分布式任务调度框架
学习为主
文章目录
分布式调度平台大多殊途同归。
关于xxl-JOB
一、概念
XXL-JOB是一个轻量级分布式任务调度平台,主打特点是平台化,易部署,开发迅速、学习简单、轻量级、易扩展,代码仍在持续更新中。本身是任务调度控制台,不承担业务逻辑,我们常常拿这个当作定时任务,一些特性什么这里就不过多介绍了。重点是大体的流程和原理。
二、架构图
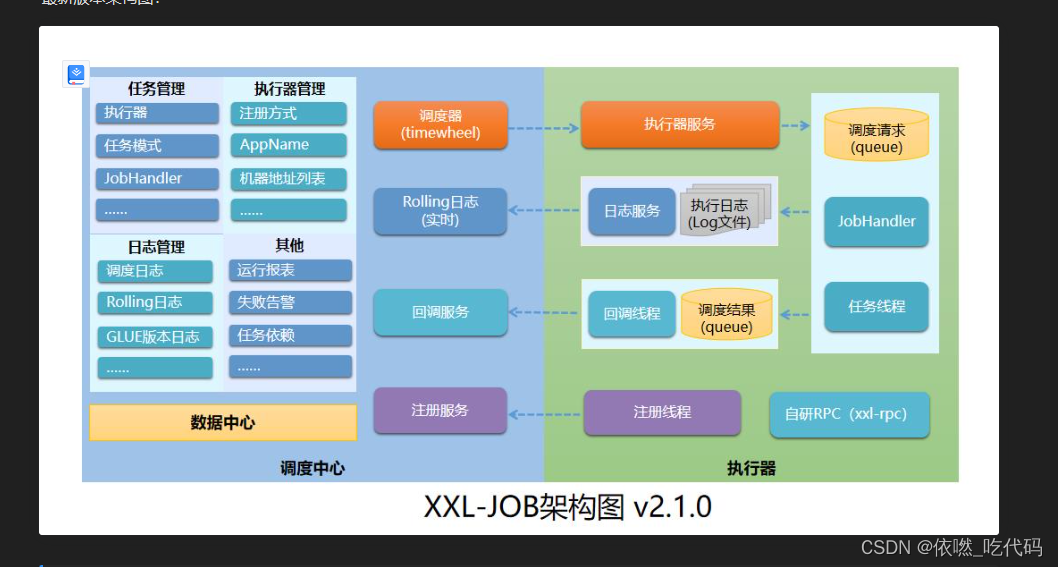
xxl-job其实也是在quartz的基础上实现的,但是修改了任务调度的模式,并且任务调度采用注册和RPC调用方式来实现。
2.1.0版本前核心调度模块都是基于quartz框架,2.1.0版本开始自研调度组件,移除quartz依赖 ,使用时间轮调度。
(RPC的底层变化, 2.0.1 使用的是Jetty服务的RPC, 2.0.2 使用的Nettty服务的RPC)
三、任务调度的流程
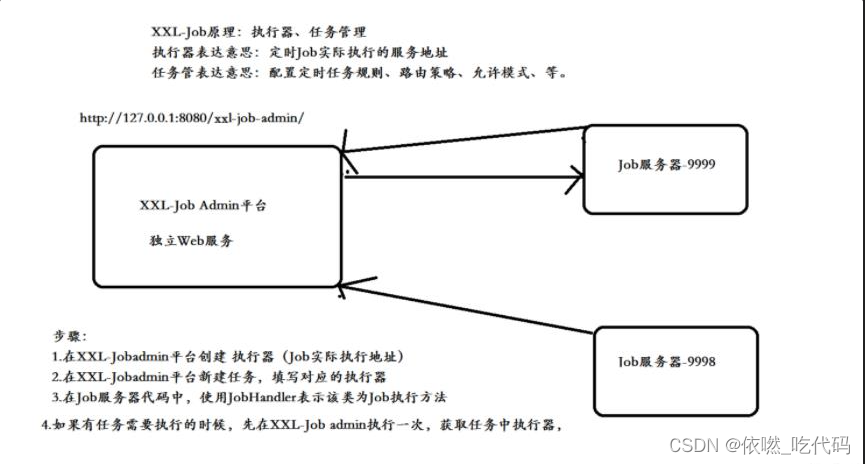
1:XXL-Jobadmin平台创建执行器(Job实际执行地址)
2:XXL-Jobadmin平台新建任务,填写对应的执行器
3:Job服务器代码中,使用JobHandler表示该类为Job执行方法
4:当任务执行的时候,会现在XXL-Jobadmin调度平台先执行一次,获取任务中的执行器,然后去对应的执行器地址服务器,执行对应的任务
设计思想:
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
定时触发任务是如何实现的?:使用时间轮实现
xxl_job_info表是记录定时任务的db表,里面有个trigger_next_time(Long)字段,表示下一次触发的时间点任务时间被修改 / 每一次任务触发后,可以根据cronb表达式计算下一次触发时间戳:
Date nextValidTime = new CronExpression(jobInfo.getJobCron()).getNextValidTimeAfter(new Date()))
更新trigger_next_time字段
定时执行任务逻辑:
- 定时任务scheduleThread:不断从db把5秒内要执行的任务读出,立即触发 / 放到时间轮等待触发,并更新trigger_next_time
- 获取当前时间now
- 轮询db,找出
trigger_next_time在距now 5秒内的任务
3.1 对到达now时间后的任务(超出now 5秒外)
(1) 直接跳过不执行;
(2) 重置trigger_next_time
3.2 对到达now时间后的任务(超出now 5秒内)
(1) 开线程执行触发逻辑;
(2) 若任务下一次触发时间是在5秒内,则放到时间轮内(Map<Integer, List>秒数(1-60) => 任务id列表);
(3) 重置trigger_next_time
3.3 对未到达now时间的任务
(1)直接放到时间轮内;
(2)重置trigger_next_time
- 定时任务ringThread:时间轮实现到点触发任务
4.1 时间轮数据结构:Map<Integer, List> key是秒数(1-60) ,value是任务id列表
- 获取当前时间秒数
- 从时间轮内移出当前秒数前2个秒数(避免处理耗时太长,跨过刻度,向前校验一个刻度)的任务列表id,一一触发任务;
如何避免集群中的多个服务器同时调度任务?
当xxl-job应用本身集群部署(实现高可用HA)时,如何避免集群中的多个服务器同时调度任务?
通过mysql悲观锁实现分布式锁(for update语句)
- setAutoCommit(false)关闭隐式自动提交事务,启动事务
- select lock for update(显式排他锁,其他事务无法进入&无法实现for update)
- 读db任务信息 -> 拉任务到内存时间轮 -> 更新db任务信息
- commit提交事务,同时会释放for update的排他锁(悲观锁)
任务执行器注册中心是如何实现的?
使用db表xxl_job_group记录下执行器的信息:
执行器AppName、执行器名称title、执行器地址列表address_list(多地址逗号分隔)
如何实现任务执行器的路由?
执行器集群部署时提供丰富的路由策略,包括:
第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 第一个、最后一个、轮询、随机:都是简单读address_list即可
- 一致性HASH:TreeSet实现一致性hash算法
- 最不经常使用、最近最久未使用:HashMap、LinkedHashMap
- 故障转移:遍历address_list获取address时,逐个检查该address的心跳(请求返回状态);只有心跳正常的address才返回使用
- 忙碌转移:遍历address_list获取address时,逐个检查该address是否忙碌(请求返回状态);只有状态为idle的address才返回使用
如何实现任务分片、并行执行?
- 拉出任务的执行机器列表,逐个设置index / total,把index / total分发到任务执行器
- 任务执行器可根据index / total参数开发分片任务

学习1:https://www.kuaiyong.icu/xxl_job%e5%ae%9a%e6%97%b6%e4%bb%bb%e5%8a%a1%e7%ae%a1%e7%90%86%e5%b9%b3%e5%8f%b0/
学习2:https://blog.csdn.net/weixin_40816738/article/details/123720235