文章目录
论文: 《DiffEdit: Diffusion-based semantic image editing with mask guidance》
github: https://github.com/johnrobinsn/diffusion_experiments/blob/main/DiffEdit.ipynb
摘要
图像生成最佳展现巨大优势,扩散模型对于各种文本prompt可生成令人信服图片。作者提出DiffEdit,基于文本query进行图像编辑。当前基于扩散模型图像编辑方法,通常需要提供mask,转为条件修复任务。作为对比,DiffEdit可基于prompt自动生成mask,高亮需要编辑区域。在ImageNet达到SOTA,同时作者在COCO及基于文本生成的图像上进行验证。
算法
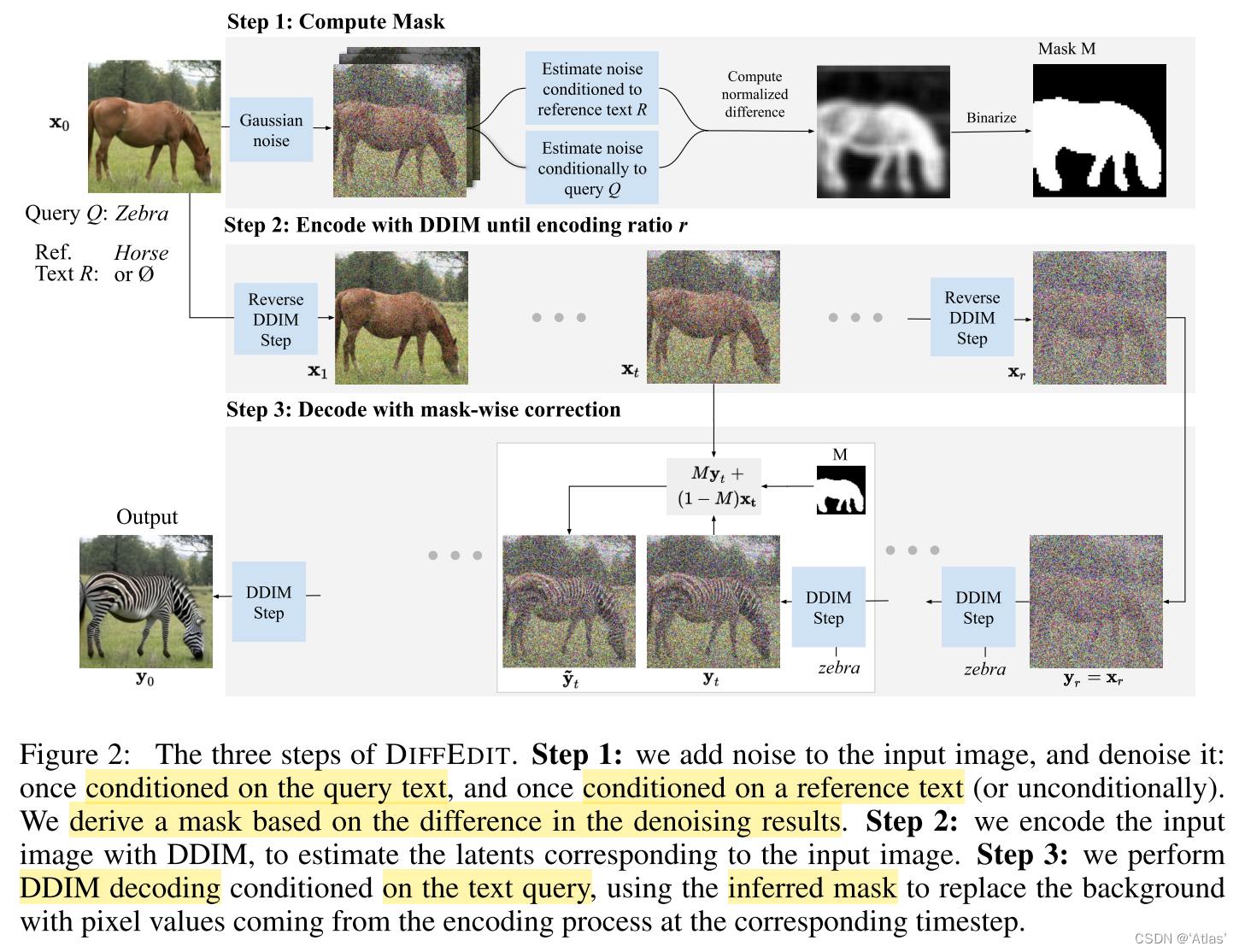
DIFFEDIT依据文本推理需要编辑的mask区域,图2表示该方法的三个步骤:
Step1:计算编辑mask
进行图像去噪时,不同文本输入,扩散模型给出不同噪声估计,根据噪声估计的差异找到那些图像区域与条件文本变换有关。如图2所示。本算法中使用高斯噪声,通过去除10个输入噪声极值并进行平均化进行稳定预测,归一化到[0, 1],通过阈值0.5进行二值化。
Step2:编码
使用DDIM中编码器 E r E_r Er对输入图 x 0 x_0 x0编码到隐空间,直到达到编码比例 r r r,该过程未使用文本条件;
Step3:使用mask引导进行解码
获得隐向量 x r x_r xr后,基于编辑文本Q使用扩散模型解码 x r x_r xr,同时利用mask M引导扩散过程,该过程通过替换mask以外区域像素值为DDIM编码得到的 x t x_t xt对应区域像素值,因此可映射回源图。
编码比例r决定可编辑能力,该值越大编辑能力更强,从而更好地匹配文本Q,代价为与输入图偏差更大。
理论分析:
对于输入图 x 0 x_0 x0经编码得到的 x r x_r xr,通过无条件DDIM可解码为 x 0 x_0 x0,虽然DIFFEDIT中基于文本Q为条件进行解码,但仍存在强偏置使得与原图接近。
实验
数据集:
ImageNet、Imagen、COCO
扩散模型:
mask分辨率32 * 32(ImageNet)、64 * 64(Imagen及COCO),使用DDIM采样50 step
ImageNet数据集上实验
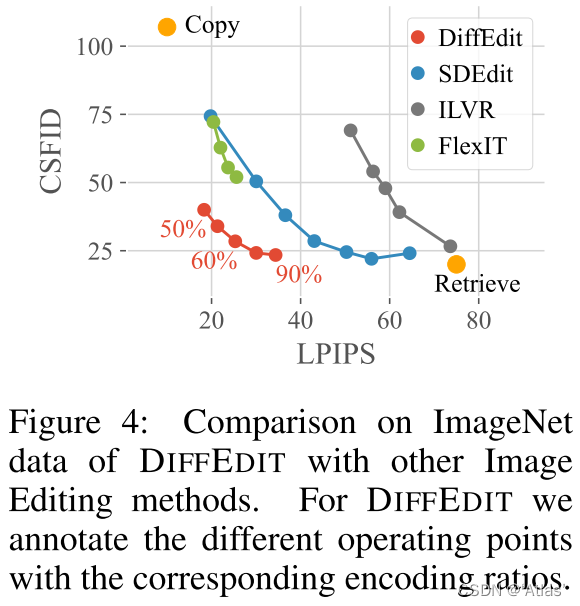
评估:使用LPIPS感知距离评估与输入图像距离,使用CSFID评估图片真实性以及与文本一致性,ImageNet为单目标因此适合。
越强的图像编辑能力,CSFID得分越低,但是导致图片与输入图不一致,导致LPIPS得分变高。图4表明DIFFEDIT相对于其他方案,在两者之间获得不错均衡。
消融实验
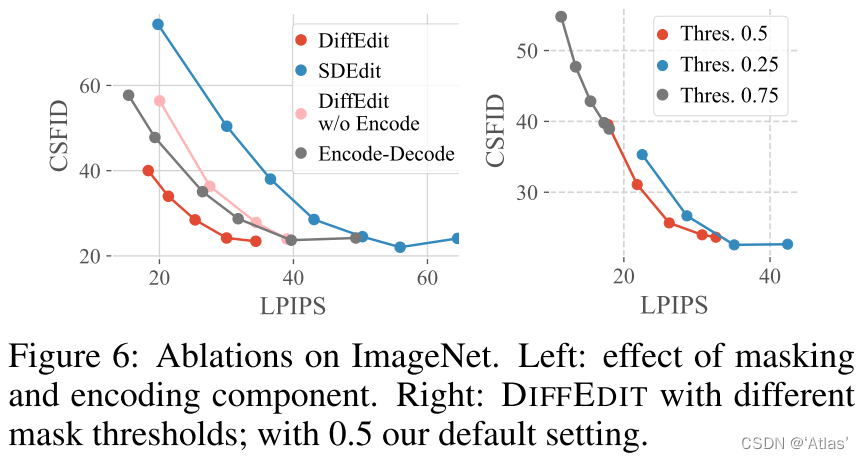
图6中Encode-Decode表示增加DDIM encoding,DiffEdit w/o Encode表示仅使用mask,图6左展示与SDEdit相比,两者均分别提升均衡性,并且两者结合展示出互补性。图5展示可视化结果。

图6右侧展示不同二值化阈值,阈值越低,mask区域越大,0.5可达到不错CSFID-LPIPS均衡。
IMAGEN数据集上实验
评估:使用FID评估图像逼真度,CLIP-Score评估图文一致性。
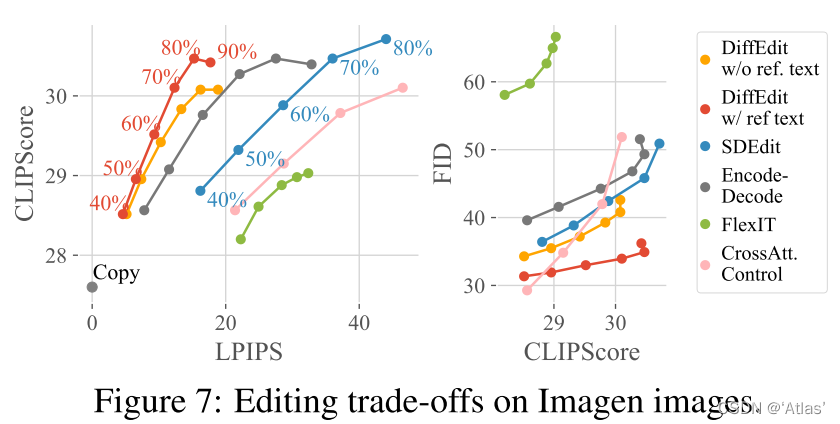
图7表明DIFFEDIT CLIP-LPIPS及FID-CLIP均衡。其中mask计算有两种:
w/ref. text:使用原始caption 作为参考text;
w/o ref. text:输入空text;
使用原始caption作为参考text获得最佳均衡。图8为可视化结果。使用参考text更容易忽视参考text及query text都描述的部分。

图9展示通过对比caption及query text推理所得mask。

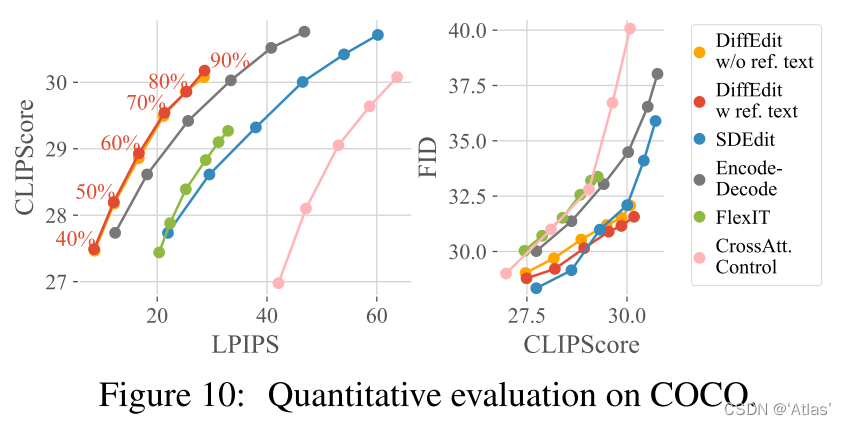
COCO数据集上实验
作者使用COCO验证集,query text与图片对应caption相似但不一致,如图15,以此评估图像编辑能力。评估指标使用CLIPScore, FID and LPIPS。

图10展示DIFFEDIT达到CLIP-LPIPS最佳均衡,但是最大CLIP得分低于SDEdit。
可视化结果如图11,第一列展示DDIM编码好处:能够纠正mask中目标的主要特性;最后三列表明允许选择输入图中不同目标进行不同编辑。

结论
DIFFEDIT,一种新颖的基于扩散模型的语义图像编辑算法。给出文本query,使用扩散模型,DIFFEDIT推理相关区域进行编辑而无用用户提供mask。利用DDIM编码输入图进行初始化生成过程,作者进行理论分析及实验表明该方法保留输入图更多的外观信息。在ImageNet,COCO,Imagen数据集展示不错编辑能力,并且超越之前方法。