先上代码为敬,如果错误,请指正;
代码参考了博文:CUDA 3D convolution![]() https://www.cnblogs.com/ijpq/p/15405106.html
https://www.cnblogs.com/ijpq/p/15405106.html
__global__ void convolution_2D_basic_kernel(float *N, float *P,
int Mask_Width, int Width, int Height){
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
int n = size_kernel / 2;
// 在共享存储器上分配一个TILE_SIZE*TILE_SIZE的二维数组;
__shared__ float N_ds[TILE_SIZE][TILE_SIZE];
// 左上角块内的一个元素
int halo_index_left_x = (blockIdx.x - 1) * blockDim.x + threadIdx.x;
int halo_index_top_y = (blockIdx.y - 1) * blockDim.y + threadIdx.y;
if (threadIdx.x >= blockDim.x - n && threadIdx.y >= blockDim.x - n) {
N_ds[threadIdx.y - (blockDim.y - n)][threadIdx.x - (blockDim.x - n)] =
(halo_index_left_x < 0 || halo_index_top_y < 0)
? 0 : N[halo_index_top_y][halo_index_left_x];
}
// 上方中间块内的一个元素
if (threadIdx.y >= blockDim.x - n) {
N_ds[threadIdx.y - (blockDim.y - n)][threadIdx.x] = halo_index_top_y < 0 ? 0 : N[halo_index_top_y][i];
}
// 右上角块内的一个元素
int halo_index_right_x = (blockIdx.x + 1) * blockDim.x + threadIdx.x;
if (threadIdx.x < n && threadIdx.y >= blockDim.x - n) {
N_ds[threadIdx.y - (blockDim.y - n)][n + blockDim.x + threadIdx.x] =
(halo_index_right_x >= Width || halo_index_top_y < 0)
? 0 : N[halo_index_top_y][halo_index_right_x];
}
// 左侧中间块内的一个元素
if (threadIdx.x >= blockDim.x - n) {
N_ds[threadIdx.y][threadIdx.x - (blockDim.x - n)] = halo_index_left_x < 0 ? 0 : N[j][halo_index_left_x];
}
// 内部元素块内的一个元素
N_ds[threadIdx.y][threadIdx.x] = N[j][i];
// 右侧中间块内的一个元素
if (threadIdx.x < n) {
N_ds[threadIdx.y][n + blockDim.x + threadIdx.x] = halo_index_right_x >= Width ? 0 : N[j][halo_index_right_x];
}
int halo_index_bottom_y = (blockIdx.y + 1) * blockDim.y + threadIdx.y;
// 左下角块内的一个元素
if (threadIdx.x >= blockDim.x - n && threadIdx.y < n) {
N_ds[n + blockDim.y + threadIdx.y][threadIdx.x - (blockDim.x - n)] =
(halo_index_left_x < 0 || halo_index_bottom_y >= Height)
? 0 : N[halo_index_bottom_y][halo_index_left_x];
}
// 下方中间块内的一个元素
if (threadIdx.y < n) {
N_ds[n + blockDim.y + threadIdx.y][threadIdx.x] = halo_index_top_y >= Height ? 0 : N[halo_index_bottom_y][i];
}
// 右下角块内的一个元素
if (threadIdx.x < n && threadIdx.y < n) {
N_ds[n + blockDim.y + threadIdx.y][n + blockDim.x + threadIdx.x] =
(halo_index_right_x >= Width || halo_index_bottom_y >= Height)
? 0 : N[halo_index_bottom_y][halo_index_right_x];
}
__syncthreads();
float p_value = 0;
for (int i = 0; i < size_kernel; i++) {
for (int j = 0; j < size_kernel; j++) {
p_value += N_ds[threadIdx.y + j][threadIdx.x + i] * M[j][i]
}
}
P[j][i] = p_value;
}
之前笔记中实现过了一维的卷积cuda代码:
CUDA笔记-卷积计算_cuda卷积_黑山老妖的博客的博客-CSDN博客CUDA 3D convolution - ijpq - 博客园overview https://www.cnblogs.com/ijpq/p/15405106.htmlhttps://blog.csdn.net/liushao1031177/article/details/124044206 2D卷积代码,其实现思路和优化思路也是等同与一维卷积的;就是在待卷机区域向外延伸,将边缘数据放到块内存,将卷积核放到常量内存上;提高片上内存的访问次数,减少低速全局内存的访问次数;
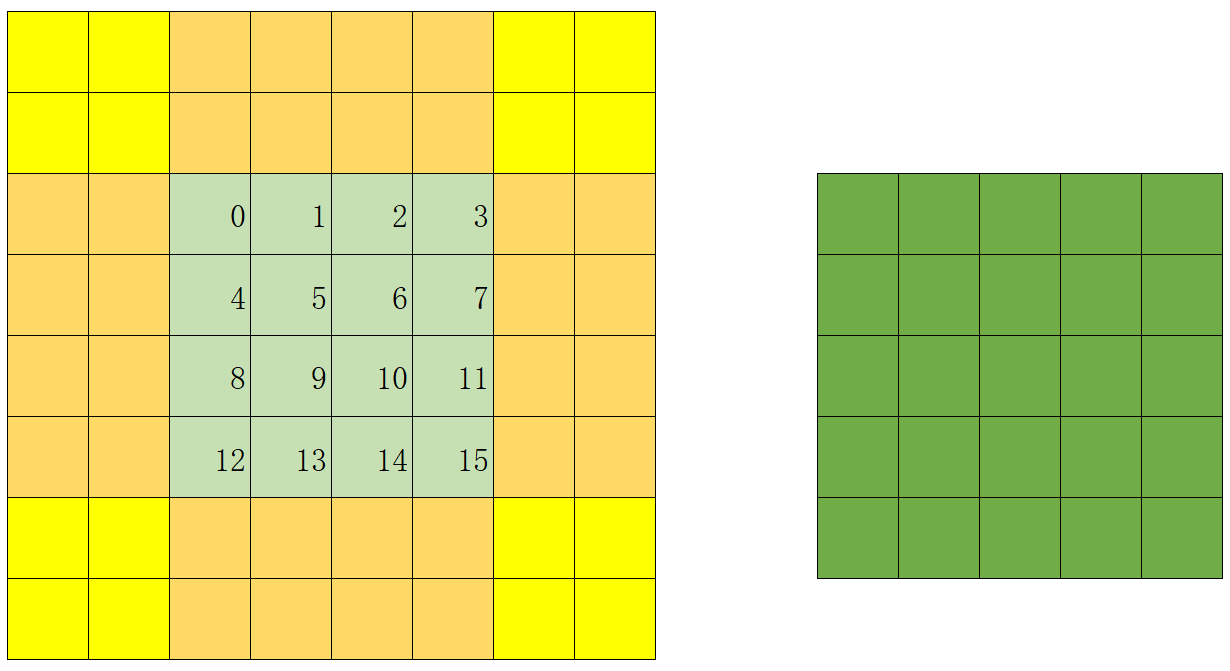
还需要注意边上8个块上数据的设置逻辑,如果看不懂的,从一维笔记里的2个块的设置思路;
同理,三维度上的3D卷积也可以使用该思路写代码,只是到时候就要提前把边缘的26个块提前设置好,可以想象要有26个逻辑部分要写以后闲着没事可以补充上;