目录
什么是希尔排序?
在写希尔排序的代码之前,我们先对希尔排序的排序原理以及定义进行梳理:
希尔排序(Shell's sort)又称缩小增量排序,它是一种属插入排序类的方法,但是在时间效率上较前述纪总排序方法有较大的改进。希尔排序的基本思想是:先将整个待排记录序列分割成若干个字序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
希尔排序相当于是对插入排序的优化,在我的上一篇文章C语言实现插入排序中讲到过,插入排序是在序列中已经有一部分序列是有序的所进行的排序,在插入排序中越有序,效率越高。
希尔排序的使用场景:
希尔排序适用于中规模数据量的排序。
通过排序之间的比较引入希尔排序:
例如在这里我们给出一个序列:
int ar[5] = {1,2,3,4,0};如果这时我们利用冒泡排序的话,一共所需要执行的趟数是四趟,直到将元素0放在最前面,每趟的执行顺序是:
{1,2,3,0,4};
{1,2,0,3,4};
{1,0,2,3,4};
{0,1,2,3,4};但是如果我们使用插入排序的话,效率就会大大提高,只需要一次即可将元素0放在最前面。
我们先对数组进行扫描,直到下标扫描至0号元素,不满足后大于前的规则,这时将0赋值给temp,现在和前面的已经排序好的序列进行比较,0比他们任何一个都要小,所以把元素1,2,3统一向后迁移一位,0放在最前面,
{0,1,2,3,4};我们回到希尔排序,希尔排序相当于是对插入排序的优化,尽管插入排序相比较冒泡和选择排序具有明显的优势,但是当序列中存在大量的元素都需要排序的时候,这时每次都与相邻的元素进行比较就显得有些复杂了,而希尔排序正是为了解决这种复杂而被设计出来的。
演示希尔排序的过程:
如图我给出一个数组:
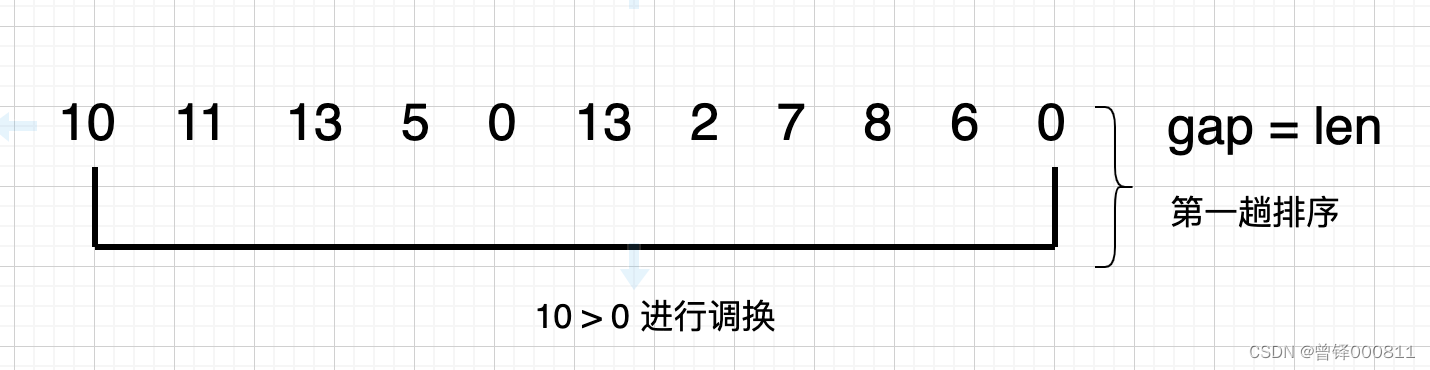
{10,11,13,5,0,13,2,7,8,6,0};第一趟排序:
接下来我们通过在画板上演示希尔排序的过程:
第二趟排序:
定义排序增量为整个序列的长度,直接进行比较,我们发现10 > 0所以对两个元素的位置进行调换,并在下一次排序中将排序增量缩小为原来的一半:
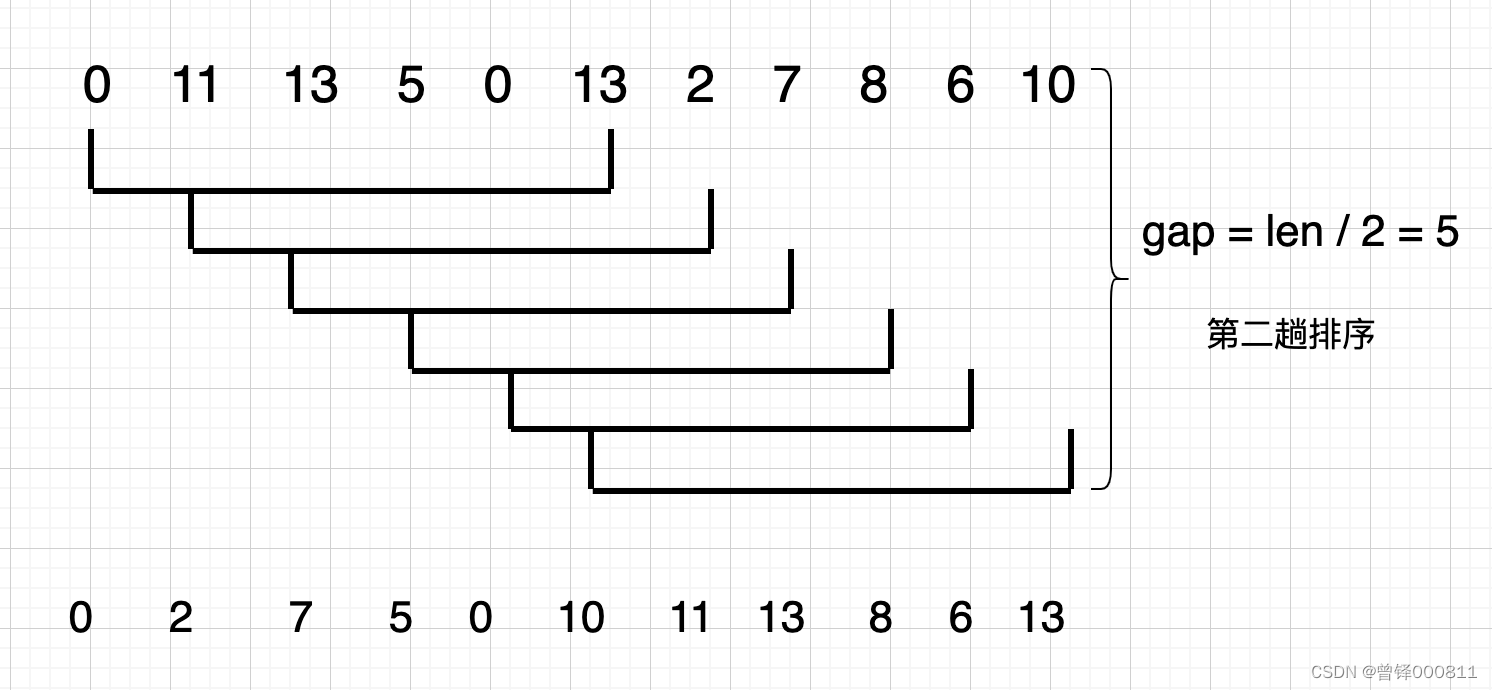
因为我是以整型值的方式定义gap值的,元素的个数为11,11 / 2为5.5,这里直接取gap的值为5,我们发现11 > 2 , 13 > 7 , 13 > 10,所以对这六个元素进行位置调换,图中下方是经过第二趟排序后的元素顺序:0 2 7 5 0 10 11 13 8 6 13.
第三趟排序:
此时gap的值变为第二次的一半:5 / 2 = 2.5,这里取gap的值为2:
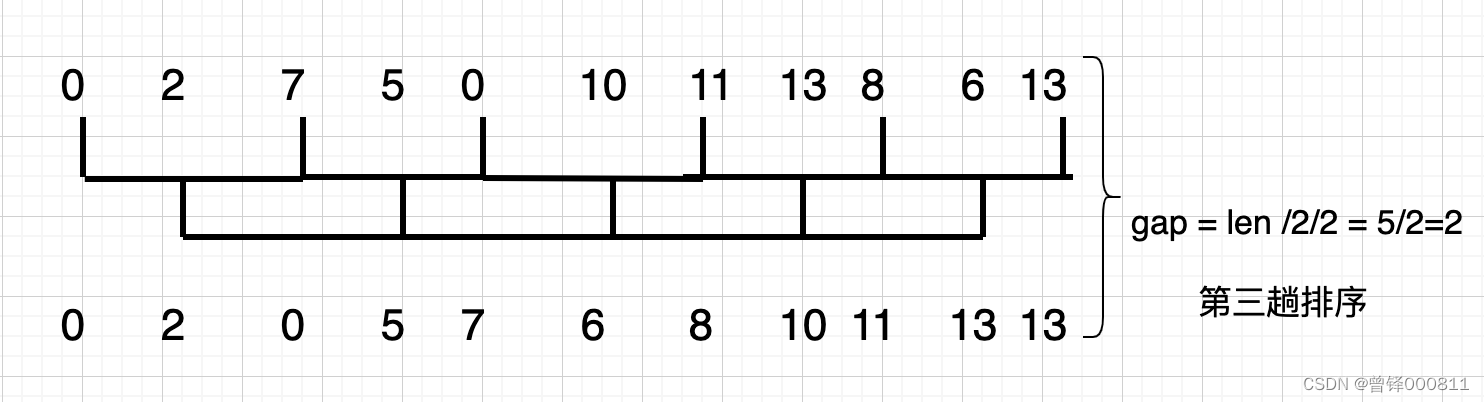
我们发现:7 > 0 , 13 > 11 > 8,对这六个元素进行位置调换,图中下方是经过第三趟排序后的元素:0 2 0 5 7 6 8 10 11 13 13
第四趟排序:
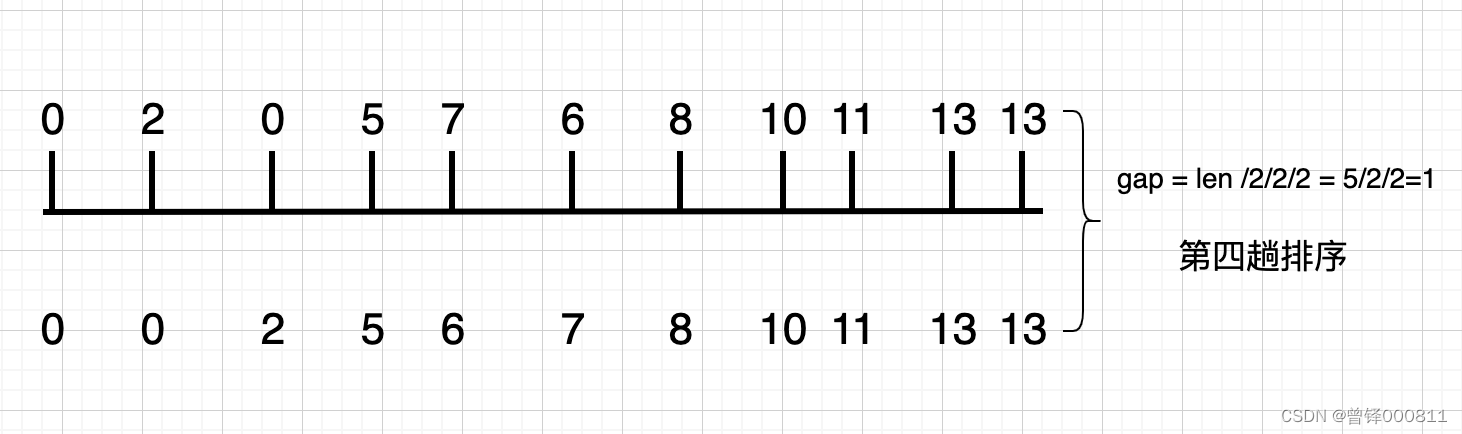
此时gap的值变为一,相当于直接插入排序,第四次排序的结果也就是最终的排序结果,我们发现:2 > 0 , 7 > 6 , 我们对这四个元素进行位置调换,排序后的结果为:0 0 2 5 6 7 8 10 11 13 13
程序验证:
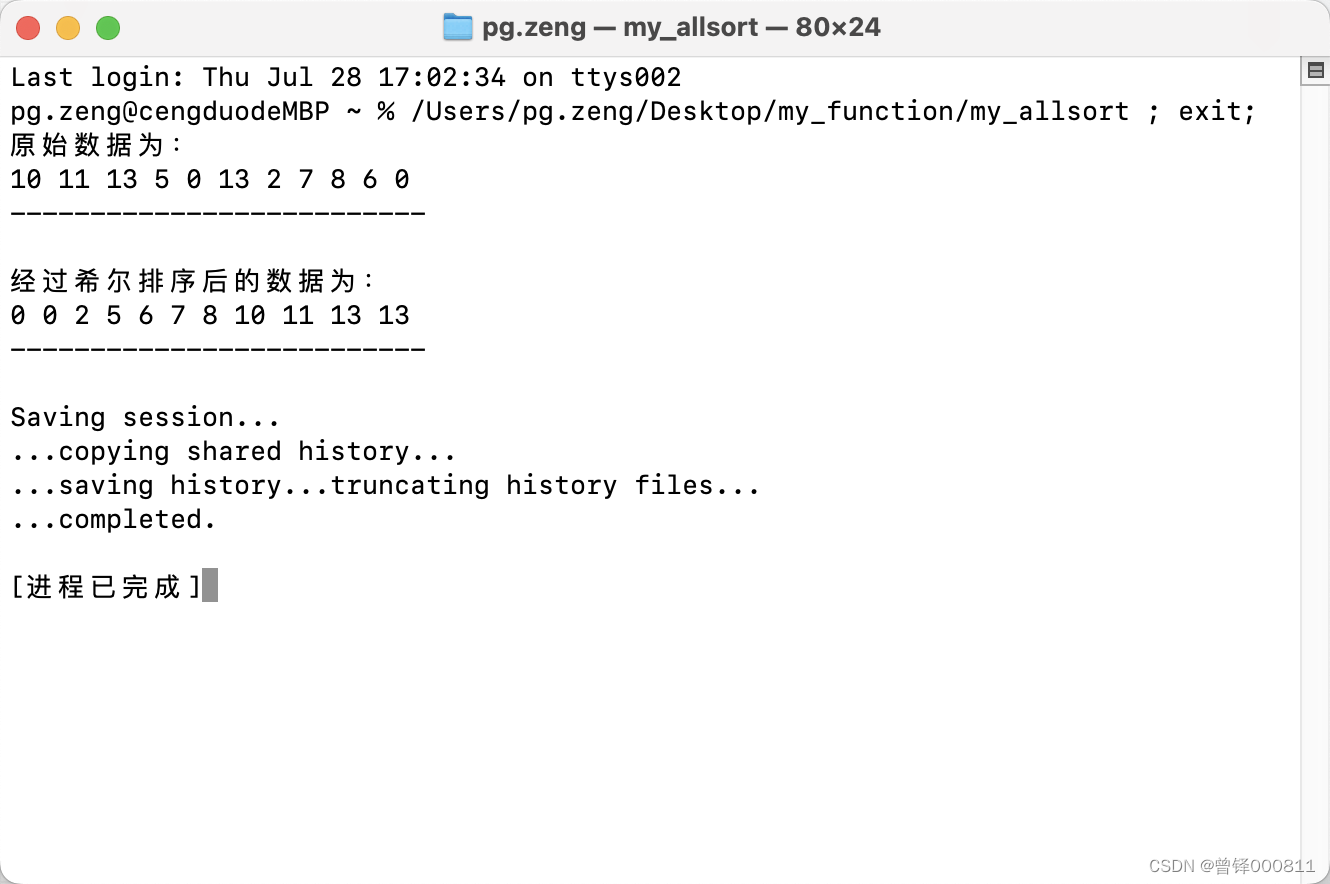
如图,成功的将这11个数进行了排序。
程序代码:
#include<stdio.h>
#include<iostream>
#include<stdlib.h>
#include<assert.h>
#include<time.h>
#define MAXSIZE 11
void initar(int *ar,int len)
{
assert(ar != nullptr);
for(int i = 0;i < len;i++){
ar[i] = rand() % 20;
}
}
void showar(int *ar,int len)
{
assert(ar != nullptr);
for(int i = 0;i < len;i++){
printf("%d ",ar[i]);
}
printf("\n--------------------------\n");
}
void Shell_sort(int *ar, int len) {
assert(ar != nullptr && len >= 0);
int i = 0,j = 0;
int temp = 0;//定义中间值用于存储数据
int gap = 0;//定义排序增量
gap = len;//将排序增量的初始值直接设置为数组的长度
while(gap > 1){
gap /= 2;
for(i = gap;i < len;i += gap){
if(ar[i] < ar[i - gap]){
temp = ar[i];
for(j = i - gap;j >= 0 && ar[j] > temp;j -= gap){
ar[j + gap] = ar[j];
}
ar[j + gap] = temp;
}
}
}
}
int main()
{
srand((unsigned int)time(NULL));
int ar[MAXSIZE];
initar(ar,MAXSIZE);
printf("原始数据为:\n");
showar(ar,MAXSIZE);
printf("\n经过希尔排序后的数据为:\n");
Shell_sort(ar,MAXSIZE);
showar(ar,MAXSIZE);
}使用计算机随机生成的12个小于20的数,我们来使用希尔排序进行排序,我在函数的第三层for循环末尾添加了展示数组语句,每排序一趟就会对整个数组进行输出,我们来看一下结果:
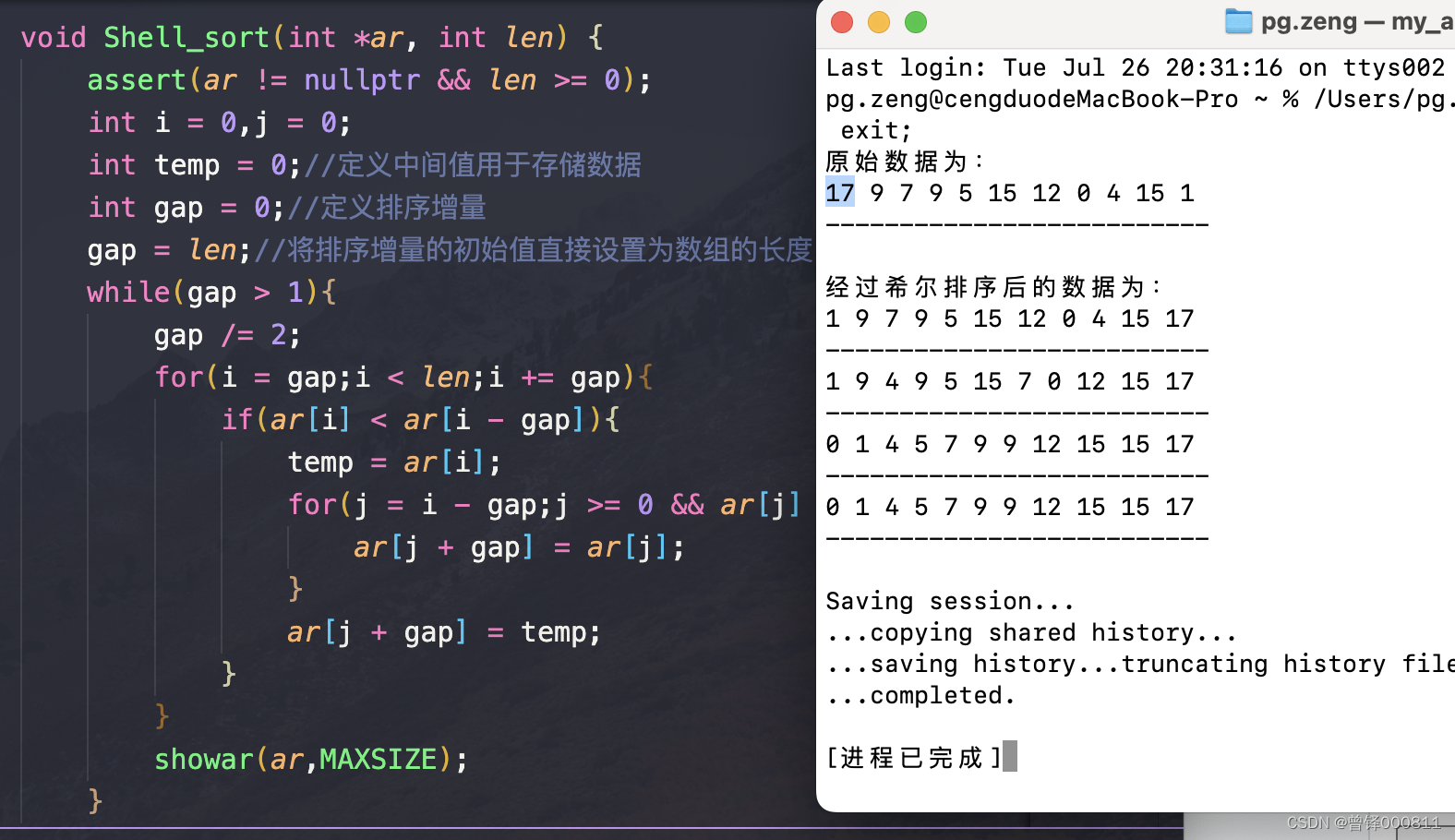
如图,我使用希尔排序一共进行了四趟排序(也就是gap的值发生了四次变化),最后对系统随机生成的数据完成了升序排序。
现实生活中的希尔排序:
我们都玩过扑克牌,即使没玩过也看过别人玩过,每一副扑克牌买回来的时候都是新的,都是按照不同花色从小到大排序好的,我们可以把这个排序过程看作是一个简单的希尔排序。
开始把54张扑克牌从小到大的排序前,我们是不是应该先按照不同的花色,把扑克牌分成四组,分别对应:梅花、方片、黑桃、红心,这时就可以理解为我们目前阶段的排序增量为4,接下来我们再对不同花色中的13个数进行从小到大的排序,这是的排序增量就是1,排序方法也就是直接插入排序。
所以对扑克牌的排序就可以看作是一个简单的希尔排序,排序增量从4变为1,经过两趟,最终完成排序。
对希尔排序的总结:
希尔排序的时间复杂度是随着排序增量(gap)的变化而变化的,时间复杂度在O(nlogn)~O()之间变换,空间复杂度始终为O(1),希尔排序是一个不稳定的算法。
希尔排序的执行顺序是:排序增量递减,增量变为1时进行直接插入排序。
空间复杂度为O(1):因为只需要保存临时变量。
希尔排序是不稳定的算法:由于排序增量将序列分成不同的序列,但是这样可能会导致相同的元素的相对位置发生改变,例如奇数序列{4,5,3,2,1},如果此时的排序增量(gap)值为2的话,那么最后一个元素1的相对位置就会发生改变。