在Models - Hugging Face模型中找使用方法
一:如何找到统一使用方法
对于文字处理AutoTokenizer是一样的,模型名可能不一样。具体操作如下:
1. 先在模型下面找到你需要的模型点开

2. 点开最右边的Use in Transformers

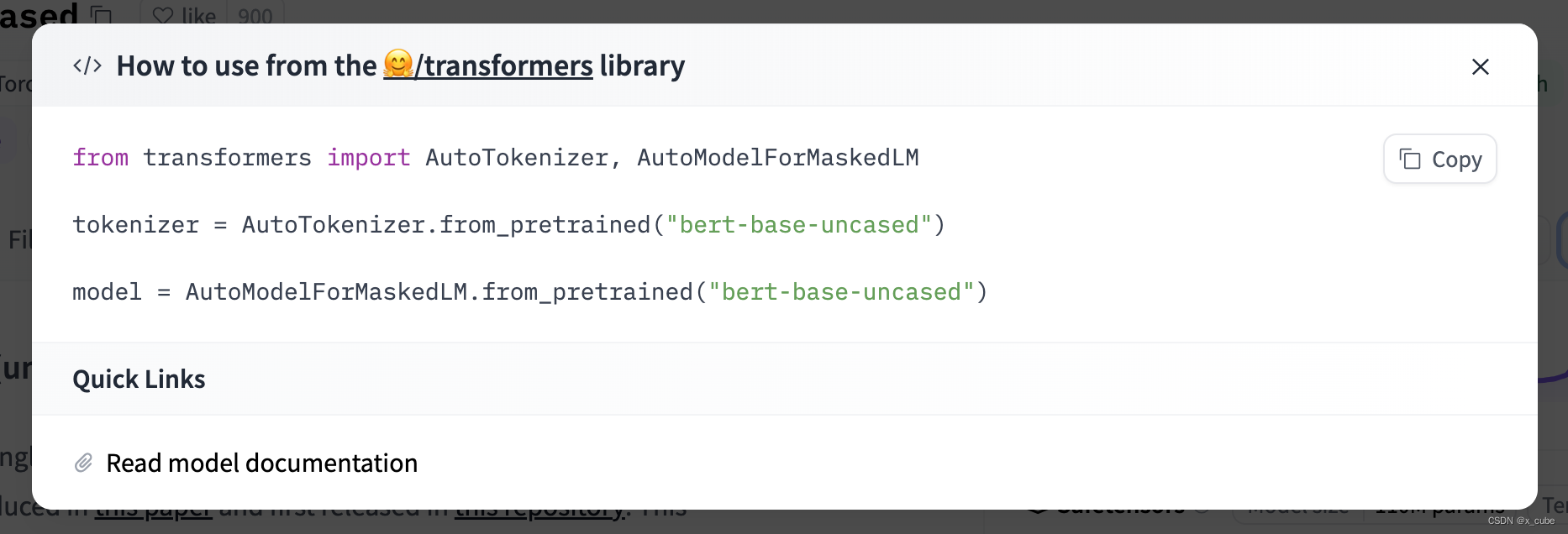
二:如何找到本模型使用方法
滑到底端的如何使用,此为pytorch的使用方法,也有其他的说明。

其中字符串名字可以为路径。
同理,文本操作如下:


专属命名的方法一般是:
分词器命名:"模型名+Tokenizer"
图片处理命名:模型名+ImageProcessor
模型名命名:“ 模型名+Modal”
这个命名和公司有关,还是直接选择自己需要的模型在官网查询使用最好。
三:两种使用方法结果一样
# -------------------- 使用 RobertaTokenizer ---------------
tokenizer = RobertaTokenizer.from_pretrained(pretrained_model_path)
inputs = tokenizer("对比原始的分词和最新的分词器", return_tensors="pt")
print(inputs['input_ids'])
# -------------------- 使用 AutoTokenizer ---------------
auto_tokenizer = AutoTokenizer.from_pretrained(pretrained_model_path) # 使用一样的
auto_inputs = auto_tokenizer('对比原始的分词和最新的分词器', return_tensors='pt')
print(auto_inputs['input_ids'])输出的结果一样。