在ES的倒排索引机制中有四个重要的名词:Term、Term Dictionary、Term Index、Posting List。
-
Term(词条):词条是索引里面最小的存储和查询单元。一段文本经过分析器分析以后就会输出一串词条。一般来说英文语境中词条是一个单词,中文语境中一个词条是分词后的一个词组。
此处涉及到分词器,分词器的作用是将一段文字分解为若干个词组,不同的分词器使用的分词算法不同,得到的分词结果也不同。
-
Term Dictionary(词典):词典是词条的集合,顾名思义,词典中维护的是Term。词典一般是由文本集合中出现过的所有词条所组成的集合。
-
Term Index(词条索引):由于词典中维护着文本中所有的词条,为了在其中更快的找到某个词条,我们为词条建立索引。通过压缩算法,词条索引的大小只有所有词条的几十分之一,因此词条索引可以存储在内存中,因此可以提供更快的查找速度。
-
Posting List(倒排表):倒排表记录的是词条出现在哪些文档里,以及出现的位置和频率等信息。倒排表中的每条记录称为一个倒排项(posting)。
将以上概念类比到词典中,Term相当于词典中的词语,Term Dictionary相当于词典本身,Term Index相当于词典的目录。
举个栗子,假设现在我们输入系统多段文本,经过分词器分词后得到以下词条:
- elastic
- flink
- hadoop
- kafka
- spark
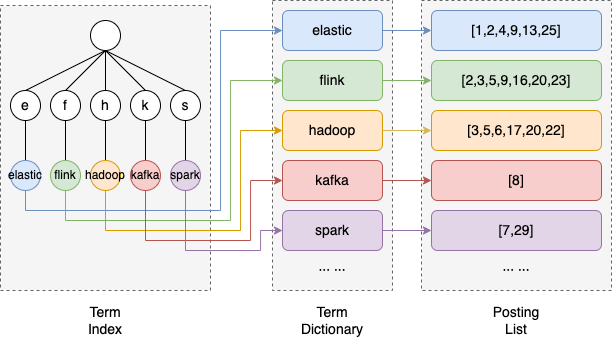
我们使用ES进行全文搜索时,如图所示,系统首先会通过Term Index找到该Term在Term Dictionary中的位置,再通过倒排索引结构找到对应的Posting,从而定位到该词组在文本中的位置,完成一次搜索。
扫描二维码关注公众号,回复:
16213085 查看本文章
