PointPillars: Fast Encoders for Object Detection from Point Clouds
不同于point和voxel,pillars把处理对象变成了柱子。在划分完柱子之后,开始进行点云到伪图像的变换,也就是图中的Pillar Feature Net。
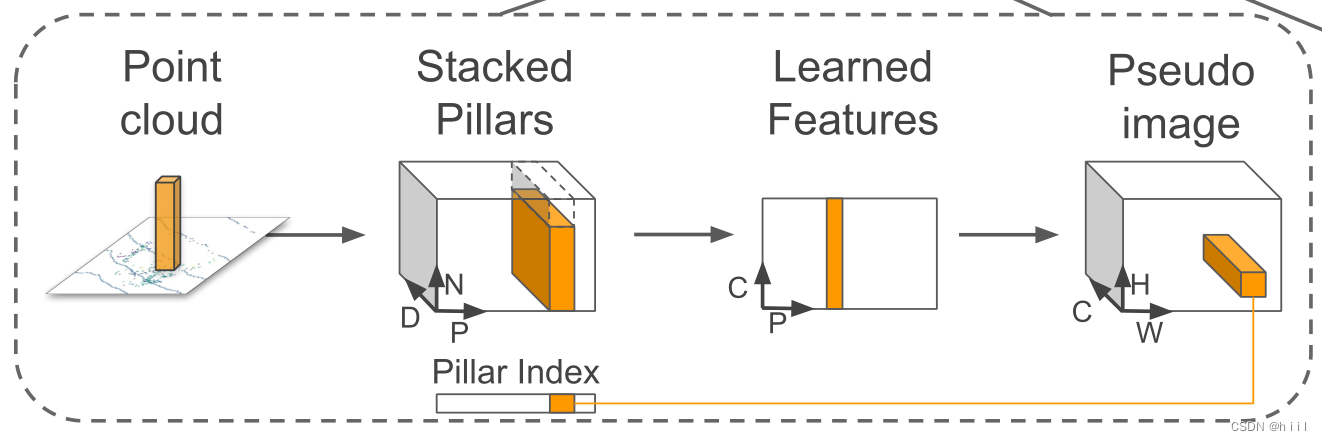
在初始特征选取方面,与voxelnet大同小异,设某个非空柱中有t个点,每个点有四维特征xyzr,xyz是空间坐标,r是反射率。那么整个柱子的点可以表示为集合。这是每个点各自的特征,接下来要做特征增强。
表示每个点到所有点的算数平均值的距离。
表示点在xy维度相对于柱中心点xy的偏移量。这样柱中的每一个点都具有9个维度的特征了(4+3+2)。下面可以用以下张量表示一帧点云数据:(D,P,N):P是有多少个pillar,N是每个pillar中有多少点,D是每个点的9维特征。
接下来,又要提到PointNet了,利用简化的升维方法把每个点的特征由D升维到C(利用Linear,BN,ReLu,即所谓的FCN,前面两篇文章也有提及,自行查看),则张量变为(C,P,N),然后在C维度用maxpooling,即每个柱子从内部若干点的特征汇聚(池化)出一组C维度的特征来表示自己,而略去了点的数量。
这和PointNet以及VoxelNet中的原理一致,PointNet在maxpooling后得到了表征全体点云的特征,VoxelNet在maxpooling后得到表征该体素的特征。因此在柱子中得到了表征该柱子的特征。现在就有了每个柱子的特征了,再按照已有特征中的位置特征把它们放回到相应柱子的位置,就得到了柱子的位置维度wh,以及柱子的特征c。
这里叫做伪图像,我的理解,我们知道图像的特征有chw
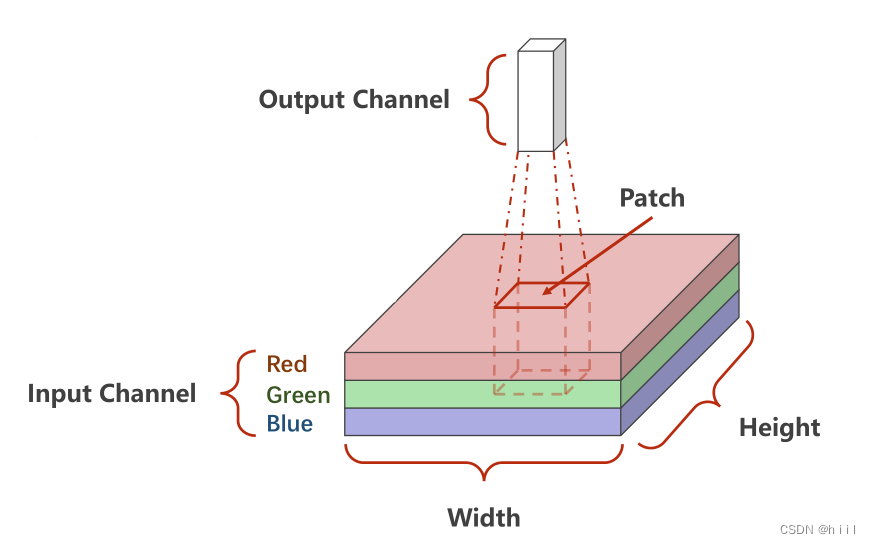
hw这两个维度表示像素的位置,而c表示一个像素的特征。pillars中也是,俯瞰的时候,柱子就是一个个像素,hw表示位置,而c表示该柱子的特征。