文章目录
1、简介
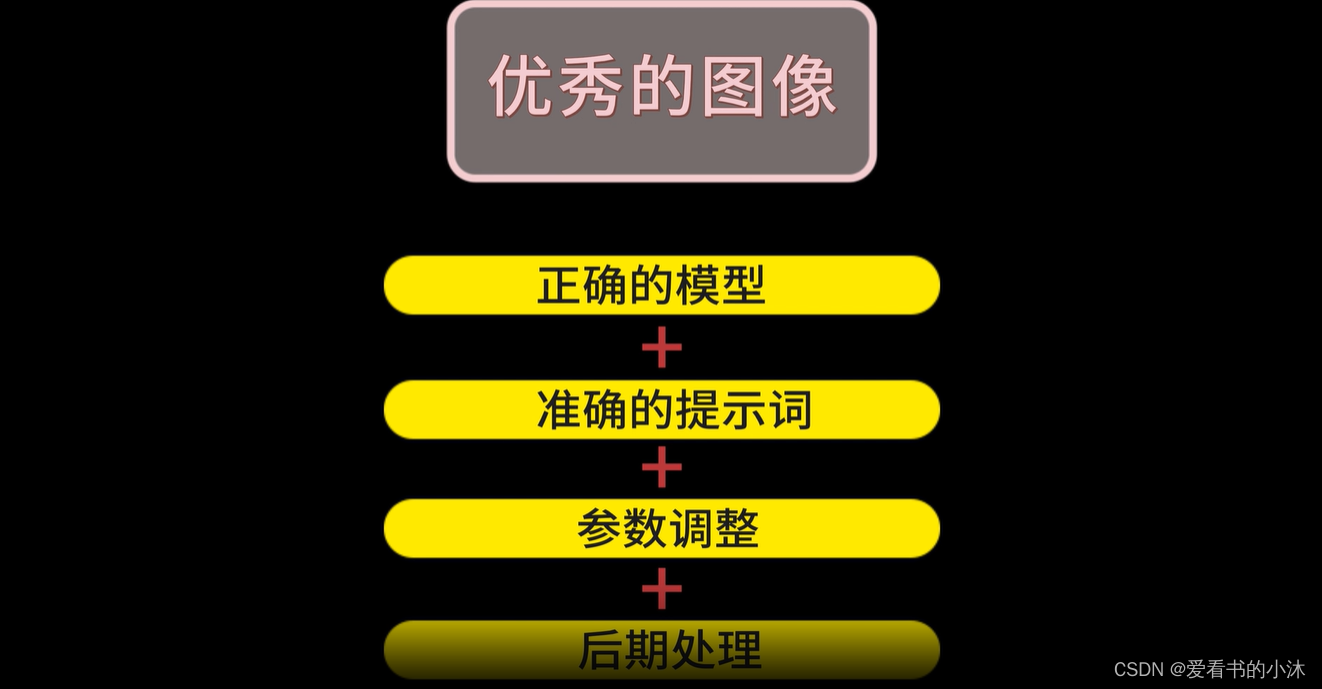
Stable Diffusion是一种强大的图像生成AI,它可以根据输入的文字描述词(prompt)来绘制图像。在Stable Diffusion上完成优秀图像的制作需要有正确的模型+准确的提示词+参数调整+后期处理技术。
网易云课堂云课堂stable diffusion上线。
1.1 参与方式
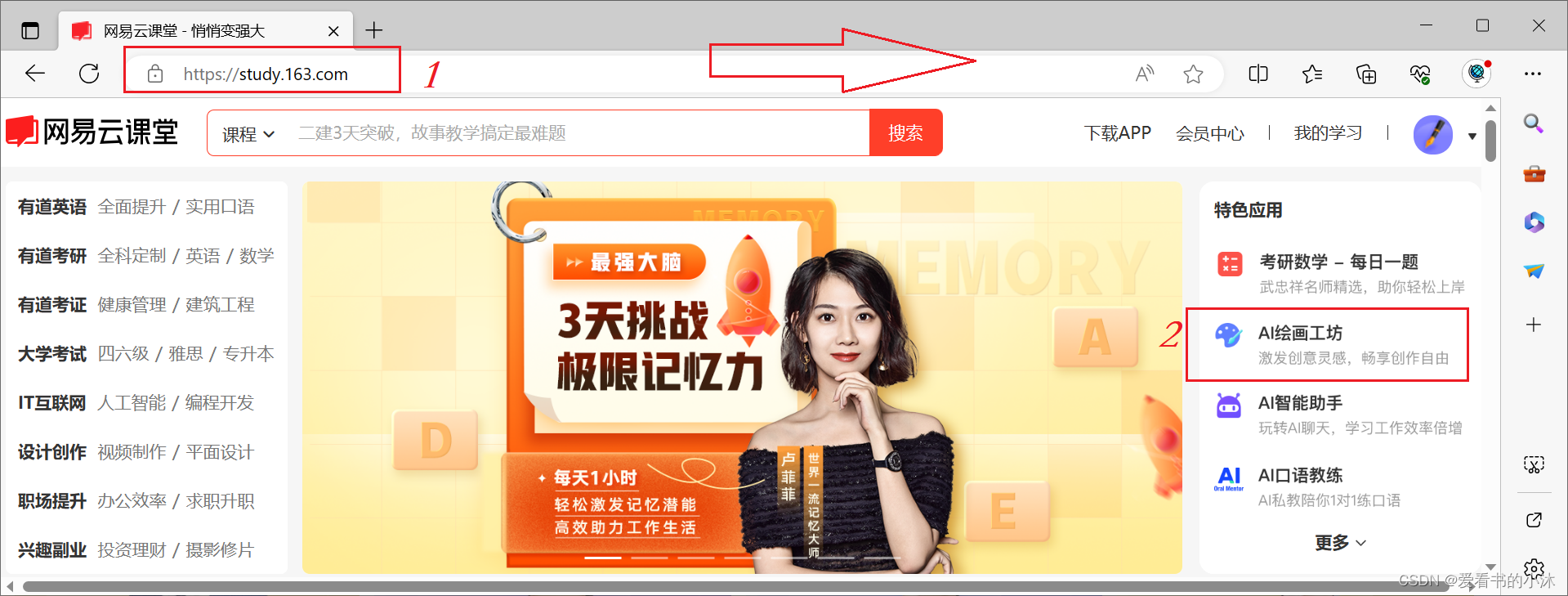
- 参与方式一
① 进入网易云课(https://study.163.com/ )
② 点击AI绘画工坊
③ 进入云课堂Stable Diffusion
④ 开始创作
https://study.163.com/
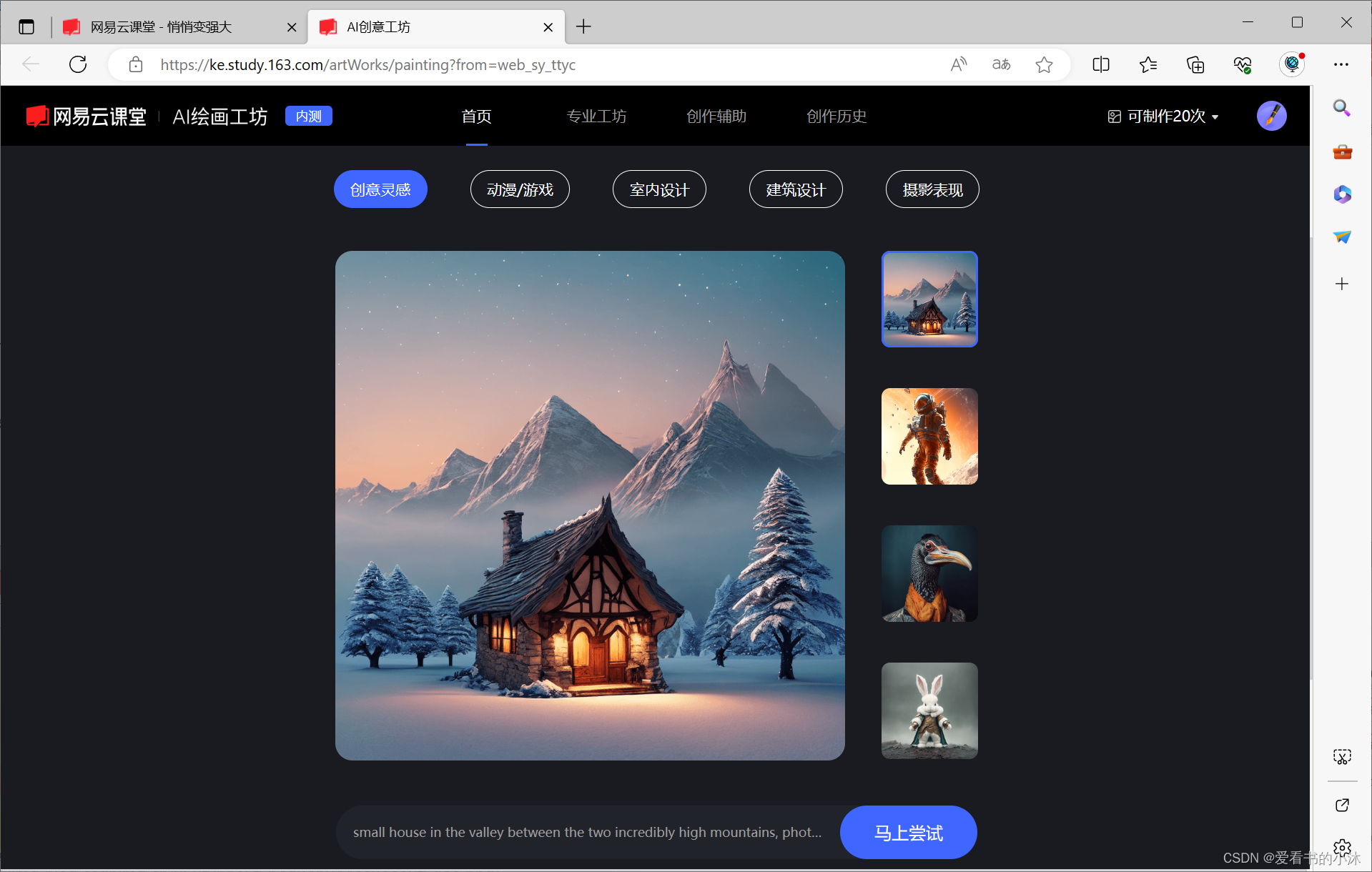
- 参与方式二
电脑端复制下方链接到网址栏,一键进入云课堂Stable Diffusion
https://ke.study.163.com/artWorks/painting?from=web_gzh
1.2 模型简介
Stable Diffusion官方会提供SD模型(目前更新到Stable Diffusion 2.1-v)。除此之外,我们也可以从Civitai上面获取模型。Civitai是目前一个比较成熟的Stable Diffusion模型社区,里面拥有几千个模型,以及数十万张附带提示词的图像,这些都让Stable Diffusion的学习成本降低了很多。
我们目前使用比较多的主要包括2类模型:大模型、微调模型
- 大模型:常见的大模型一般为Checkpoint(ckpt)和safetensors两种格式,大模型一般是通过Dreambooth训练得到,特点是出图效果好,但是由于训练的是一个完整的新模型,所以训练速度普遍偏慢,生成模型的文件较大,一般都在几个G。
- 微调模型:微调模型需要配合大模型使用,常见包括Embedding模型、Hypernetwork模型、Lora模型、VAE模型(常用的是Embedding和Lora模型)。
- Embedding模型:主要用于定义新关键字来生成新的对象或风格的小文件(图像风格引导)。不会改变模型,只是定义新的关键字来实现某些样式。
- LoRA模型:简单理解就是大模型的补丁,可以用于修改图像风格/增加细节。因为效果很好并且训练较为快速和简单,所以性价比最高,也是目前最常用的微调模型。
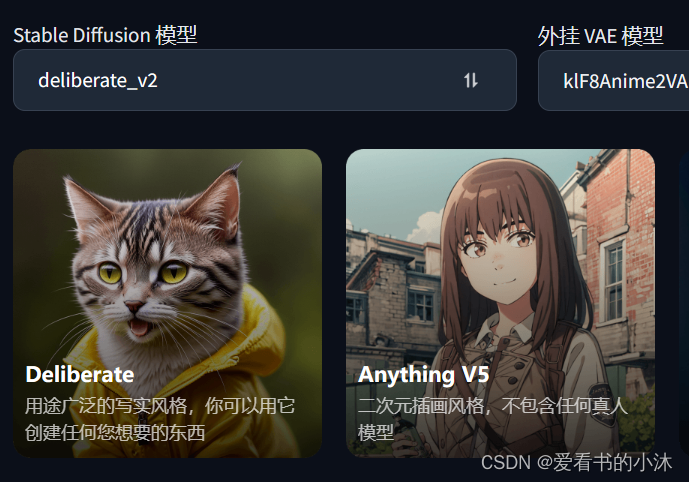
Deliberate
C站链接:https://civitai.com/models/4823/deliberate
模型说明:胜任多种风格,可以创建任何想要的东西,我们也将它称为万能模型。
Anything V5
C站链接:https://civitai.com/models/9409/or-anything-v5
模型说明:Anything V5 是一个以二次元漫画为主打的模型,具备非常好的出图效果,并且对关键词的要求并不高,但是风格呈现比较单一。
ChilloutMix
C站链接:https://civitai.com/models/6424/chilloutmix
模型说明:该模型最大的特点就是可以画出超级逼真、超级写实的亚洲人像(有可能你在某些平台上看见的小姐姐图片都是这个模型做出来的哦)。
Henmix_real写实人像
C站链接:https://civitai.com/models/20282/henmixreal
模型说明:使用该模型可以生成非常有质感的写实人像照片。
ReV Animated
C站链接:https://civitai.com/models/7371?modelVersionId=46846
模型说明:该模型特别适合进行动漫人物或者场景的2.5D/3D的绘制。
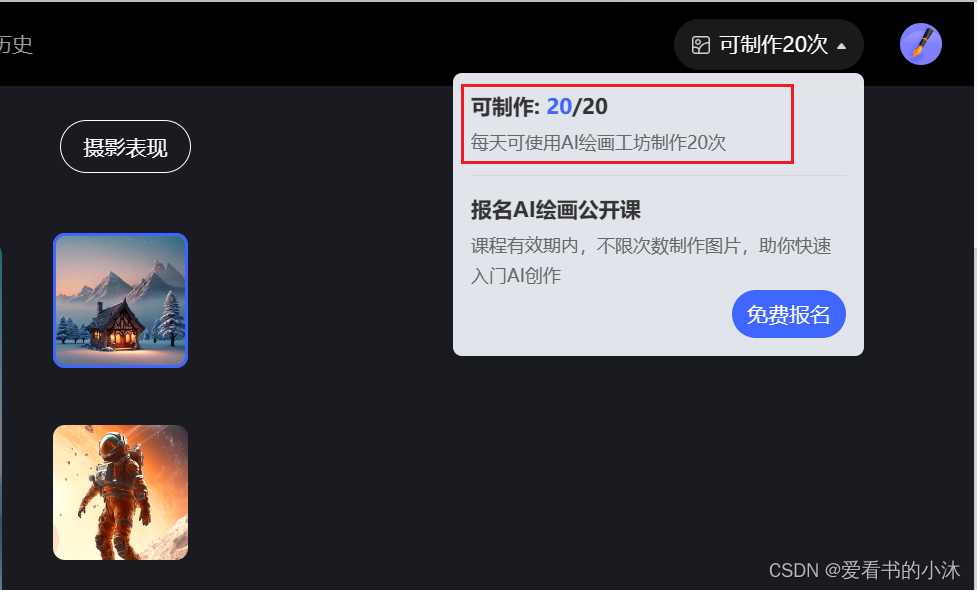
2、使用费用
每天可使用AI绘画工坊制作20次!!!
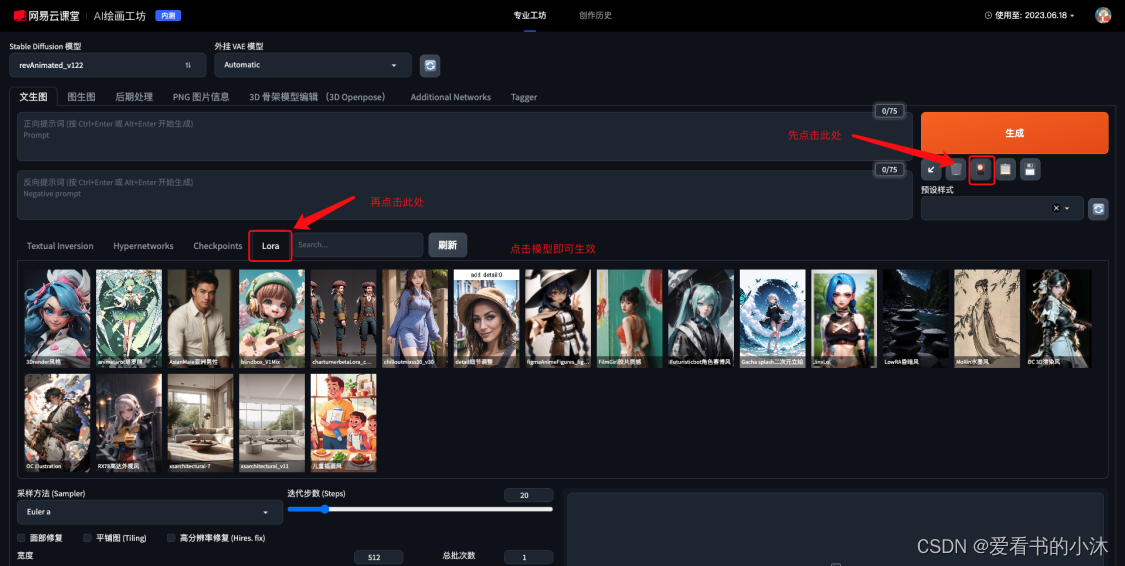
3、操作步骤
一般AI绘画步骤有这几个:选择模型,输入提示词,调整参数,后期处理等。
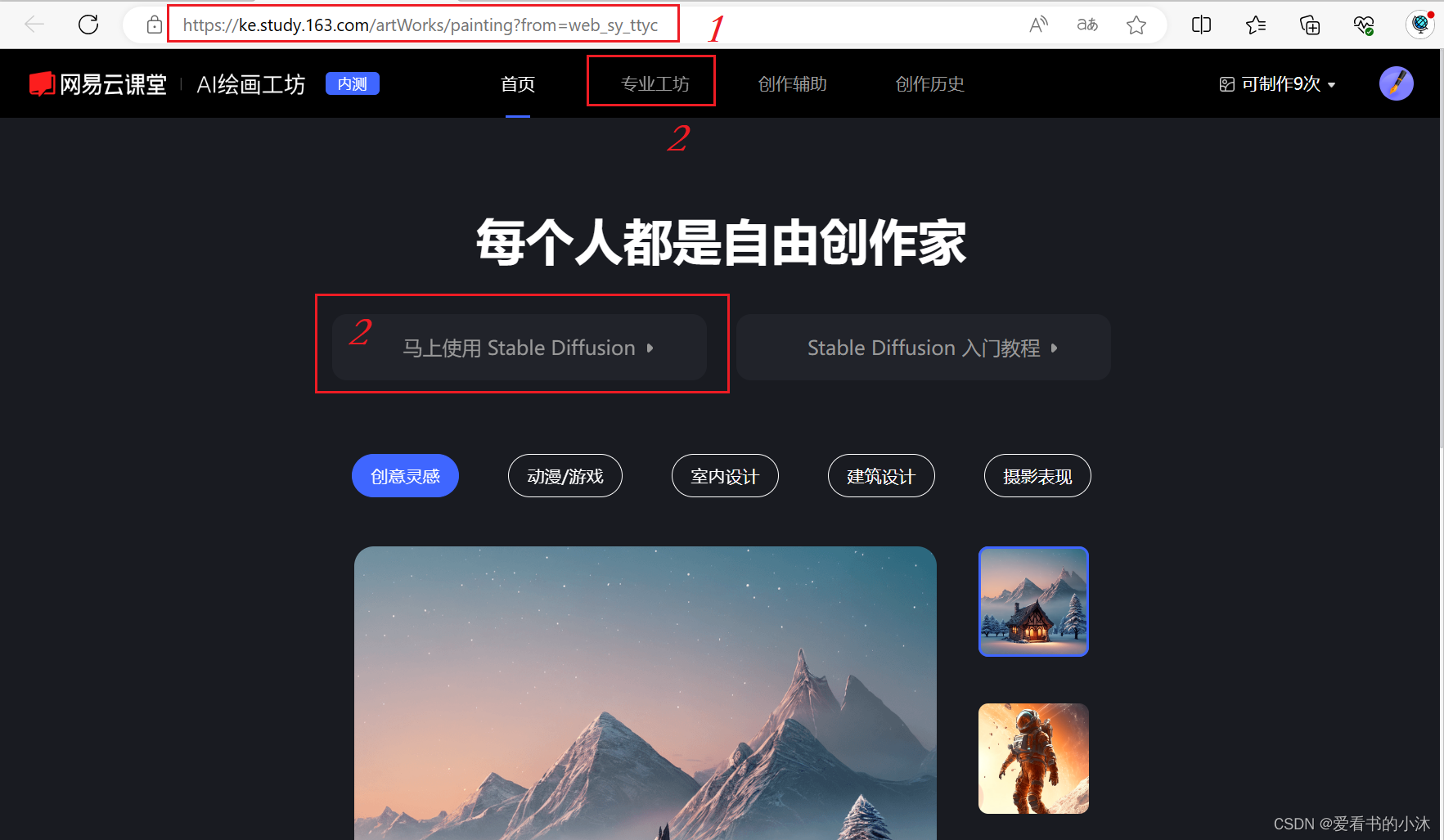
首先进入官网网址,如下:
https://ke.study.163.com/artWorks/painting?from=web_sy_ttyc
3.1 选择模型
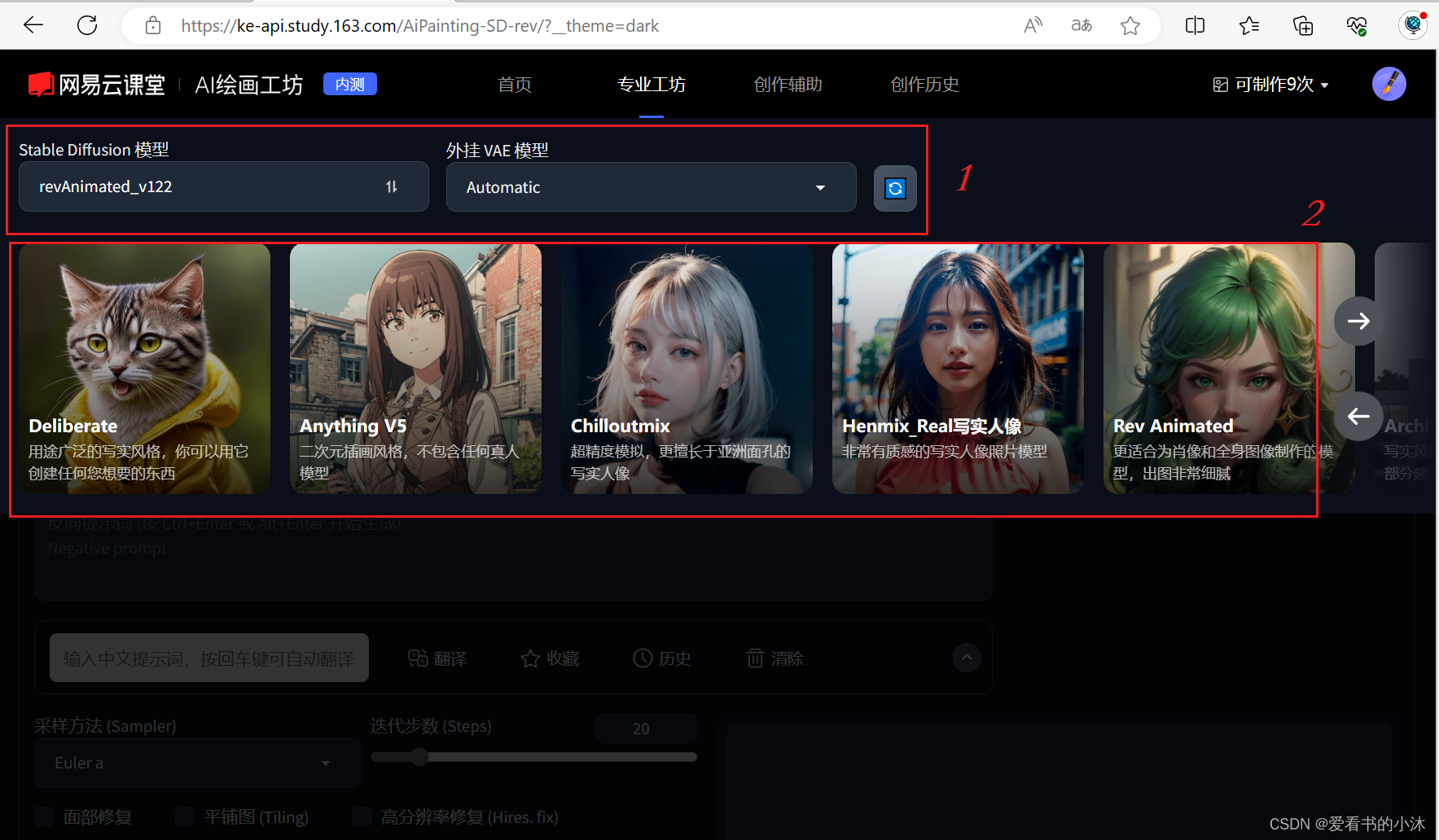
- 这里我们选择模型 “Anything V5”。
3.2 输入提示词
-
正向提示词:
-
反向提示词:
-
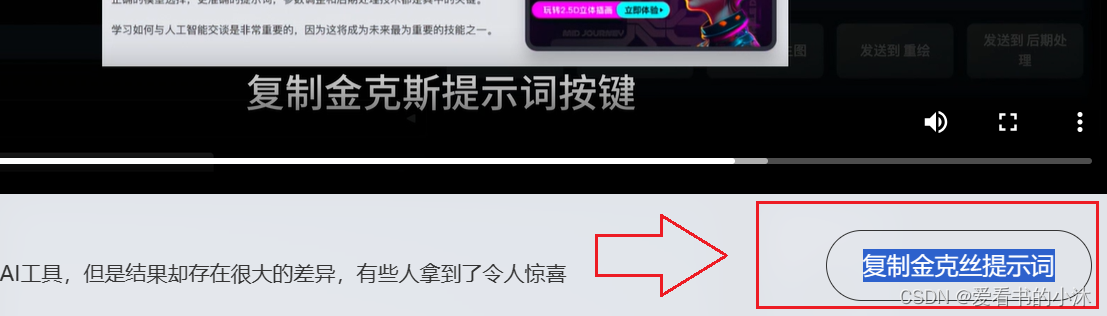
(1)这里我们复制一下官网上提供的提示词,点击那个按钮“复制金克丝提示词”。
-
(2)复制到正向提示词文本框中

-
(3)然后点击下图中的那个按钮“”,一键扩展上面输入的信息。

-
(4)接着相关控件里的内容自动更新如下:
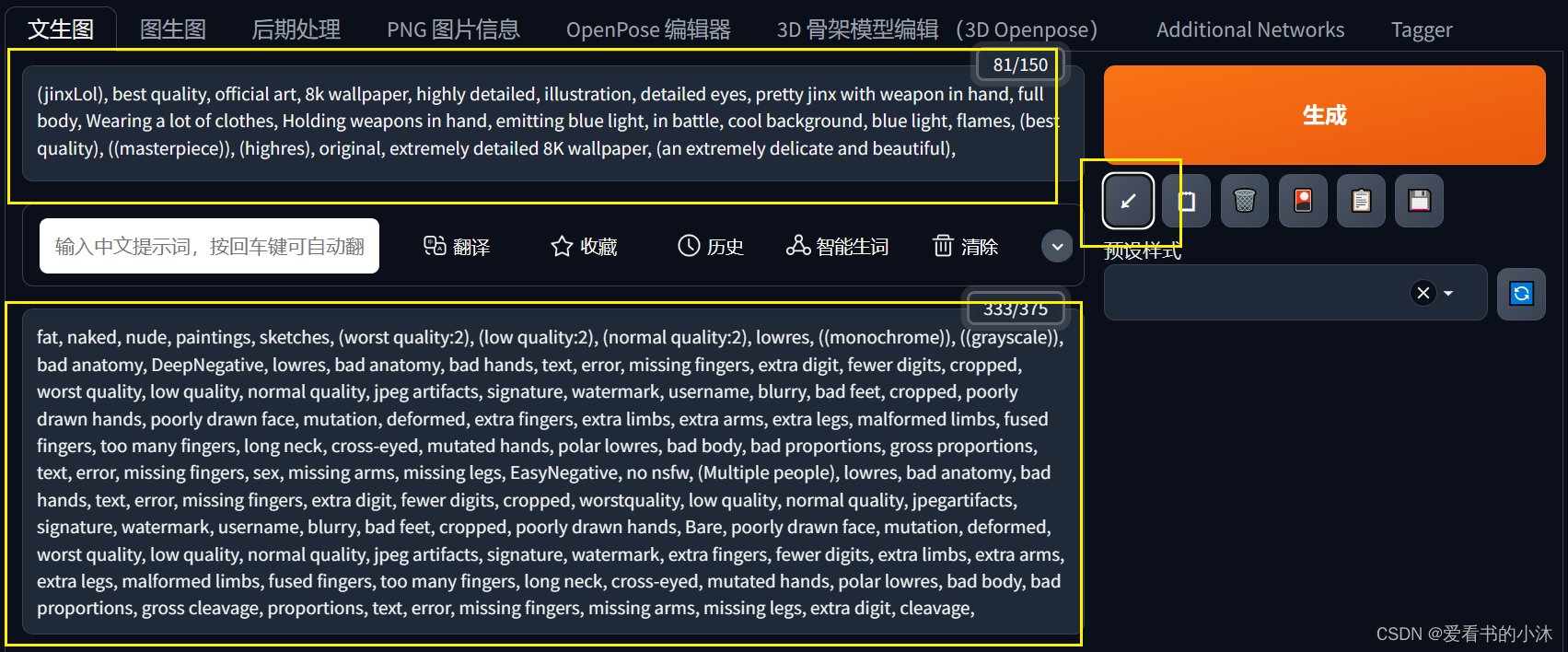
-
(5)然后点击下图的按钮,选择网易云中给大家准备的金克丝Lora模型:
-
(6)Lora模型界面显示如下,选择一个之后:
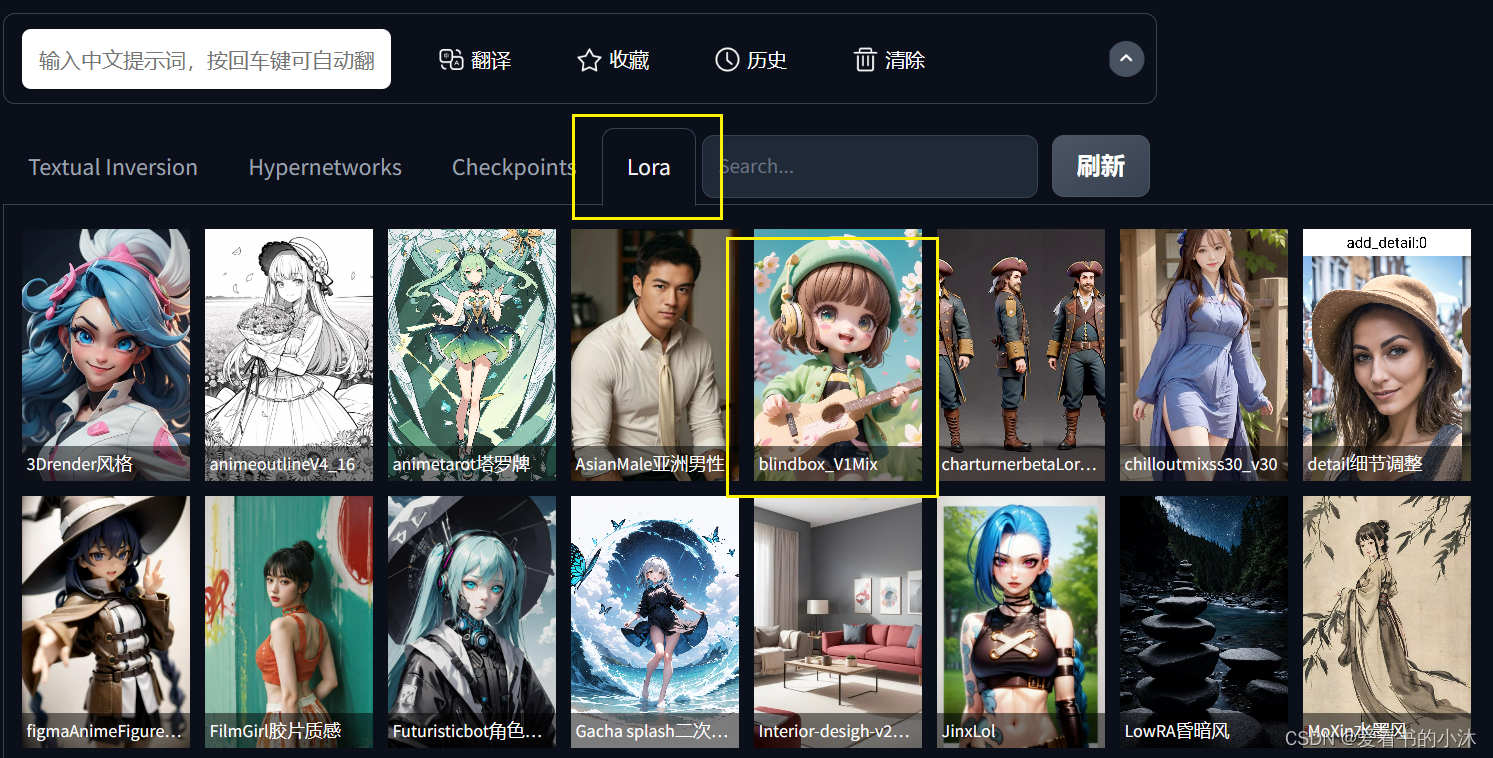
-
(6)点击按钮“生成”,进行生成结果图片。
3.3 调整参数
3.4 图片生成

4、测试例子
提问法制作Prompt:
问题》》》确定prompt
想生成的图像是照片还是画作呢? 》》》画作(Painting)
主题是什么?人物?动物?风景? 》》》小狗(a cute dog)
灯光上面的细节?柔和的?环境光?霓虹灯?》》》自然光(natural light,)
环境上面的细节?室内?室外?水下?》》》在天空中(in the sky)
色彩方案呢?鲜艳的?昏暗的?柔和色调?》》》明亮色彩(bright colors)
画面风格?3D渲染?吉卜力工作室?电影海报?》》》新海诚(by Makoto Shinkai)
4.1 小狗
- 模型:
ReV Animated
- 提示词:
A painting of a cute dog,natural light,in the sky,with bright colors by Makoto Shinkai

4.2 蜘蛛侠
- 模型:
ReV Animated
- 提示词:
Crochet doll of Spiderman, studio lighting

4.3 人物
- 模型:
ReV Animated
- 提示词:
Pencil painting of Emma Watson

4.4 龙猫
- 模型:
ReV Animated
- 提示词:
A cute totoro in a yard, bokeh

结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!