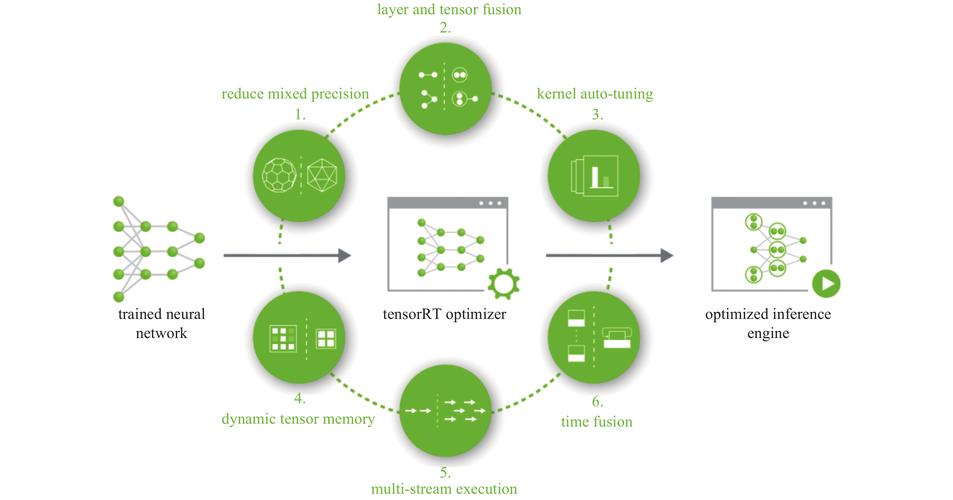
深度学习在图像处理领域取得了重大的突破,可以用于图像分类、目标检测、图像生成等各种任务。处理图像数据的关键是将图像转换为适合深度学习模型处理的形式。下面是处理图像数据的一般步骤:


1.数据准备:
- 收集和整理用于训练的图像数据集。数据集应包含图像文件和对应的标签或注释信息。将数据集分为训练集、验证集和测试集,并进行标记化和预处理。
2.数据预处理:
- 对图像进行预处理操作,如调整图像大小、裁剪、旋转、翻转等。还可以进行图像增强操作,如平移、缩放、亮度调整等,以扩充训练数据集。对图像进行归一化处理,将像素值映射到特定的范围,如[0, 1]或[-1, 1]。
3.数据增强:
- 在训练过程中,使用数据增强技术增加数据样本的多样性。常用的数据增强方法包括随机裁剪、旋转、缩放、平移、加噪声等,以提高模型的鲁棒性和泛化能力。
4.特征提取:
- 使用卷积神经网络(CNN)进行特征提取。通过堆叠卷积层和池化层,逐渐减小特征图的尺寸并增加通道数,提取图像的局部和全局特征。常用的CNN模型包括LeNet、AlexNet、VGG、ResNet等。
5.模型训练:
- 定义损失函数,如交叉熵损失函数,用于衡量模型预测结果与真实标签之间的差异。选择适当的优化器,如Adam、SGD等,通过反向传播算法更新模型参数。通过迭代训练过程来优化模型,减小损失函数的值。
6.模型评估:
- 使用验证集和测试集评估模型性能。常用的评估指标包括准确率、精确率、召回率、F1分数等。根据评估结果调整模型结构、参数设置或训练策略,以提高模型的准确性和泛化能力。
-
感谢大家对文章的喜欢,欢迎关注威
❤公众号【AI技术星球】回复(123)
白嫖深度学习配套资料+60G入门进阶AI资源包+技术问题答疑+完整版视频
内含:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等
通过以上步骤,您可以有效处理图像数据并应用深度学习模型进行各种图像处理任务。这些技术在计算机视觉领域有广泛应用,如图像分类、目标检测、图像生成等。不同任务可能需要不同的网络结构和训练策略,因此建议根据具体任务和数据特点选择合适的模型和方法。