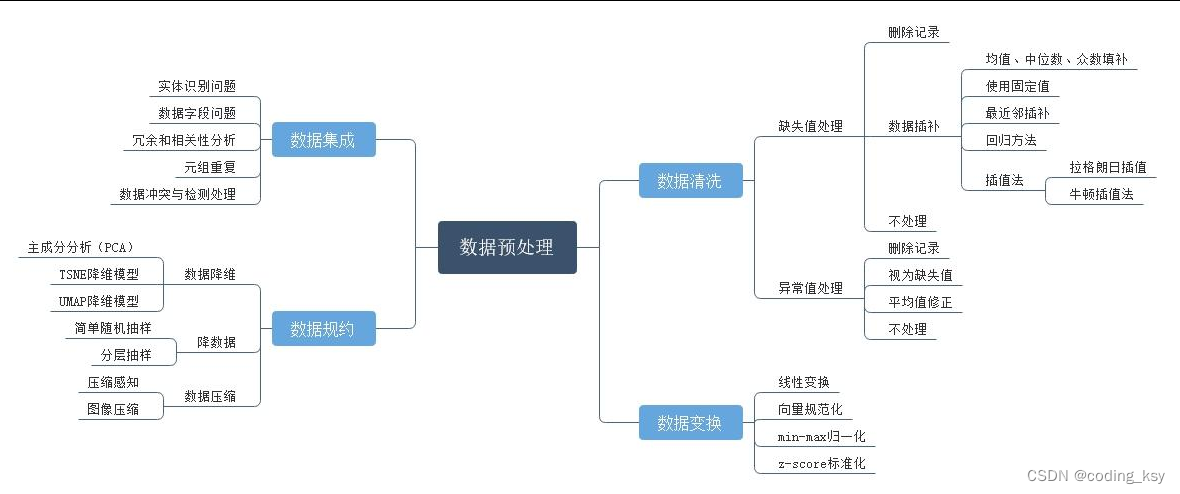
1 数据预处理是什么?
在数学建模赛题中,官方给所有参赛选手的数据可能受到主
观或客观条件的影响有一定的问题,如果不进行数据的处理而直
接使用的话可能对最终的结果造成一定的影响,因此为了保证数
据的真实性和建模结果的可靠性,需要在建模之前对数据进行相
关的预处理工作!
数据预处理一般包括:
数据清洗、数据集成、数据变换及数据规约
2 数据预处理——数据清洗
当我们得到一组数据时,这组数据可能会存在一些缺失值和
异常值(噪声数据)。此时我们进行数据清洗,主要包括两个部
分:
缺失值处理与异常值处理
2.1 缺失值处理
缺失值的处理方法主要有三种:
删除记录、数据插补和不处理。
删除记录:指当该组数据某一个案的数据缺省时,删除这组个案的数据,这种方法的优点是处理
方便,但在数据较少时要慎重使用。
数据插补:使用不同的插补方法将缺省的数据补齐。主要插补方法有:均值/中位数/众数插补;
使用固定值插补;最近邻插补;回归方法插补;插值法插补。
最近邻插补:即在记录中找到与缺失样本最接近的样本的该属性插补,可以通过计算对象间的欧
式距离衡量。
回归方法插补:根据已有数据和与其有关的其他变量的数据建立拟合模型来预测缺失值。
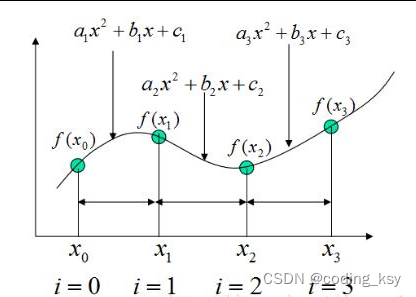
插值法:常用的插值法有很多,主要有
拉格朗日插值法、牛顿插值法。
不处理,有时我们可以将所有缺省数据的样本划分为另一组,进行特殊处理。


Matlab插值:一维插值
yi=interp1(x,y,xi, 'method')
%x,y
为插值点,
xi,yi
为被插值点和结果,
x,y
和
xi,yi
通常为向量
%'method'
表示插值方法:常用方法有
'nearest''linear''spline''cubic'
‘
nearest
’
——
最邻近插值
:
插入与其距离最近的值
‘
linear
’
——
线性插值:构造线性函数进行插值
‘
spline
’
——
三次样条插值,构造三次多项式进行插值
‘
cubic
’
——
立方插值:构造立方函数进行插值
‘
method
’缺省时默认为线性插值
Matlab插值:二维插值
yi=interp2(x,y,z,xi,yi, 'method')
%x,y,z
为插值点,
xi,yi
为被插值点
,zi
为输出的插值结果,即插值函数在
(
xi,yi
)处的值;
x,y
为向量,
xi,yi
为向量或矩阵,而
z
和
zi
则为矩阵
%'method'
表示插值方法:常用方法有
'nearest''linear''spline''cubic'
‘
nearest
’
——
最邻近插值
:
插入与其距离最近的值
‘
linear
’
——
双线性插值:构造两组线性函数进行插值
‘
spline
’
——
双三次样条插值,在每个区间内构造三次多项式进行插值
‘
cubic
’
——
双立方插值:构造立方函数进行插值
默认为双线性插值
% 一维插值
clc;clear all;
y=[0.31472 0.84549 0.98429 0.81619 0.51237];
x=[1 2 3 4 5];
x1=0:0.1:5;
y1=interp1(x,y,x1,'spline');%三次样条插值,构造三次多项式进行插值
plot(x1,y1)%二维插值
x=1:5;
y = 1:3;
temps = [82 81 80 82 84;79 63 61 65 81;84 84 82 85 86];
xi = 1:.2:5;
y1 = 1:.2:3;
zzi = interp2(x,y,temps,xi',y1,'spline');
mesh(xi,y1,zzi);clc;clear all;
x=[123 55 89 84 56 54 100];
y=[2 5 8 9 10 16 15];
z=[165 654 852 254 0 456 251];
x1=50:0.1:150;
y1=0:0.1:20;
[x1,y1]=meshgrid(x1,y1);
z1=griddata(x,y,z,x1,y1,
'linear');
meshc(x1,y1,z1);
2.2 异常值处理
例如:一组身高的数据,大部分数据都是一点几米,突然蹦出个5米,显然和其他数据差异过
大,则判断该数据属于异常值。
处理方法有两种:
正态分布3σ原则,和画箱型图。
1、正态分布3σ原则
数值分布在(μ-3σ,μ+3σ)中的概率为99.73%,其中μ为平均值,σ为标准差。
求解步骤:
1.计算均值μ和标准差σ;2.判断每个数据值是否在(μ-3σ,μ+3σ)内,不在则为异常值。
适用题目:
总体符合正态分布,例如人口数据、测量误差、生产加工质量、考试成绩等。
不适用题目:
总体符合其他分布,例如公交站人数排队论符合泊松分布
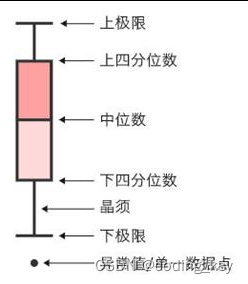
2、画箱型图
箱型图中,把数据从小到大排序。
下四分位数
Q1
是排第25%的数值,上四分位数
Q3
是排第75%的数值。
四分位距
IQR
=
Q3
-
Q1
,也就是排名第75%的减去第25%的数值
正态分布类似,设置个合理区间,在区间外的就是异常值。
一般设[
Q1
−
1.5*
IQR
,
Q3
+1.5*
IQR
]内为正常值
3 数据预处理——数据变换
3.1 数据类型的一致化处理方法

极大型
:
期望取值越大越好;
极小型
:
期望取值越小越好;
中间型
:
期望取值既不要太大,也不要太小为好,取适当的区间为最好
;
区间型
:
期望取值最好是落在某一个确定的区间内为最好。
料请关注公众号【数学建模老哥】课件或代码请公众号回复“课件” ,粉丝
3.1 数据类型的一致化处理方法
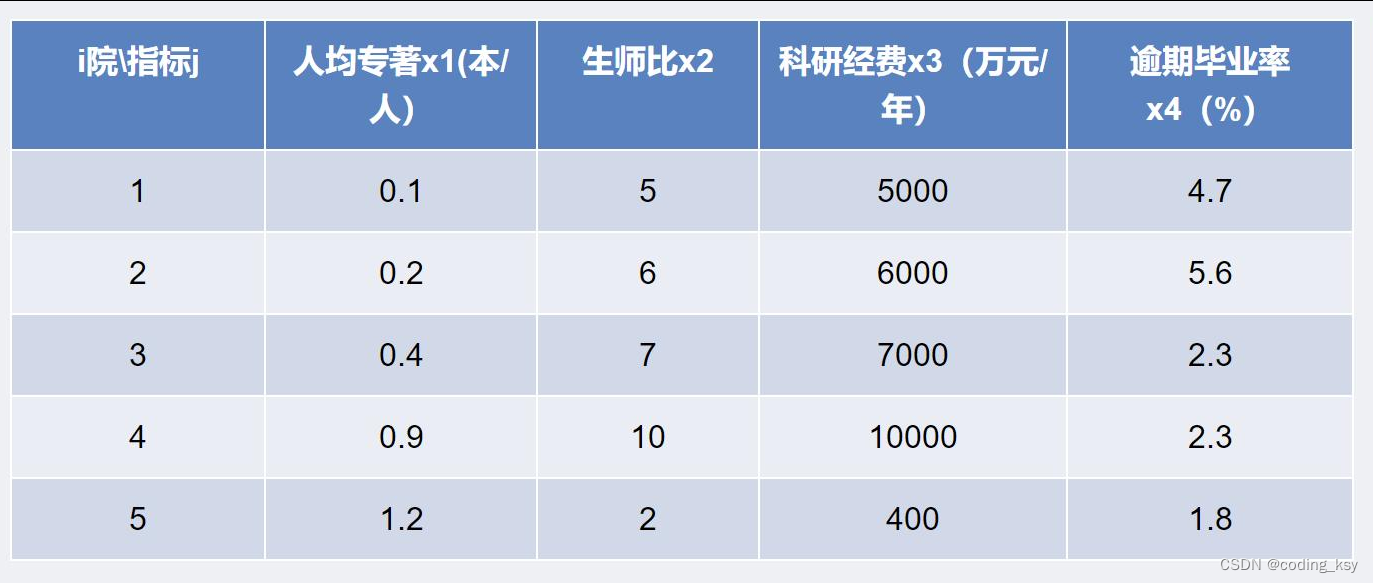
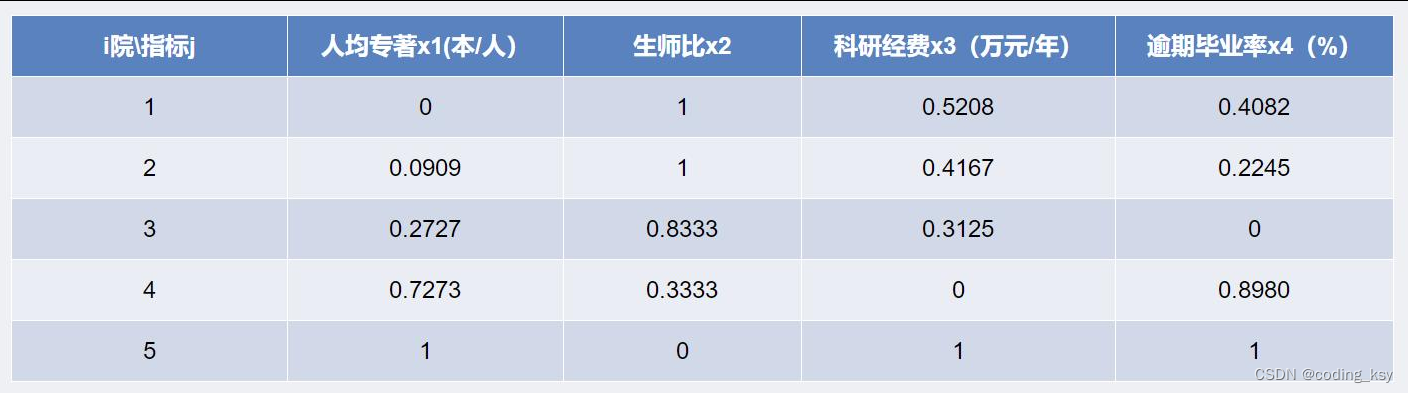
为了客观评价我国研究生教育的实际状况和各研究生院的教学质量,国务
院学位办组织过一此研究生院的评估。为了取得经验,先选了5所研究生院,
收集有关数据进行了式评估,表1给出了部分数据。
3.2数据指标的无量纲化处理





常用方法: 标准差法、极值差法和功效系数法等。

(1)标准差方法
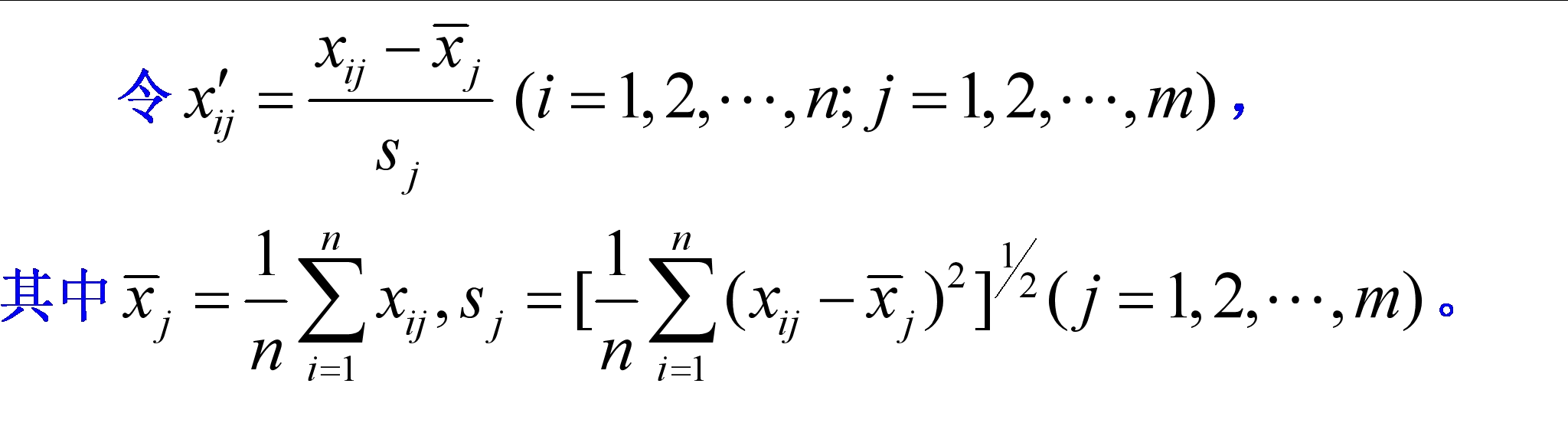

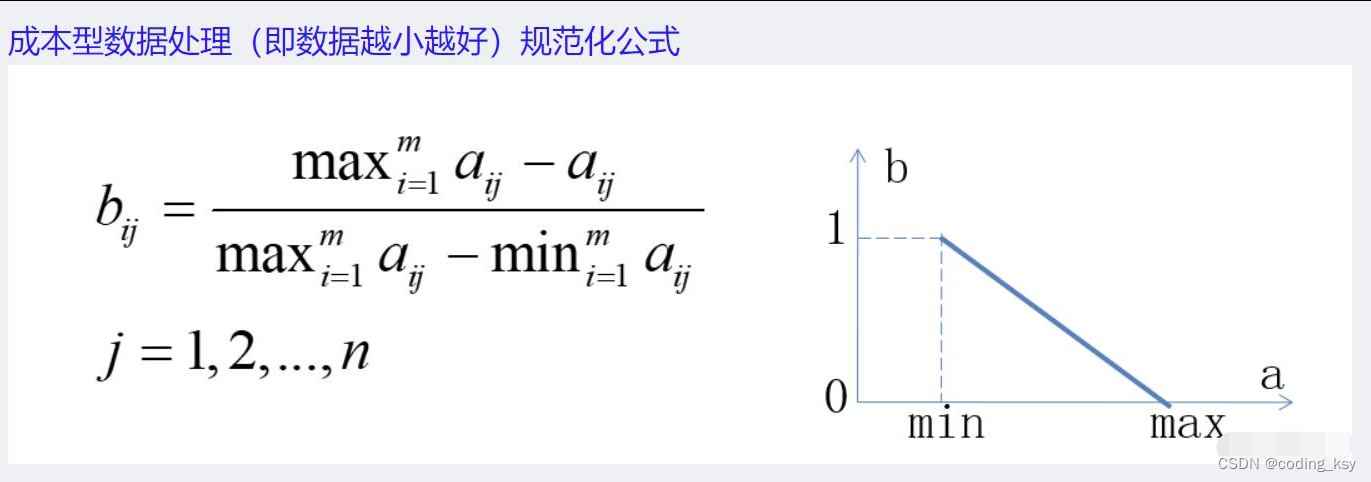
(2) 极值差方法

(3
) 功效系数方法


![]()


数据无量纲化处理的函数:
%数据预处理方法:线性归一化
%a为处理数据矩阵 u为选择处理方法 1为效益型 2
为成本型 3为区间型 qujian为效益形中的最优属性
区间 rennai为忍耐上下限区间
function b=topsis(a,u,qujian,rennai)
am1=min(a);am2=max(a);
% 效益型数据处理(即数据越大越好)
if u==1
b=(a-am1)./(am2-am1);
% 成本型数据处理(即数据越小越好)
elseif u==2
b=(am2-a)./(am2-am1);
% 区间型数据处理
elseif u==3
n=length(a);
for k=1:n
if a(k)>=rennai(1)&a(k)<qujian(1)
b(k)=1-(qujian(1)-a(k))/(qujian(1)-rennai(1));
elseif a(k)>=qujian(1)&a(k)<=qujian(2)
b(k)=1;
elseif a(k)>qujian(2)&a(k)<=rennai(2)
b(k)=1-(a(k)-qujian(2))/(rennai(2)-qujian(2));
else
b(k)=0;
end
end
end调用无量纲化处理的函数
A=[0.1 0.2 0.4 0.9 1.2;
5 6 7 10 2;
5000 6000 7000 10000 400;
4.7 5.6 6.7 2.3 1.8];
A=A';
a1=A(:,1);a2=A(:,2);a3=A(:,3);a4=A(:,4);
b1=topsis(a1,1);
b2=topsis(a2,3,[5,6],[2,12]);
b3=topsis(a3,2);
b4=topsis(a4,2);
[b1,b2',b3,b4]
3.3 定性指标的量化处理方法
在社会实践中,很多问题都涉及到定性因素(指标)的定量处理
问题。诸如:教学质量、科研水平、工作政绩、人员素质、各种满意
度、信誉、态度、意识、观念、能力等因素有关的政治、社会、人
文等领域的问题。
如何对有关问题给出定量分析呢?
按国家的评价标准,评价因素一般分为五个等级,
如A,B,C,D,E。
如何将其量化?若A-,B+,C-,D+等又如何合理量化?
简单地对应数字分量化方法是不科学的!
根据实际问题,构造模糊隶属函数的量化方法是一种可行
有效的方法。
假设有多个评价人对某项因素评价为A,B,C,D,E共5个等级:
{v1 ,v2 ,v3 ,v4,v5}。
譬如:评价人对某事件“满意度”的评价可分为
{很满意,满意,较满意,不太满意,很不满意}
将其5个等级依次对应为5,4,3,2,1。
为取连续量化,取偏大型柯西分布和对数函数作为隶属函数:




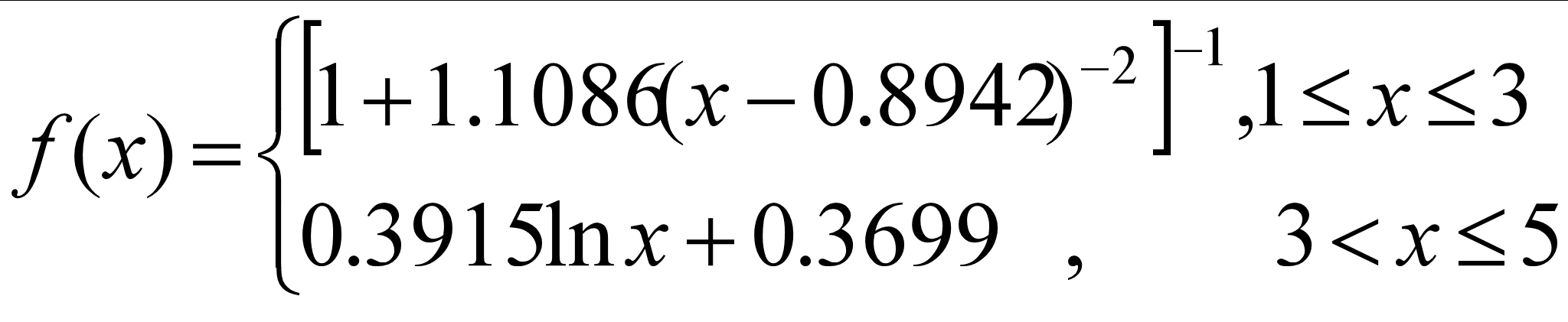
根据这个规律,对于任何一个评价值,
都可以给出一个合适的量化值。
根据实际情况也可以构造其他的隶属
函数