笔记列表:
目录
- 173、k8s调度原理-ResourceQuota配额限制_1
- 174、k8s调度原理-LimitRange使用_1
- 175、k8s调度原理-nodeSelector_1
- 176、青云-取消合约按量操作_1
- 177、k8s调度原理-limitrange其他设置项_1
- 178、k8s调度原理-亲和与反亲和_1
- 179、k8s调度原理-NodeAffinity_1
- 180、k8s调度原理-亲和与反亲和与拓扑键_1
- 181、k8s调度原理-node的污点_1
- 182、k8s调度原理-pod的容忍_1
- 183、k8s调度原理-拓扑分区约束_1
- 184、k8s调度原理-资源调度策略_1
- 185、k8s安全-基于角色的访问控制_1
- 186、k8s安全-role与clusterrole的写法_1
- 187、k8s安全-dash为什么能操作集群_1
- 188、k8s安全-ServiceAccount与ClusterRole实战_1
- 189、k8s安全-Pod的ServiceAccount注意项_1
- 190、k8s安全-如何自己开发一个k8s的可视化平台_1
- 191、k8s安全-补充_1
- 192、k8s生态-helm应用商店_1
- 193、k8s小实验-部署mysql有状态服务_1
- 194、MySQL默认不是主从同步需要自己设置_1
- 194~231、自建集群、ceph搭建
- 232~241、prometheus、harbor仓库搭建
- 后面的暂时先不总结了,以后再说
173、k8s调度原理-ResourceQuota配额限制_1
173.1、产生背景
一个k8s集群常常是多个团队在使用,比如我们公司是总集成商,所以我们的集群是多家三方公司在使用的,并且一个名称空间就代表一家三方公司,之前就出现过我使用多线程调用k8s集群中另外一家三方公司的事件抽取服务,然后就直接把他们服务给抽炸了,导致公司的k8s集群之间瘫痪,所以限制每个名称空间的资源配额十分重要,能避免单个名称空间出现问题导致整个集群宕机的情况出现
173.2、工作方式
官方文档: https://kubernetes.io/zh-cn/docs/concepts/policy/resource-quotas/
- 服务对象:为名称空间所服务
- 限制范围:可以限制每个名称空间的内存、cpu、资源上限
- 数量:可以为一个名称空间创建多个ResourceQuota对象
- 限制方式:当资源在创建或者更新的时候超过了ResourceQuota的资源限制,那就会报错
- cpu和内存对资源创建的特殊限制:如果我们限制了cpu和内存的最小值、最大值,那么创建资源的时候必须设置请求值(request)和约束值(limit),否则k8s系统将会拒绝该资源创建
173.3、限制resource和limit
173.3.1、ResourceQuota的yaml文件
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: test # 本次使用test名称空间进行测试
spec:
hard:
requests.cpu: "1" # 限制cpu初始值是1
requests.memory: 1Gi # 限制内存初始值是1Gi
limits.cpu: "2" # 限制cpu最大值是2
limits.memory: 2Gi # 限制内存最大值是2Gi
173.3.2、测试ResourceQuota的yaml文件
apiVersion: v1
kind: Pod
metadata:
name: "nginx-resourcequota-pod-test"
namespace: test
labels:
app: "nginx-resourcequota-pod-test"
spec:
containers:
- name: nginx-resourcequota-pod-test
image: "nginx"
resources:
limits:
cpu: 200m
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
173.3.3、测试结果
我们去查看ResourceQuota资源的占用情况,如下所示:

173.4、限制资源count
173.3.1、ResourceQuota的yaml文件
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: test
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
pods: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
173.3.2、测试结果
我们去查看ResourceQuota资源的占用情况,如下所示:

173.5、ResourceQuota优先级
173.5.1、ResourceQuota的yaml文件
可以看到这是一个List集合,其中这种写法和用---写法的作用是一样的
然后里面设置了多个ResourceQuota,并且声明了优先级名称,也就是spec.scopeSelector.matchExpressions.values字段,在声明Pod的时候可以在spec.priorityClassName中指定优先级名称
apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-high
namespace: test
spec:
hard:
cpu: "1000"
memory: 200Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["high"] # 优先级名称,下面会用到,帮助Pod确定使用哪个ResourceQuota
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-medium
namespace: test
spec:
hard:
cpu: "10"
memory: 20Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["medium"] # 优先级名称,下面会用到,帮助Pod确定使用哪个ResourceQuota
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-low
namespace: test
spec:
hard:
cpu: "5"
memory: 10Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["low"] # 优先级名称,下面会用到,帮助Pod确定使用哪个ResourceQuota
173.5.2、测试ResourceQuota的yaml文件
apiVersion: v1
kind: Pod
metadata:
name: high-priority
namespace: test
spec:
containers:
- name: high-priority
image: nginx
resources:
requests:
memory: "100Mi"
cpu: "200m"
limits:
memory: "100Mi"
cpu: "200m"
priorityClassName: high # 设置优先级名称,和上面的spec.scopeSelector.matchExpressions.values的对应
174、k8s调度原理-LimitRange使用_1
174.1、产生背景
如果我们设置了ResourceQuota中的request和limit,但是在创建Pod的没有设置request和limit,按照之前的情况,肯定会报错的,但是我们设置LimitRange之后就可以使用默认限制了
另外一种情况是某个Pod、Container申请的资源太多了,把其他Pod、Container的都挤占了,这种情况是无法接受的,所以也需要限制Pod、Container的资源请求范围
174.2、限制范围
- 在一个命名空间中实施对每个 Pod 或 Container 最小和最大的资源使用量的限制。
- 在一个命名空间中实施对每个 PersistentVolumeClaim 能申请的最小和最大的存储空间大小的限制。
- 在一个命名空间中实施对一种资源的申请值和限制值的比值的控制。
- 设置一个命名空间中对计算资源的默认申请/限制值,并且自动的在运行时注入到多个 Container 中。
174.3、ResourceQuota和LimitRange的关系
两者共同起作用,都会进行限制
174.4、设置limit默认值、request默认值、limit的取值范围
174.4.1、LimitRange用法举例
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
namespace: test
spec:
limits: # 下面举例中都是cpu的限制,当然也可以换成memory,这就是对内存的限制了
- default: # 此处定义默认限制值,也就是limit的默认值
cpu: 500m
defaultRequest: # 此处定义默认请求值,也就是request的默认值
cpu: 500m
max: # max 和 min 共同来定义限制范围,也就是limit的范围
cpu: "1"
min:
cpu: 100m
maxLimitRequestRatio: # limit /request <= 该ratio都是正常的
cpu: 2
type: Container # 添加对容器的限制,如果换成是Pod,那就是对Pod的限制了
174.4.2、Pod使用举例
如果我们设置了spec.max.cpu和spec.min.cpu,但是没有设置spec.default,如果在创建Pod的时候不设置limit.cpu的值,那么它会使用spec.max.cpu的值
174.5、其他几个使用示例
- 如何配置每个命名空间最小和最大的 CPU 约束
- 如何配置每个命名空间最小和最大的内存约束
- 如何配置每个命名空间默认的 CPU 申请值和限制值
- 如何配置每个命名空间默认的内存申请值和限制值
- 如何配置每个命名空间最小和最大存储使用量
- 配置每个命名空间的配额的详细例子
175、k8s调度原理-nodeSelector_1
175.1、产生背景
有一些资源,我们只想在部分节点上部署,所以可以用标签去选择节点,这件事情我们在部署ingress的时候用过,毕竟ingress只用部署在部分节点上就行了;另外我之前还遇到过一件事情,那是一主一从的架构,jenkins的所需要的一些信息只在主节点上存在,但是jenkins启动之后会漂移到从节点上,当时避免出现这种情况,所以我们就在重启jenkins的时候先把从节点给暂停调度了,然后才把jenkins部署到主节点的,像这种情况使用nodeSelector是一个很好的选择
175.2、使用示例
apiVersion: v1
kind: Pod
metadata:
name: "nginx-nodeselector-test"
namespace: default
labels:
app: "nginx-nodeselector-test"
spec:
containers:
- name: nginx-nodeselector-test
image: "nginx"
nodeSelector: # 用node节点标签去选择部署的node
kubernetes.io/os: linux # node节点中的标签,可以用kubectl get node --show-labels命令查看node节点的标签
176、青云-取消合约按量操作_1
不用管
177、k8s调度原理-limitrange其他设置项_1
在# 174、k8s调度原理-LimitRange使用_1里面已经提过了
178、k8s调度原理-亲和与反亲和_1
178.1、亲和、反亲和概念
Pod部署到某些机器或者不部署到某些机器,那肯定是有原因的,亲和就是选择一些自己喜欢的机器,而反亲和就是反之,对于机器的是否选择可以从这三点出发,这些内容可以通过kubectl explain pod.spec.affinity找到,如下:
- nodeAffinity:Node亲和,也就是说Node有哪些标签我就去
- podAffinity:Pod亲和,也就是说有哪些Pod我就去
- podAntiAffinity:Pod反亲和,也就是说有哪些Pod我就不去
179、k8s调度原理-NodeAffinity_1
179.1、NodeAffinity的两种过滤条件
- pod.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution:硬性过滤,必须满足该条件才能调度到该节点上;
DuringScheduling代表在调度期间有效(调度是k8s中scheduler的作用),而IgnoredDuringExecution代表在运行期间被忽略 - pod.spec.affinity.nodeAffinity.preferredDuringSchedulingIgnoredDuringExecution:软性评分,会被优先调度到分数高的节点上,能根据分数进行动态选择
179.2、亲和策略、反亲和策略、拓扑分区的作用
这些方式都是为了控制Pod的部署节点位置
为了让Pod能够按照我们的意愿分配到一些节点上,或者不分配到节点上,也就是说让Pod的部署能受到我们的控制
这些策略的作用仅仅在调度期间有效,然后在运行期间无效,这也就是上面DuringSchedulingIgnoredDuringExecution名称的由来
179.3、如果都不符合必须亲和策略,部署情况如何
那就是不会部署,但是一直会尝试,等待有符合要求的节点出现进行部署
179.4、节点标签强制选择(requiredDuringSchedulingIgnoredDuringExecution)
apiVersion: v1
kind: Pod
metadata:
name: "busybox-nodeaffinity"
namespace: default
labels:
app: "busybox-nodeaffinity"
spec:
containers:
- name: busybox-nodeaffinity
image: "busybox"
command: ['sleep', '3600']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms: # 节点选择
- matchExpressions: # 使用标签进行选择
- key: kubernetes.io/hostname # 标签名称
operator: In # 操作符可以是In(存在于), NotIn(不存在于), Exists(存在,连values参数都不用写), DoesNotExist(不存在,连values参数都不用写). Gt(大于指定值,但是值两边也要加引号,比如:['100', '200']), Lt(小于指定值,虽然是数字,但是值两边也要加引号,比如:['100', '200'])
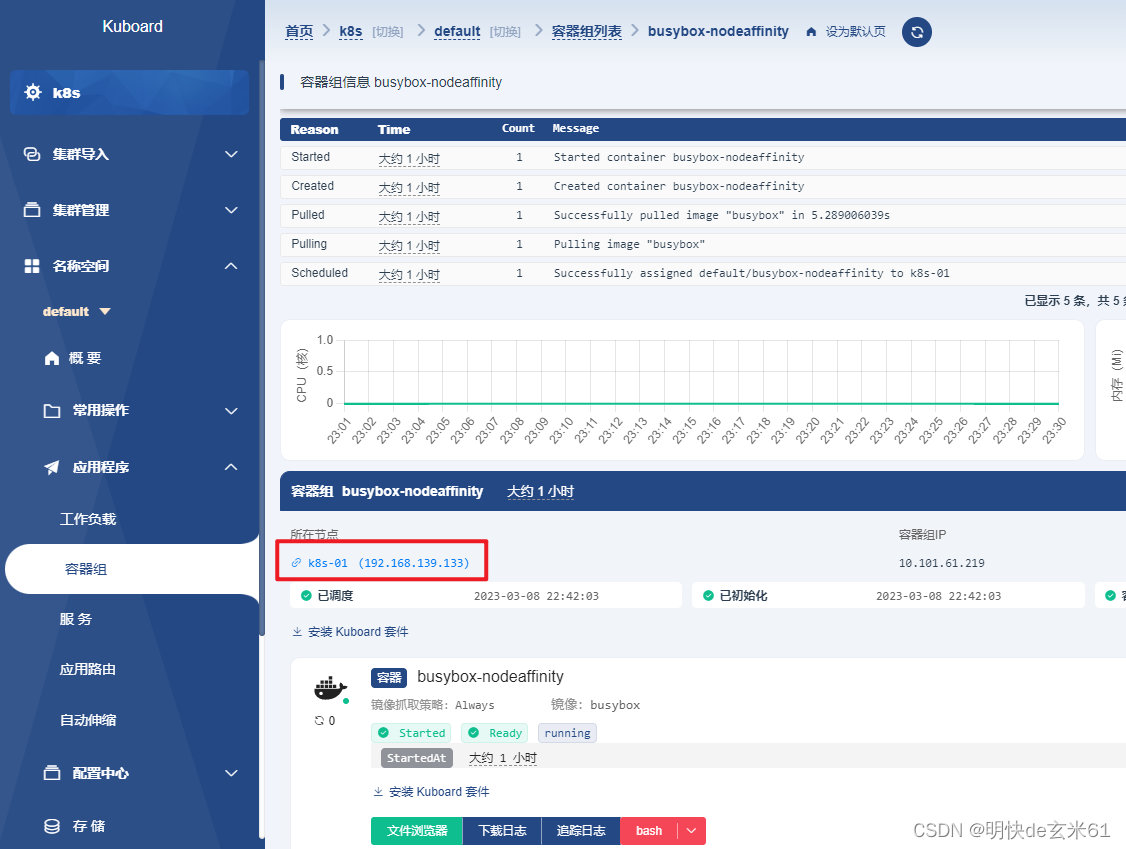
values: ['k8s-01'] # 标签键是kubernetes.io/hostname,值是k8s-01,并且是必须调度条件,那肯定会调度到k8s-01节点
部署效果如下图:
179.5、节点标签选择更喜欢的(preferredDuringSchedulingIgnoredDuringExecution)
apiVersion: v1
kind: Pod
metadata:
name: "busybox-nodeaffinity-prefer"
namespace: default
labels:
app: "busybox-nodeaffinity-prefer"
spec:
containers:
- name: busybox-nodeaffinity-prefer
image: "busybox"
command: ['sleep', '3600']
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference: # 节点选择
matchExpressions: # 使用标签进行选择
- key: kubernetes.io/hostname # 标签名称
operator: In # 操作符可以是In, NotIn, Exists, DoesNotExist. Gt, Lt
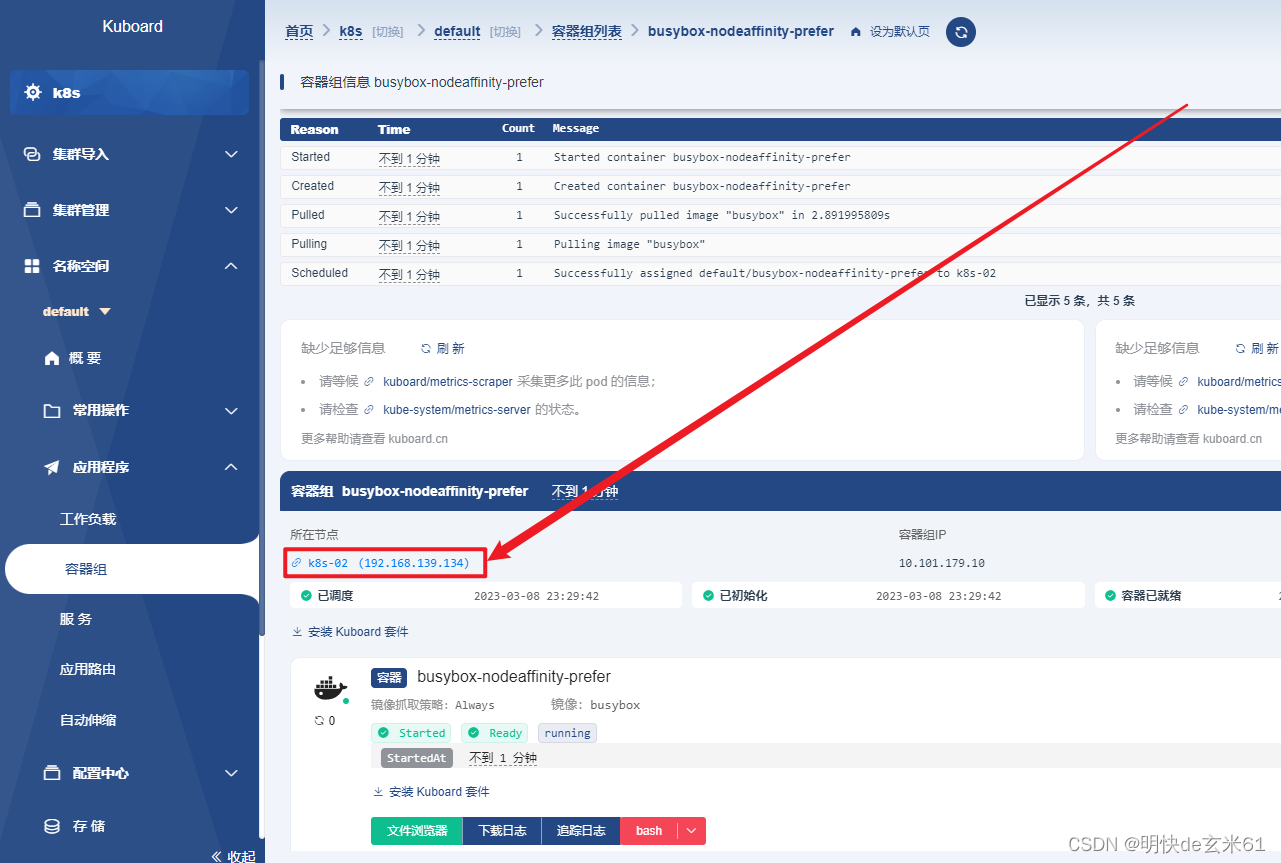
values: ['k8s-01'] # 标签键是kubernetes.io/hostname,值是k8s-01,并且是软性调度条件,其中k8s-02节点分数更高,那肯定会调度到k8s-02节点
weight: 20 # 权重值范围0~100
- preference: # 节点选择
matchExpressions: # 使用标签进行选择
- key: kubernetes.io/hostname # 标签名称
operator: In # 操作符可以是In, NotIn, Exists, DoesNotExist. Gt, Lt
values: ['k8s-02'] # 标签键是kubernetes.io/hostname,值是k8s-02,并且是软性调度条件,那肯定会调度到k8s-02节点
weight: 80 # 权重值范围0~100
部署效果如下图:
180、k8s调度原理-亲和与反亲和与拓扑键_1
180.1、Pod亲和—标签强制选择
说明:
下面说的是Pod标签亲和策略,然后还提到了拓扑键topologyKey,然后说一下拓扑键的作用,只要符合Pod标签亲和,假设是节点A符合,然后节点B不符合,但是节点B的拓扑键中节点标签值和拓扑A相同,那节点B也是符合Pod亲和的
apiVersion: v1
kind: Pod
metadata:
name: "busybox-podaffinity-require"
namespace: default
labels:
app: "busybox-podaffinity-require"
spec:
containers:
- name: busybox-podaffinity-require
image: "busybox"
command: ['sleep', '3600']
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector: # 标签选择,还可以使用namespaceSelector(名称空间通过标签选择)、namespaces(名称空间通过名称选择)、topologyKey(使用拓扑键进行选择)
matchExpressions: # 使用标签进行选择,还可以使用matchLabels
- key: app # Pod的标签名称
operator: In
values: ['nginx'] # Pod的标签值,由于Pod标签app=nginx的只有在k8s-node2节点存在,所以本次肯定部署在k8s-node2节点
topologyKey: "kubernetes.io/hostname" # node节点标签名称,只要和该pod所在的节点的该标签值相同,那就是同一个拓扑网络,那享受的亲和/反亲和待遇是一样的
180.2、Pod反亲和—通过标签相同来避免多个Pod部署到同一台节点上
说明:
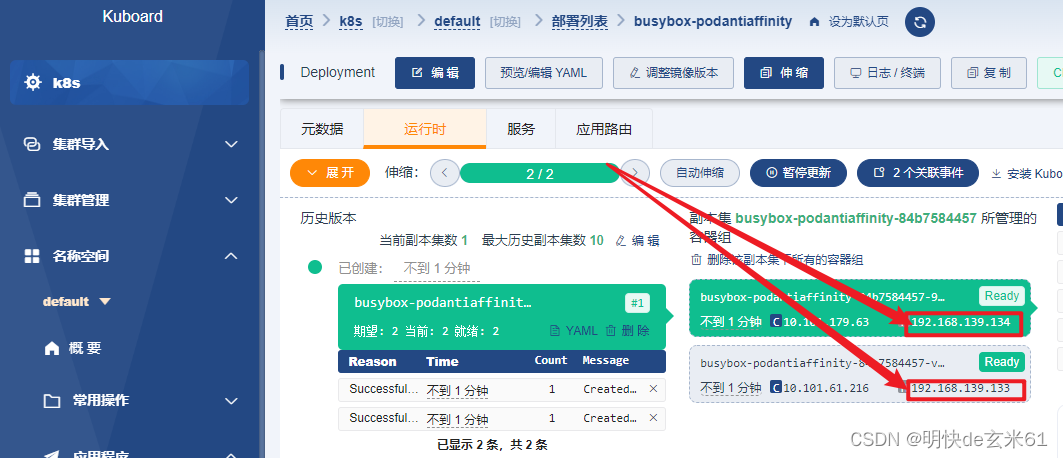
我们的目的是让2个busybox的Pod副本部署到不同节点上,其中Pod的标签是app=busybox-podantiaffinity,如果Pod1部署在节点A上,那么第二个Pod就不能部署在节点A上了,毕竟为了了Pod反亲和原则
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox-podantiaffinity
namespace: default
labels:
app: busybox-podantiaffinity
spec:
selector:
matchLabels:
app: busybox-podantiaffinity
replicas: 2
template:
metadata:
labels:
app: busybox-podantiaffinity
spec:
containers:
- name: busybox-podantiaffinity
image: "busybox"
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector: # 标签选择,还可以使用namespaceSelector、namespaces、topologyKey
matchExpressions: # 使用标签进行选择,还可以使用matchLabels
- key: app # Pod的标签名称
operator: In
values: ['busybox-podantiaffinity'] # 本次部署的busybox的标签是app=busybox-podantiaffinity,我们本次的目的是避免两个容器部署到同一台机器上,所以我们禁止Pod部署到已经含有该标签的节点上
topologyKey: "kubernetes.io/hostname" # node节点标签名称,只要和该pod所在的节点的该标签值相同,那就是同一个拓扑网络,那享受的亲和/反亲和待遇是一样的
部署结果如下:
181、k8s调度原理-node的污点_1
181.1、master节点为什么默认情况下不能调度
因为mater节点上默认存在不能调度的污点,我们通过kuboard查看效果,下图右下角的NodeSchedule就是污点,如下:
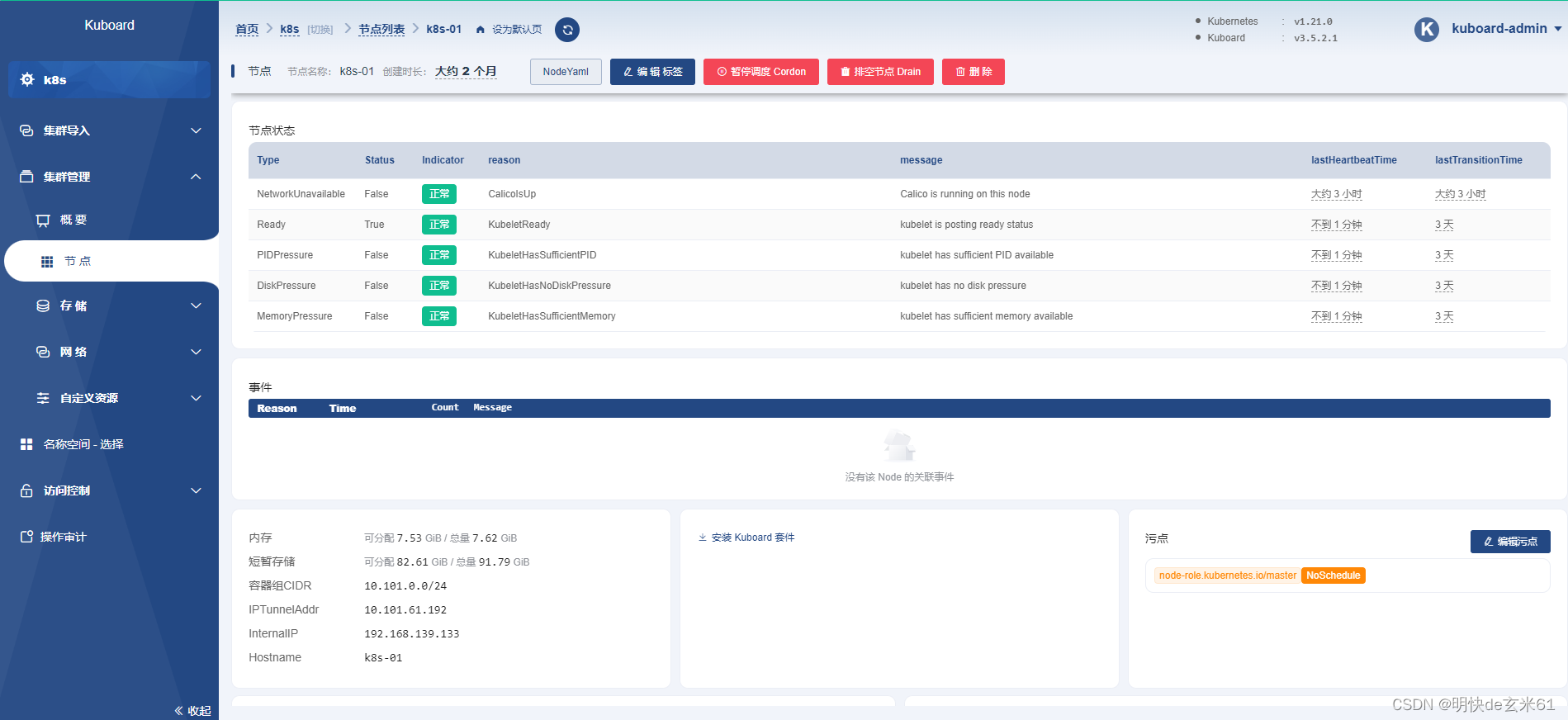
181.2、污点类型
- NoSchedule:不能调度Pod到该节点,但是不影响节点上已有Pod的使用,常用于master节点
- NoExecute:不能调度Pod到该节点,并且驱逐所有已经在该节点的Pod,常用语节点维护
- PreferNoSchedule:尽量不调度,但不是不能调度
181.3、给节点添加污点
添加污点和添加标签用的方法不一样,不过污点也是加在节点上的,写法如下:
// 节点名称:可以通过hostname获取,比如k8s-01
// 污点键:随意取
// 污点值:随意取
// 污点效果:NoSchedule(不调度Pod到该节点)、NoExecute(不调度Pod到该节点,驱逐已有节点)、PreferNoSchedule(尽量不调度Pod到该节点)
kubectl taint node 节点名称 污点键=污点值:污点效果
例如:
kubectl taint nodes k8s-01 taint-key=taint-value:NoSchedule
181.4、查看节点上的污点
命令如下:
// 节点名称:可以通过hostname获取,比如k8s-01
kubectl describe node 节点名称
例如:
kubectl describe node k8s-01
我们在结果中直接找Taints即可,效果如下:

181.5、删除节点上的污点
// 1、最简单写法,例如:kubectl taint node k8s-01 taint-key-
kubectl taint node 节点名称 污点键-
// 2、简单写法,例如:kubectl taint node k8s-01 taint-key:NoSchedule-
kubectl taint node 节点名称 污点键:污点效果-
// 3、完整写法,例如:kubectl taint node k8s-01 taint-key=taint-value:key:NoSchedule-
kubectl taint node 节点名称 污点键=污点值:污点效果-
182、k8s调度原理-pod的容忍_1
182.1、Pod容忍写法
在下面的脚本执行之前,我已经将两个节点k8s-01、k8s-02都打上了不可调度污点
182.1.1、全写
apiVersion: v1
kind: Pod
metadata:
name: "busybox-pod-tolerations-01"
namespace: default
labels:
app: "busybox-pod-tolerations-01"
spec:
containers:
- name: busybox-pod-tolerations-01
image: "busybox"
command: ['sleep', '3600']
tolerations:
- key: "node.kubernetes.io/unschedulable" # 污点键
operator: "Equal" # 操作符,默认是Equal,其他可以选择的值是:Exists
value: "" # 污点值
effect: "NoSchedule" # 污点类型,可以选择的值是:NoSchedule(不调度Pod到该节点)、NoExecute(不调度Pod到该节点,驱逐已有节点)、PreferNoSchedule(尽量不调度Pod到该节点)
182.1.2、只写key和operator
apiVersion: v1
kind: Pod
metadata:
name: "busybox-pod-tolerations-02"
namespace: default
labels:
app: "busybox-pod-tolerations-02"
spec:
containers:
- name: busybox-pod-tolerations-02
image: "busybox"
command: ['sleep', '3600']
tolerations:
- key: "node.kubernetes.io/unschedulable" # 污点键
operator: "Exists" # 操作符,默认是Equal,其他可以选择的值是:Exists
182.1.3、只写key、operator、effect
apiVersion: v1
kind: Pod
metadata:
name: "busybox-pod-tolerations-03"
namespace: default
labels:
app: "busybox-pod-tolerations-03"
spec:
containers:
- name: busybox-pod-tolerations-03
image: "busybox"
command: ['sleep', '3600']
tolerations:
- key: "node.kubernetes.io/unschedulable" # 污点键
operator: "Exists" # 操作符,默认是Equal,其他可以选择的值是:Exists
effect: "NoSchedule" # 污点类型,可以选择的值是:NoSchedule(不调度Pod到该节点)、NoExecute(不调度Pod到该节点,驱逐已有节点)、PreferNoSchedule(尽量不调度Pod到该节点)
182.1.4、节点中的可容忍污点类型是驱逐NoExecute
如果Pod可以容忍的污点类型是驱逐NoExecute,那也是可以部署上的,并且是不会被驱逐的
182.1.5、指定Pod容忍污点的时间tolerationSeconds
容忍污点的秒数,如果超过这个秒钟,那Pod将被重新分配,很少使用,全路径是:pod.spec.tolerations.tolerationSeconds
默认情况下不设置,即这个时间是没有限制的
182.2、常见污点写法,便于排错
如果节点不可用了,我们可以看下该节点上面是不是存在污点了,如果是,那就根据污点类型来进行排错

183、k8s调度原理-拓扑分区约束_1
说明:
拓扑分区约束说白了就是在部署的时候Pod怎么选节点的问题,首先先根据topologyKey去划分分区,可能多个节点在同一个分区,这都是支持的,然后在根据labelSelector去选择合适的Pod,只有存在这些Pod的分区才是能部署的,然后可能多个分区都符合要求,这个时候就要看maxSkew最大倾斜了,只有让所有节点的最大倾斜度相等才行,至于是否一定要满足最大倾斜,那就需要看whenUnsatisfiable了,如果值是DoNotSchedule,那就必须保证倾斜程度和最大倾斜程度相等才行。如果值是ScheduleAnyway,将会按照最优解进行处理
作用:
- 更详细的指定拓扑网络的策略
- 用来规划和平衡整个集群的资源
yaml文件:
apiVersion: v1
kind: Pod
metadata:
name: "nginx-topologyspreadconstraints"
namespace: default
labels:
app: "nginx-topologyspreadconstraints"
spec:
containers:
- name: nginx-topologyspreadconstraints
image: "nginx"
topologySpreadConstraints:
- topologyKey: "kubernetes.io/hostname" # 首先根据node的标签先划分分区,可能多个节点是同一个分区的
labelSelector: # 根据Pod标签来选择适合的部署节点,也就说这个节点上有这个标签的Pod我才去部署
matchLabels: # 直接匹配标签,还可以有另外一种写法是matchExpressions,这个是通过表达式中的标签去选择Pod
app: "nginx" # 标签键和标签值
maxSkew: 1 # 最大倾斜,这个最大倾斜说的部署完成之后所有分区中上述标签所属Pod数量的差值,如果有A和B两个区域,比如A区域中有两个标签app=nginx的Pod,然后B区域中没有一个,那么我们这个Pod的标签如果也是app=nginx的话,那Pod倾斜程度就是2-1=1,刚刚好
whenUnsatisfiable: DoNotSchedule # 如果上面条件不满足的时候的做法,该值是默认值,也就是不满足最大倾斜就不调度。其他值是:ScheduleAnyway(按最优解处理)
184、k8s调度原理-资源调度策略_1
184.1、根据运行时requests请求信息和节点剩余资源情况来确定Pod的分配
我们都知道在声明Pod的时候可以设置resources中的requests和limits的值。
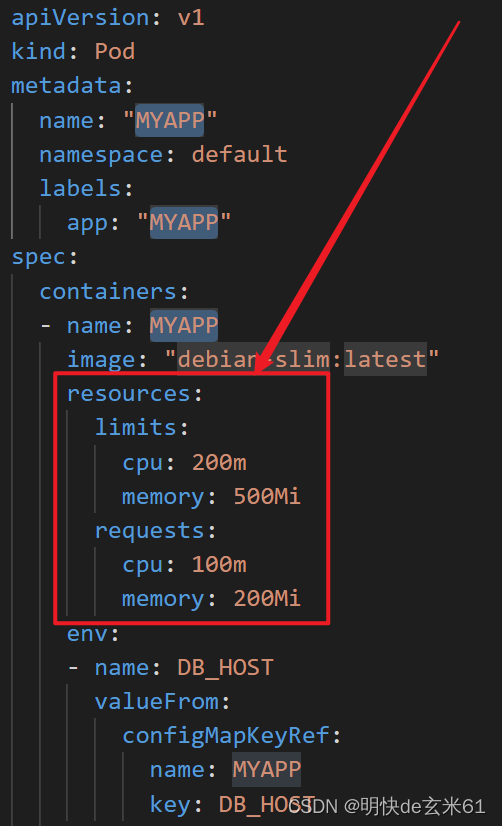
如果现在存在这么一个情况,我们一个Pod中有三个容器,容器1~3中设置的requests.cpu的值分别是200m、300m、100m,而现在有3个可用的节点A~C的cpu剩余值分别是300m、500m、700m,那这个Pod会选择哪里呢,它肯定会选择节点C,原因是只有节点C会满足要求,Pod运行时所需要的资源是所有资源加起来所需要的总量,这是选择一个节点的关键,一定要明白在K8s里面Pod是最小的单位,而不是容器,所以Pod肯定是一个整体去进行部署的
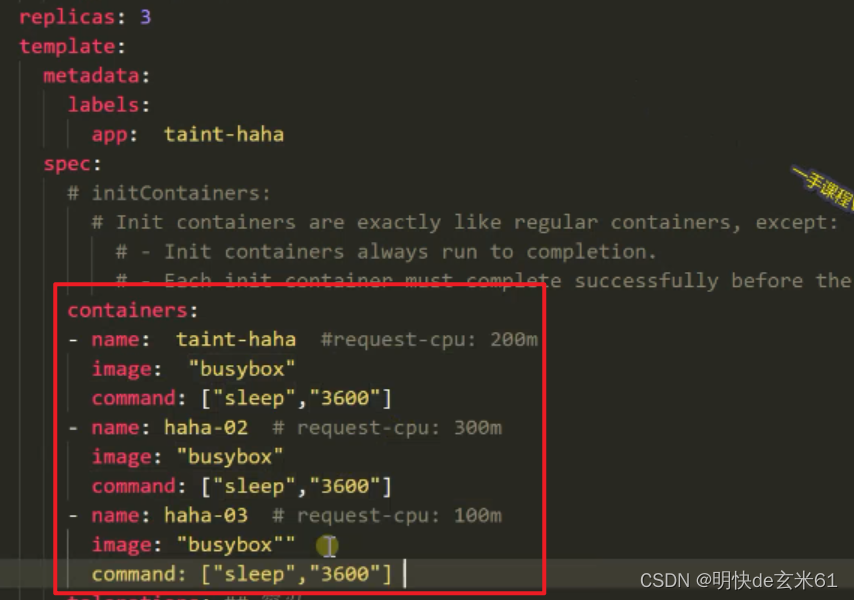
184.2、根据初始化中requests请求信息和节点剩余资源情况来确定Pod的分配
假设Pod启动中需要启动多个容器,比如下面就是启动三个容器,它们需要的cpu资源分别是300m、100m、200m,启动的时候肯定是一个一个容器来的,所以只要能支撑起容器所需的最大内存,那就是可以在上面部署的,比如现在可用的3个可用的节点A~C的cpu剩余值分别是100m、300m、700m,那节点B和节点C都是可以部署该Pod的
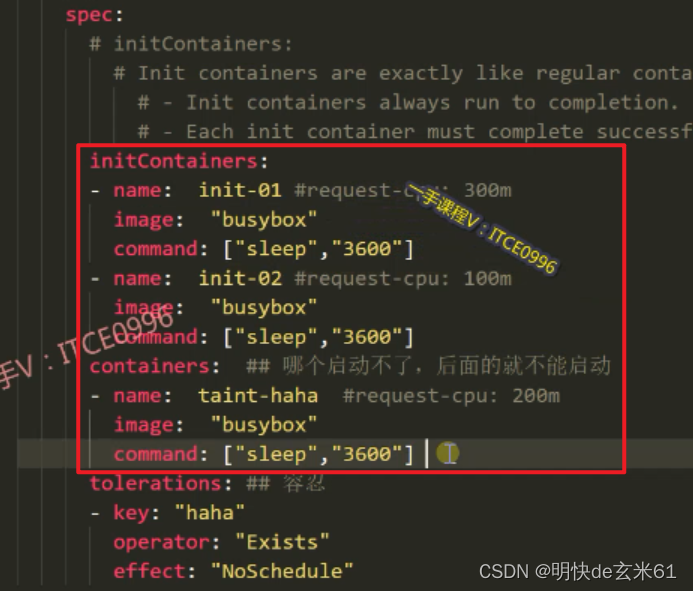
184.3、添加不调度污点、删除不调度污点、添加驱逐污点命令使用方法
- cordon(添加不调度污点,也就是打上
NoSchedule污点,污点全部内容是:node.kubernetes.io/unschedulableNoSchedule):命令是kubectl cordon 节点名称,例如:kubectl cordon k8s-01 - uncordon(删除不调度污点,也就是取消
NoSchedule污点):命令是kubectl uncordon k8s-01,例如:kubectl uncordon k8s-01 - drain(添加驱逐污点,也就是打上
NoExecute污点,绝对不要使用):命令是kubectl drain k8s-01,例如:kubectl drain k8s-01
185、k8s安全-基于角色的访问控制_1
185.1、RBAC理论
RBAC全称是Role Based Access Controller,即基于角色的访问控制,也就是用户》角色》权限完成用户的权限控制
185.2、权限控制流程
- 用户携带令牌/证书给k8s的api-server发送修改集群资源的请求
- k8s认证
- k8s查询用户权限
- 利用准入控制来判断是否可以支持这样操作
185.3、四种K8s对象
- ServiceAccount:用户,每一个用户的密码都存在Secret,里面有一个token是密码,属于名称空间
- RoleBinding:将ServiceAccount和Role绑定起来,属于名称空间
- Role:基于名称空间的角色,可以操作名称空间下的资源,属于名称空间
- ClusterRoleBinding:将ServiceAccount和ClusterRole绑定起来,属于名称空间
- ClusterRole:基于集群的角色,可以操作集群资源
说明: ServiceAccount通过RoleBinding绑定Role,通过ClusterRoleBinding绑定ClusterRole
186、k8s安全-role与clusterrole的写法_1
186.1、创建ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: test-account # 用户名称
186.2、创建Role(角色属于名称空间)
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: test-role
namespace: default # Role属于名称空间
rules:
- apiGroups:
- "" # 空字符串代表核心API组,一般都不用写
resources:
- pods # 资源类型名称,可以通过kubectl api-resources查看
# resourceNames: # 很少使用,基本不用
# - XXX # 上面指定资源类型名称,这里指定白名单,也就是说上面资源中白名单内的资源可以访问,但是上面资源中白名单外的资源都不能访问
verbs:
- get # 操作,可以通过kubectl api-resources -owide | grep 资源名称的方式去查看,最后一个字段的值就是该值
186.3、创建ClusterRole(集群角色不属于名称空间)
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: test-clusterrole # clusterrole不属于任何名称空间
rules:
- apiGroups:
- "" # 空字符串代表核心API组,一般都不用写
resources:
- namespaces # 资源类型名称,可以通过kubectl api-resources查看
verbs: # 操作,可以通过kubectl api-resources -owide | grep 资源名称的方式去查看,最后一个字段的值就是该值
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups: # 可以写多个
- "" # 空字符串代表核心API组,一般都不用写
resources:
- pods # 资源类型名称,可以通过kubectl api-resources查看
verbs: # 操作,可以通过kubectl api-resources -owide | grep 资源名称的方式去查看,最后一个字段的值就是该值
- create
- delete
187、k8s安全-dash为什么能操作集群_1
因为当时我们为k8s-dashboard设置了用户、角色、权限信息,这些信息起作用了,直接来看kuboard的页面吧!
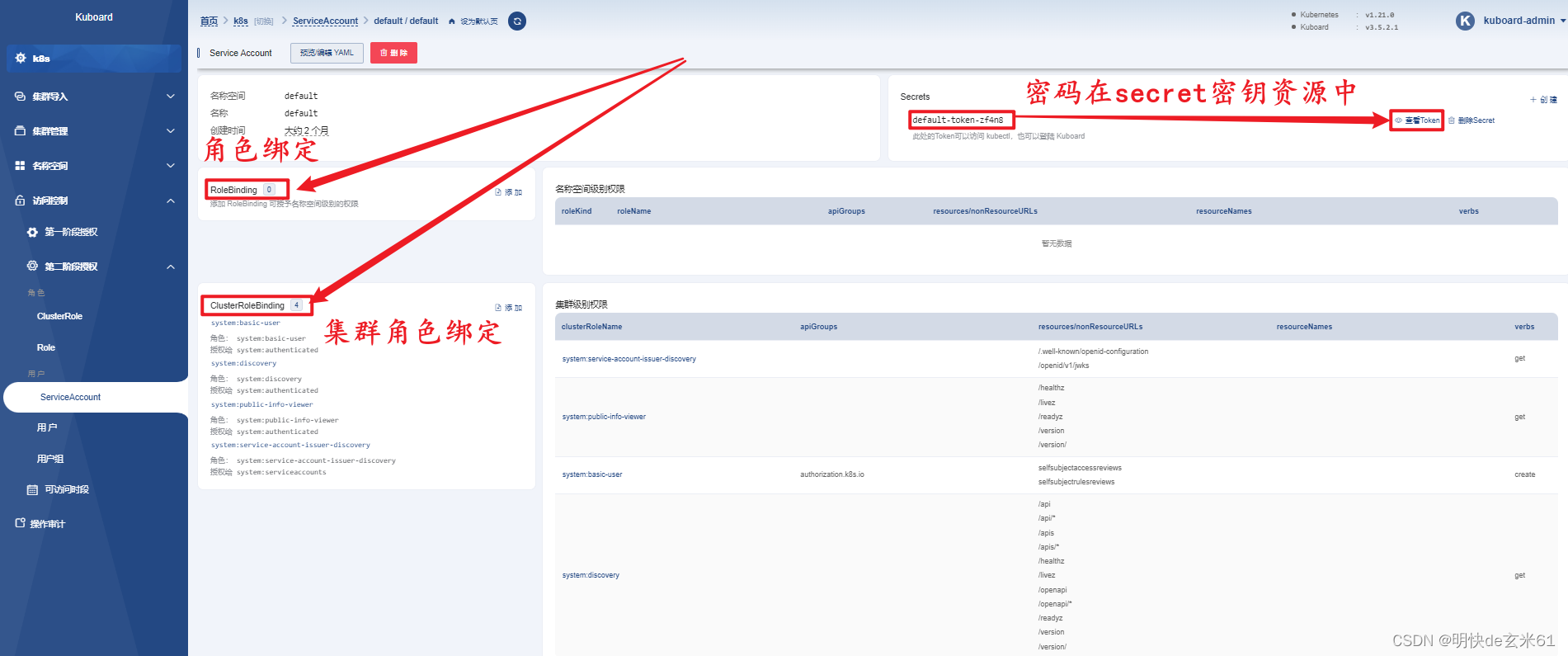
188、k8s安全-ServiceAccount与ClusterRole实战_1
188.1、创建RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: test-rolebinding
namespace: default
subjects:
- apiGroup: ""
kind: ServiceAccount # 账户类型
name: test-account # test-account是账户名称
roleRef:
apiGroup: ""
kind: Role # 角色类型
name: test-role # test-role是角色名称
188.2、创建ClusterBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: test-clusterrolebinding
namespace: default
subjects:
- apiGroup: ""
kind: ServiceAccount # 账户类型
name: test-account # test-account是账户名称
namespace: default # 还必须写,不写还报错
roleRef:
apiGroup: ""
kind: ClusterRole # 集群角色类型
name: test-clusterrole # test-clusterrole是集群角色名称
188.3、用新用户的token登录
我们假设想要用新账号登录k8sdashboard,那就去通过kuboard来获取登录token,如下:
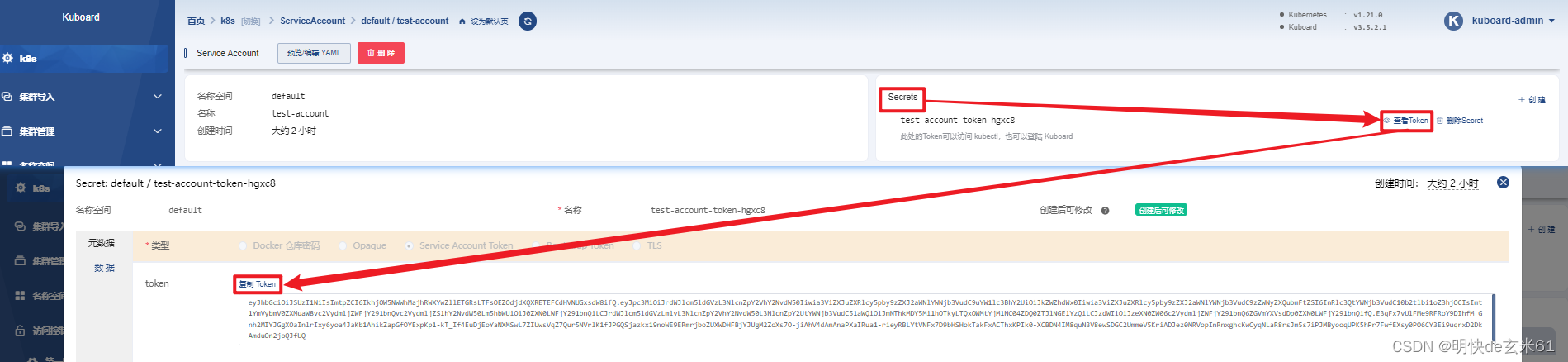
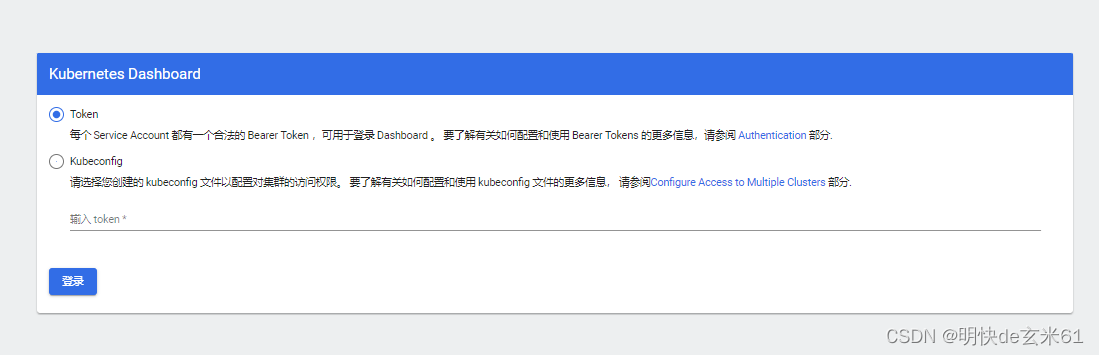
把token复制到k8sdashboard的输入框中即可,如下:
189、k8s安全-Pod的ServiceAccount注意项_1
189.1、空的默认服务账号
在名称空间创建之后,就会在该名称空间下自动创建一个默认服务账号,并且这个服务账号是空的,每个Pod都会默认挂载这个账号,如果我们想要让Pod拥有更多的权限,可以在Pod创建的时候指定服务账号名称,也就是pod.spec.serviceAccountName,那么这个Pod就拥有了这个服务账号的权限
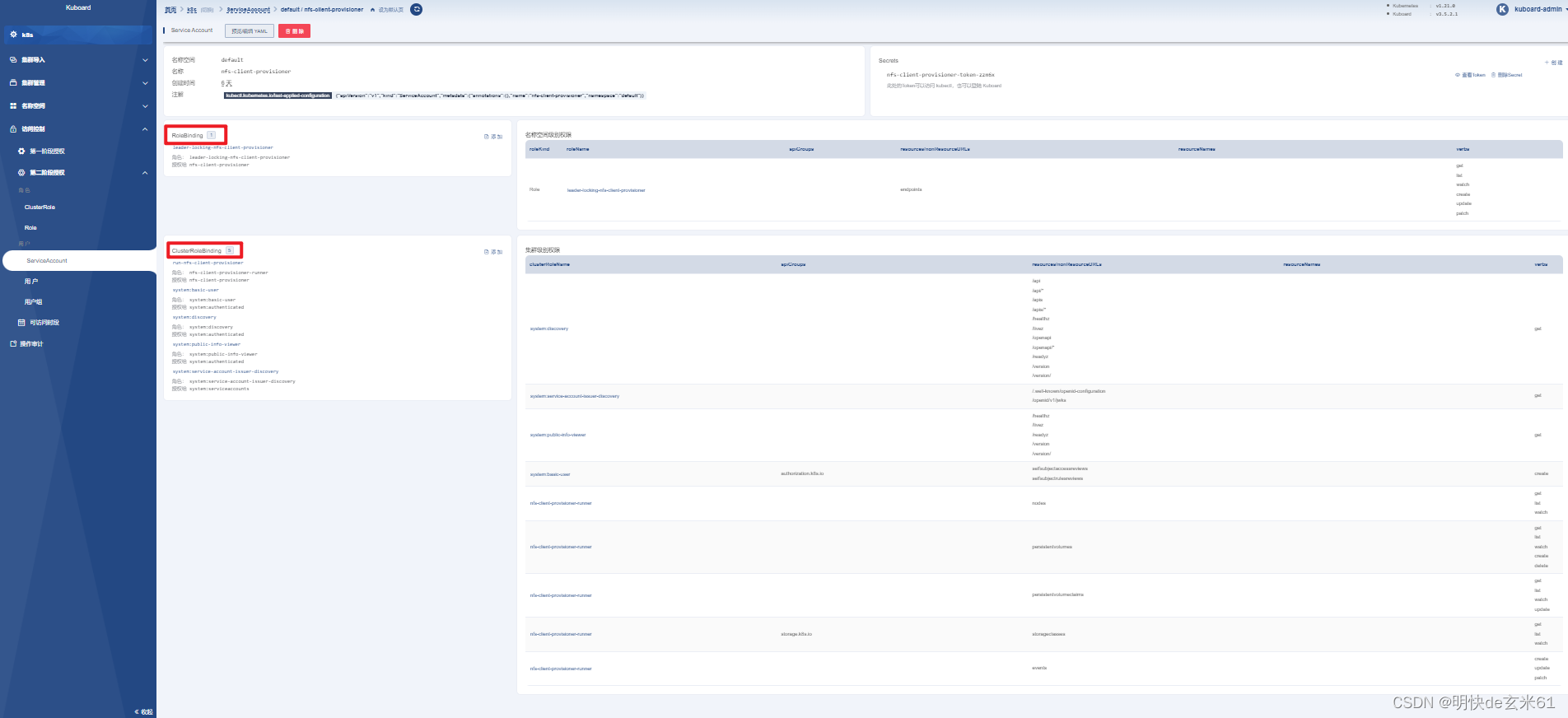
189.2、分析nfs动态挂载的权限
最好去直接看下nfs动态挂载的用户、角色、权限的关联关系配置文件,位置是:85、k8s-集群创建完成》9.2、安装步骤(只用在nfs主节点执行),我们也不慢慢分析了,直接通过kuboard去看吧,这一看权限就很多,如下:
190、k8s安全-如何自己开发一个k8s的可视化平台_1
官方提供的有api文档,如下:

我们可以通过Postman测试api接口,如下:
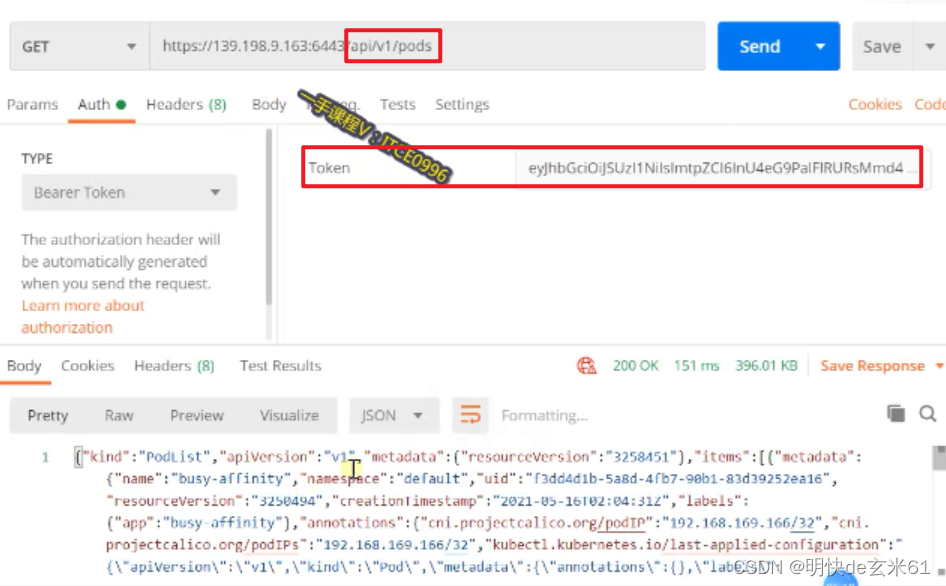
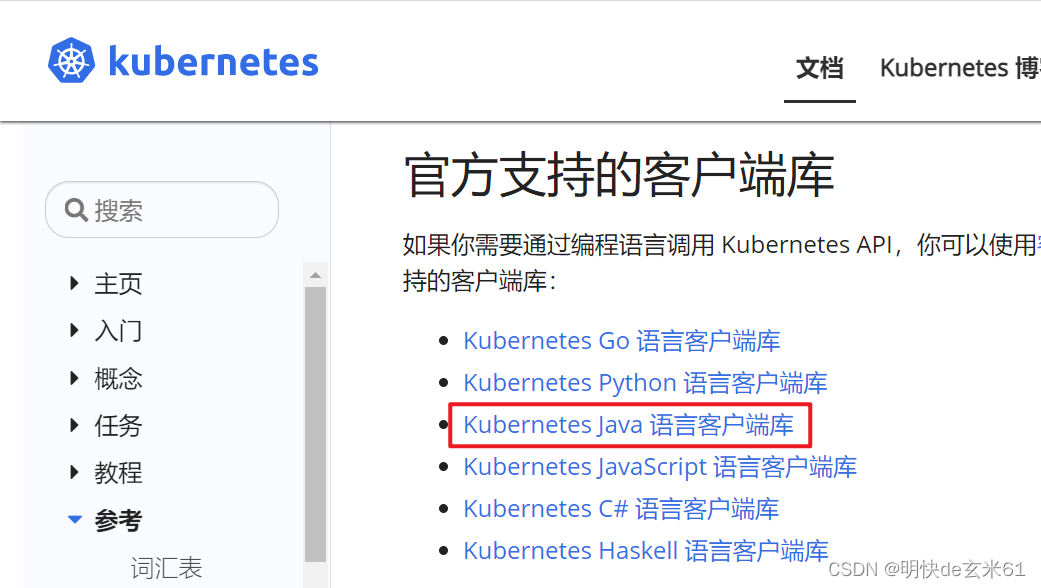
另外我们写java代码的人还可以通过参考文档中的java的sdk开发包去进行集成,如下:
191、k8s安全-补充_1
没补充啥
192、k8s生态-helm应用商店_1
192.1、安装helm
在85、k8s-集群创建完成 》 10、安装helm中已经介绍过了,这里不再赘述
192.2、相关概念
- 官网:https://helm.sh/zh/
- helm命令行:https://helm.sh/zh/docs/intro/using_helm/
- 仓库:https://artifacthub.io/
- 框架图:
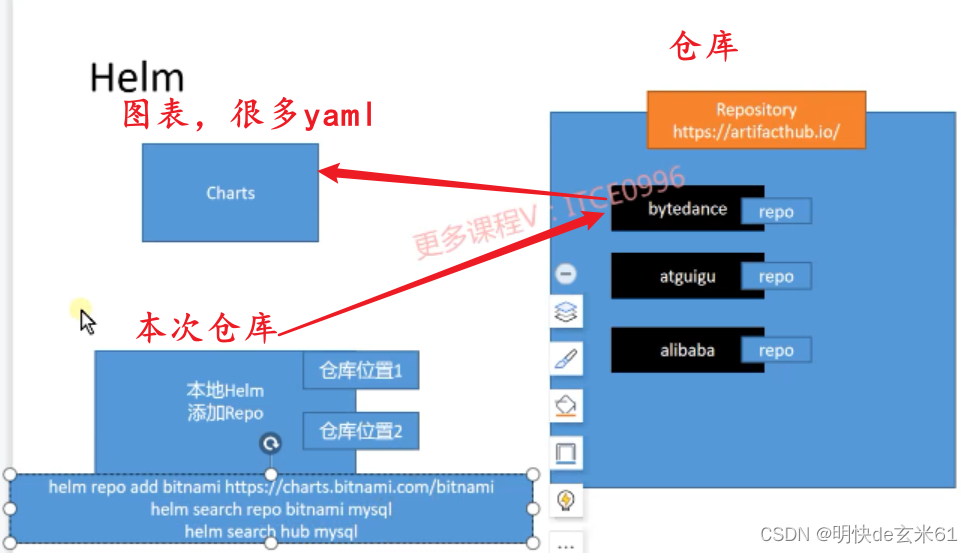
192.3、常用命令
- helm repo add 仓库名称 仓库地址:添加本地仓库,比如:
helm repo add bitnami https://charts.bitnami.com/bitnami会将bitnami仓库添加到本次仓库中 - helm list:查看所有通过helm部署的服务
- helm search hub:从中央仓库搜索可以部署的服务
- helm search repo:从你自己通过
helm repo add命令添加的仓库中搜索,比如bitnami - helm pull 仓库名称/制品名称:比如
helm pull bitnami/mysql,其中制品名称可以从中央仓库中查询,我们可以先去仓库或者通过helm search repo命令观察仓库中是否存在mysql;这下载的是tgz的压缩包,然后将压缩包通过tar -zxvf 压缩包名称进行解压,里面有需要执行的文件 - helm install -f values.yaml helm服务名称 ./:通过helm安装mysql集群,例如:
helm install -f values.yaml mysql-cluster ./ - helm uninstall 服务名称:比如
helm uninstall mysql-cluster就可以把卸载掉,其中服务名称可以通过helm list查找,如下:

192.4、helm pull下载的tgz压缩包内容介绍
- Chart.yaml:元数据描述信息
- templates:k8s中用到的yaml信息,yaml文件中很多用的都是变量名,来自于
values.yaml中 - values.yaml:配置信息,
k8s所有的yaml文件属性值很多都是来自于这里

192.5、安装主从同步的mysql集群
192.5.1、将mysql制品从中央仓库下载下来,并且解压
首先下载命令是helm pull bitnami/mysql
然后通过tar -zxvf XXX.tgz进行解压即可,之后进入解压完成的mysql目录
192.5.1、修改vlaues.yaml
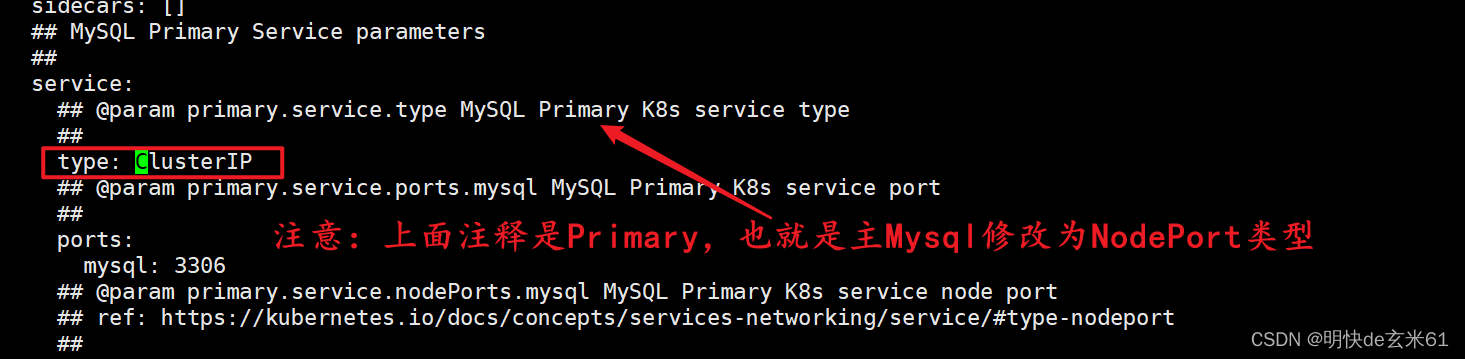
修改第1个service.type为NodePort:
在values.yaml中通过ClusterIP搜索,然后将它改为NodePort,如下:
修改第2个service.type为NodePort:
在values.yaml中通过ClusterIP搜索,然后将它改为NodePort,如下:

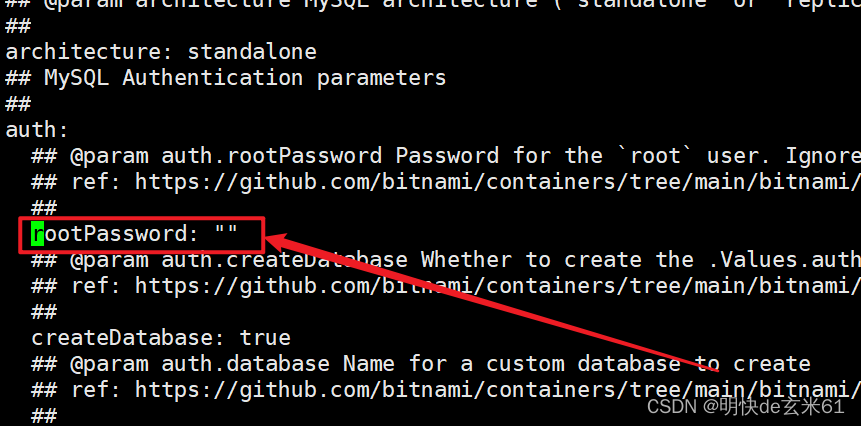
修改数据库密码,比如我修改成了123456
在values.yaml中通过rootPassword搜索,然后把密码修改了,如下:
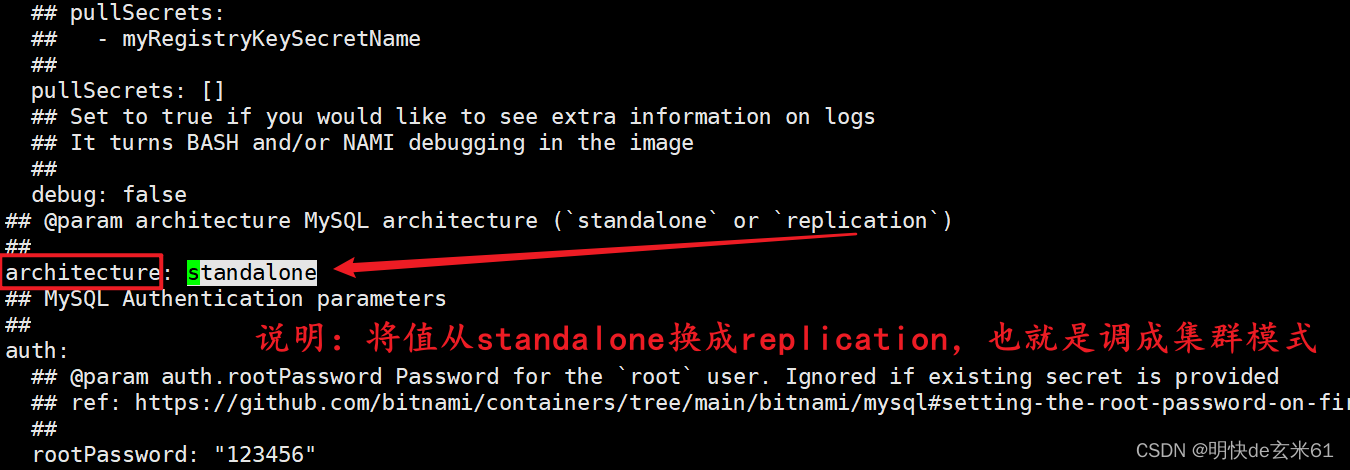
修改数据库模式为集群模式:
在values.yaml中通过standalone搜索,然后把模式修改为replication,如下:
修改上个内容之后,点击下箭头往下滑动一点,然后将副本用户、密码修改了,如下:

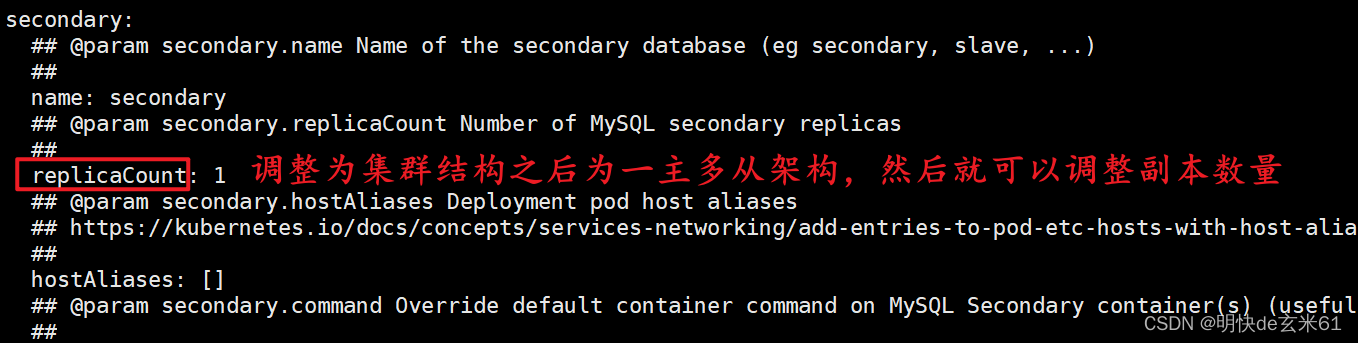
集群模式下调整副本数量:
在values.yaml中通过replicaCount搜索,然后把数量可以调成2,如下:
192.5.2、执行命令
在values.yaml中执行以下命令即可:
# values.yaml:是配置文件名称,这就是上面修改的那个
# mysql-cluster:这是helm应用的名称,也就是通过helm list查看到的名称
helm install -f values.yaml mysql-cluster ./
193、k8s小实验-部署mysql有状态服务_1
193.1、创建名称空间
kubectl create ns mysql
193.2、创建ConfigMap
通过kubectl apply -f XXX.yaml执行以下yaml文件即可
apiVersion: v1
data:
my.cnf: >
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
# 设置client连接mysql时的字符集,防止乱码
init_connect='SET NAMES utf8'
init_connect='SET collation_connection = utf8_general_ci'
# 数据库默认字符集
character-set-server=utf8
#数据库字符集对应一些排序等规则,注意要和character-set-server对应
collation-server=utf8_general_ci
# 跳过mysql程序起动时的字符参数设置 ,使用服务器端字符集设置
skip-character-set-client-handshake
#
禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求!
skip-name-resolve
kind: ConfigMap
metadata:
name: mysql-config
namespace: mysql
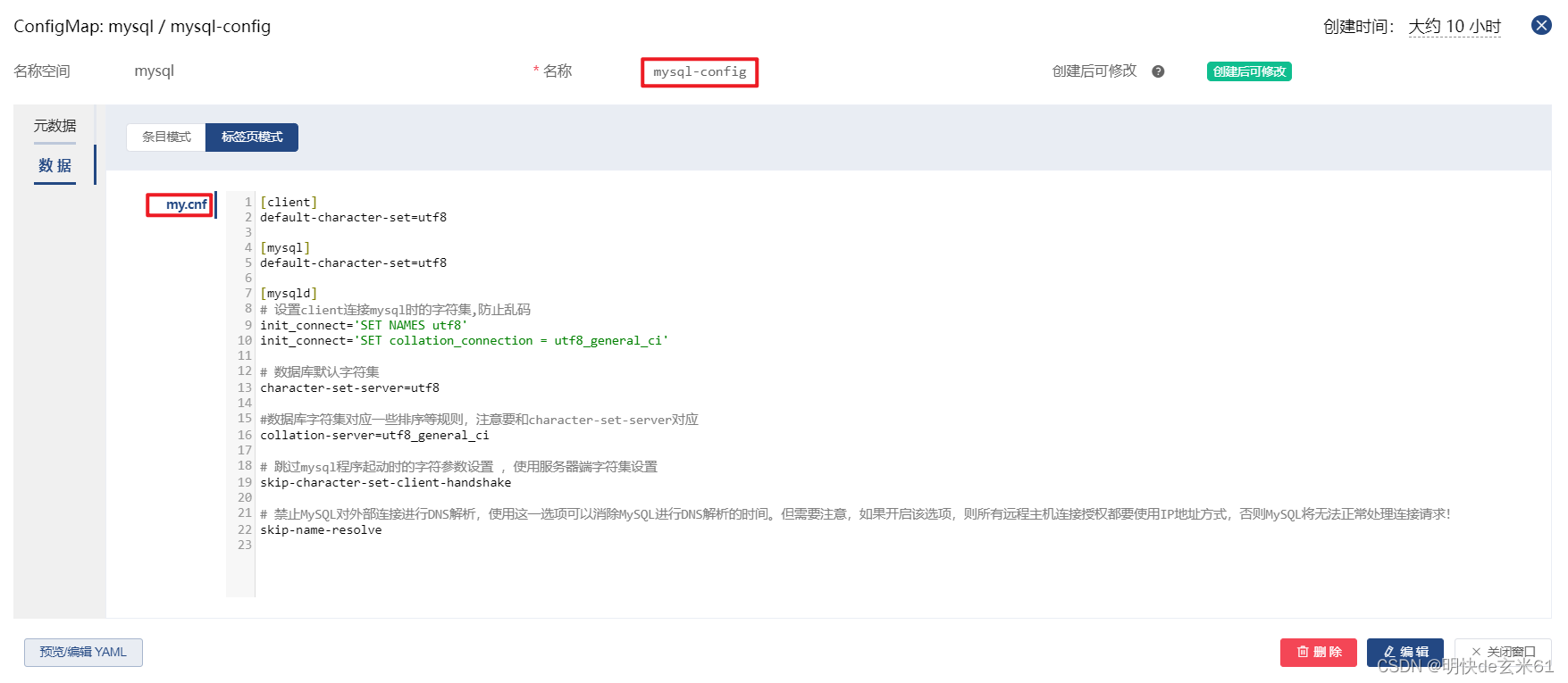
说明: 我们创建了一个ConfigMap配置的目的是把my.cnf配置文件提出来,生成效果如下:
193.3、创建mysql的Service
通过kubectl apply -f XXX.yaml执行以下yaml文件即可
apiVersion: v1
kind: Namespace
metadata:
name: mysql # 创建名称空间
spec: {
}
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
namespace: mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql # 匹配下面spec.template中的labels中的键值对
serviceName: mysql # 一般和service的名称一致,用来和service联合,可以用来做域名访问
template:
metadata:
labels:
app: mysql # 让上面spec.selector.matchLabels用来匹配Pod
spec:
containers:
- env:
- name: MYSQL_ROOT_PASSWORD # 密码
value: "123456"
image: 'mysql:5.7'
livenessProbe: # 存活探针
exec:
command:
- mysqladmin
- '-uroot'
- '-p${MYSQL_ROOT_PASSWORD}'
- ping
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
name: mysql
ports:
- containerPort: 3306 # 容器端口
name: client
protocol: TCP
readinessProbe: # 就绪探针
exec:
command:
- mysqladmin
- '-uroot'
- '-p${MYSQL_ROOT_PASSWORD}'
- ping
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
volumeMounts: # 挂载声明
- mountPath: /etc/mysql/conf.d/my.cnf # 配置文件
name: conf
subPath: my.cnf
- mountPath: /var/lib/mysql # 数据目录
name: data
- mountPath: /etc/localtime # 本地时间
name: localtime
readOnly: true
volumes:
- configMap: # 配置文件使用configMap挂载
name: mysql-config
name: conf
- hostPath: # 本地时间使用本地文件
path: /etc/localtime
type: File
name: localtime
volumeClaimTemplates: # 数据目录使用nfs动态挂载,下面的作用就是指定PVC
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: data # 和上面volumeMounts下面的name=data那个对应
spec:
accessModes:
- ReadWriteMany # 多节点读写
resources:
requests:
storage: 1Gi
storageClassName: managed-nfs-storage # nfs存储类名称
---
apiVersion: v1
kind: Service
metadata:
labels:
app: mysql
name: mysql # 存储类名称
namespace: mysql
spec:
ports:
- name: tcp
port: 3306
targetPort: 3306
nodePort: 32306
protocol: TCP
selector:
app: mysql # Pod选择器
type: NodePort
194、MySQL默认不是主从同步需要自己设置_1
意思是说需要自己去配置主从同步,但是没说具体过程,不看就行了
194~231、自建集群、ceph搭建
目前我还没有自建集群的需要,并且ceph搭建过程中需要外挂磁盘,我这里不满足条件,后续在看吧
232~241、prometheus、harbor仓库搭建
大家直接看k8s笔记(持续更新中)中的二、安装其他组件》4、安装prometheus和grafana和5、安装harbor操作即可,不过也有一点问题,暂时先这样吧,以后在补充,TODO