作为研究从业者,对于前沿热点和研究热门方向的关注是必须的。深度学习作为人工智能领域机器学习最热门的方法,最近几年的发展可谓日新月异。
什么是深度学习?深度学习当前最主要的技术有哪些?下一个深度学习的风口在哪里?
深度学习的研究热门主要集中在对比学习和多模态学习方面。
在讲对比学习之前,先讲一讲Self-Supervised(自监督)和无监督(Unsupervised)。
什么是自监督学习?
自监督学习(SSL)是一种特殊类型的表示学习(representation learning),能够从无标签数据集中学习良好的数据表示。它的目的是从无监督数据集构建有监督的学习任务。
为什么要自监督学习?
1.数据标记是昂贵的,因此高质量的标记数据集是有限的。
2.学习良好的表达方式可以更容易地将有用的信息传递给各种下游任务。
eg.下游任务只有几个例子。
e g.新任务的零射击转移。
自监督学习任务也称为 pretext tasks(代理任务)。

还有一种形式叫做无监督的学习,无监督学习是从无标记的训练数据中推断结论。最典型的无监督学习就是聚类分析,它可以在探索性数据分析阶段用于发现隐藏的模式或者对数据进行分组。无监督学习主要是从实用性上去考虑。一些算法不一定是需要对数据进行标签。
而对比学习(Contrastive Learning)的目标是:将属于同一类的点簇在嵌入空间中拉在一起,同时将来自不同类的样本簇分开。
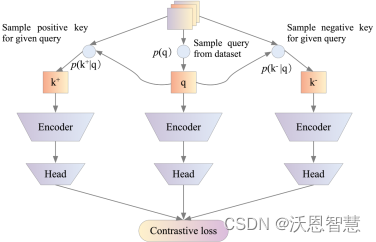
对比学习的主要技术:数据增强(Data Augmentation)
数据增强设置对于学习良好的嵌入至关重要。它在不修改语义的情况下将非本质变化引入到示例中,从而促使模型学习表示中的本质部分。
数据增强主要分为以下几种形式——
一、图像增强
基本图像增强(随机作物、颜色失真、高斯模糊、颜色抖动、随机翻转/旋转等)、扩充策略和图像混合。

二、文本扩充
几种主要技术——
AutoAugment(Cubuk等人,2018):灵感来自NAS
RandAugment(Cubuk等人2019):减少了AutoAugment中的NAS搜索空间。
PBA(基于种群的扩增;Ho等人2019):进化算法
UDA(无监督数据增强;Xie等人2019):最小化未标记示例的预测分布与其未标记增强版本之间的KL差异。
三、图像混合
如:混合(Zhang等人2018):两幅图像的加权像素组合。
Cutmix(Yun等人2019):将一幅图像的局部区域混合到另一幅图像中。
MoCHi(“Mixing of Contrastive Hard Negatives”;Kalantidis等人,2020):难负样本的混合。
四、词汇编辑
主要技术:
EDA(Easy Data Augmentation;Wei&Zou 2019):同义词替换,随机插入/交换/删除。
上下文增强(Kobayashi 2018):BERT预测的单词替换。
五、反向翻译(Sennrich等人,2015)
反向翻译通过首先将一个句子翻译成另一种语言,然后再将其翻译回原始语言,来扩充一个句子。CERT(Fang等人,2020)通过反向翻译生成增强句子。
六、Dropout and Cutoff

再来讲讲在对比学习的各个阶段我们可以尝试学习和研究的几种技术。
首先,里程碑InstDisc

一只豹子可以被识别为Leopard,jaguar,cheetah,snow leopard(雪豹)的概率很高;而被识别为lifeboat; shopping cart;bookcase的比率就很低。作者提到:Supervised learning results that motivate our unsupervised approach.监督学习的方法促成了无监督学习的发展,并且我们的无监督学习的方法将多种类的监督学习变成了基于特征代表的独立个体。

将256*256的图片经过卷积神经网络变成2048维的特征,再经过low dim变成128维的特征,做L2正则化防止过拟合,再使用Softmax激活函数进行特征分类可以得到128万的特征,将所有图片的特征存放在数据结构的字典结构中,并不断更新字典里面的特征,最终就达到了将所有图片进行对比分类的目的。
使用卷积神经网络把所有的图片都编码成一个特征;希望这些特征在最后的特征空间中都尽量的分散;对于个体判别任务来讲每个图片都是自己的类,故每个图片都应该和其他图片分开;使用对比学习训练卷积神经网络:需要正例样本和负例样本;其中正例样本:是原本的图片+原本图片经过数据增强:对于负例样本:其他图片;
第二、InvaSpread

相似的图片,它们之间的特征应该保持不变。不同的图片之间的特征应该尽量散开。
InvaSpread提出了一种新的基于实例特征的softmax嵌入方法来学习数据扩充不变量和实例展开特征。它实现了比所有竞争方法更快的学习速度和更高的准确性。证明了数据扩充不变量和实例扩展属性对于实例智能无监督嵌入学习都是重要的。它们有助于捕获样本之间明显的视觉相似性,并很好地概括了看不见的测试类别。与其他无监督学习方法相比,该方法在综合图像分类和嵌入学习实验中取得了最新的性能。
InvaSpread的Method:

第三、CPC

将原有的信息映射到压缩空间(维度更低)信息也就更加密集了。之后使用压缩空间的信息再产生一个预测空间特征,之后我们使用预测空间的当前特征预测未来的压缩空间的信息。如果可以成功预测未来空间的压缩空间信息(全序列上使用的压缩空间提取信息的获得方式是一样的)。那么也就说明我们当前提取出的预测信息是正确的,也就说明了当前预测是准确的。
第四种、CMC

CMC提出的主要的创新点在于“核心视图(Core View)”和“全图(Full Graph)”两种多视图的对比方法,一个是低成本,一个是高信息量,各有各的优点,可以根据实际应用的场景做不同的选择,比如多个视角基本是平等的关系(比如一个场景的不同拍摄角度)选择全图模式,统一图像的不同通道这种有侧重的可以选择核心视图模式。
五、Moco v1
动态内存模块——设计一个模块到内存功能,将每个批次的数据与此模块进行比较。

六、SimCLR v1

在无监督的情况下学习有效的视觉表征是一个长期存在的问题。大多数主流方法分为两类:生成性(generativ)和区别性(discriminative)。生成方法学习在输入空间中生成或以其他方式建模像素。然而,像素级的生成在计算上是昂贵的,并且对于表示学习可能不是必需的。区别性方法使用与监督学习类似的目标函数学习表示,但训练网络执行代理任务,其中输入和标签都来自未标记的数据集。许多这样的方法依赖于 启发式( heuristics)来设计代理任务,这可能会限制所学表示的通用性。 最近,基于潜在空间对比学习的鉴别方法(contrastive learning in the latent space)显示出巨大的潜力,取得了一流的结果 。
为了理解是什么促成了良好的对比表征学习,我们系统地研究了我们框架的主要组成部分,并表明:
(1) 多个数据扩充操作的组合对于定义产生有效表示的对比预测任务至关重要。此外,与监督学习相比,无监督对比学习从更强的数据扩充中获益。
(2)在表征和对比损失之间引入可学习的非线性变换,可以显著提高学习表征的质量。
(3)具有对比交叉熵损失的表征学习得益于归一化嵌入和适当调整的参数。
(4)与有监督的对比学习相比,对比学习受益于更大的批量和更长的培训时间。与监督学习一样,对比学习也得益于更深更广的网络。
七、MoCoV2

八、SimCLRv2
在充分利用大量未标记数据的同时,从少数标记示例中学习的一个范例是无监督的预训练,然后是有监督的微调。虽然这种范式以任务无关的方式使用未标记的数据,但与计算机视觉中常用的半监督学习方法相比,我们发现它对于ImageNet上的半监督学习非常有效。我们方法的一个关键要素是在预训练和微调期间使用大型(深度和广度)网络。我们发现,标签越少,这种方法(未标记数据的任务无关使用)从更大的网络中获益越多。在微调之后,通过第二次使用未标记的样本,但以特定于任务的方式,可以进一步改进大网络并将其提取为更小的网络,而分类精度几乎没有损失。所提出的半监督学习算法可归纳为三个步骤:**使用SimCLRv2对大型ResNet模型进行无监督预训练,对几个标记的示例进行监督微调,以及使用未标记的示例进行蒸馏,以提炼和传递特定于任务的知识。**此过程仅使用1%的标签即可实现73.9%的ImageNet top-1精度(≤每类13个标记图像)使用ResNet-50,标签效率比以前的技术状态提高了10倍。对于10%的标签,用我们的方法训练的ResNet-50达到77.5%的top-1准确率,优于所有标签的标准监督训练。

九、SwAV
十、BYOL
十一、Siamese
十二、Moco v3
十三、DINO
梳理完了对比学习的主要工作。
我们再来看Supervised Contrastive Learning。

直接把self-supervised contrastive loss放出来,大家可能看得更直观,简单一点来说,对于一个data sample: x,通过data augmentation(像moco v1用的random crop就是一种augmentation)得到两个x_i(anchor),x_j(positive sample)。我们要拉近x_i和x_j的representation的距离,同时拉远x_i和其他数据(negative sample)的representation的距离。

自监督对比学习未来方向
①大批量生产→ 提高了传输性能。
- ②高质量大数据语料库→ 更好的性能(从合成或Web数据中学习/测量数据集质量和过滤/主动学习)
- ③有效的负样本选择
- ④合并多个借口任务(如何组合/最佳策略)
- ⑤数据增强技巧具有关键影响,但仍然非常特殊(取决于模态/理论基础)
- ⑥提高训练效率(自监督学习方法正在推动深度学习技术竞争发展/对经济和环境成本的直接影响)
- ⑦嵌入空间中存在社会偏见(消除单词嵌入的早期工作/数据集中的偏差)

最后,我们再来谈谈Multimodal(多模态)
多模态中有两大主要分支:
联合表征——将多个模态的信息一起映射到统一的多模态向量空间。
协调表征——将多模态中的每个模态映射到其自己的表示空间,但映射的向量满足某些相关约束(例如线性相关)

多模态变换也可以称为映射,它主要将一种模态的信息变换或映射到另一种模态信息。
主要应用如,机器翻译、唇读、语音翻译、图像捕获、视频字幕、语音合成等。

在这部分有几个关键概念我们需要掌握:
一、多模态表征学习(Multimodal Representation Learning)
·联合表征:将多个模态的信息一起映射到统一的多模态向量空间
·协调表征:将多模态中的每个模态映射到其自己的表示空间,但映射的向量满足某些相关约束(例如线性相关)

二、Translation
多模态变换也可以称为映射,它主要将一种模态的信息变换或映射到另一种模态信息。
应用——机器翻译/唇读/语音翻译/图像捕获/视频字幕/语音合成/图像捕获
三、对齐
从同一样本中找到两个甚至多个模态的子部件之间的关系和联系。
·研究兴趣

·相关任务
给定一张图片和图片的描述,在图片中找到一个区域
描述中该区域的表示。图像
语义分割
四、多模态融合
结合多模态信息进行目标预测(分类或回归)是MMML最早的研究方向之一,也是目前应用最广泛的方向。它还有其他常见的名称。例如,多源信息融合和多传感器融合。
根据融合类型,可分为数据级融合、决策级融合和融合的组合。
当前的挑战
·Visual-Audio Recognition
·Multimodal sentiment analysis
·Mobile Identity Authentication
五、共同学习(Co-learning)
利用资源丰富模式的知识,帮助建立低资源模式的模型。根据数据表划分,可以分为:
·并行:共同培训、转移学习
p·非平行:转移学习、概念基础、零射击学习
p·混合:桥接
六、MISA
