文章目录
1. 引言
RabbitMQ 是一款功能强大的开源消息队列中间件,它提供了一个灵活的消息传递机制,用于在分布式系统中传递和存储消息。作为一种高效、可靠的中间件,RabbitMQ 提供了多种消息队列类型,适用于不同的应用场景和需求。
在这篇文章中,我们将深入探索 RabbitMQ 的不同队列类型,包括经典队列、仲裁队列、流队列、懒队列和死信队列。每种队列都有其独特的特点和优势以及对应的使用场景,也是对上一篇文章java客户端的使用的进一步探索和补充。在开始前,需要已经安装了RabbitMQ 服务并开启管理页面,同时还应具备一种客户端的使用。
服务和管理后台的安装以及java客户端的使用可以查看之前的文章,都进行过详细的说明和介绍
2. 经典队列(Classic Queue)
2.1 概述
经典队列是 RabbitMQ 提供的原始队列类型。 它是非复制 FIFO 队列的实现,是一种适用于许多用例的通用队列类型。其中数据安全不是重中之重,因为数据存储在 不会复制经典队列。如果数据安全很重要, 建议使用仲裁队列和流队列。
经典队列是默认队列类型,经典队列消息存储有两个版本(实现) 和索引。
- 版本1
经典的默认和原始实现 队列。该版本中的索引使用日志和 段文件。从段文件读取消息时,它会加载 内存中的整个段文件,这可能会导致内存问题 但确实减少了执行的 I/O 量。该版本嵌入索引中的小消息,进一步恶化了内存问题。 - 版本2
利用了现代改进的性能 存储设备,是推荐的版本。该版本中的索引仅使用分段文件,并且仅加载来自 磁盘(如有必要)。它将根据 电流消耗率。该版本不嵌入消息 在其索引中,而是使用每个队列的消息存储。版本2是在 RabbitMQ 3.10.0 中添加的,并且显着 在 RabbitMQ 3.12.0 中进行了改进。目前可以 在版本 1 和版本 2 之间来回切换。未来, 将删除版本 1,并执行到版本 2 的迁移 升级后在节点启动时自动。
默认版本可以通过在 rabbitmq.conf 中设置
classic_queue.default_version来通过配置来设置。更改默认版本 仅影响新声明的队列。
注意:版本仅影响数据在磁盘上的存储和读取方式:所有功能都是在两个版本中均可用。
2.2 特征
经典队列支持队列独占性、队列和消息 TTL(生存时间)、队列长度限制、消息优先级、使用者优先级,并遵守使用策略控制的设置。值得一提的是,经典队列不支持毒消息处理,来自官网的描述:
Classic queues do not support poison message handling, unlike quorum queues. Classic queues also do not support at-least-once dead-lettering, suported by quorum queues.
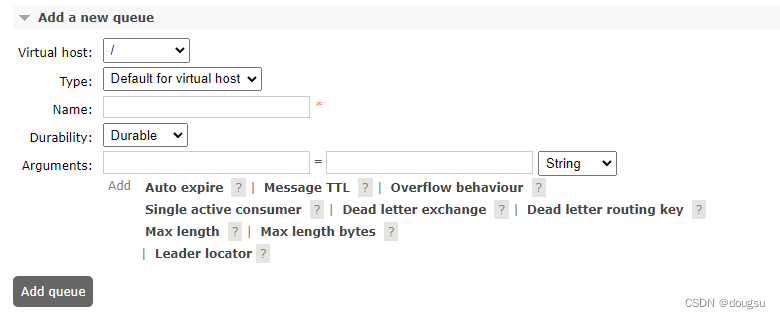
2.3 声明
不指定参数的队列声明其实声明的就是经典队列
2.3.1 管理页面的声明
管理页面的声明如下

一般的,在创建虚拟机时,会选择默认内部创建的队列类型,如果其他地方不知道,就跟根据该参数进行默认创建队列
2.3.2 客户端的声明
在客户端声明,就比较简单,只需要使用客户端jar包通过的默认方法即可
//队列名称
String queueName = "classis-queue";
//声明队列
channel.queueDeclare(queueName, true, false, false, null);
2.4 可选的配置参数
在创建经典队列界面支持添加不同的参数:
- Auto expire:自动过期,设置队列的自动过期时间,以毫秒为单位。作用对象是队列,当队列在指定时间内未被使用(没有生产者或消费者连接),队列将会自动删除。
例子:设置一个队列名为 “q1”,在 10 秒内未被使用将自动删除。
Map<String, Object> arguments = new HashMap<>();
// 10000 毫秒 = 10 秒
arguments.put("x-expires", 10000);
channel.queueDeclare("q1", false, false, false, arguments);
- Message TTL:消息生存时间,设置队列中消息的生存时间,以毫秒为单位。作用对象是消息,所以不仅可以在发送消息时设置,还可以在队列声明设置,当消息在队列中存活时间超过 TTL 时,将会过期并被删除。
例子:设置一个消息的 TTL 为 5 秒。
//在发送消息时设置
String message = "Hello, RabbitMQ!";
String queueName = "q2";
channel.queueDeclare(queueName, true, false, false, null);
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.expiration("5000")
.build();
channel.basicPublish("", queueName, properties, message.getBytes());
//在声明队列时设置
String message = "Hello, RabbitMQ!";
String queueName = "q2";
channel.queueDeclare(queueName, true, false, false, null);
channel.basicPublish("", queueName, properties, message.getBytes());
注意:
- 两种设置方式只能设置一种,不能混合使用
- 如果通过消息设置时间,后续时间可以修改,例如第一条是5s,第二条可以是10秒
- 声明队列方式设置后就不能修改,如果队列已经存在,还必须保持一致
- Overflow behaviour:溢出行为,设置队列中消息达到最大长度或最大容量时的溢出行为。可选的溢出行为有 drop-head, reject-publish 和 reject-publish-dlx。
drop-head:删除头部,新的消息将导致队列的头部(最老的消息)被丢弃
reject-publish:拒绝接收新消息
reject-publish-dlx:当队列已满时,新的消息会被拒绝(Rejected),并转发到指定的死信交换(Dead Letter Exchange)
配置例子:设置一个队列名为 “my_queue”,当消息数量达到 1000 条时,使用 reject-publish 溢出行为拒绝新消息。
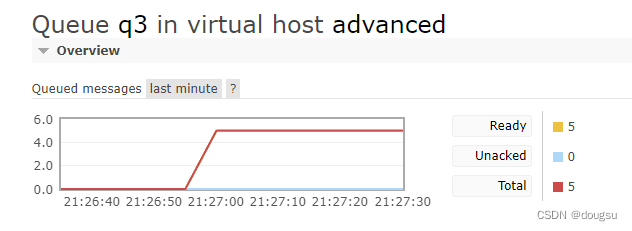
例子:设置长度超过5,并且溢出策略设置为删除头部
String queueName = "q3";
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-max-length", 5);
arguments.put("x-overflow", "drop-head");
channel.queueDeclare(queueName, true, false, false, arguments);
for (int i = 0; i <= 10; i++) {
String message = "Hello, RabbitMQ-" + i;
channel.basicPublish("", queueName, null, message.getBytes());
}
执行后可以看到队列中的消息还是只有5条
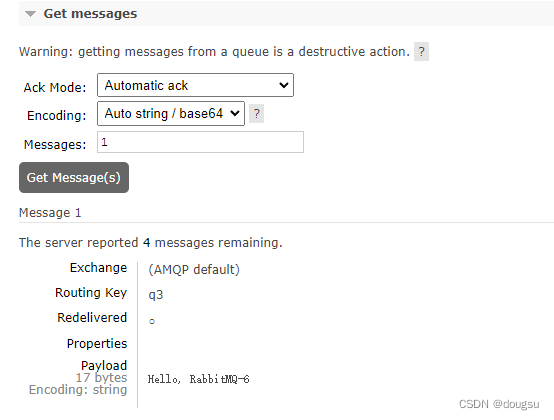
获取一条消息,可以看到从第六条开始
- Single active consumer:单个活跃消费者,设置队列只有一个活跃的消费者,当该消费者断开连接后,其他消费者才能接管处理消息。
例子:设置一个队列名为 “q4”,只允许一个活跃消费者。
Map<String, Object> arguments = new HashMap<String, Object>();
arguments.put("x-single-active-consumer", true);
channel.queueDeclare("q4", false, false, false, arguments);
- Dead letter exchange:死信交换,设置一个交换机,用于接收过期或被拒绝的消息,成为死信后将转发到指定交换机。
例子:设置一个队列名为 “q5”,当消息过期或被拒绝后,转发到名为 “q5_dlx” 的交换机。
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange", "q5_dlx");
arguments.put("x-dead-letter-routing-key", "");
channel.queueDeclare("q5", false, false, false, arguments);
成为死信消息,满足以下任意一种即可:
- 消息被拒绝(basic.reject或basic.nack),并且requeue参数设置为false,意味着消息不会重新入队列,而是被标记为死信并发送到死信交换机。
- 消息在队列中过期,即消息的存活时间超过了设置的x-message-ttl参数。
- 队列长度限制(x-max-length参数)导致消息被丢弃,并且x-overflow参数设置为reject-publish-dlx,意味着消息被标记为死信并发送到死信交换机。
- 消息达到队列的最大长度,即达到了x-max-length参数设置的值,并且x-overflow参数设置为reject-publish-dlx,导致消息被标记为死信并发送到死信交换机。
- 队列过期,即队列的存活时间超过了设置的x-expires参数。
-
Dead letter routing key:死信路由键,设置死信消息的路由键(Routing Key)。当消息成为死信时,会带着原始消息的路由键发送到指定的死信交换。
-
Max length:最大消息数量,设置队列的最大长度,当队列中消息数量达到该值时,新的消息将无法进入队列。
-
Max length bytes:最大队列容量,设置队列的最大容量,以字节为单位。当队列中消息的总字节数达到该值时,新的消息将无法进入队列。
例子:设置一个队列名为 “q6”,最大容量为 10MB。
Map<String, Object> arguments = new HashMap<>();
// 10MB
arguments.put("x-max-length-bytes", 10 * 1024 * 1024);
channel.queueDeclare("q6", false, false, false, arguments);
-
Leader locator:领导者定位器,RabbitMQ 内部使用的参数,用于确定消息队列的主节点。通常情况下,不需要手动配置此参数。
-
Maximum priority:最大优先级,该参数用于定义队列中消息的最大优先级。优先级是一个非负整数,数值越大,表示优先级越高。当一个队列设置了 x-max-priority 参数后,生产者发送的消息可以携带一个 priority 属性指定消息的优先级,然后 RabbitMQ 会根据消息的优先级进行消息排序和分发。高优先级的消息会被优先消费,以确保高优先级任务得到更快的处理。此参数应为 1 到 255 之间的正整数,官方建议设置1到5之间。
例子:设置队列q5的最大优先级为5
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-max-priority", 5);
channel.queueDeclare("q5", true, false, false, arguments);
- Version:版本,该参数用于定义队列的版本。在 RabbitMQ 3.8.0 版本中引入了队列版本的概念,它用于支持不同类型的队列。详细参照前面2.1的概述部分
3. 仲裁队列(Quorum Queue)
3.1 概述
仲裁队列是 RabbitMQ 实现持久、 基于Raft共识算法的复制FIFO队列。仲裁队列和流现在取代了原始复制的镜像经典队列。镜像经典队列在未来会弃用并计划删除。
3.2 特征
与传统镜像队列相比,仲裁队列在行为上也存在重要差异和一些限制, 包括特定于工作负载的,例如,当使用者重复对同一消息重新排队时。
某些功能(如有害消息处理)是特定的 到仲裁队列。官方提供了一个仲裁队列与经典队列差异对比的表格:
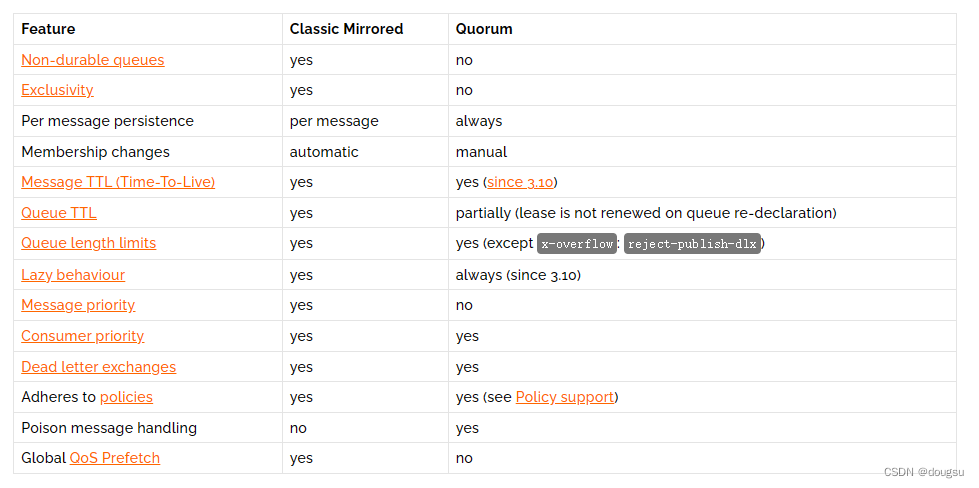
3.3 声明
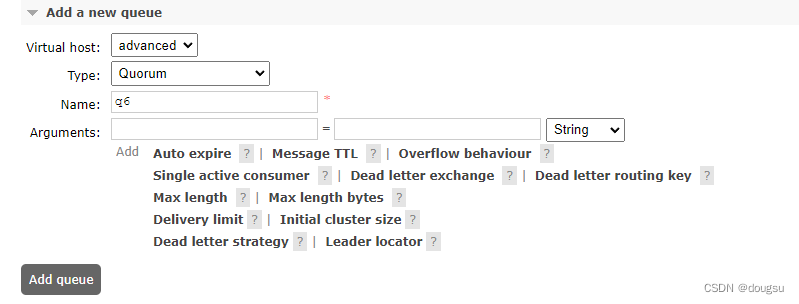
3.3.1 管理页面的声明
管理页面比较简单,直接类型即可
3.3.2 客户端的声明
目前客户端的声明目前没有特定的函数,只能通过设置参数,如
String queueName = "q7";
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-queue-type", "quorum");
channel.queueDeclare(queueName, true, false, false, arguments);
声明后到管理后台可以查看创建情况

3.4 可选的配置参数
仲裁队列大部分可配置的参数跟classis队列时一样的,可以参考前面 2.4部分,下面时仲裁队列区别于经典队列的参数:
- Delivery limit:允许的失败投递尝试次数。一旦一条消息被不成功地投递超过这个次数,它将会被丢弃或者根据队列配置被转移到死信队列。
例子:设置消息的最大投递次数为5
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-delivery-limit", 5);
channel.queueDeclare("q-1", true, false, false, arguments);
- Initial cluster size:设置队列的初始集群大小。该参数用于定义 RabbitMQ 集群的初始节点数量。在创建 RabbitMQ 集群时,需要指定至少一个初始节点的数量,这些节点会形成初始的集群配置。后续的节点加入和自动发现将由集群自动管理。通过设置正确的初始集群大小,可以确保集群能够正常启动,并且新加入的节点能够正确加入现有集群。
例子:设置初始集群大小为3个节点
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-quorum-initial-group-size", 3);
channel.queueDeclare("quorum_queue", true, false, false, arguments);
- Dead letter strategy:有效值为at-most-once或at-least-once。默认值为at-most-once(消息至多被投递一次)。该设置仅适用于quorum队列。如果设置为at-least-once(消息至少被投递一次),则溢出行为必须设置为reject-publish。否则,死信策略将回退到at-most-once。
例子:死信队列处理示例
Map<String, Object> arguments = new HashMap<>();
// 设置死信策略为 at-least-once
arguments.put("x-dead-letter-strategy", "at-least-once");
// 设置溢出行为为 reject-publish
arguments.put("x-overflow", "reject-publish");
// 设置死信队列的交换机为 dlx_e
arguments.put("x-dead-letter-exchange", "dlx_e");
channel.queueDeclare("q-1", true, false, false, arguments);
- Leader locator:设置在集群节点上声明队列时,确定队列领导者所在位置的规则。有效值为client-local(默认值)和balanced。
client-local:队列领导者将被定位在与客户端最近的节点上。这是默认值,它可以在大多数情况下提供最佳性能,因为队列操作会路由到最近的节点,减少了网络延迟。
balanced:队列领导者将被平衡地定位在集群的不同节点上。这样可以在集群中均匀分布队列的领导者角色,使得负载更均衡。在某些场景下,这种方式可能会提供更好的性能。
Map<String, Object> arguments = new HashMap<>();
// 设置主节点定位器为 client-local
arguments.put("x-queue-leader-locator", "client-local");
channel.queueDeclare("quorum_queue", true, false, false, arguments);
4. 流队列(Stream Queue)
4.1 概述
流是一种新的持久和复制的数据结构,它建模 具有非破坏性使用者语义的仅追加日志。 它们可以通过 RabbitMQ 客户端库(就好像它是队列一样)或通过专用的二进制协议插件和相关客户端使用。建议使用后一个选项,因为它 提供对所有特定于流的功能的访问,并提供最佳吞吐量(性能)。
4.2 特征
主要特征:
- 长度限制:可以设置队列的最大长度,当队列中消息的总大小超过这个值时,最旧的消息将会被移除。
- 时间保留:可以设置队列中消息的最长保留时间,超过此时间的消息将会被自动删除。
- 消息分段:支持将大消息分段存储,每个分段的大小可以设置。这样可以优化内存的使用,降低内存消耗。
- 高可用性:流队列使用 Raft 共识算法实现复制,确保消息在集群中的高可用性和数据安全性。
4.3 声明
4.3.1 管理页面的声明
为了防止流队列无限增大,一般需要设置x-max-length-bytes和x-stream-max-segment-size-bytes,具体的例子见4.4

4.3.2 客户端的声明
见下面4.4的例子
4.4 可选的配置参数
-
Max length bytes:见2.4部分
-
Max time retention :设置流队列的数据保留时间,单位为时间单位(Y=年,M=月,D=天,h=小时,m=分钟,s=秒)。
-
Max segment size in bytes :在磁盘上流段的总大小。该参数用于设置流队列的最大分段大小,也就是队列中消息的最大存储单元的大小。当消息的大小超过这个限制时,消息将被拆分成多个分段进行存储。
-
Initial cluster size :见3.4部分*
-
Leader locator:见3.4部分
流队列的参数一般都不是单独配置的,而是需要组合配置,下面是一个常用的stream队列的声明例子
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-queue-type", "stream");
//流队列大小是10G
arguments.put("x-max-length-bytes", 10_000_000_000L);
//每个segment的大小是100M
arguments.put("x-stream-max-segment-size-bytes", 100_000_000);
//流队列的数据保留时间1个月
arguments.put("x-max-age", "1M");
channel.queueDeclare("stream_queue", true, false, false, arguments);
5. 懒队列(Lazy Queue)
5.1 概述
经典队列可以在延迟模式下运行。自RabbitMQ 3.12起,队列模式被忽略,经典队列的行为与延迟队列类似。然而,它们可能会根据消费速率在内存中保留少量消息(截至目前为止最多2048条)。在延迟模式下运行的经典队列会尽早地将其内容移动到磁盘,并在被消费者请求时才将其加载到内存中,因此称为延迟队列。延迟队列的主要目标之一是能够支持非常长的队列(数百万条消息)。队列可能因为各种原因变得非常长:
- 消费者离线/崩溃/维护中
- 突然出现消息输入峰值,生产者超过消费者
- 消费者较慢
5.2 特征
默认情况下,队列会保留一个内存中的消息缓存,当消息被发布到RabbitMQ时,该缓存会填充。这个缓存的目的是能够尽可能快地将消息传递给消费者。请注意,持久性消息在进入代理时可能被写入磁盘,并同时保留在内存中。
每当代理考虑需要释放内存时,缓存中的消息将被分页到磁盘。将一批消息分页到磁盘需要时间,并阻塞队列过程,使其无法在分页时接收新的消息。尽管RabbitMQ的最新版本改进了分页算法,但对于队列中可能需要分页的数百万条消息的用例来说,情况仍然不理想。
延迟队列会尽早将消息移动到磁盘上,这意味着在正常操作的大多数情况下,内存中保留的消息数量显著减少。这的代价是增加了磁盘I/O的负担。
5.3 开启懒队列模式
5.3.1 客户端方式
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-queue-mode", "lazy");
channel.queueDeclare("myqueue", false, false, false, args);
5.3.2 策略方式
要使用策略指定队列模式,将密钥队列模式添加到策略定义中,使用服务端提供的rabbitmqctl 工具执行,例如:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues
如果队列模式是通过策略配置的, 可以在运行时更改它,而无需删除和重新声明队列。 要使名为“lazy-queue”的队列使用默认(非惰性)模式,请更新其匹配策略 要指定不同的队列模式:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"default"}' --apply-to queues
命令的解释:
- rabbitmqctl: 是 RabbitMQ 的管理命令行工具,用于管理 RabbitMQ 服务器。
- set_policy: 是一个命令,用于设置策略(policy)。
- Lazy: 是设置的策略名称,这里命名为 “Lazy”。
- ** “^lazy-queue " ∗ ∗ : 是一个正则表达式,用于匹配队列名称。这里的正则表达式为 " l a z y − q u e u e " ** : 是一个正则表达式,用于匹配队列名称。这里的正则表达式为 "^lazy-queue "∗∗:是一个正则表达式,用于匹配队列名称。这里的正则表达式为"lazy−queue”,表示只匹配队列名称为 “lazy-queue” 的队列。
- ‘{“queue-mode”:“default”}’: 是策略的具体配置参数。这里设置了队列模式为 “default”,表示该队列采用默认的模式。
- –apply-to queues: 是一个选项,表示将策略应用于队列。
6. 死信队列(Dead-Letter Queue)
6.1 概述
来自队列的消息可以是“死信”;也就是说,重新发布到 发生以下任何事件时的交换:
- 使用者使用 basic.reject 或 basic.nack 对消息进行否定确认,并将重新排队参数设置为 false
- 消息由于设置 TTL 属性而过期
- 因为其队列超出了长度限制而被丢弃的消息
请注意,队列过期不会对其中的消息进行死信。
死信交换 (DLX) 是正常的交换。他们可以是 任何常用类型,并按常规声明。
对于任何给定的队列,DLX 可以由客户端使用队列的参数定义,也可以在服务器中定义 使用策略。在 策略和参数都指定 DLX 的情况,即 在参数中指定会否决策略中指定的参数。
6.2 声明
6.2.1 策略的声明
建议使用策略进行配置,因为它允许 DLX 不涉及应用程序重新部署的重新配置。使用服务提供的rabbitmqctl工具。
例子:把死信交换机设置到所有队列上:
rabbitmqctl set_policy DLX ".*" '{"dead-letter-exchange":"my-dlx"}' --apply-to queues
-
rabbitmqctl::是 RabbitMQ 的管理命令行工具,用于管理 RabbitMQ 服务器。
-
set_policy: 是一个命令,用于设置策略(policy)。
-
DLX: 是设置的策略名称,这里命名为 “DLX”。
-
“.": 是一个正则表达式,用于匹配队列名称。这里的正则表达式为 ".”,表示匹配所有队列的名称。
-
‘{“dead-letter-exchange”:“my-dlx”}’: 是策略的具体配置参数。这里设置了一个死信交换机,即 “dead-letter-exchange”。
-
–apply-to queues: 是一个选项,表示将策略应用于队列。
6.2.2 客户端的声明
要设置队列的死信交换,请指定 可选的 x-dead-letter-exchange参数,当 声明队列。该值必须是同一虚拟主机中的交换名称 :
channel.exchangeDeclare("some.exchange.name", "direct");
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-dead-letter-exchange", "some.exchange.name");
channel.queueDeclare("myqueue", false, false, false, args);
以上代码声明了一个名为 “some.exchange.name” 的新交换器,并将这个新交换器设置为新创建队列的死信交换器。请注意,交换器不必在队列声明时就声明,但是在消息需要被转发到死信队列的时候,它应该已经存在;如果在那时交换器不存在,消息将会被静默丢弃。
还可以指定在将消息转发到死信队列时要使用的路由键。如果没有设置,消息将使用自己的路由键。
args.put("x-dead-letter-routing-key", "some-routing-key");
当指定了死信交换器后,除了对声明的队列的通常配置权限之外,用户还需要对该队列拥有读权限,并且对死信交换器拥有写权限。权限在队列声明时进行验证。
总结
本文介绍了 RabbitMQ 中的不同类型的队列,包括经典队列、仲裁队列、流队列、懒队列和死信队列,并详细介绍了它们的特征和声明方式。通过了解这些不同的队列类型,希望可以帮助你根据业务需求选择合适的队列,优化消息系统的性能和可靠性。