导读:原文《99页4万字XX大数据湖项目建设方案》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。
目 录
1.项目综述
1.1.项目背景
1.2.项目目标
1.3.项目建设路线
2需求分析
2.1功能需求
2.1.1统一数据接入
2.1.2数据迁移
2.1.3数据范围与ETL
2.1.4报表平台
2.1.5安全管理
2.1.6数据治理
2.2非功能需求
2.2.1运维保障需求
2.2.2可用性需求
2.2.3可靠性需求
2.2.4性能需求
2.3需求总结
3整体解决方案
3.1数据湖整体方案
3.1.1硬件部署方式
3.1.2基于CDH的数据湖软件部署
3.1.3数据ETL及数据接口开发方案
3.1.4沙盒管理
3.1.5多租户管理
3.2报表平台整体方案
3.2.1系统设计原则
3.2.2数据分析场景
3.2.3业务需求建议
3.2.4系统逻辑架构
3.2.5技术方案特点
3.2.6其它特性
3.2.7 报表平台具体实施步骤:
3.3数据仓库整体方案
3.3.1数仓的定义
3.3.2 数据仓库的特点
3.3.2 数据仓库具体实施步骤
3.4数据治理整体方案
3.4.1主数据管理实施
3.4.2元数据管理实施
4 企业版功能和特性
4.1 CDH核心套件
4.1.1分布式文件系统HDFS
4.1.2分布式数据库HBase
4.1.3统一资源管理和调度框架YARN
4.1.4分布式批处理引擎MapReduce
4.1.5分布式内存计算框架Spark
4.1.6数据仓库组件Hive
4.1.7安全管理组件 Sentry
4.1.8隐私保护
4.1.9统一用户体验工具 HUE
4.1.10元数据管理Metastore&HCatalog
4.1.11高性能数据分析MPP引擎 Impala
4.1.12数据导入导出工作Sqoop
4.1.13消息处理总线Kafka
4.2 Manager集群管理组件
4.3 Navigator数据管理组件
5项目建设
5.1项目实施计划
5.1.1项目实施服务
5.1.2人员构成
5.2验收说明
5.2.1验收依据
5.2.2验收内容和方式
5.3项目风险评估
66项目培训
6.1 培训服务简介
在线学习资源
6.2 标准课程简介
Hadoop集群管理课程
Hadoop技术开发课程
Hadoop数据分析课程
培训课程优势
培训质量保障
培训计划定义
6.3智慧企业大数据应用、管控、展示一体化云数据湖维护培训
7售后技术支持服务
7.1提供全程技术支持
7.2全周期技术支持
7.3协调原厂支持
7.3.1全周期的技术支持
7.3.2技术支持种类
7.3.3远程支持
7.3.4服务支持策略
7.4主动技术支持
7.5预测技术支持
7.6知识库
1.1. 项目建设路线
第一期:建设企业数据湖,梳理企业应用系统内部的业务数据类型,数据量;将结构化、非结构化数据打标签导入数据湖中心湖中,构建视频池、文本池和应用池分类。对某些应用场景构建BI报表分析。
第二期:建立主数据管理和数仓,ETL规范和流程,数据安全管理,数据可视化管理,数据监控的管理。梳理数据湖使用人员的角色和权限,对数据湖进行基于业务需求场景的多租户管理。根据业务的微服务化,逐步构建企业大数据微服务平台,细粒度的平台资源管理。
第三期:数据的深化应用,一体化管控数据标准和数据治理,深化主数据消费和应用。逐步将应用的数据来源迁移至数据湖中,形成数据应用平台、数据挖掘和BI报表平台,人工智能和机器学习平台。
2 需求分析
2.1功能需求
数据湖的应用、管控、展示为一体,提供标准的服务和数据接口和报表展现方式。数据湖数据采用高效,可靠的存储架构。企业业务数据制订迁移方案,将ERP系统、数据采集系统、OA系统、视频监控系统、云商系统中存储的核心数据,整体迁移至数据湖,非弹性资源实行本地化部署,对于弹性计算功能,需与算法数据湖进行协同计算。以实现核心数据可控,消除安全问题和潜在未知风险。支持可视化建模,支持鼠标拖拽方式进行人工智能算法建模。包括数据预处理、特征工程、算法模型、模型评估和部署等功能支持快销业务领域的预测预警等多种类型的算法应用,包括逻辑回归、K近邻、随机森林、朴素贝叶斯、K均值聚类、线性回归、GBDT二分类、GBDT回归等算法模型,也支持深度学习等人工智能训练模型。展示层通过统一的商业BI报表组件,多维度,动态的展示各业务系统的运行状况,资源使用情况等。并支撑周期性或临时性生成各业务状况,决策数据展示,故障分析挖掘等业务场景。
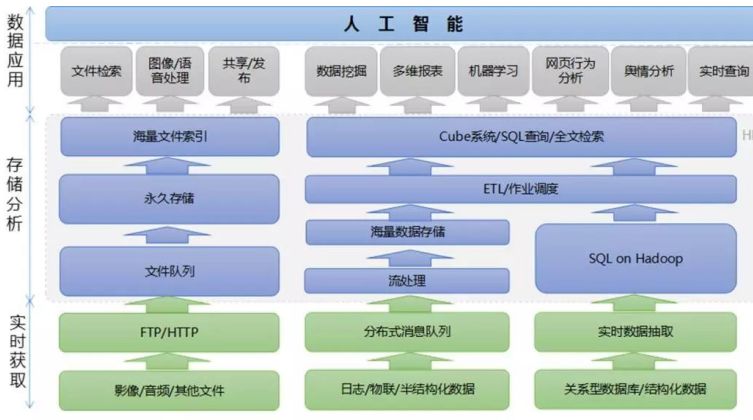
x x数据湖架构图
文件中心:
主要用于存储各种格式文件,包括影像文件,视频音频文件,PDF,Office文件等类型文件,提供文件级别的全文检索,文 件发布,文件共享,文件提取等功能。提供文件权限管理,版本管理,历史版本恢复等管理功能。
文件中心中文件内容可以经由ETL过程与日志中心,数据中心交换融合数据,共同参与数据处理,数据挖掘,机器学习,影像分析等工作。
日志中心:
收集各类日志数据,物联数据等实时数据,由流处理引擎实时处理数据,确保在第一时间分析处理数据,做到实时监控, 实时告警。
经处理的实时数据可与文件中心,数据中心的数据融合,共同参与数据分析等工作。
结构化数据中心:
实时(或批量)获取数据库或其他介质中的架构化数据,借助Hadoop/Spark等强大的处理能力,高效处理各类数据。
有效结合文件中心,日志中心中的数据共同参与数据分析,数据挖掘。
支持百亿级数据Cube,做到海量数据亚秒级多维度查询。
标准SQL输出接口,支持不断升级的需求以及二次开发。
1.1. 项目目标
平台层通过对各业务板块各种数据的采集、整理、汇聚,建立一个基于“互联网+”、云计算技术和人工智能技术的数据湖,实现各业务板块的生产监视、智能设备状态监测、智能故障诊断、智能运行保障、生产数据分析等功能,打造涵盖智慧型生产、经营、发展、党建等全领域的综合平台。
业务层公司数据湖融合实时数据库、关系数据库,实现数据资产管理,提供大数据应用和数据分析计算模型。其中,实时数据是主要的数据形式,实时数据库集群承担高通量数据接入的任务同时,为总部实时业务应用系统提供高实时性的数据查询、计算、组态数据源服务,同时完成数据的标准化、格式化、清洗和整理,将整齐的数据通过Kafka或其他适配器等方式输出到Hadoop数据湖,并负责提供从Hadoop平台到实时库等其他所需数据应用的输入输出组件。数据集中、挖掘,对实现与下属单位互联互通、智能处理、智能协同的目标,使用标准化、自动化、数字化、信息化、智能化等手段,打造涵盖智慧型生产、经营、发展、党建等全领域的综合平台,形成具有“自分析、自诊断、自管理、自趋优、自恢复、自学习、自提升”为特征的智慧企业生态系统。
展示层随着数据湖数据存储、分析、挖掘的深入应用,将极大的激发各部门、各层级对于业务数据的分析和探索,在此之上的数据报表展示需求也将呈现复杂性、综合性、多终端性、个性化等特点。本平台主要目标是建立一个快速的可视化报表平台,无缝化对接数据湖,提供丰富的报表展示功能,面对各层次人员提供对应的数据报表及分析服务。
基于此平台,我们不仅可以在报表开发过程中,加快开发速度,提高数据应用的及时性,还可以在业务需求变更、调整后,大大的降低维护难度,实现可视化做到随需应变。最终在深入完善复杂报表、打印导出、图形化分析、移动决策、大屏监控、自助分析等多个可视化分析领域的支撑。
1.2. 项目建设路线
第一期:建设企业数据湖,梳理企业应用系统内部的业务数据类型,数据量;将结构化、非结构化数据打标签导入数据湖中心湖中,构建视频池、文本池和应用池分类。对某些应用场景构建BI报表分析。
第二期:建立主数据管理和数仓,ETL规范和流程,数据安全管理,数据可视化管理,数据监控的管理。梳理数据湖使用人员的角色和权限,对数据湖进行基于业务需求场景的多租户管理。根据业务的微服务化,逐步构建企业大数据微服务平台,细粒度的平台资源管理。
第三期:数据的深化应用,一体化管控数据标准和数据治理,深化主数据消费和应用。逐步将应用的数据来源迁移至数据湖中,形成数据应用平台、数据挖掘和BI报表平台,人工智能和机器学习平台。
2.1.1 统一数据接入
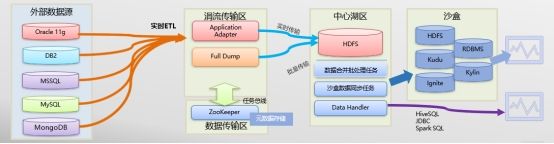 数据湖接口统一接口示意图
数据湖接口统一接口示意图
数据接入原则
1、以应用驱动为主,优先建设高价值数字孪生项目;
2、入湖数据必须有数据管理部认证,发布对应数据资产标准,匹配对应数据责任人;
3、数据建模原则以原始数据、清洗整合数据、三范式结构、服务化宽表逐级向上规范;
4、整体平台需符合高可用、平行扩容原则,符合业务3-5年的数据规划。
数据实时同步,支持绝大多数的数据库实时同步需求。支持跨广域网的数据同步,支持接收器集群。建设统一的,标准的,易于复制和维护的数据实时同步平台,同时完成数据实时同步的技术规范及策略。实现数据同步监控系统,构建数据的更新情况有一个持续的,可靠的实时监控系统。完成一次性数据快速导入与增量数据导入的融合机制——涓流复制。通过Full Dump模块实现数据入库的加密,基于Data Handle提供HiveSQL接口,同时完成数据出库的解密。通过Application Adapter的定制实现数据访问权限的控制
2.1.2 数据迁移
l 将对于频繁读写数据的业务系统,ERP系统、数据采集系统、OA系统、视频监控系统、云商系统保留原数据库的方案。业务数据同步至数据湖,并在并轨运行过程中,需定期验证本地数据湖中与业务系统数据的一致性。
l 接收实时增量数据,按照预定架构存储数据至本地数据湖。生产实时数据实时接入、可靠传输至公司数据库集群中,数据接入量约为110TB/天,历史数据40000TB。
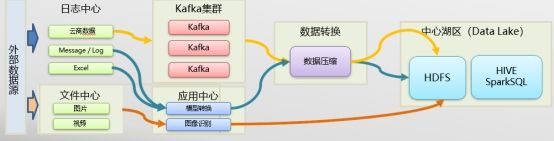
数据迁移逻辑架构图
l 数据湖作业分为非弹性和弹性两类,对于非弹性作业在本地数据湖进行运算,对于消耗资源大且需弹性计算作业,采用与企业云进行协同计算,在企业云数据湖中不保存数据,待作业计算完成后将过程和结果数据回传至本地数据湖进行存储。接口服务支持发布订阅模式,支持跨数据湖、跨系统的调用,支持HDFS、Hive、HBase等系统。
a) 接口类型
批量数据封装
将大批量数据按一定条件抽取出来封装成数据资源。批量数据封装必须通过系统进行,不能进行手工操作。
数据请求接口封装
通过restful接口方式将数据封装成访问接口,使访问方通过远程调用对数据进行访问。
文章引用的资料均来自网络公开渠道,仅作为行业交流和学习使用。其版权归原资料作者或出版社所有,本文作者不对所涉及的版权问题承担任何法律责任。喜欢文章可以点赞转发评论,学习更多内容请私信。