一、说明
当我第一次开始在工业界工作时,我很快意识到的一件事是,有时你必须收集、组织和清理自己的数据。在本教程中,我们将从一个名为FundRazr的众筹网站收集数据。像许多网站一样,该网站有自己的结构、形式,并有大量可访问的有用数据,但由于它没有结构化的 API,很难从网站获取数据。因此,我们将通过网络抓取网站以获取非结构化网站数据,并放入有序形式以构建我们自己的数据集。
为了抓取网站,我们将使用Scrapy。简而言之,Scrapy 是一个框架,旨在更轻松地构建网络爬虫并减轻维护它们的痛苦。基本上,它允许您专注于使用 CSS 选择器和选择 XPath 表达式的数据提取,而不是蜘蛛应该如何工作的复杂内部。这篇博文超出了抓取文档中的出色官方教程,希望如果您需要更难地抓取一些东西,您可以自己完成。有了这个,让我们开始吧。如果您迷路了,我建议您在单独的选项卡中打开视频。
二、安装入门(先决条件)
如果您已经拥有 anaconda 和谷歌浏览器(或 Firefox),请跳到创建新的 Scrapy 项目。
1. 在你的操作系统上安装 Anaconda (Python)。您可以从官方网站下载 anaconda 并自行安装,也可以按照下面的这些 anaconda 安装教程进行操作。
Installing Anaconda2. 安装Scrapy(anaconda 附带它,但以防万一)。您还可以在终端 (mac/linux) 或命令行 (windows) 上安装。您可以输入以下内容:
conda install -c conda-forge scrapy 3.确保您拥有谷歌浏览器或火狐浏览器。在本教程中,我使用的是谷歌浏览器。如果您没有谷歌浏览器,可以使用此链接在此处安装它。
三、创建一个新的 Scrapy 项目
1.打开终端(mac/linux)或命令行(窗口)。导航到所需的文件夹(如果需要帮助,请参阅下图)并键入
scrapy startproject fundrazr 
scrapy的开始项目基金,这将创建一个包含以下内容的fundrazr目录:
四、使用谷歌浏览器(或火狐浏览器)上的检查查找良好的开始网址
在爬虫框架中,start_urls是蜘蛛将开始爬行的URL列表,当没有指定特定的URL时。我们将使用start_urls列表中的每个元素作为获取单个广告系列链接的方法。
1.下图显示,根据您选择的类别,您将获得不同的起始URL。黑色突出显示的部分是可能抓取的基金类别。
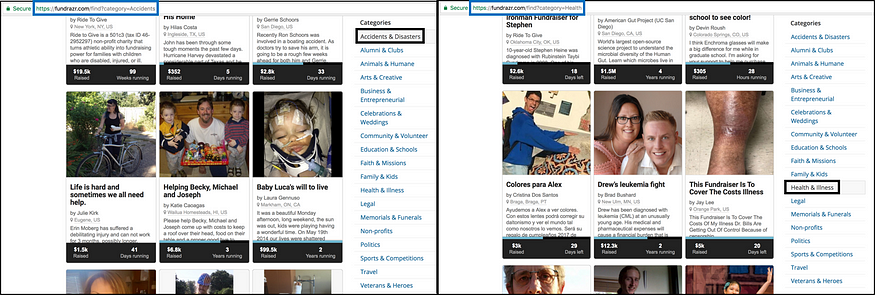
对于本教程,列表start_urls中的第一个是:
Raise money for Health, Illness & Medical Treatments - FundRazr
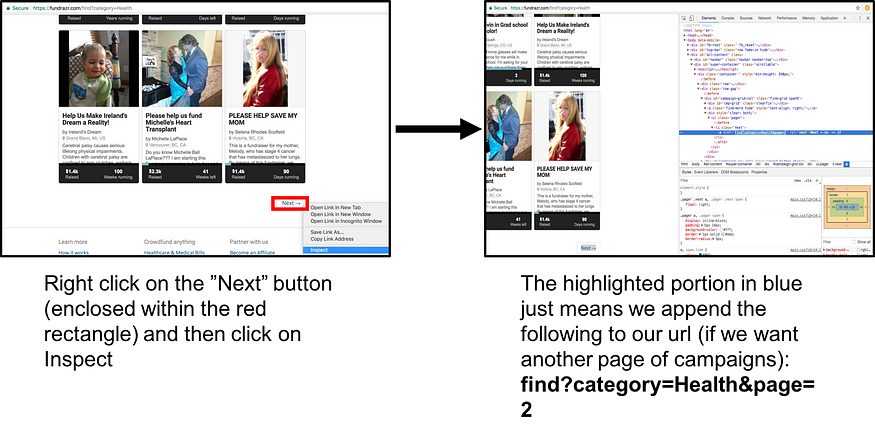
2.这部分是关于获取要放入start_urls列表中的其他元素。我们正在了解如何转到下一页,以便我们可以获取其他 url 以放入start_urls。
第二个起始网址是:Raise money for Health, Illness & Medical Treatments - FundRazr
下面的代码将在本教程后面的蜘蛛代码中使用。它所做的只是列出start_urls。变量 npages 只是我们希望从中获取广告系列链接的其他页面数量(在第一页之后)。
start_urls = ["https://fundrazr.com/find?category=Health"]
npages = 2
# This mimics getting the pages using the next button.
for i in range(2, npages + 2 ):
start_urls.append("https://fundrazr.com/find?category=Health&page="+str(i)+"")根据网站当前结构生成其他起始 URL 的代码
五、用于查找单个广告系列链接的刮擦外壳
学习如何使用Scrapy提取数据的最佳方法是使用Scrapy shell。我们将使用 XPaths,它可用于从 HTML 文档中选择元素。
我们将尝试获取xpath的第一件事是各个广告系列链接。首先,我们检查广告系列在HTML中的大致位置。
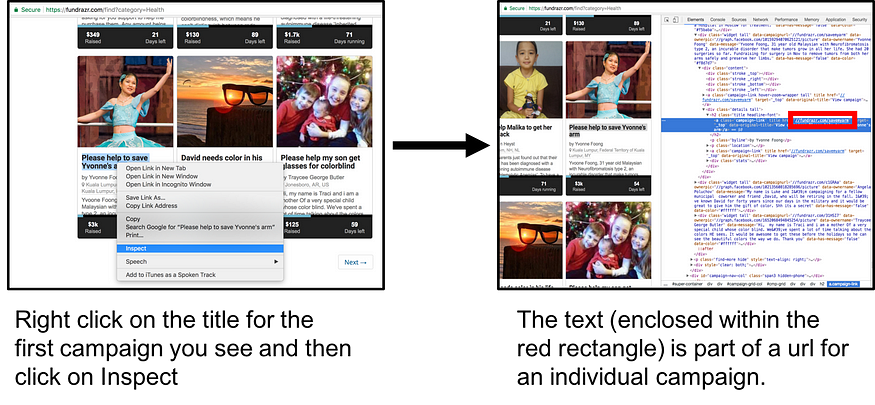
我们将使用 XPath 提取包含在下面红色矩形中的部分。

随附的部分是我们将隔离的部分网址
在终端类型 (mac/linux) 中:
scrapy shell 'https://fundrazr.com/find?category=Health'在命令行类型(窗口)中:
scrapy shell “https://fundrazr.com/find?category=Health"在 scrapy shell 中键入以下内容(为了帮助理解代码,请观看视频):
response.xpath("//h2[contains(@class, 'title headline-font')]/a[contains(@class, 'campaign-link')]//@href").extract()
随着网站随着时间的推移而更新,您很有可能会得到不同的部分网址
下面的代码用于获取给定起始网址的所有活动链接(稍后在第一个蜘蛛部分详细介绍)
for href in response.xpath("//h2[contains(@class, 'title headline-font')]/a[contains(@class, 'campaign-link')]//@href"):
# add the scheme, eg http://
url = "https:" + href.extract() 通过键入 exit() 退出 Scrapy Shell。

退出 Scrapy Shell
六、检查单个广告系列
虽然我们之前应该了解各个广告系列链接的结构,但本节将介绍各个广告系列的链接。
- 接下来,我们转到单个广告系列页面(请参阅下面的链接)进行抓取(我应该注意,其中一些广告系列很难查看)
Please help to save Yvonne by Yvonne Foong
2.使用与以前相同的检查过程,我们检查页面上的标题
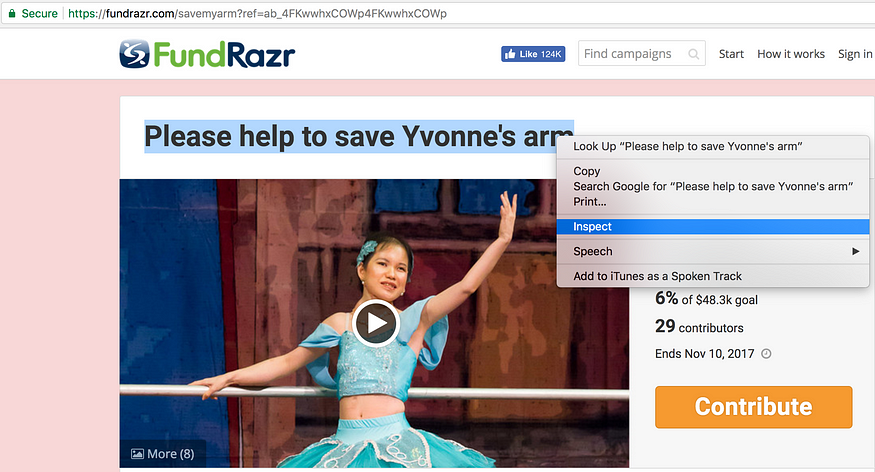
检查广告系列标题
3.现在我们将再次使用刮擦外壳,但这次是个人活动。我们这样做是因为我们想了解各个广告系列的格式(包括了解如何从网页中提取标题)。
在终端类型 (mac/linux) 中:
scrapy shell 'https://fundrazr.com/savemyarm'在命令行类型(窗口)中:
scrapy shell “https://fundrazr.com/savemyarm"获取广告系列标题的代码是
response.xpath("//div[contains(@id, 'campaign-title')]/descendant::text()").extract()[0]![]()
4.我们可以对页面的其他部分执行相同的操作。
募集金额:
response.xpath("//span[contains(@class,'stat')]/span[contains(@class, 'amount-raised')]/descendant::text()").extract()目标:
response.xpath("//div[contains(@class, 'stats-primary with-goal')]//span[contains(@class, 'stats-label hidden-phone')]/text()").extract()货币类型:
response.xpath("//div[contains(@class, 'stats-primary with-goal')]/@title").extract()活动结束日期:
response.xpath("//div[contains(@id, 'campaign-stats')]//span[contains(@class,'stats-label hidden-phone')]/span[@class='nowrap']/text()").extract()贡献者数量:
response.xpath("//div[contains(@class, 'stats-secondary with-goal')]//span[contains(@class, 'donation-count stat')]/text()").extract()故事:
response.xpath("//div[contains(<a data-cke-saved-href="http://twitter.com/id" href="http://twitter.com/id" class="af ov">@id</a>, 'full-story')]/descendant::text()").extract() 网址:
response.xpath("//meta[<a data-cke-saved-href="http://twitter.com/property" href="http://twitter.com/property" class="af ov">@property</a>='og:url']/@content").extract() 5. 通过键入退出刮擦外壳:
exit() 七、项目
抓取的主要目标是从非结构化源(通常是网页)中提取结构化数据。Scrapy Spiders可以将提取的数据作为Python字典返回。虽然方便和熟悉,但 Python 词典缺乏结构:很容易在字段名称中输入错误或返回不一致的数据,尤其是在具有许多蜘蛛的大型项目中(几乎是从伟大的刮擦官方文档中逐字复制的!
我们将要修改的文件items.py 的代码在这里。
将其保存在fundrazr/fundrazr目录下(覆盖原始 items.py 文件)。
本教程中使用的 item 类(基本上是我们在输出数据之前存储数据的方式)如下所示。
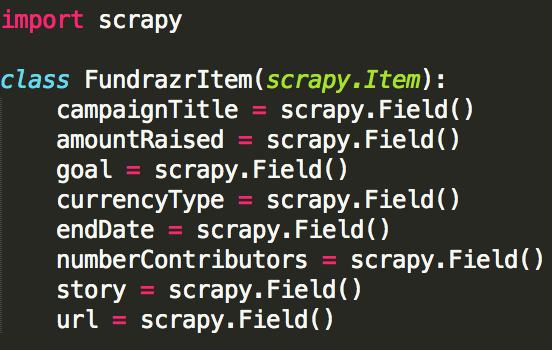
items.py 代码
八、蜘蛛
蜘蛛是您定义的类,Scrapy 使用它从网站(或一组网站)中抓取信息。我们的蜘蛛的代码如下。
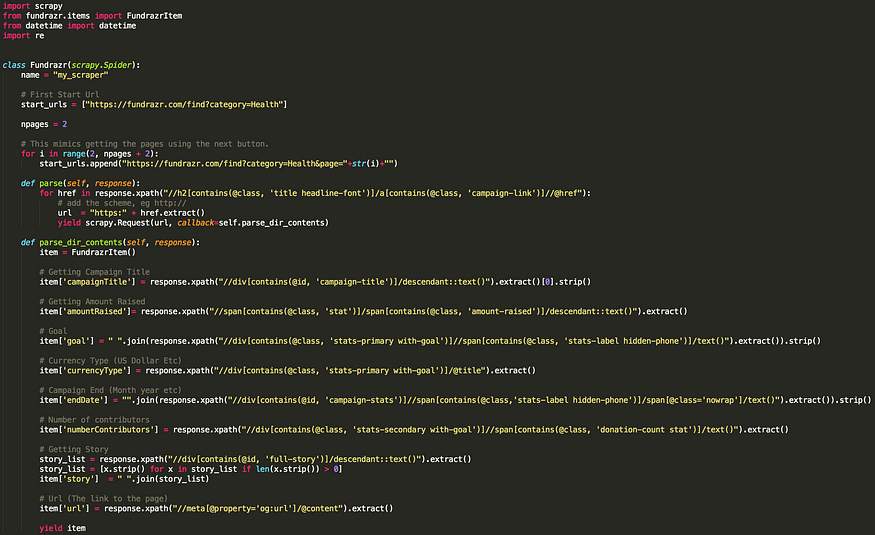
Fundrazr 刮擦代码,在此处下载代码。
将其保存在fundrazr/spiders目录下的名为fundrazr_scrape.py的文件中。
当前项目现在应具有以下内容:

我们将创建/添加的文件
九、运行蜘蛛
- 转到fundrazr/fundrazr目录并键入:
scrapy crawl my_scraper -o MonthDay_Year.csv 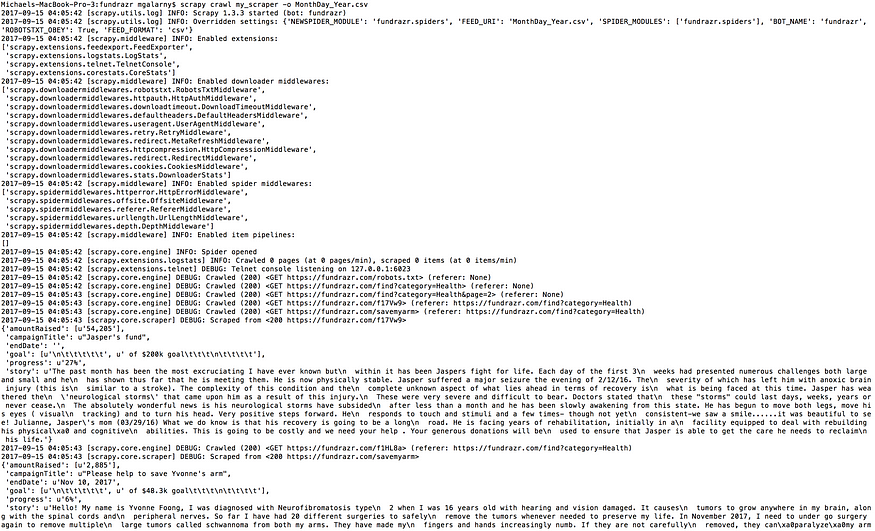
刮擦爬行my_scraper -o MonthDay_Year.csv
2. 数据应输出在基金/基金目录中。
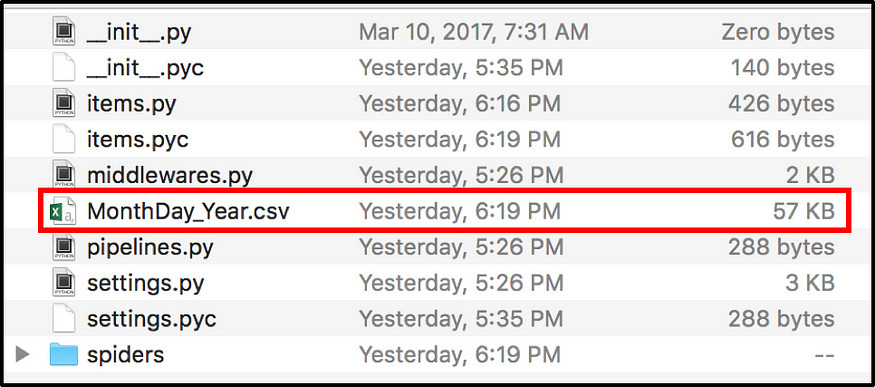
数据输出位置
十、我们的数据
- 本教程中输出的数据应大致如下图所示。抓取的各个广告系列会随着网站的不断更新而有所不同。此外,每个单独的广告系列之间可能会有空格,因为 excel 正在解释 csv 文件。
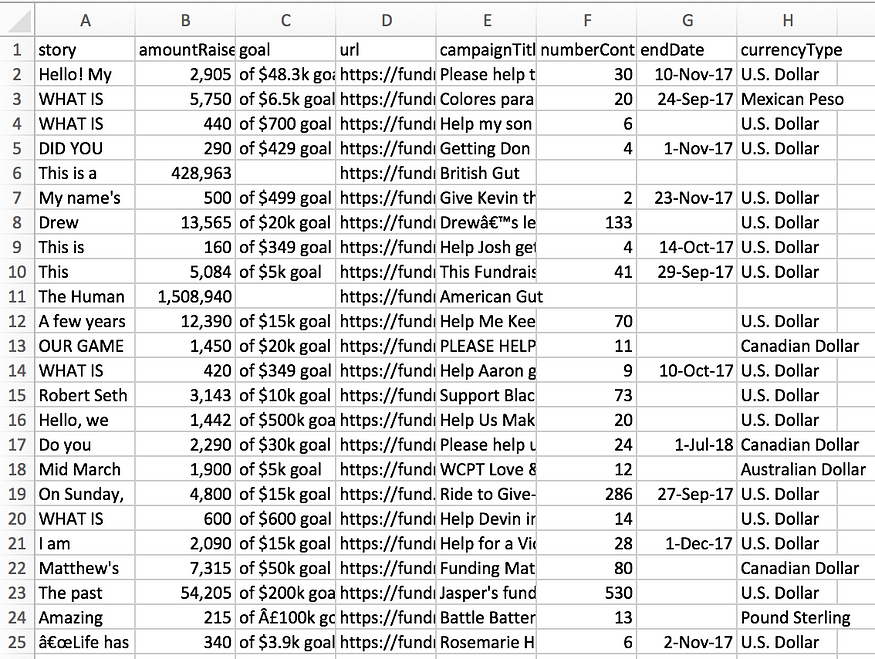
数据应大致采用此格式。
2.如果您想下载一个更大的文件(它是通过将npages = 2更改为npages = 450并添加download_delay = 2来完成的),您可以通过从我的github下载文件来下载一个更大的文件,其中包含大约6000个广告系列。该文件称为MiniMorningScrape.csv(它是一个大文件)。

大约 6000 个广告系列被抓取
十一、结语
创建数据集可能是一项繁重的工作,并且经常是学习数据科学中被忽视的部分。我们没有回顾的一件事是,虽然我们抓取了大量数据,但我们仍然没有清理足够的数据来进行分析。不过,这是另一篇博客文章。