1 多目标文件的链接
现在我们把例子拆成两个.c文件,stack.c实现堆栈,而main.c使用堆栈:
/* stack.c */
char stack[512];
int top = -1;
void push(char c)
{
stack[++top] = c;
}
char pop(void)
{
return stack[top--];
}
int is_empty(void)
{
return top == -1;
}
在这段程序中top总是指向栈顶元素,所以要初始化成-1才表示空堆栈,这两种堆栈使用习惯都很常见。
/* main.c */
#include <stdio.h>
int a, b = 1;
int main(void)
{
push('a');
push('b');
push('c');
while(!is_empty())
putchar(pop());
putchar('\n');
return 0;
}
a和b这两个变量没有用,只是为了顺便说明链接过程才加上的。编译的步骤和以前一样,可以一步编译:
$ gcc main.c stack.c -o main
也可以分多步编译:
$ gcc -c main.c
$ gcc -c stack.c
$ gcc main.o stack.o -o main
如果用nm命令查看目标文件的符号表,会发现main.o中有未定义的符号push、pop、is_empty、putchar,前三个符号在stack.o中定义了,在链接时做符号解析,而putchar是libc的库函数,在可执行文件main中仍然是未定义的,要在程序运行时做动态链接。
通过readelf -a main命令可以看到:main的.bss段合并了main.o和stack.o的.bss段,其中包含了变量a和stack;main的.data段合并了main.o和stack.o的.data段,其中包含了变量b和top;main的.text段合并了main.o和stack.o的.text段,包含了各函数的指令,如图所示。
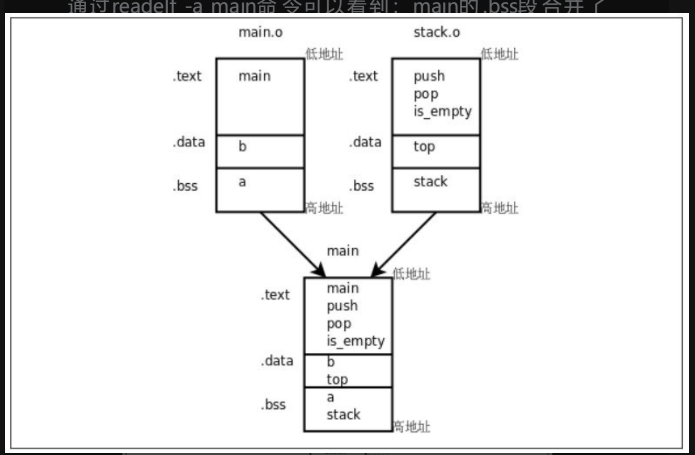
结果正如我们所预料,可执行文件main的每个段中来自main.o的变量或函数都排到后面了。
实际上链接过程是由一个链接脚本(Linker Script)控制的,链接脚本决定了给每个段分配什么地址,如何对齐,哪个段在前,哪个段在后,哪些段合并到同一个Segment。
另外链接脚本还要把一些特殊地址定义成符号,例如__bss_start代表.bss段的起始地址,_end代表.bss段的结束地址,这些符号会出现在可执行文件的符号表中,加载器可以由这些符号得知.bss段的地址范围,以便把它清零。
如果用ld做链接时没有通过-T选项指定链接脚本,则使用ld的默认链接脚本,默认链接脚本可以用ld --verbose命令查看(由于比较长,只列出一些片断):
$ ld --verbose
...
using internal linker script:
==================================================
/* Script for -z combreloc: combine and sort reloc sections */
OUTPUT_FORMAT("elf32-i386", "elf32-i386",
"elf32-i386")
OUTPUT_ARCH(i386)
ENTRY(_start)
SEARCH_DIR("/usr/i486-linux-gnu/lib32");SEARCH_DIR("/usr/local/lib32"); SEARCH_DIR("/lib32"); SEARCH_DIR("/usr/lib32"); SEARCH_DIR("/usr/i486-linux-gnu/lib"); SEARCH_DIR("/usr/local/lib"); SEARCH_DIR("/lib"); SEARCH_DIR("/usr/lib");
SECTIONS
{
/* Read-only sections, merged into text segment: */
PROVIDE (__executable_start = SEGMENT_START("text-segment",
0x08048000)); . = SEGMENT_START("text-segment", 0x08048000) + SIZEOF_HEADERS;
.interp : { *(.interp) }
.note.gnu.build-id : { *(.note.gnu.build-id) }
.hash : { *(.hash) }
.gnu.hash : { *(.gnu.hash) }
.dynsym : { *(.dynsym) }
.dynstr : { *(.dynstr) }
.gnu.version : { *(.gnu.version) }
.gnu.version_d : { *(.gnu.version_d) }
.gnu.version_r : { *(.gnu.version_r) }
.rel.dyn :
...
.rel.plt :
...
.init :
...
.plt : { *(.plt) *(.iplt) }
.text :
...
.fini :
...
.rodata : { *(.rodata .rodata.* .gnu.linkonce.r.*) }
...
.eh_frame : ONLY_IF_RO { KEEP (*(.eh_frame)) }
...
/* Adjust the address for the data segment. We want to adjust up to
the same address within the page on the next page up. */
. = ALIGN (CONSTANT (MAXPAGESIZE)) - ((CONSTANT (MAXPAGESIZE) - .)
& (CONSTANT (MAXPAGESIZE) -1)); . = DATA_SEGMENT_ALIGN (CONSTANT(MAXPAGESIZE), CONSTANT (COMMONPAGESIZE));
...
.ctors :
...
.dtors :
...
.jcr : { KEEP (*(.jcr)) }
...
.dynamic : { *(.dynamic) }
.got : { *(.got) *(.igot) }
...
.got.plt : { *(.got.plt) *(.igot.plt) }
.data :
...
_edata = .; PROVIDE (edata = .);
__bss_start = .;
.bss :
...
_end = .; PROVIDE (end = .);
. = DATA_SEGMENT_END (.);
/* Stabs debugging sections. */
...
/* DWARF debug sections.
Symbols in the DWARF debugging sections are relative to the
beginning
of the section so we begin them at 0. */
...
}
==================================================
ENTRY(_start)指明整个程序的入口点是_start,这并不是规定死的,修改链接脚本就可以改用其他符号做入口点。
/* Read-only sections, merged into text segment: */
PROVIDE (__executable_start = SEGMENT_START("text-segment",
0x08048000)); . = SEGMENT_START("text-segment", 0x08048000) +
SIZEOF_HEADERS;
.interp : { *(.interp) }
.note.gnu.build-id : { *(.note.gnu.build-id) }
...
PROVIDE (__executable_start = SEGMENT_START(“text-segment”, 0x08048000));语句导出一个GLOBAL的符号__executable_start,它的值是Text Segment的起始地址(默认值是0x8048000)。
再看. = SEGMENT_START(“text-segment”, 0x08048000) +SIZEOF_HEADERS;这一句。“.”表示当前链接地址,即程序加载运行时的虚拟地址,链接器每组装一个段就把当前链接地址自动加上这个段的长度,因此各段在加载时一般是紧挨着的,中间没有空隙,
只有一种情况例外:如果在链接脚本中给“.”赋值,那么链接器组装下一个段就从赋值的新地址开始,而不是和前一个段紧挨着了。
所以这条语句表示把当前链接地址改成Text Segment的起始地址加上SIZEOF_HEADERS偏移量,后面的段从这里开始组装,后面的段依次是.interp段、.note.gnu.build-id段等(其中包括我们熟悉的.plt段、.text段和.rodata段),这些段都被组装到Text Segment中。
每个段的描述格式都是“段名 : { 组成 }”,例如.plt : { *(.plt) *(.iplt) },左边表示链接生成的文件的.plt段,右边表示所有目标文件的.plt段和.iplt段,意思是链接生成的文件的.plt段由各目标文件的.plt段和.iplt段组成。
组装完Text Segment之后又给当前链接地址赋了新值,从新的虚拟地址开始组装Data Segment:
/* Adjust the address for the data segment. We want to adjust up to
the same address within the page on the next page up. */
. = ALIGN (CONSTANT (MAXPAGESIZE)) - ((CONSTANT (MAXPAGESIZE) - .)
& (CONSTANT (MAXPAGESIZE) -1)); . = DATA_SEGMENT_ALIGN (CONSTANT
(MAXPAGESIZE), CONSTANT (COMMONPAGESIZE));
...
计算Data Segment的起始地址要做一系列对齐操作,可以结合图来理解,Data Segment从Text Segment的下一个页面开始,并且不是从该页面的起始地址开始,而是有一个偏移量。
上面这两个表达式的详细计算过程我们就不深入讨论了。计算出当前地址之后,从该地址开始组装链接脚本后面列出的几个段,例如.data段、.bss段等。
组装完Data Segment之后又给当前链接地址赋了新值,从新的虚拟地址开始组装调试信息等其他Segment:
. = DATA_SEGMENT_END (.);
/* Stabs debugging sections. */
...
/* DWARF debug sections.
Symbols in the DWARF debugging sections are relative to the
beginning
of the section so we begin them at 0. */
...
关于链接脚本就介绍这么多。
从现在开始我们写的很多程序都是由多个.c文件编译链接在一起的,在gdb调试时如何指定某个.c文件中的某一行代码呢?现在我们调试这个程序,在push函数和pop函数里设断点,注意gdb命令的写法。
$ gcc stack.c main.c -g -o main
$ gdb main
GNU gdb (GDB) 7.1-ubuntu
Copyright (C) 2010 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i486-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /home/akaedu/main...done.
(gdb) l
1 /* main.c */
2 #include <stdio.h>
3
4 int a, b = 1;
5
6 int main(void)
7 {
8 push('a');
9 push('b');
10 push('c');
(gdb) l stack.c:1
1 /* stack.c */
2 char stack[512];
3 int top = -1;
4
5 void push(char c)
6 {
7 stack[++top] = c;
8 }
9
10 char pop(void)
(gdb) b push
Breakpoint 1 at 0x80483f0: file stack.c, line 7.
(gdb) b stack.c:10
Breakpoint 2 at 0x8048411: file stack.c, line 10.
(gdb) r
Starting program: /home/akaedu/main
Breakpoint 1, push (c=97 'a') at stack.c:7
7 stack[++top] = c;
(gdb) c
Continuing.
Breakpoint 1, push (c=98 'b') at stack.c:7
7 stack[++top] = c;
(gdb) c
Continuing.
Breakpoint 1, push (c=99 'c') at stack.c:7
7 stack[++top] = c;
(gdb) c
Continuing.
Breakpoint 2, pop () at stack.c:12
12 return stack[top--];
在gdb命令中指定某个.c文件中的某一行或某个函数,可以用“文件名:行号”或“文件名:函数名”的语法。