLogLog)。从字面意思就不难理解每个方法命令的含义(歪果仁的命名还是很见名知意的)。
Tips:如果想使用=Redis的HyperLogLog,redis的version>=2.8.9
1、PFADD
redis> PFADD hll1 foo bar zap a
(integer) 12、PFCOUNT
redis> PFCOUNT hll1
(integer) 43、PFMERGE
redis> PFADD hll2 a b c foo
(integer) 1
redis> PFMERGE hll3 hll1 hll2
"OK"
redis> PFCOUNT hll3
(integer) 6四、HyperLogLog原理
上面简单介绍了HyperLogLog的使用场景以及命令下面来介绍下HyperLogLog原理。
HyperLogLog 算法的基本思想来自伯努利过程。伯努利过程就是一个抛硬币实验的过程。抛一枚正常硬币,落地可能是正面,也可能是反面,二者的概率都是 1/2 。伯努利过程就是一直抛硬币,直到落地时出现正面位置,并记录下抛掷次数k。比如说,抛一次硬币就出现正面了,此时 k 为 1; 第一次抛硬币是反面,则继续抛,直到第三次才出现正面,此时 k 为 3。
那么如何通过伯努利过程来估算抛了多少次硬币呢?还是假设 1 代表抛出正面,0 代表反面。连续出现两次 0 的序列应该为“001”,那么它出现的概率应该是三个二分之一相乘,即八分之一。那么可以估计大概抛了 8 次硬币。
HyperLogLog 原理思路是通过给定 n 个的元素集合,记录集合中数字的比特串第一个1出现位置的最大值k,也可以理解为统计二进制低位连续为零(前导零)的最大个数。通过k值可以估算集合中不重复元素的数量m,m近似等于 2^k。但这这样计算仅仅是粗略的估算还是不太准确,Redis中的HyperLogLog是基于分桶优化。
分桶就是分多少轮。抽象到计算机存储中去,就是存储的是一个以单位是比特(bit),长度为 L 的大数组 S ,将 S 平均分为 m 组,注意这个 m 组,就是对应多少轮,然后每组所占有的比特个数是平均的,设为 P。容易得出下面的关系:
- L = S.length
- L = m * p
- 以 K 为单位,S 占用的内存 = L / 8 / 1024
Redis中的HyperLogLog设置为:m=16834,p=6,L=16834 * 6。占用内存为=16834 * 6 / 8 / 1024 = 12K
形象化为:
第0组 第1组 .... 第16833组
[000 000] [000 000] [000 000] [000 000] .... [000 000]回到现实中来看看是如何分配桶的
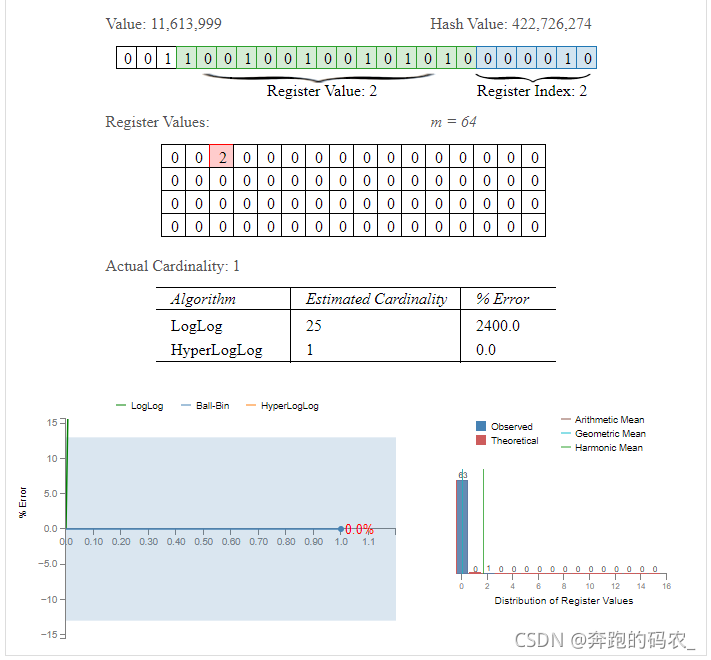
- 插入值为11613999
- 计算其hash值为422726274
- 假设以后6位计算其桶的下标,二进制转换为2,也就是说桶M的位置为2
- 剩余的比特串中从低位到高位第一次出现1的位置为2即将2放入到桶中。
- 在设置前,要设置进桶的值是否大于桶中的旧值,如果大于才进行设置,否则不进行设置。
- 最后由所有桶中的得到基数估算值
最终将每个桶的值代入到下面的DV公式中计算出最终基数估算值
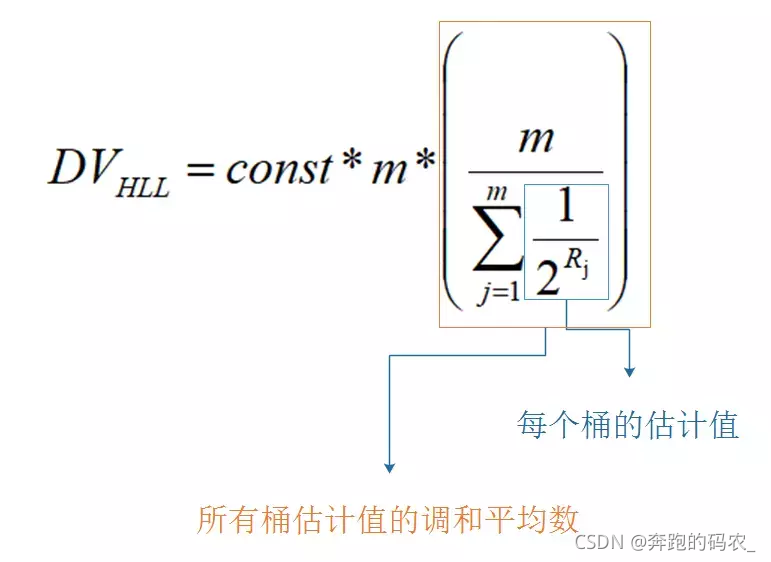
以上动态生成的工具在此处感兴趣的可以访问观看Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure – AK Tech Blog
五、结尾
Redis中HyperLogLog就写到这里了,本文只是通过HyperLogLog列举了相关的对应知识点,具体详细的知识点如果大家感兴趣也可以继续深造。
参考文章
HyperLogLogJAVA算法实现工程