大模型(LLM) + 上下文检索增强
原创 烛之文 自然语言处理算法与实践 2023-08-01 18:54
收录于合集
#大模型2个
#LLM2个
#大模型检索增强1个
1、背景
在大模型(ChatGpt、LLaMA等)应用落地中,利用【外挂】知识库进行上下文检索增强(In-Context Retrieval-Augmented )来进一步提升LLM效果,这一策略被越来越多的人认可。该策略带来的好处有:
(1)让大模型获取更多的知识,尤其最新的信息,而大模型是无法记住所有的知识;
(2)缓解大模型存在的幻觉问题(类似一本正经的胡说八道),提供外挂信息,可让大模型的输出更有据可循;例如在利用LLM做事件点评时,嵌入事件之间的因果逻辑,能让大模型输出的结果合理性更强;
(3)很多开源的大模型都是通用型的,结合领域的外挂知识库,能让这类大模型在领域问题表现的更好;这也是低成本应用大模型的一种策略;
在知道Retrieval-Augmented+LLM(RALM) 结合带来的好处后,就自然衍生出“怎样检索”、“检索后怎样结合输出”之类的问题。本次分享主要聚焦后者:介绍几种LLM如何利用检索到的内容来输出的方法;
(1)直接放在prompt:这是一种比较简单的操作方式,将检索到与query相关的内容直接放在prompt中,当成一个背景知识交给大模型直接来输出;该方式简洁但结合方式过于粗糙,难以达到精控调节的目的。
(2)KNN+LLM:在推理中,将两个next_token 分布进行融合解码,一个分布来自LLM自身输出,一个是来自检索的top-k token,具体为利用LLM embedding方式在外挂知识库中查找与query token相似的token;该方式存在一个缺陷是需要额外构建一个向量库;
(3)自回归方式检索+解码:思路为先利用LLM解码出部分tokens,然后检索与该tokens相似的文本(文档),然后拼接在prompt中,进行next-tokens预测,这样自回归式的完成解码。该策略对比前两种,好处是能实现更细粒度的检索与融合,且不需要构建向量,或者涉及参数训练等额外工作;
本次分享一篇关于上述第三种策略的paper:<In-Context Retrieval-Augmented Language Models >,提出一种In-Context RALM方法,其整体思路如下图:

图中Prefix可视为LLM解码出来的token片段,Retrieved Evidence是利用token片段检索出来的文本,将其拼在一起,形成新的prompt,然后解码下Suffix token片段,其中绿色标记代表从检索的文本中获取的信息。
2、In-Context RALM
当前LLM基本都是采用自回归的解码方式,其输出的序列
![]()
可以表示为:
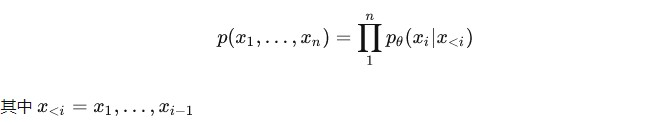
在检索式增强语言模型(Retrieval augmented language models )中,在预测第
![]()
token时,可以利用
![]()
token片段从外挂知识库C中检索出相关文本:
![]()
,这样token
![]()
输出依赖两部分信息:
![]()
,两者信息的融合文中采用简单的拼接方式,即表示为:
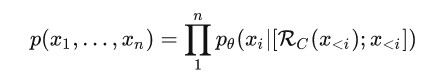
上述公式显示的方式是逐个token来检索+解码,而现在LLM输出的序列都比较长,这种方式无疑加大了推理时间,为了缓解该问题,可有下面两种方式来提高解码速度。
(1)Retrieval Stride:思路不逐个token来检索+解码,而是采用类似滑动窗口的方式多个tokens再去检索,这样上述解码方式就变如下:
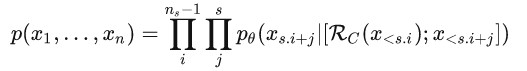
其中s为设置的片段长度,如s=5表示每5个tokens进行检索一次,同时生成后续5个tokens;
![]()
表示片段的个数,也可视为检索的次数,这样对比原始的方式,将检索复杂度从n降低到
![]()
在上述Retrieval Stride策略中,检索的序列
![]()
变成
![]()
,l为控制检索序列的长度�为控制检索序列的长度 ,如此,解码方式如下:
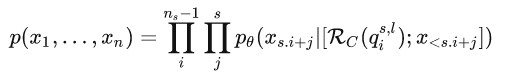
3、实验
文中在5个数据集上验证自己提出的in-context RALM方法,首先通过实验确定片长s和检索长度l的合理值,,结果如下:
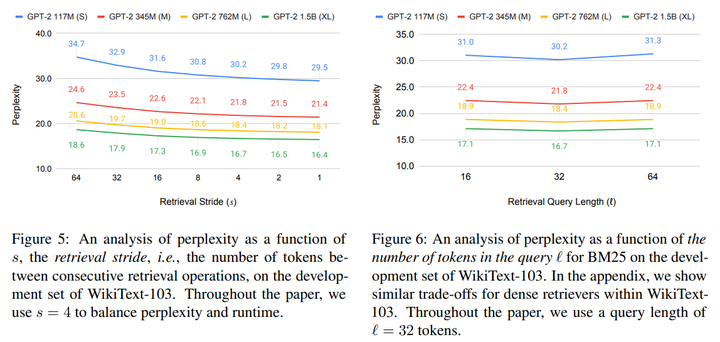
显示s=4,l=32时兼顾了检索效率和效果。
下图显示在OPT系列模型下,利用文中提出检索增强的方式(检索采用BM25的方式),在各个mode size下都能带来增益,在66B大模型,能带来平均1个点的增益,而模型越小,带来的增益越明显,这也跟我们的常识吻合。
不过文中采用BM25这种传统检索方法,应该还有进一步优化的空间,这样检索增强带来的效果更好。此外,文中也没对比提到的KNN+LMM等方法。
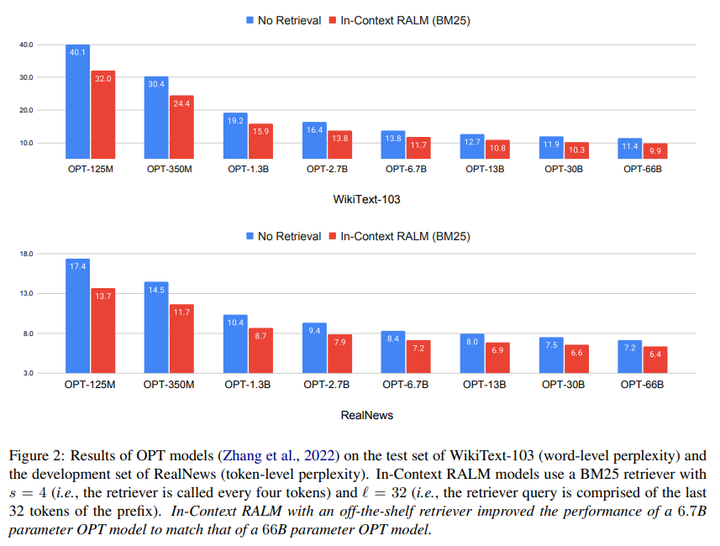
显示在不同大模型下,文中提出检索增强方式不论在token级别还是word级别都能带来增益
4、结语
本次分享了一种检索增强+大模型的融合解码策略,该方法简单有效;当然也存在缺陷,就是提高了推理成本;另外检索只用了生成序列的信息,并没有利用上原始query的信息,二者融合,可能也是一个提升思路。