文章目录
Regularized Logistic Regression
题目:微晶体质检
(吴恩达机器学习课后题链接放在最后)

输入:两次测试的结果
输出:微晶体质检结果(通过/驳回)
Training set

第一列为第一次测试结果,第二列为第二次测试结果,一二列为输入
第三列为晶体质检结果,即理想输出
处理Training set
file = pd.read_csv('E:/吴恩达机器学习/machine-learning-ex2/ex2/ex2data2.txt', header=None, names=['score1', 'score2', 'result'])
m = len(file['result'])
X = file.iloc[:,0:2]
y = file.iloc[:,2]
X = np.array(X, dtype='float64')
y = np.array(y, dtype='int32')
print(X, y)
运行结果如下
X:
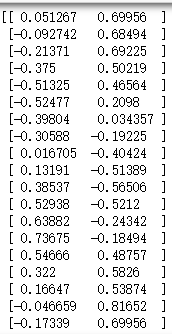
y :
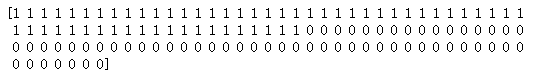
注意:这里的X并没有加入全1列,并不意味着不需要加全1列,而是会在下面的feature_mapping的加入。
数据可视化
**方式一:**lambda 表达式
func_shape = lambda x: 'o' if x == 1 else 'x'
func_color = lambda x: 'y' if x == 1 else 'k'
for i in range(m):
plt.scatter(file['score1'][i], file['score2'][i], marker = func_shape(file['result'][i]),color = func_color(file['result'][i]))
plt.show()
定义了两个lambda表达式,以绘制散点图时指定颜色和形状。

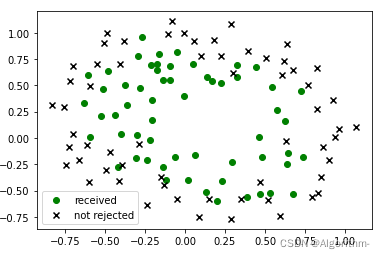
方式二:
received = file[file.result.values == 1]
rejected = file[file.result.values == 0]
l1 = plt.scatter(received.score1, received.score2, c='green',marker='o')
l2 = plt.scatter(rejected.score1, rejected.score2, c='black', marker='x')
plt.legend((l1, l2), ('received', 'not rejected'),loc='best')
plt.show()
在file中提取出result为0和1两种情况下的DataFrame,然后分别调用各自的score1、score2和result,指定颜色和形状等。
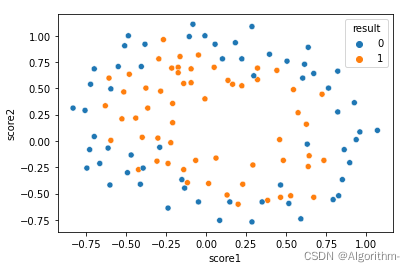
方式三:
import seaborn as sns
sns.scatterplot(x='score1',y='score2',hue='result',data=file)
用seaborn库方式比较方便,x和y为绘图的横纵坐标,均来自data中,hue指定类别。
Feature_mapping
由上面可视化的图可知,我们并不能很好的用一条直线来把两种结果的数据进行分离,所以如果不对特征值进行调整,而是直接用逻辑回归进行训练,可想而知并不能得到很好的效果。直接采用逻辑回归算法只能拟合出线性的决策边界。

一种能更好拟合数据的方法是创造更多的feature,使模型非线性化。
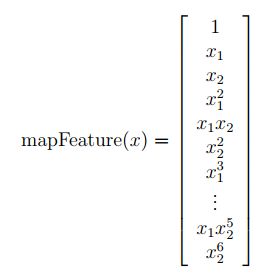
这里把feature map成power为6的多项式。我们的feature也从3维(两个feature和“1”)map成了28维。这时我们就可以通过数据拟合出更复杂的决策边界。
注意由于我们引入更多的feature,模型有可能会过拟合,所以我们需要对模型进行改进,加入正则项,即Regularized Logistic Regression。
代码如下:
方法一:
def feature_mapping2(X1, X2, power, as_ndarray=False):
data = {
"f{}{}".format(i- j, j):np.multiply(np.power(X1, i-j), np.power(X2,j))
for i in np.arange(power+1)
for j in np.arange(i+1)}
if as_ndarray:
return np.array(pd.DataFrame(data))
else:
return pd.DataFrame(data)
fxx就是多项式x1和x2的幂次。大家细心看一下应该都可以看明白,便于理解,这里展示DataFrame结果。(实际使用需要用ndarray形式)

方法二:
def feature_mapping(X1, X2):
X = np.ones((m, 1))
for i in range(1,7):
for j in range(i+1):
new1 = np.matrix([X1[k,l]**(i-j) for k in range(m) for l in range(1)])
new2 = np.matrix([X2[k,l]**j for k in range(m) for l in range(1)])
new = np.multiply(new1, new2)
new = new.transpose()
X = np.column_stack((X, new))
return X
[X1[k,l]**(i-j) for k in range(m) for l in range(1)] : 对X1列每个元素进行乘方操作,返回值是列表,需要转成矩阵,此时维数是(1, m)。
new = np.multiply(new1, new2) : new1和new2按元素相乘,由于new1和new2是矩阵,所以new也是矩阵,为(1, m)维,需要转置才能column_stack到新的一列。
sigmod函数

# sigmod func
def sigmod(z):
g_z = 1/(1+np.exp(-z))
return g_z
损失函数求解
首先定义权重theta、学习率alpha、迭代次数iterations
theta = np.zeros(X.shape[1])
theta定义为一维向量,个数和feature数相同,类型和X和y保持一致。
加入了正则化,损失函数CostFunction如下:
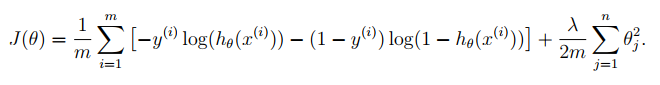
def costFunction(theta, X, y, lam):
first = - y @ np.log(sigmod(X@theta))
second = - (1 - y.transpose()) @ np.log(1 - sigmod(X@theta))
cost_reg = (lam/(2*m) * (np.power(theta[1:], 2).sum()))
J_theta = (1/m) * (first + second) + cost_reg
return J_theta
@ : 矩阵相乘
其中要特别说明:y为一维向量,在矩阵相乘@中,当y在@左侧,y作为行向量;当y在@右侧,y作为列向量。
梯度下降算法
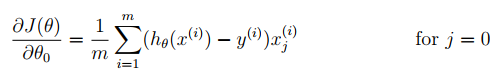
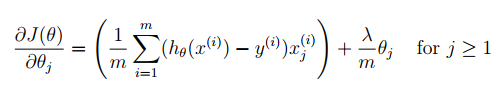
注意,梯度下降是不断更新权重theta,并不是更新X或y,之后权重会影响模型的预测效果,而与输入输出无关。
对每一个权重theta,更新时刻为累加完所有的m个代数值后,所得累加值在与学习率alpha和样本数据m进行运算后才进行theta更新。
在这里,因为x0=1,为常数。所以我们可以不对x0进行正则化,对结果并不会产生影响。
def gradient(theta, X, y, lam=1):
grad_reg = (lam/m) * np.concatenate((np.array([0]),theta[1:]),axis=0)
grad = (1/m) * (X.transpose() @ (sigmod(X @ theta) - y)) + grad_reg
return grad
下面用scipy.optimize库求解最优点。
import scipy.optimize as opt
lam = 1 # change lambda here
# 预测
result = opt.minimize(fun=costFunction,x0=theta,args=(X, y, lam),method='Newton-CG',jac=gradient)
fin_theta = result.x
y_pred = predict(X, fin_theta)
print(result)
参数fun:代价函数;x0为初始theta;args为fun中除了theta外还需额外传入的参数;method为所用算法,jac为梯度函数,需要return 权重更新的部分。
注意:传入的x0需要是一维,同样,gradint函数的返回值也要是一维向量,以便和x0进行权重更新。
可视化
绘制决策边界(本次python实现的难点)
绘制思路:
要绘制决策边界,就要找到sigmod()函数输出为0.5的点,也就是X@theta = 0。
我们的方法是,在(-1, -1)到(1.5, 1.5)的方形内,选取一定的点,对方形内的点经过feature_mapping后逐个分析,判断X@theta是否为0。当然,恰好等于0的条件有些严格,我们可以取一个阈值,当计算的X@theta小于阈值时,即画出该点。最后,我们总结步骤如下:
选定方形和取点密度->提取方形内的点->对每一个点进行feature_mapping->判断X@theta < threshold? -> 小于则画出该点
def draw_boundary(power=6):
density = 1000
threshold = 0.001
x, y = find_db(density,6,fin_theta,threshold)
for i in range(m):
plt.scatter(file['score1'][i], file['score2'][i], marker = func_shape(file['result'][i]),color = func_color(file['result'][i]))
plt.scatter(x, y, c='r', s=10)
plt.title("Decision Boundary")
plt.show()
def find_db(density, power, theta, threshold):
t1 = np.linspace(-1, 1.5, density)
t2 = np.linspace(-1, 1.5, density)
# 输出1000*1000的所有点(zip方法)
cordinates = [(x,y) for x in t1 for y in t2]
t1, t2 = zip(*cordinates)
mapped_feature = feature_mapping2(t1, t2, power) # 返回df
inner = mapped_feature.values @ theta
decision = mapped_feature[abs(inner) < threshold ]
return decision.f10, decision.f01
find_db函数:返回满足阈值条件的点的x1和x2。
draw_boundary函数:绘制返回的满足条件的点。
这里对如下代码进行详解:
t1 = np.linspace(-1, 1.5, density)
t2 = np.linspace(-1, 1.5, density)
cordinates = [(x,y) for x in t1 for y in t2]
t1, t2 = zip(*cordinates)
取定t1和t2后,如果把t1和t2画出来,则会是一条直线,由(-1, -1)到(1.5, 1.5),要怎么把所有的点进行表示呢?
用两个for循环把所有的点存放到cordinates里,在用zip函数把cordinates里的所有x赋值给t1,所有的y赋值给t2。
下面比较不同lambda的决策边界
lam = 1
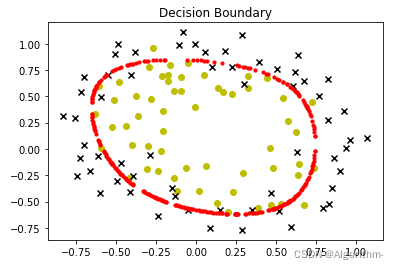
lam = 0.05
过拟合 overfitting
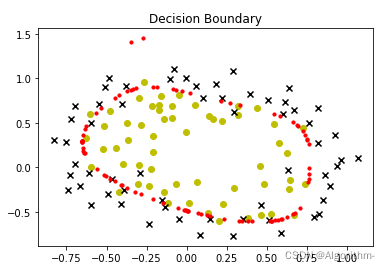
lam = 10
欠拟合 underfitting
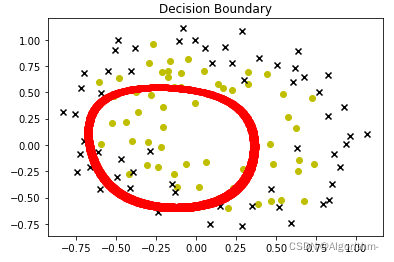
预测
lam = 1情况下。
def predict(score1,score2, final_theta):
data = {
"f{}{}".format(i- j, j):[np.multiply(np.power(0.4, i-j), np.power(0.6,j))]
for i in np.arange(6+1)
for j in np.arange(i+1)}
input = np.array(pd.DataFrame(data))
prob = sigmod(input@final_theta)
return (prob>=0.5).astype(int)
predict(0.4, 0.6,fin_theta)
传入参数:两次测试成绩。
输出:微晶体质检结果。

上一篇Logistic Regression放在另一个文章里,点击这里跳转
欢迎评论区留言讨论。
NG Machine Learning Courses
链接:https://pan.baidu.com/s/1FoAQNRdevsqYzW4a5QDsBw
提取码:0wdr