这篇论文是FPGA 2021年的best paper award,主要解决的是在HLS编译过程中优化布局和布线,最终达到整个multi-die的FPGA板上的大规模HLS设计时钟频率尽可能提升的目的,这篇工作在当前chiplet工艺铺展开来的当下更加有现实意义,通过这篇文章学习一下如何对Multi-Die场景下的模块进行建模。
0 Abstract
这部分首先肯定了HLS作为工具链的高效性和实用性,但是也指出HLS工具目前的一个问题在于HLS和RTL级代码之间可以达成的性能差距很大。 其中一个非常重要的因素在于综合工具对HLS级别的代码的级间互联的延迟缺乏准确的估计。在当下的Multi-Die FPGA和大规模HLS设计下,这个问题凸显的更加严重。
在这篇文章中,提出了AutoBridge来在HLS编译期间将粗粒度的布局规划和流水线结合起来。首先,AutoBridge设计的全局物理布局视图暴露给HLS,这使得HLS可以更加将较长的布线识别出来并将其流水化,尤其是那些跨越了多Die边缘的导线。其次,通过挖掘HLS流水线的灵活性,FloorPlanner可以在FPGA的多Die上进行设计逻辑的分配,而不是一股脑地将所有设计逻辑全部放在一个Die上,这会导致整体设计的时钟频率提不上来。最后,因为引入流水线可能会引入额外的延迟,AutoBridge进一步引入了新的算法来弥补额外引入的延迟。
最后,AutoBridge可以被结合到Xilinx FPGA的设计流中,在吞吐量没有损失的情况下将时钟频率提升了一倍有余。
1 Introduction
这部分首先肯定了HLS存在的意义,但是同样指出HLS设计FPGA难以达到RTL级专家设计的结果。这其中一个非常重要的因素在于HLS不能很好地去预测布局布线(routing and placement)之后设计的物理布局,当前的HLS工具依赖于预先设定的操作延迟和非常粗糙的互联模型,将寄存器插入到没有定时(timing)的设计中。
虽然后续的重定时技术(re-timing)和综合优化技术有希望进一步解决上述问题,但是HLS规定每一条路径上可以使用的寄存器数量有上限,这大大限制了大规模HLS设计时的优化程度,导致生成的RTL代码的时钟频率进一步降低。这个问题在当下Multi-Die的场景下变得更加严重,跨越多个Die的布线会带来非常严重的延迟开销,并且因为各种专用IP核嵌入在可编程逻辑中造成了大量可编程资源的消耗,这导致布线时的迂回,诸多新因素叠加导致时钟频率进一步降低。
接下来论文中指出,之前已有的工作存在的问题是将HLS与底层的物理设计耦合的太过于紧密,在延迟预测(delay prediction)和HLS布局协同优化时相关的导线和寄存器通通都被考虑进来。这样的方式面对小型设计尚且可以工作,而在大型的面向multi-die的HLS设计中代价十分昂贵。
所以文章写到这里顺理成章地引出了AutoBridge,AutoBridge是一种是一种粗粒度的布局引导的流水化方法( a coarse-grained floorplan-guided pipelining approach ),专门用来解决大型HLS设计中的定时(timing)问题。粗粒度的布局规划包含将FPGA设备分割形成区域网络,然后将每一个HLS函数在HLS编译时期指定给一个区域,区域之间的通信进一步使用流水线方法来加速,而区域内的优化则交给默认的HLS工具来做。
随后论文中将AutoBridge的优点又总结了一遍,其实这部分和Abstract部分是大体一致的。
1.早期的布局阶段将全局的物理布局视图提供给了HLS,这可以帮助HLS更好地检测和流水化长导线,尤其是跨越multi-die边缘的导线。
2.流水化感知的布局规划(pipelining-aware floorplanning)可以通过将之后的设计逻辑分配到其他die上来减少本地的布线拥塞(local routing congestion)。
3.因为AutoBridge引入了额外的全局互联流水线,这可能会带来额外的延迟,所以为了弥补可能带来的额外延迟,这里引入了新的分析与延迟平衡算法(latency balancing algorithm)来确保最终整个设计的吞吐率不会受到任何影响。
作为Intro部分的结尾,这部分最后给出AutoBridge的贡献:
1.AutoBridge是第一个将布局(floorplanning)和流水线(pipelining)结合起来解决大规模HLS设计在multi-die场景下的时钟频率问题的工作。
2.AutoBridge为HLS设计了一种粗粒度布局方法(coarse-grained floorplan),它可以将设计逻辑分布在不同的die上来减少本地拥塞,并可以使用HLS=将全局互联充分流水化。
3.AutoBridge分析了引入的额外延迟对设计吞吐量的影响,并提出了新的算法来弥补这种额外引入的延迟对设计造成的可能负面影响。
4.AutoBridge可以与现有的商用FPGA工具结合,并可以在秒级提供有效优化,在43个应用上将它们的时钟频率从147MHz提升到297MHz,而带来的额外面积开销可以忽略不计。
2 BACKGROUND AND MOTIVATING EXAMPLES
2.1 Multi-Die FPGA Architectures
这部分给出了几种商用化Multi-Die FPGA的架构图,并分析了它们板载的IO资源,这部分其实是想说明AutoBridge面向的Multi-Die场景是十分符合现有的商业和技术发展脉络的,也有相当的必要。
2.2 Motivating Examples
这部分举了两个例子来表明AutoBridge方法的有效性。
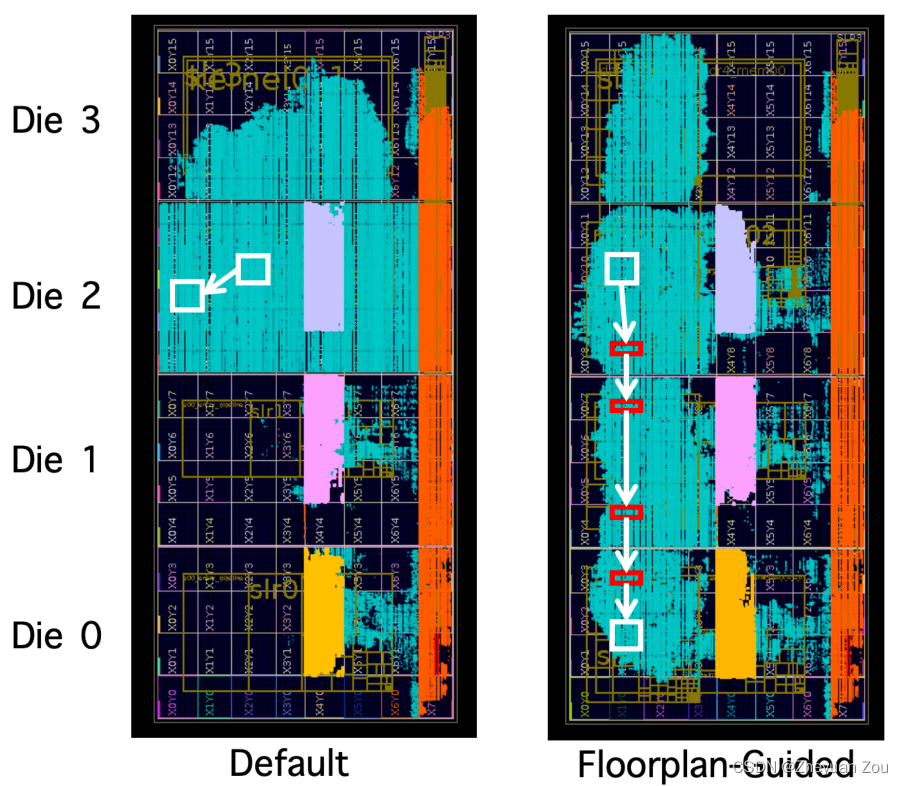
第一个例子(见上图)是在Xilinx U250FPGA上的一个CNN加速器设计,原设计需要与3个DDR控制器交互。默认的HLS工具实现完成之后,会将整个设计紧密地打包在Die2和Die3上(青绿色部分表示加速器占用资源,灰色、紫色、黄色三块代表DDR控制器)。为了证明方法的有效性,这里首先通过人为布局的方式将设计逻辑分配到4个不同的die上,并且将连接不同模块的FIFO完全流水化,使用这种方法成功将原有设计的时钟频率提升了53%。

第二个例子是在Xilinx U280 FPGA上执行一个模板计算任务,原有的四个核心是完全一样的,但是默认的HLS工具会将它们分布在不同的Die上。而在AutoBridge的方法中,在HLS编译阶段就会预决定哪些导线将会跨越Die的边界并将其流水化。这使得原本不可实现的设计的时钟频率提升到了297MHz。
3 COUPLING HLS WITH COARSE-GRAINED FLOORPLANNING
这部分标题《将粗粒度布局规划和HLS结合起来》就十分直白的提出了AutoBridge的方法,在开始正式论述之前,首先提出了几条约定。HLS代码保持源代码的格层次结构,每个HLS函数(function)都会被编译成RTL代码的一个模块(module)。同时这里强调,AutoBridge不是要对已有的布线算法做出改进,而是要给HLS提供更多的有关布局的信息,以指导它更好地完成布局。
3.1 Coarse-Grained Floorplanning Scheme
这部分开头就说明了AutoBridge没有尝试为每个模块(module)找到专有区域,而是将FPGA设备看成是由多Die的边界和大IP块分割而成的网状结构。这些物理屏障会将整个FPGA中的可编程逻辑分成一系列不相交的槽(disjoint slots),AutoBridge会尝试将每一个HLS函数按照粗粒度布局的方法分配给一个区域。
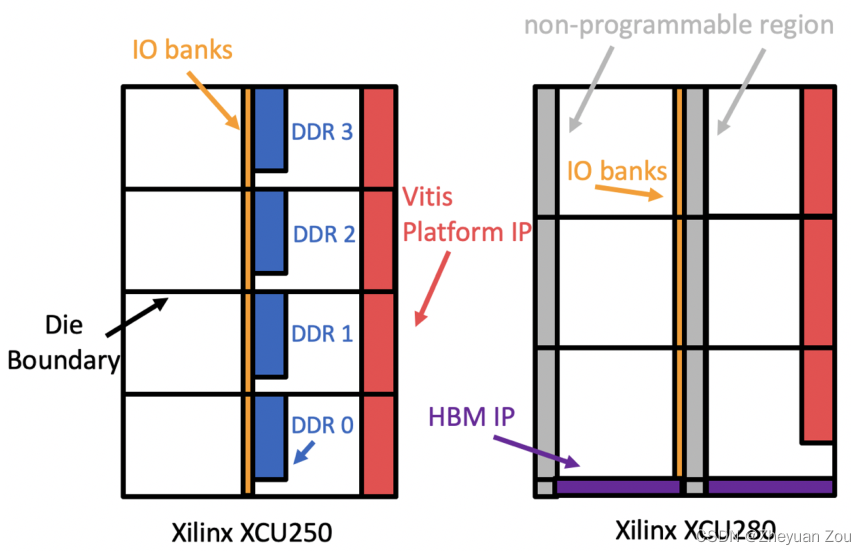
比如对于上图的Xilinx XCU250 FPGA, DDR控制器IP核与Die边界将整个FPGA板分成了 4 × 2 4 \times 2 4×2的网状结构,而对于XCU280则分成了 3 × 2 3 \times 2 3×2的网状结构。AutoBridge将尝试将每一个HLS函数编译而成的模块(module)分配到这样的一个粗粒度区域。
3.2 Problem Formulation
这部分将要进行AutoBridge要解决问题的形式化定义,这里首先做了很多假设和限制:
假定HLS的设计满足数据流编程模型,每一个函数对应于一个数据流过程(dataflow process),每个函数将会被编译成为一个RTL模块,函数与函数之间通过FIFO保持通信。(BTW,我对这里所谓的数据流编程模型非常的不解…orz)
(补充,数据流格式表示的是每个函数之间满足严格的生产者消费者模型,因而它们会被构建成一个DAG图)
这里是问题的形式化定义:
已知:
1.给出一个图 G r a p h ( V , E ) Graph(V,E) Graph(V,E),V(顶点集)表示的是HLS函数的集合,E(边集)则表示的是连接顶点之间的FIFO集合。
2.FPGA划分成网的行数和列数。
3.每个slot所能允许的最大资源使用率。
4.位置限制,比如特定的IP核必须放置在IO模块的旁边,还有像某些IP核必须放在同一Die上等限制。
目标:
1.将每一个顶点v分配给一个指定的槽,使得这个槽的资源使用不超过规定的上限
2.代价函数(cost function)最小化
这里对代价函数的定义如下:
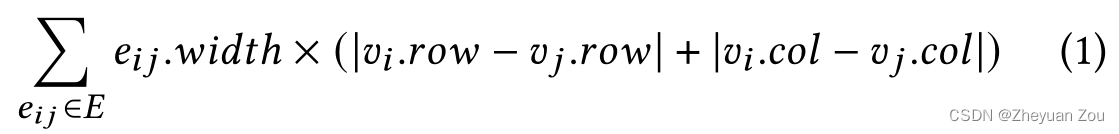
e i j . w i d t h e_{ij}.width eij.width表示的是连接顶点 v i v_i vi和 v j v_j vj的FIFO的位宽,而后面的括号内的内容则是连接 v i v_i vi和 v j v_j vj的导线穿越die的边界的次数。
3.3 Solution
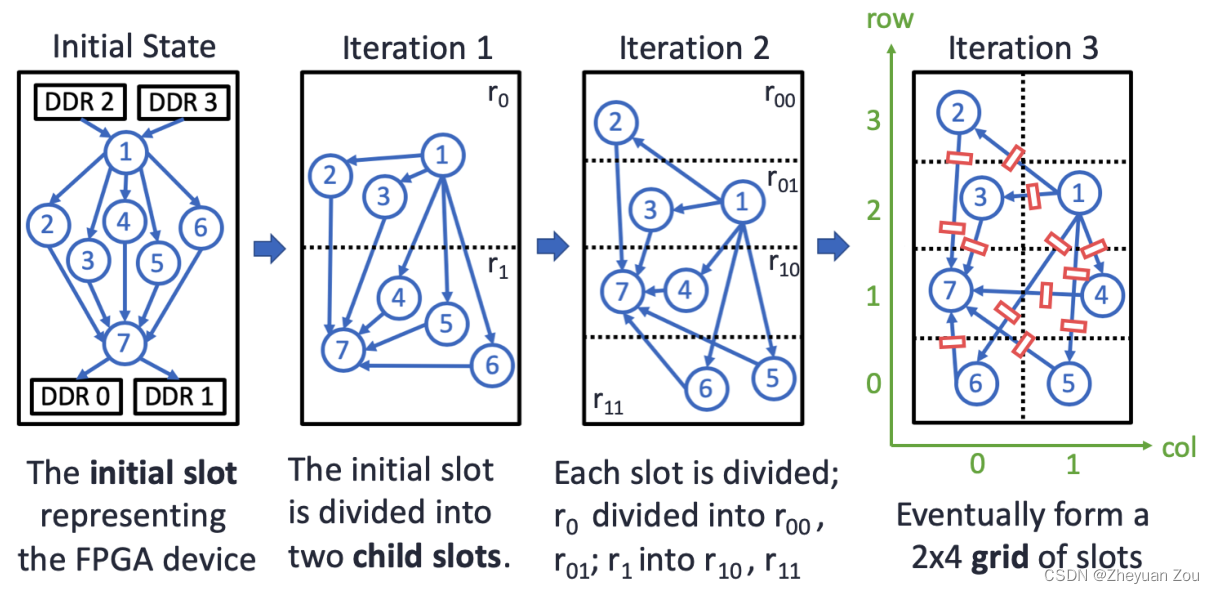
因为HLS的设计抽象层次很高,所以一般不会超过几百个函数的大小,所以上述定义的问题规格其实很小,使用确定性的算法就可以在短时间内找到相对较好的解,所以这里使用了自顶向下的分区布局方法,同时因为问题的解决空间小,因而可以在每个分区中寻求更加精确的解决方案,以下是自顶向下分区的一个例子:
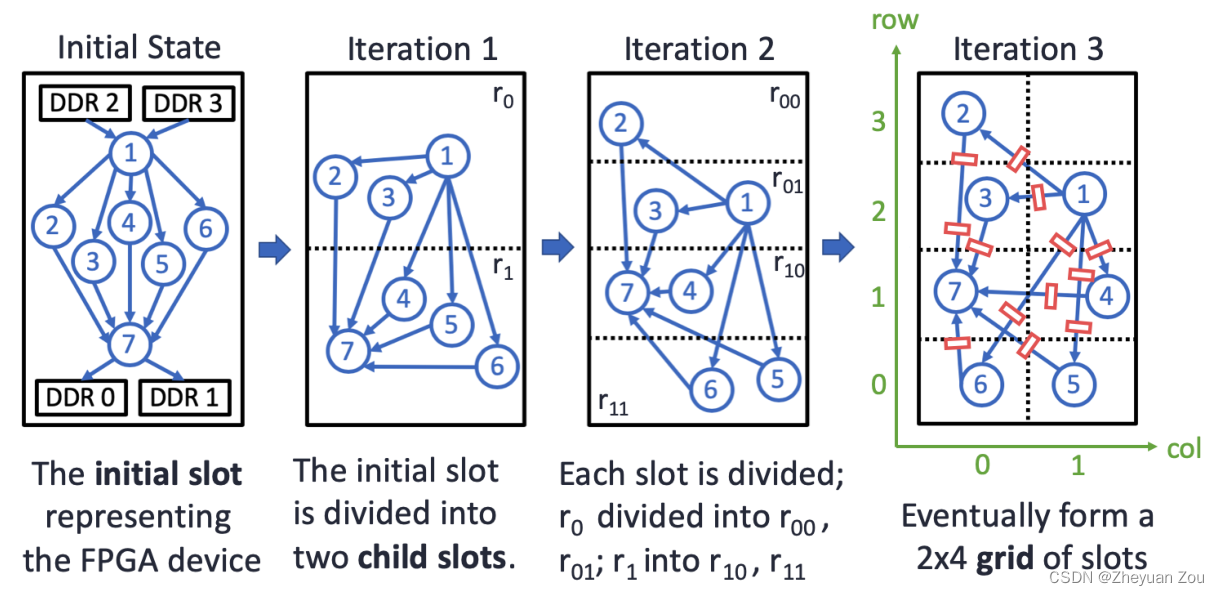
这个例子(上图)展示了自顶向下划分的步骤,一开始所有节点全部在一个槽中,随后第一次迭代一分为二地将slots划分为两个部分,每一次划分就是从水平上或者垂直方向上将原先的slot一分为二成为两个子槽(child slot),并将原先的每个module按照资源用量的需求都分配到不同的子槽中。
AutoBridge使用了整数线性规划(Integer Linear Programming, ILP)的方法来解决上述问题,这里存在一个问题就是划分分区的时候可能存在一个子槽里的module需要和另一个子槽里的module进行紧密通信的情况,这种情况会给整体设计带来巨大的延迟。所以ILP必须统筹地取考虑全局的设计质量,而不能陷入局部最优。
因为问题规模较小,所以这里ILP可以枚举所有可能的分区来获得一个最优解。在这里还有一个额外选项,就是每一次迭代的分区方式还可以是N-分区(N-Partitioning),但是这种方式在实验中展现的效率不如2-分区速度快。
ILP Formulation of One Partitioning Iteration.
这部分详细解释了如何使用ILP方法来进行一次分区的迭代。
首先有一个二进制变量(binary decision variable) v d v_d vd来表示模块在每一次分区时的选择(左右半区、上下半区)。但是为了保证每一个划分的子槽有足够的资源容纳分配给它的模块,因此加入下面的约束,它表示的意思是分配到每个子槽中的模块所占用的资源之和不可以超过子槽资源的总量。
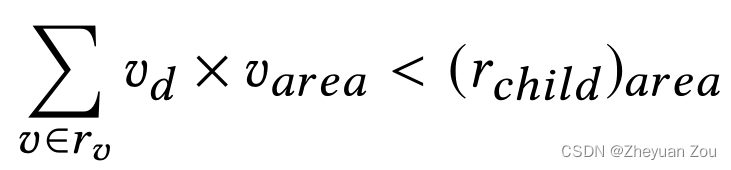
V d V_d Vd表示的是一个槽在分区时候的选择, 它只有0和1两个选项,它本质上是用来计算模块的新坐标的。在每次分区时坐标的计算公式如下,比如下面对应的是竖直分区时的新坐标计算公式:
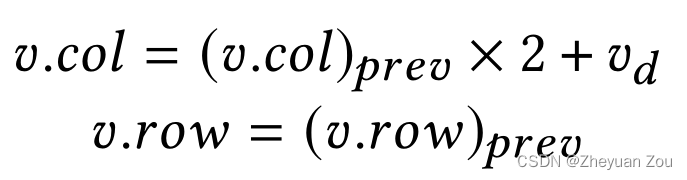
和竖直分区一样,水平分区只是将上述过程镜像了过来:
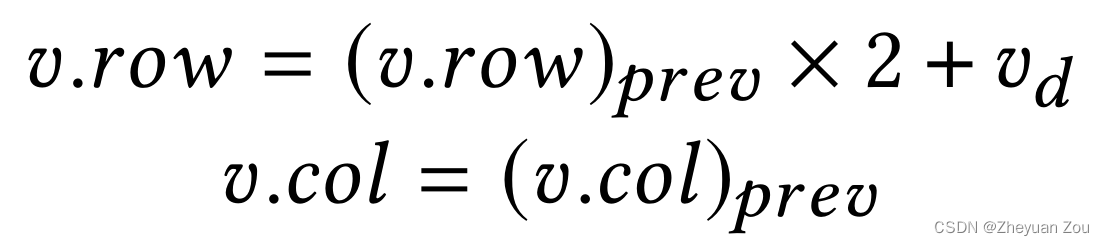
结合上述公式,对比下面的图表就可以看出来上述坐标计算公式是如何工作的:

4 FLOORPLAN-AWARE PIPELINING
在上述已有布局生成的情况下,下面准备对每一个跨越槽与槽之间的FIFO进行流水化,尽管这项工作HLS工具本身也可以做,但是额外新增的延迟有可能会影响设计的整体吞吐率。
4.1 Pipelining Followed by Latency Balancing for Dataflow Designs
这部分主要讲解AutoBridge中的含延迟平衡的流水化(pipelining with latency balancing)方法。
首先再一次明确了AutoBridge面向的是HLS数据流设计(HLS Dataflow Design),其中每个模块之间通过FIFO来进行通信。每一个函数都会被综合成为一个由FSM(Finite State Machine)控制的RTL模块,但是因为FSM的灵活性,也使得估测整体设计的额外开销非常困难。
所以这里原文说AutoBridge采用了一种相对保守(conservative)的方案,首先会对所有跨越槽边界的边进行流水化,随后会使用割集流水化(cut-set pipelining)的方式来平衡并行路径之间的延迟。一个很简单的例子如下:
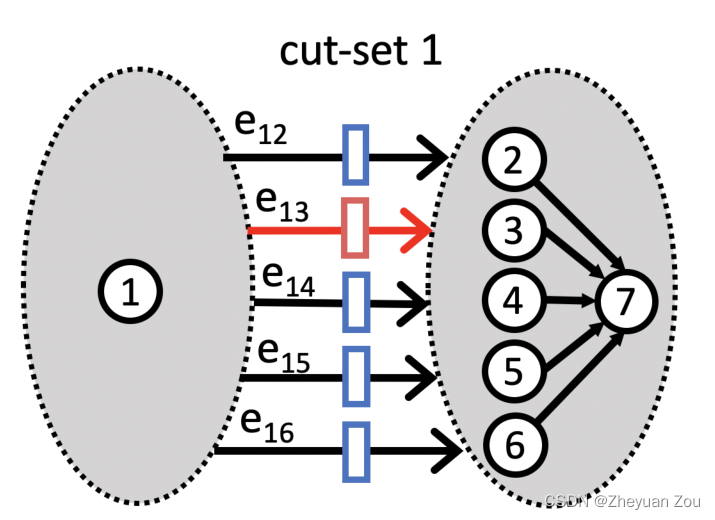
如上图所示 { e 12 , e 13 , e 14 , e 15 , e 16 } \{e_{12}, e_{13}, e_{14},e_{15},e_{16}\} {
e12,e13,e14,e15,e16}是一个割集,如果 e 13 e_{13} e13因为流水化而引入了外的延迟,那么在剩下的边中引入同样大小的延迟,并不会影响设计总体的吞吐量。但是这里存在一个权衡,一个边可以存在于多个割集之中,所以得尽可能去寻找平衡开销尽可能小的割集进行平衡。比如以下这个例子:
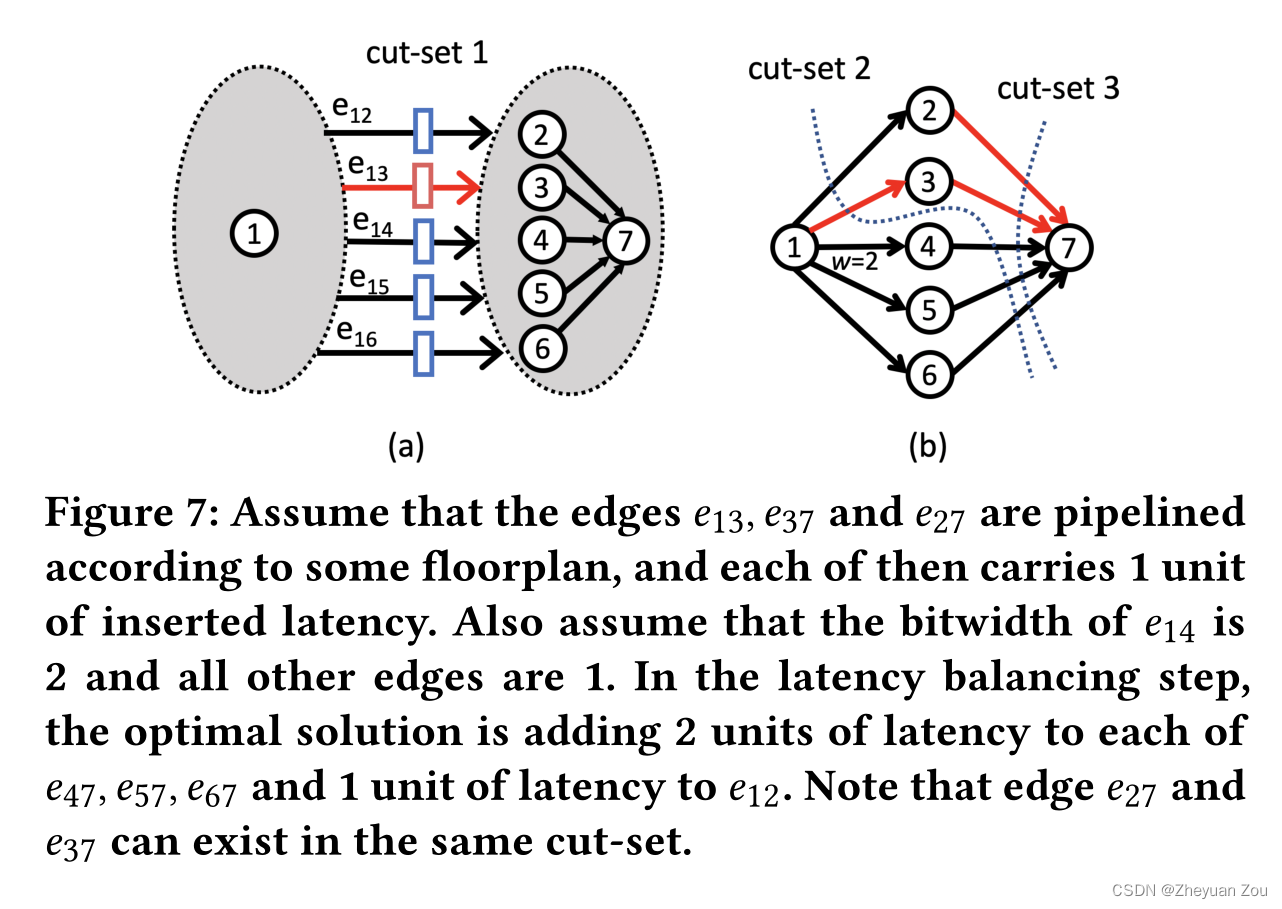
在上面这个例子中, e 14 e_{14} e14的bitwidth是2,其他边的bitwidth都是1,所以绕开 e 14 e_{14} e14来选取割集可以引入更少的开销。同时还要注意,有些时候一个割集中可能存在多个因为流水化而引入额外延迟的边,此时只需要平衡剩下的边就可以了,如上图右边的 e 27 , e 37 e_{27},e_{37} e27,e37。
上述的割集流水化算法的本质和reconvergent paths是一样的,就是指将首尾固定的所有路径上的延迟全部调整成一样,基于此提出下面的延迟平衡算法(Latency Balancing Algorithm)。
4.2 Latency Balancing Algorithm
上面对延迟平衡算法做了比较定性的说明,下面正式提出这个算法。
首先定义要解决的问题,形式化定义如下:
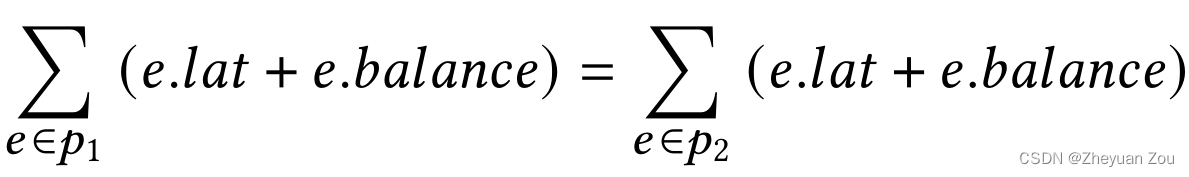
这行约束表示要将任意的reconvergent paths对 { p i , p j } \{p_i, p_j\} {
pi,pj}的延迟全部均衡,其中 e . l a t e.lat e.lat表示的是因为流水化而引入的延迟, e . b a l a n c e e.balance e.balance表示因为要进行延迟均衡而引入的额外延迟,目标是对于任何一对交汇路径,它们的总延迟一定要一样。
在满足上述要求的条件下,最小化以下目标:
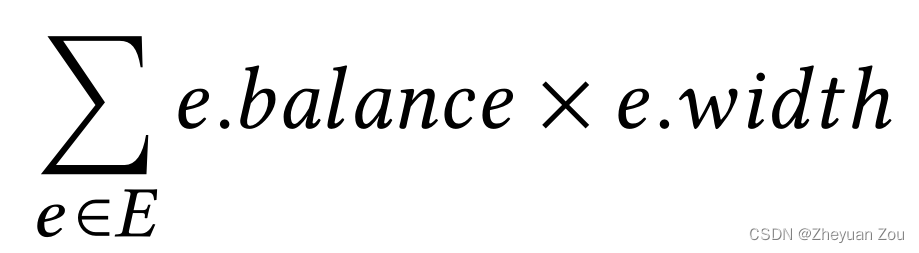
e . w i d t h e.width e.width表示的是FIFO的位宽,上式表示的含义是最小化引入的延迟和FIFO位宽乘积之和。
针对上述问题,AutoBridge使用了ILP的方法来解决,这种方法可以在多项式时间内完成上述问题的求解。具体方法是为每一个顶点 v i v_i vi赋予一个变量 S i S_i Si, S i S_i Si的含义是顶点 v i v_i vi到整个图的汇点的因为流水化而引入的最大延迟。那么 S x − S y S_x - S_y Sx−Sy表示的就是两个顶点 v x v_x vx和 v y v_y vy之间所有路径的因为流水化而引入的最大延迟,最大延迟满足下面的约束条件(这是接下来SDC部分的约束条件)
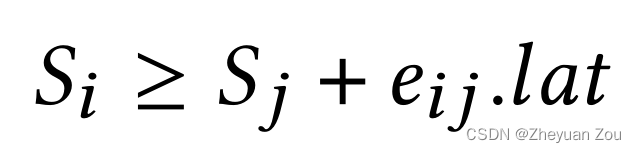
那么表述上述算法的 e i j . b a l a n c e e_{ij}.balance eij.balance就可以如下:
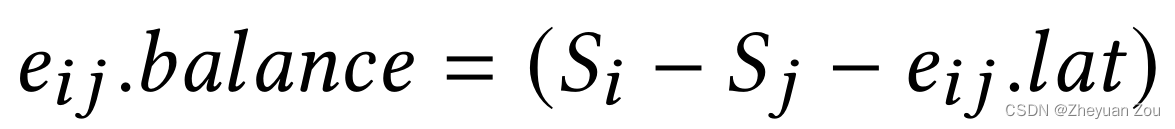
上述问题的优化目标就可以简单地表示为:
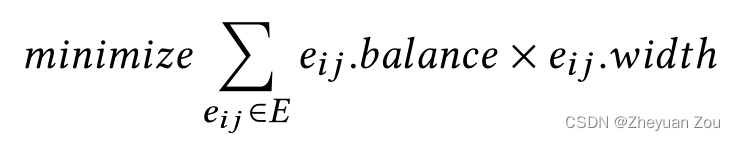
以上三者联立就得到了一个差分约束系统,差分约束系统(System of Differenial Constraints, SDC)可以用线性规划(linear programming)的方式来解,同时保证每一个解都是整数,有算法保证线性规划问题可以在多项式时间内解决。
如果上述问题无解,那么说明数据流图中存在依赖环,这时就需要将无法布局的信息传递给floor planner,让floorplanner重新规划布局,使得有依赖关系的顶点处于一个slot内,这样它们之间的边就不会有跨越子槽边界了,进而也不会被流水化了。
4.3 Loop-Level Latency Balancing
这一节主要讲解了对上述发生依赖时情况的补救措施,如果在数据流图中以整个函数作为顶点,可能会将某些原本可以分配到不同子槽的模块打包在一起。这一节提出了从循环的粒度出发进行延迟平衡,这可以给我们带来更多"察觉"优化的机会。
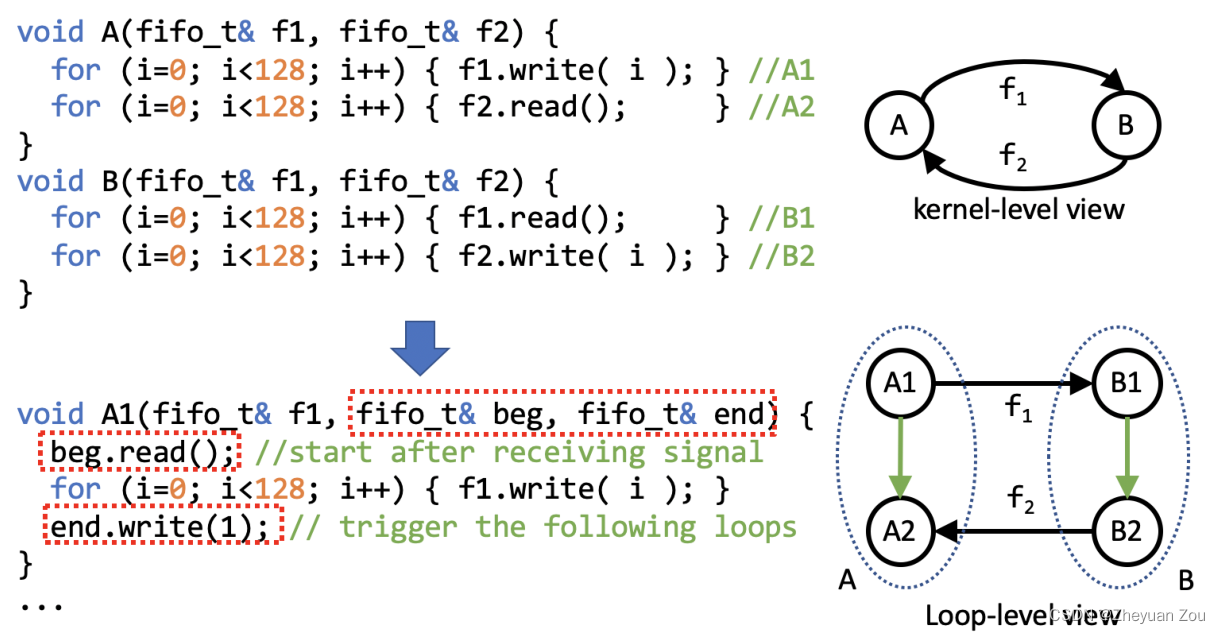 如果以kernel的角度来观察,上面的循环是存在依赖关系的。但是如果将循环作为更小的粒度,并在不同循环之间加上单位宽的FIFO触发信号,这里就可以发现其实循环之间也构成了一个reconvergent path,也就是说这两个函数依然可以分配到不同的子槽中,行为是安全的。
如果以kernel的角度来观察,上面的循环是存在依赖关系的。但是如果将循环作为更小的粒度,并在不同循环之间加上单位宽的FIFO触发信号,这里就可以发现其实循环之间也构成了一个reconvergent path,也就是说这两个函数依然可以分配到不同的子槽中,行为是安全的。
4.4 Extension to Non-Dataflow Designs
这部分讲解了如何将AutoBridge扩展到非数据流设计上,这里不再展开。
5 EXPERIMENTS
从略
6 RELATED WORK
从略
7 CONCLUSIONS
从略