
目录
传统类集框架的弊端
传统的类集框架存在一个非常严重的弊端。那就是在多线程的情况下对集合修改会报错。
如下代码
package Example2123;
import java.util.ArrayList;
import java.util.List;
public class javaDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// 多线程
for (int i =0;i<10;i++){
// 多线程下多次放入数据与输出数据
new Thread(()->{
for (int j=0;j<10;j++){
list.add(Thread.currentThread().getName());
System.out.println(list);
}
},"Thread"+i).start();
}
}
}
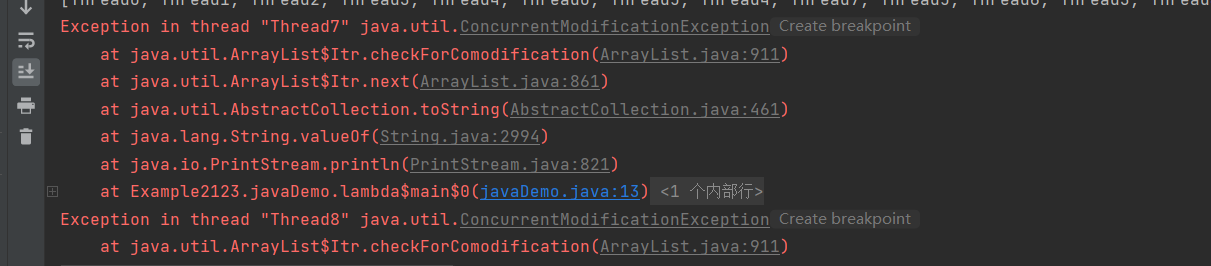
出现了修改异常,因为传统的类集框架是针对单线程设计的。如果出现多线程同时修改的情况下再输出则会出现异常。为此JUC中就提供了并发集合来解决集合安全的问题
1.并发集合的类型
| No. | 集合接口 | 集合类 | 描述 |
|---|---|---|---|
| 1 | List | CopyOnWriteArrayList | 当于线程安全的 ArrayList,并支持高并发访问 |
| 2 | Set | CopyOnWriteArraySet | 相当于线程安全的 HashSet,基于 CopyOnWriteArrayList 实现 |
| 3 | Set | ConcurrentSkipListSet | 相当于线程安全的 TreeSet,基于跳表结构实现,并支持高并发访问 |
| 4 | Map | ConcurrentHashMap | 相当于线程安全的 HashMap,支持高并发访问 |
| 5 | Map | ConcurrentSkipListMap | 相当于线程安全的 TreeMap,基于跳表结构实现,并支持高并发访问 |
| 6 | ArrayBlockingQueue | 基于数组实现的线程安全的有界阻塞队列 | |
| 7 | Queue | LinkedBlockingQueue | 单向链表实现的阻塞队列,支持 FIFO 处理 |
| 8 | Queue | ConcurrentLinkedQueue | 单向链表实现的无界队列,支持 FIFO 处理 |
| 9 | Deque | LinkedBlockingDeque | 双向链表实现的双向并发阻塞队列,支持 FIFO、FILO 处理 |
| 10 | Deque | ConcurrentLinkedDeque | 双向链表实现的无界队列,支持 FIFO、FILO 处理 |
2.并发单值集合
并发单值在类集框架中分为两类,一类是List链表,一条是Set集合。以下分别是并发链表和并发集合
1.CopyOnWriteArraylist (并发链表)
常用方法如下:
| 方法名 | 描述 |
|---|---|
boolean add(E e) |
将指定元素追加到此列表的末尾。 |
void add(int index, E element) |
将指定元素插入此列表中的指定位置。 |
boolean remove(Object o) |
从列表中移除指定元素的第一个匹配项(如果存在)。 |
E remove(int index) |
移除列表中指定位置的元素。 |
E get(int index) |
返回列表中指定位置的元素。 |
int size() |
返回列表中的元素数。 |
boolean contains(Object o) |
如果列表包含指定的元素,则返回 true。 |
Iterator<E> iterator() |
返回在列表的元素上进行迭代的迭代器。 |
案例代码:
package Example2124;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
public class javaDemo {
public static void main(String[] args) {
// 创建并发链表
List<String> list = new CopyOnWriteArrayList<>();
// 创建多线程
for (int i=0;i<10;i++){
new Thread(()->{
// 多线程对并发集合进行修改
for (int j=0;j<10;j++){
list.add(Thread.currentThread().getName());
System.out.println(list);
}
},"Thread"+i).start();
}
}
}
注意:
- 由于CopyOnWriteArrayList是基于数组实现的并发集合类。 在执行修改操作时候都会创建一个新的数组,再将更新后的数据复制进入新的数组中。所以该类实现修改的效率比较低。
- 在使用迭代器iterator的时候,并不支持iterato的remove删除元素的操作。
2.CopyOnWriteArraySet
以下是常用的方法
| 方法名 | 描述 |
|---|---|
boolean add(E e) |
将指定元素添加到此集合中,如果已存在则不添加。 |
boolean remove(Object o) |
从集合中移除指定元素的第一个匹配项(如果存在)。 |
boolean contains(Object o) |
如果集合包含指定的元素,则返回 true。 |
int size() |
返回集合中的元素数。 |
boolean isEmpty() |
如果集合不包含任何元素,则返回 true。 |
void clear() |
从集合中移除所有元素。 |
Iterator<E> iterator() |
返回在集合的元素上进行迭代的迭代器。 |
案例代码:
package Example2125;
import java.util.Set;
import java.util.concurrent.CopyOnWriteArraySet;
public class javaDemo {
public static void main(String[] args) {
// 创建并发集合
Set<String> set = new CopyOnWriteArraySet<>();
// 多个人同时写自己喜欢的Hobby
String hobbies[] = new String[]{"篮球","逛街","打游戏","跑步","写编程"};
for (int i=0;i<10;i++){
new Thread(()->{
for (int j=0;j< hobbies.length;j++){
set.add(hobbies[j]);
}
}).start();
}
System.out.println(set);
}
}
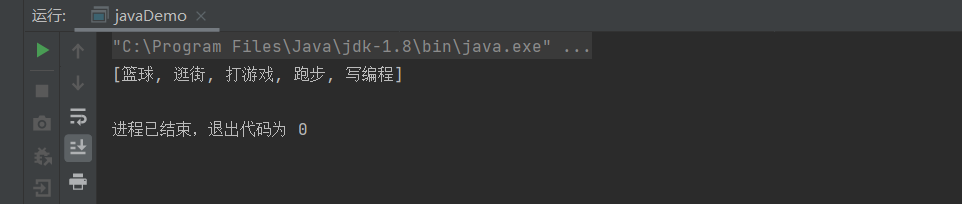
注意:CopyOnWriteArraySet是依赖于CopyOnWriteArrayList进行数据保存的,所以对应的迭代器输出时候也不能出现删除操作
3.并发多值集合
1.ConcurrentHashMap
原理:将一个哈希表的结构分为多个片段,并且每一个片段中都有互斥锁,所以在同一个片段中线程之间是互斥的,而由于由多个片段,所以可以进行异步处理。这样保证了安全的前提下又能保证
常用的方法
| 方法名 | 描述 |
|---|---|
V put(K key, V value) |
将指定的键值对添加到映射中。如果键已经存在,则替换对应的值,并返回旧值。 |
V get(Object key) |
返回指定键所映射的值,如果键不存在,则返回 null。 |
boolean containsKey(Object key) |
如果映射包含指定键的映射关系,则返回 true。 |
boolean containsValue(Object value) |
如果映射将一个或多个键映射到指定值,则返回 true。 |
V remove(Object key) |
从映射中移除指定键的映射关系,并返回该键对应的值。 |
boolean remove(Object key, Object value) |
仅当指定的键当前映射到指定的值时,才从映射中移除该键的映射关系。 |
int size() |
返回映射中键值对的数目。 |
boolean isEmpty() |
如果映射不包含任何键值对,则返回 true。 |
void clear() |
从映射中移除所有的键值对。 |
案例代码:
package Example2126;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class javaDemo {
public static void main(String[] args) {
// 创建并发哈希表
Map<String,Integer> map = new ConcurrentHashMap<>();
for (int i=0;i<5;i++){
new Thread(()->{
// 多线程传输数据
for (int j = 0;j<5;j++){
map.put(Thread.currentThread().getName(),j);
}
},"Thread"+i).start();
}
// 输出map
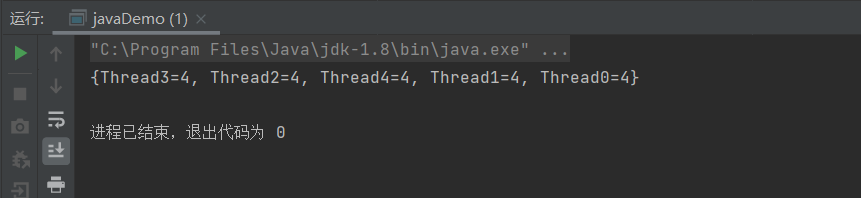
System.out.println(map);
}
}
面试题 Java8开始ConcurrentHashMap,为什么舍弃分段锁?
ConcurrentHashMap的原理是引用了内部的 Segment ( ReentrantLock ) 分段锁,保证在操作不同段 map 的时候, 可以并发执行, 操作同段 map 的时候,进行锁的竞争和等待。从而达到线程安全, 且效率大于 synchronized。
但是在 Java 8 之后, JDK 却弃用了这个策略,重新使用了 synchronized+CAS。
弃用原因
通过 JDK 的源码和官方文档看来, 他们认为的弃用分段锁的原因由以下几点:
- 加入多个分段锁浪费内存空间。
- 生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。
- 为了提高 GC 的效率
- 新的同步方案
- 既然弃用了分段锁, 那么一定由新的线程安全方案, 我们来看看源码是怎么解决线程安全的呢?(源码保留了segment 代码, 但并没有使用)。
面试题 ConcurrentHashMap(JDK1.8)为什么要使用synchronized而不是如ReentranLock这样的可重入锁?
(1)锁的粒度
首先锁的粒度并没有变粗,甚至变得更细了。每当扩容一次,ConcurrentHashMap的并发度就扩大一倍。
(2)Hash冲突
JDK1.7中,ConcurrentHashMap从过二次hash的方式(Segment -> HashEntry)能够快速的找到查找的元素。在1.8中通过链表加红黑树的形式弥补了put、get时的性能差距。
JDK1.8中,在ConcurrentHashmap进行扩容时,其他线程可以通过检测数组中的节点决定是否对这条链表(红黑树)进行扩容,减小了扩容的粒度,提高了扩容的效率。下面是我对面试中的那个问题的一下看法。
为什么是synchronized,而不是ReentranLock
(1)减少内存开销
假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承AQS来获得同步支持。但并不是每个节点都需要获得同步支持的,只有链表的头节点(红黑树的根节点)需要同步,这无疑带来了巨大内存浪费。
(2)获得JVM的支持
可重入锁毕竟是API这个级别的,后续的性能优化空间很小。
synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。这就使得synchronized能够随着JDK版本的升级而不改动代码的前提下获得性能上的提升。
面试题 concurrentHashMap和HashTable有什么区别?
concurrentHashMap融合了hashmap和hashtable的优势,hashmap是不同步的,但是单线程情况下效率高,hashtable是同步的同步情况下保证程序执行的正确性。
concurrentHashMap锁的方式是细粒度的。concurrentHashMap将hash分为16个桶(默认值),诸如get、put、remove等常用操作只锁住当前需要用到的桶。
concurrentHashMap的读取并发,因为读取的大多数时候都没有锁定,所以读取操作几乎是完全的并发操作,只是在求size时才需要锁定整个hash。
而且在迭代时,concurrentHashMap使用了不同于传统集合的快速失败迭代器的另一种迭代方式,弱一致迭代器。在这种方式中,当iterator被创建后集合再发生改变就不会抛出ConcurrentModificationException,取而代之的是在改变时new新的数据而不是影响原来的数据,iterator完成后再讲头指针替代为新的数据,这样iterator时使用的是原来的数据。
4.跳表集合
跳表是一种类似于平衡二叉树的数据结构,主要在链表中使用
原理:一个有序的数组正常使用索引查询的时候时间复杂度为O(1),但是如果是需要通过遍历查找想要优化查找速度则会使用二分法,而链表不是数组,为了有相似的效果所以引入了跳表集合
跳表的两种集合类型:ConcurrentSkipListMap、ConcurrentSkipListSet,下面依次介绍
1.ConcurrentSkipListMap
常用方法:
| 方法 | 描述 |
|---|---|
put(key, value) |
将指定的键值对插入到映射中。如果键已经存在,则更新对应的值。 |
get(key) |
返回与指定键关联的值,如果键不存在,则返回 null。 |
remove(key) |
从映射中移除与指定键关联的映射关系。 |
containsKey(key) |
判断映射中是否包含指定键。 |
containsValue(value) |
判断映射中是否包含指定值。 |
size() |
返回映射中键值对的数量。 |
isEmpty() |
判断映射是否为空。 |
clear() |
从映射中移除所有的键值对。 |
案例代码:
package Example2127;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CountDownLatch;
public class javaDemo {
public static void main(String[] args) throws Exception {
// 创建子线程优先同步器
CountDownLatch latch = new CountDownLatch(10);
Map<String, Integer> map = new ConcurrentHashMap<>();
for (int i = 0; i < 10; i++) {
int threadNum = i;
new Thread(() -> {
for (int j = 0; j < 10; j++) {
// 存放数据到map中
map.put("Thread" + threadNum + "-" + j, j);
}
latch.countDown();
}, "Thread" + threadNum).start();
}
// 等待子线程放入所有数据完毕
latch.await();
// 通过跳表的查询,优化查询速度
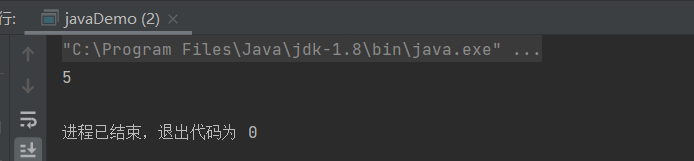
System.out.println(map.get("Thread9-5"));
}
}
2.ConcurrentSkipListSet
常用的方法:
| 方法 | 描述 |
|---|---|
boolean add(E e) |
向集合中添加指定元素 |
boolean remove(Object o) |
从集合中移除指定元素 |
boolean contains(Object o) |
判断集合中是否包含指定元素 |
int size() |
返回集合的大小 |
E first() |
返回集合中的第一个元素 |
E last() |
返回集合中的最后一个元素 |
Iterator<E> iterator() |
返回在此集合元素上进行迭代的迭代器 |
void clear() |
从集合中移除所有元素 |
Object[] toArray() |
返回包含集合中所有元素的数组 |
boolean isEmpty() |
判断集合是否为空 |
案例代码:
package Example2128;
import java.util.Set;
import java.util.concurrent.ConcurrentSkipListSet;
import java.util.concurrent.CountDownLatch;
public class javaDemo {
public static void main(String[] args) {
Set<String> set = new ConcurrentSkipListSet<>();
CountDownLatch latch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
final int temp = i;
new Thread(() -> {
for (int j = 0; j < 10; j++) {
set.add("Thread" + temp + "-" + j);
}
latch.countDown();
}, "Thread" + temp).start();
}
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(set.contains("Thread3-8"));
}
}

面试题哪些集合类是线程安全的?
- Vector:就比Arraylist多了个同步化机制(线程安全)。
- Stack:栈,也是线程安全的,继承于Vector。
- Hashtable:就比Hashmap多了个线程安全。
- ConcurrentHashMap:是一种高效但是线程安全的集合。