数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个DataStream转换为新的DataStream。

基本转换算子(map/ filter/ flatMap)
WaterSensor.java
package com.atguigu.bean;
import java.util.Objects;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class WaterSensor {
public String id;
public Long ts;
public Integer vc;
// 一定要提供一个 空参 的构造器
public WaterSensor() {
}
public WaterSensor(String id, Long ts, Integer vc) {
this.id = id;
this.ts = ts;
this.vc = vc;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public Long getTs() {
return ts;
}
public void setTs(Long ts) {
this.ts = ts;
}
public Integer getVc() {
return vc;
}
public void setVc(Integer vc) {
this.vc = vc;
}
@Override
public String toString() {
return "WaterSensor{" +
"id='" + id + '\'' +
", ts=" + ts +
", vc=" + vc +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
WaterSensor that = (WaterSensor) o;
return Objects.equals(id, that.id) &&
Objects.equals(ts, that.ts) &&
Objects.equals(vc, that.vc);
}
@Override
public int hashCode() {
return Objects.hash(id, ts, vc);
}
}
映射(map)
map是大家非常熟悉的大数据操作算子,主要用于将数据流中的数据进行转换,形成新的数据流。简单来说,就是一个“一一映射”,消费一个元素就产出一个元素。
我们只需要基于DataStream调用map()方法就可以进行转换处理。方法需要传入的参数是接口MapFunction的实现;返回值类型还是DataStream,不过泛型(流中的元素类型)可能改变。
下面的代码用不同的方式,实现了提取WaterSensor中的id字段的功能。
public class TransMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1L, 1),
new WaterSensor("sensor_2", 2L, 2)
);
// 方式一:传入匿名类,实现MapFunction
stream.map(new MapFunction<WaterSensor, String>() {
@Override
public String map(WaterSensor e) throws Exception {
return e.id;
}
}).print();
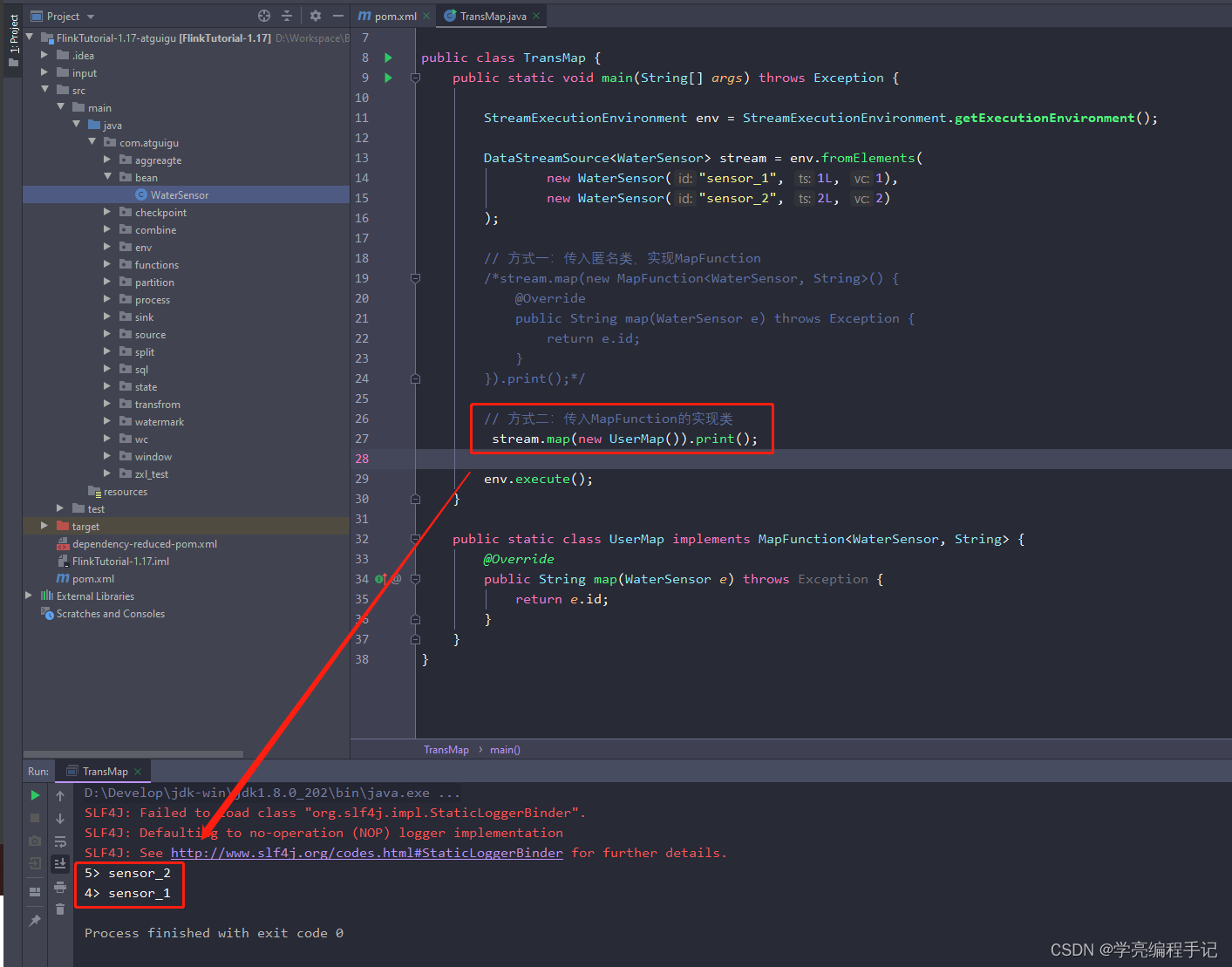
// 方式二:传入MapFunction的实现类
// stream.map(new UserMap()).print();
env.execute();
}
public static class UserMap implements MapFunction<WaterSensor, String> {
@Override
public String map(WaterSensor e) throws Exception {
return e.id;
}
}
}
执行结果:
方式一:传入匿名类,实现MapFunction
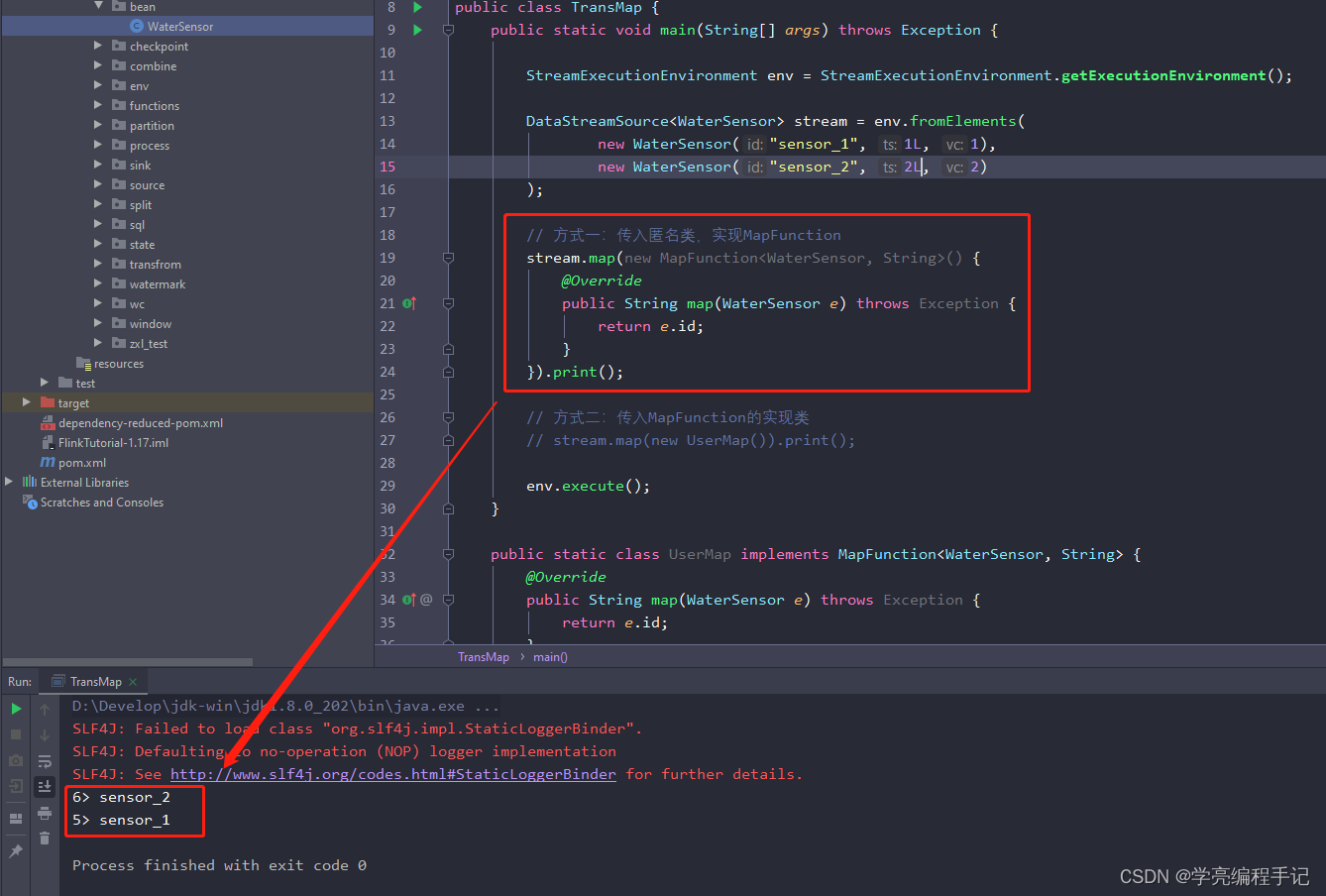
方式二:传入MapFunction的实现类
上面代码中,MapFunction实现类的泛型类型,与输入数据类型和输出数据的类型有关。在实现MapFunction接口的时候,需要指定两个泛型,分别是输入事件和输出事件的类型,还需要重写一个map()方法,定义从一个输入事件转换为另一个输出事件的具体逻辑。
过滤(filter)
filter转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为true则元素正常输出,若为false则元素被过滤掉。
进行filter转换之后的新数据流的数据类型与原数据流是相同的。filter转换需要传入的参数需要实现FilterFunction接口,而FilterFunction内要实现filter()方法,就相当于一个返回布尔类型的条件表达式。
案例需求:下面的代码会将数据流中传感器id为sensor_1的数据过滤出来。
package com.atguigu.zxl_test;
import com.atguigu.bean.WaterSensor;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1L, 1),
new WaterSensor("sensor_1", 2L, 2),
new WaterSensor("sensor_2", 2L, 2),
new WaterSensor("sensor_3", 3L, 3)
);
// 方式一:传入匿名类实现FilterFunction
stream.filter(new FilterFunction<WaterSensor>() {
@Override
public boolean filter(WaterSensor e) throws Exception {
return e.id.equals("sensor_1");
}
}).print();
// 方式二:传入FilterFunction实现类
// stream.filter(new UserFilter()).print();
env.execute();
}
public static class UserFilter implements FilterFunction<WaterSensor> {
@Override
public boolean filter(WaterSensor e) throws Exception {
return e.id.equals("sensor_1");
}
}
}
执行结果:
方式一:传入匿名类实现FilterFunction
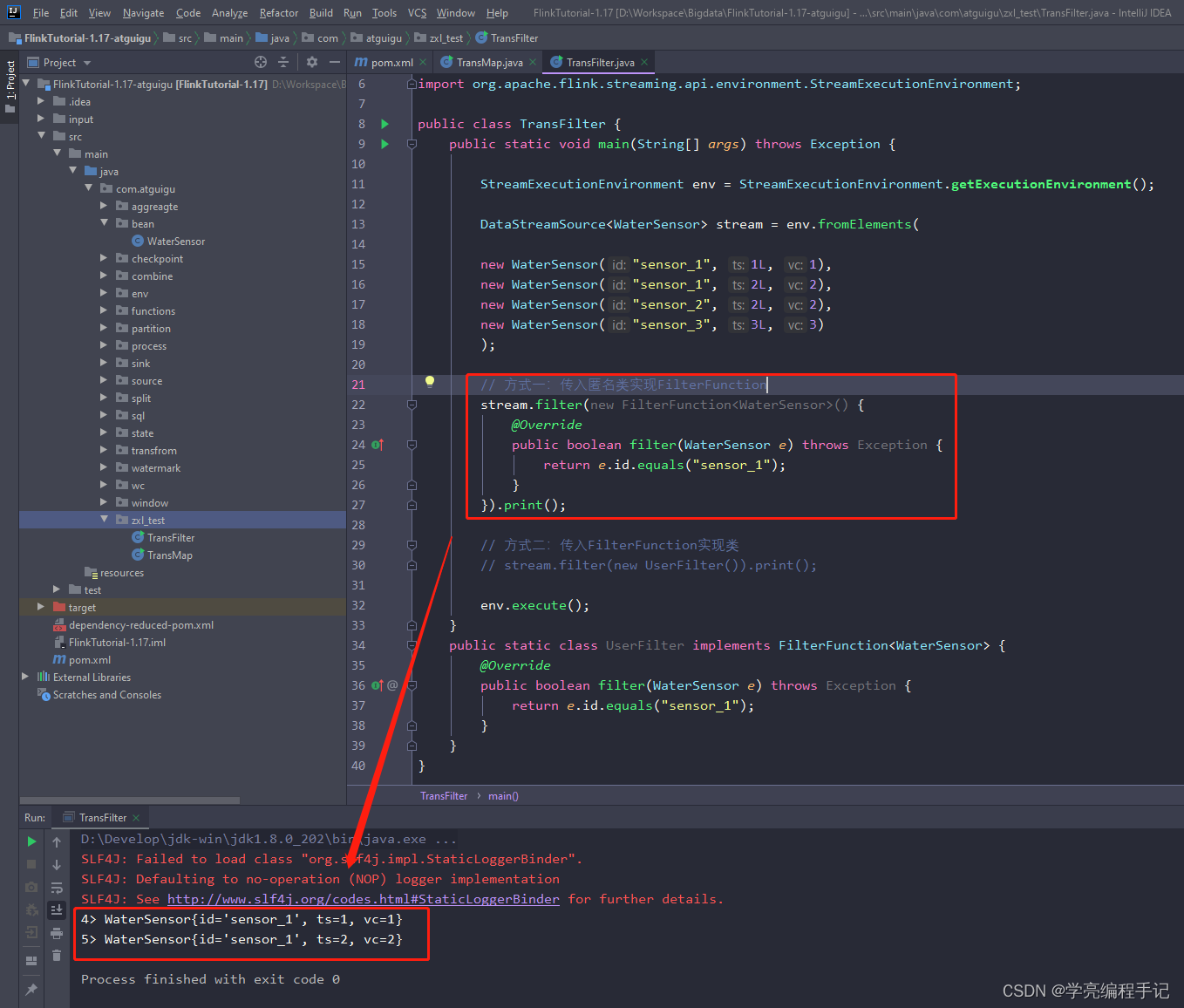
方式二:传入FilterFunction实现类

扁平映射(flatMap)
flatMap操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生0到多个元素。flatMap可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。
同map一样,flatMap也可以使用Lambda表达式或者FlatMapFunction接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。
案例需求:如果输入的数据是sensor_1,只打印vc;如果输入的数据是sensor_2,既打印ts又打印vc。
实现代码如下:
package com.atguigu.zxl_test;
import com.atguigu.bean.WaterSensor;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class TransFlatmap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1L, 1),
new WaterSensor("sensor_1", 2L, 2),
new WaterSensor("sensor_2", 2L, 2),
new WaterSensor("sensor_3", 3L, 3)
);
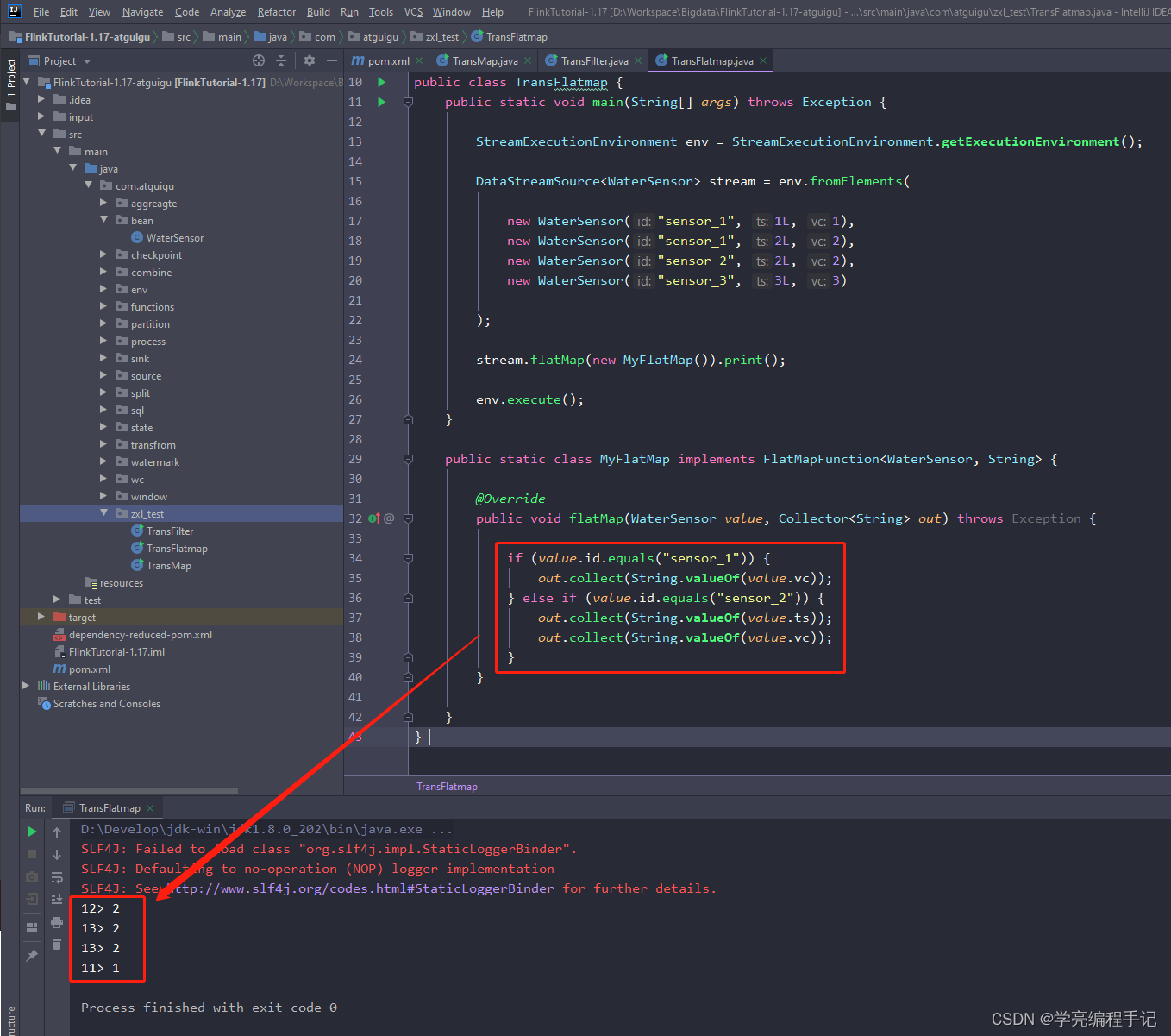
stream.flatMap(new MyFlatMap()).print();
env.execute();
}
public static class MyFlatMap implements FlatMapFunction<WaterSensor, String> {
@Override
public void flatMap(WaterSensor value, Collector<String> out) throws Exception {
if (value.id.equals("sensor_1")) {
out.collect(String.valueOf(value.vc));
} else if (value.id.equals("sensor_2")) {
out.collect(String.valueOf(value.ts));
out.collect(String.valueOf(value.vc));
}
}
}
}
执行结果:
聚合算子(Aggregation)
计算的结果不仅依赖当前数据,还跟之前的数据有关,相当于要把所有数据聚在一起进行汇总合并——这就是所谓的“聚合”(Aggregation),类似于MapReduce中的reduce操作。
按键分区(keyBy)
对于Flink而言,DataStream是没有直接进行聚合的API的。因为我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在Flink中,要做聚合,需要先进行分区;这个操作就是通过keyBy来完成的。
keyBy是聚合前必须要用到的一个算子。keyBy通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务。
基于不同的key,流中的数据将被分配到不同的分区中去;这样一来,所有具有相同的key的数据,都将被发往同一个分区。
在内部,是通过计算key的哈希值(hash code),对分区数进行取模运算来实现的。所以这里key如果是POJO的话,必须要重写hashCode()方法。
keyBy()方法需要传入一个参数,这个参数指定了一个或一组key。有很多不同的方法来指定key:比如对于Tuple数据类型,可以指定字段的位置或者多个位置的组合;对于POJO类型,可以指定字段的名称(String);另外,还可以传入Lambda表达式或者实现一个键选择器(KeySelector),用于说明从数据中提取key的逻辑。
我们可以以id作为key做一个分区操作,代码实现如下:
package com.atguigu.zxl_test;
import com.atguigu.bean.WaterSensor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransKeyBy {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1L, 1),
new WaterSensor("sensor_1", 2L, 2),
new WaterSensor("sensor_2", 2L, 2),
new WaterSensor("sensor_3", 3L, 3)
);
// 方式一:使用Lambda表达式
KeyedStream<WaterSensor, String> keyedStream = stream.keyBy(e -> e.id);
// 添加操作符,例如打印结果 解决报错:No operators defined in streaming topology. Cannot execute.
keyedStream.print();
// 方式二:使用匿名类实现KeySelector
/*KeyedStream<WaterSensor, String> keyedStream1 = stream.keyBy(new KeySelector<WaterSensor, String>() {
@Override
public String getKey(WaterSensor e) throws Exception {
return e.id;
}
});
// 添加操作符,例如打印结果 解决报错:No operators defined in streaming topology. Cannot execute.
keyedStream1.print();*/
env.execute();
}
}
执行结果:
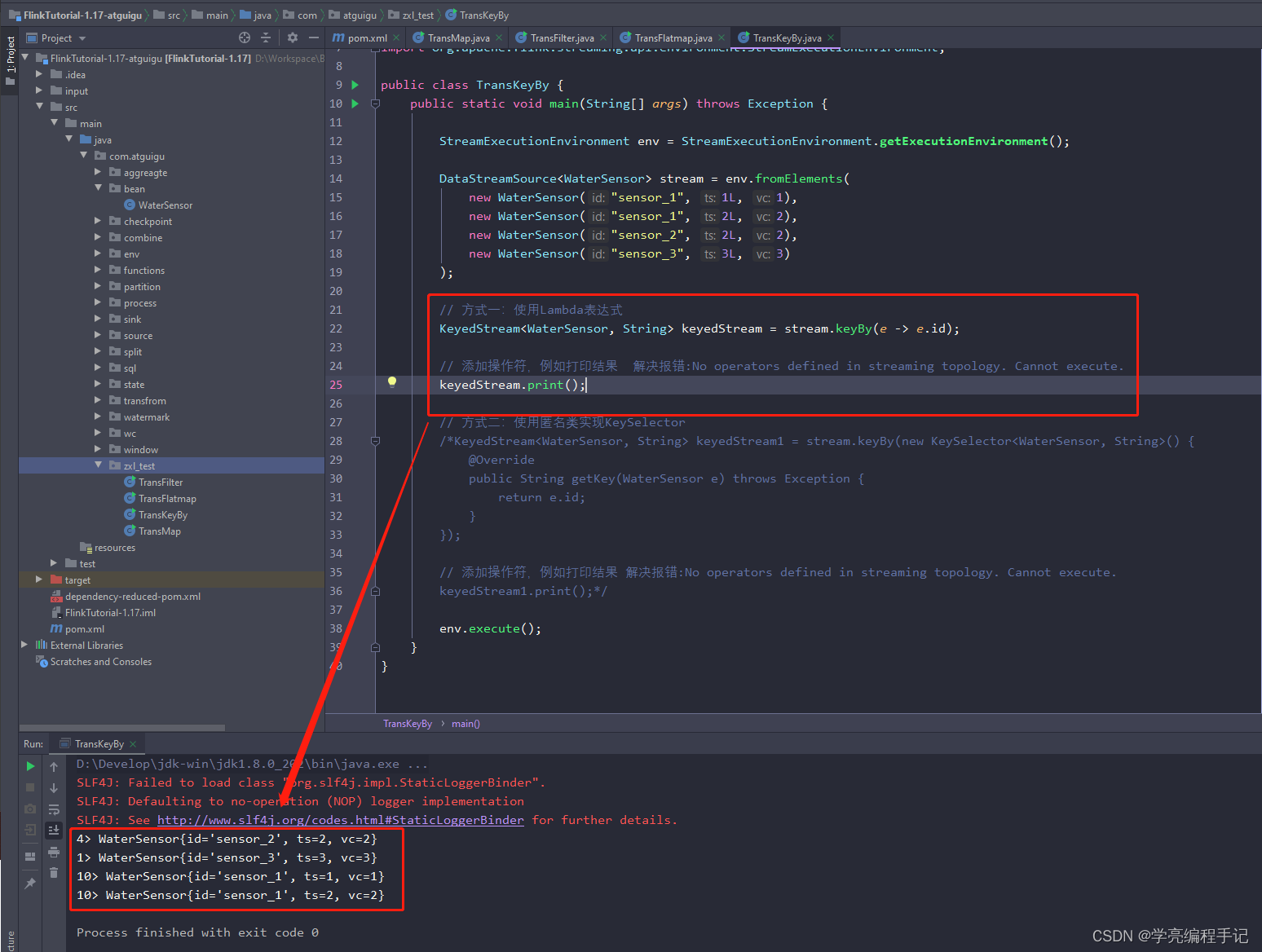
需要注意的是,keyBy得到的结果将不再是DataStream,而是会将DataStream转换为KeyedStream。KeyedStream可以认为是“分区流”或者“键控流”,它是对DataStream按照key的一个逻辑分区,所以泛型有两个类型:除去当前流中的元素类型外,还需要指定key的类型。
KeyedStream也继承自DataStream,所以基于它的操作也都归属于DataStream API。但它跟之前的转换操作得到的SingleOutputStreamOperator不同,只是一个流的分区操作,并不是一个转换算子。KeyedStream是一个非常重要的数据结构,只有基于它才可以做后续的聚合操作(比如sum,reduce)。
简单聚合(sum/min/max/minBy/maxBy)
有了按键分区的数据流KeyedStream,我们就可以基于它进行聚合操作了。Flink为我们内置实现了一些最基本、最简单的聚合API,主要有以下几种:
- sum():在输入流上,对指定的字段做叠加求和的操作。
- min():在输入流上,对指定的字段求最小值。
- max():在输入流上,对指定的字段求最大值。
- minBy():与min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而minBy()则会返回包含字段最小值的整条数据。
- maxBy():与max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
简单聚合算子使用非常方便,语义也非常明确。这些聚合方法调用时,也需要传入参数;但并不像基本转换算子那样需要实现自定义函数,只要说明聚合指定的字段就可以了。指定字段的方式有两种:指定位置,和指定名称。
对于元组类型的数据,可以使用这两种方式来指定字段。需要注意的是,元组中字段的名称,是以f0、f1、f2、…来命名的。
如果数据流的类型是POJO类,那么就只能通过字段名称来指定,不能通过位置来指定了。
public class TransAggregation {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
stream.keyBy(e -> e.id).max("vc"); // 指定字段名称
env.execute();
}
}
简单聚合算子返回的,同样是一个SingleOutputStreamOperator,也就是从KeyedStream又转换成了常规的DataStream。所以可以这样理解:keyBy和聚合是成对出现的,先分区、后聚合,得到的依然是一个DataStream。而且经过简单聚合之后的数据流,元素的数据类型保持不变。
一个聚合算子,会为每一个key保存一个聚合的值,在Flink中我们把它叫作“状态”(state)。所以每当有一个新的数据输入,算子就会更新保存的聚合结果,并发送一个带有更新后聚合值的事件到下游算子。对于无界流来说,这些状态是永远不会被清除的,所以我们使用聚合算子,应该只用在含有有限个key的数据流上。
归约聚合(reduce)
reduce可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
reduce操作也会将KeyedStream转换为DataStream。它不会改变流的元素数据类型,所以输出类型和输入类型是一样的。
调用KeyedStream的reduce方法时,需要传入一个参数,实现ReduceFunction接口。接口在源码中的定义如下:
public interface ReduceFunction<T> extends Function, Serializable {
T reduce(T value1, T value2) throws Exception;
}
ReduceFunction接口里需要实现reduce()方法,这个方法接收两个输入事件,经过转换处理之后输出一个相同类型的事件。在流处理的底层实现过程中,实际上是将中间“合并的结果”作为任务的一个状态保存起来的;之后每来一个新的数据,就和之前的聚合状态进一步做归约。
我们可以单独定义一个函数类实现ReduceFunction接口,也可以直接传入一个匿名类。当然,同样也可以通过传入Lambda表达式实现类似的功能。
为了方便后续使用,定义一个WaterSensorMapFunction:
public class WaterSensorMapFunction implements MapFunction<String,WaterSensor> {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0],Long.valueOf(datas[1]) ,Integer.valueOf(datas[2]) );
}
}
案例:使用reduce实现max和maxBy的功能。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction())
.keyBy(WaterSensor::getId)
.reduce(new ReduceFunction<WaterSensor>()
{
@Override
public WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {
System.out.println("Demo7_Reduce.reduce");
int maxVc = Math.max(value1.getVc(), value2.getVc());
//实现max(vc)的效果 取最大值,其他字段以当前组的第一个为主
//value1.setVc(maxVc);
//实现maxBy(vc)的效果 取当前最大值的所有字段
if (value1.getVc() > value2.getVc()){
value1.setVc(maxVc);
return value1;
}else {
value2.setVc(maxVc);
return value2;
}
}
})
.print();
env.execute();
reduce同简单聚合算子一样,也要针对每一个key保存状态。因为状态不会清空,所以我们需要将reduce算子作用在一个有限key的流上。
用户自定义函数(UDF)
用户自定义函数(user-defined function,UDF),即用户可以根据自身需求,重新实现算子的逻辑。
用户自定义函数分为:函数类、匿名函数、富函数类。
函数类(Function Classes)
Flink暴露了所有UDF函数的接口,具体实现方式为接口或者抽象类,例如MapFunction、FilterFunction、ReduceFunction等。所以用户可以自定义一个函数类,实现对应的接口。
需求:用来从用户的点击数据中筛选包含“sensor_1”的内容:
方式一:实现FilterFunction接口
public class TransFunctionUDF {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
DataStream<String> filter = stream.filter(new UserFilter());
filter.print();
env.execute();
}
public static class UserFilter implements FilterFunction<WaterSensor> {
@Override
public boolean filter(WaterSensor e) throws Exception {
return e.id.equals("sensor_1");
}
}
}
方式二:通过匿名类来实现FilterFunction接口:
DataStream<String> stream = stream.filter(new FilterFunction< WaterSensor>() {
@Override
public boolean filter(WaterSensor e) throws Exception {
return e.id.equals("sensor_1");
}
});
方式二的优化:为了类可以更加通用,我们还可以将用于过滤的关键字"home"抽象出来作为类的属性,调用构造方法时传进去。
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
DataStream<String> stream = stream.filter(new FilterFunctionImpl("sensor_1"));
public static class FilterFunctionImpl implements FilterFunction<WaterSensor> {
private String id;
FilterFunctionImpl(String id) {
this.id=id; }
@Override
public boolean filter(WaterSensor value) throws Exception {
return thid.id.equals(value.id);
}
}
方式三:采用匿名函数(Lambda)
public class TransFunctionUDF {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
//map函数使用Lambda表达式,不需要进行类型声明
SingleOutputStreamOperator<String> filter = stream.filter(sensor -> "sensor_1".equals(sensor.id));
filter.print();
env.execute();
}
}
富函数类(Rich Function Classes)
“富函数类”也是DataStream API提供的一个函数类的接口,所有的Flink函数类都有其Rich版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction等。
与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
Rich Function有生命周期的概念。典型的生命周期方法有:
- open()方法,是Rich Function的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如map()或者filter()方法被调用之前,open()会首先被调用。
- close()方法,是生命周期中的最后一个调用的方法,类似于结束方法。一般用来做一些清理工作。
需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如RichMapFunction中的map(),在每条数据到来后都会触发一次调用。
来看一个例子说明:
public class RichFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env
.fromElements(1,2,3,4)
.map(new RichMapFunction<Integer, Integer>() {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("索引是:" + getRuntimeContext().getIndexOfThisSubtask() + " 的任务的生命周期开始");
}
@Override
public Integer map(Integer integer) throws Exception {
return integer + 1;
}
@Override
public void close() throws Exception {
super.close();
System.out.println("索引是:" + getRuntimeContext().getIndexOfThisSubtask() + " 的任务的生命周期结束");
}
})
.print();
env.execute();
}
}
物理分区算子(Physical Partitioning)
常见的物理分区策略有:随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)。
随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用DataStream的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
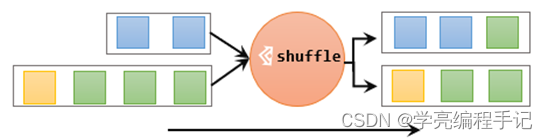
经过随机分区之后,得到的依然是一个DataStream。
我们可以做个简单测试:将数据读入之后直接打印到控制台,将输出的并行度设置为2,中间经历一次shuffle。执行多次,观察结果是否相同。
public class ShuffleExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Integer> stream = env.socketTextStream("hadoop102", 7777);;
stream.shuffle().print()
env.execute();
}
}
轮询分区(Round-Robin)
轮询,简单来说就是“发牌”,按照先后顺序将数据做依次分发。通过调用DataStream的.rebalance()方法,就可以实现轮询重分区。rebalance使用的是Round-Robin负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
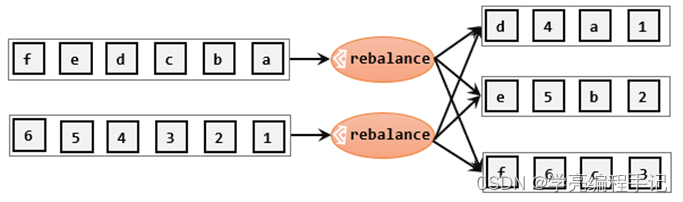
stream.rebalance()
重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用rescale()方法时,其实底层也是使用Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中。rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
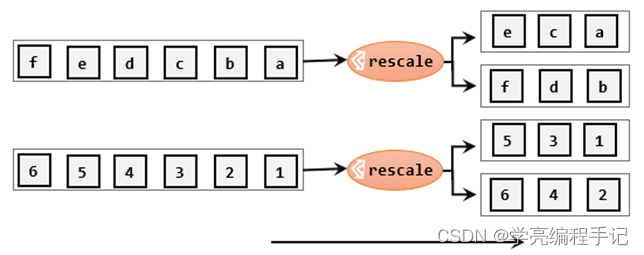
stream.rescale()
广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用DataStream的broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
stream.broadcast()
全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
stream.global()
自定义分区(Custom)
当Flink提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。
1)自定义分区器
public class MyPartitioner implements Partitioner<String> {
@Override
public int partition(String key, int numPartitions) {
return Integer.parseInt(key) % numPartitions;
}
}
2)使用自定义分区
public class PartitionCustomDemo {
public static void main(String[] args) throws Exception {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(2);
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
DataStream<String> myDS = socketDS
.partitionCustom(
new MyPartitioner(),
value -> value);
myDS.print();
env.execute();
}
}
分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一DataStream,定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。
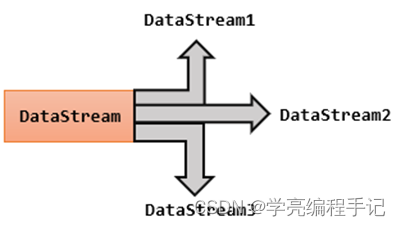
简单实现
其实根据条件筛选数据的需求,本身非常容易实现:只要针对同一条流多次独立调用.filter()方法进行筛选,就可以得到拆分之后的流了。
案例需求:读取一个整数数字流,将数据流划分为奇数流和偶数流。
代码实现:
public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<Integer> ds = env.socketTextStream("hadoop102", 7777)
.map(Integer::valueOf);
//将ds 分为两个流 ,一个是奇数流,一个是偶数流
//使用filter 过滤两次
SingleOutputStreamOperator<Integer> ds1 = ds.filter(x -> x % 2 == 0);
SingleOutputStreamOperator<Integer> ds2 = ds.filter(x -> x % 2 == 1);
ds1.print("偶数");
ds2.print("奇数");
env.execute();
}
}
这种实现非常简单,但代码显得有些冗余——我们的处理逻辑对拆分出的三条流其实是一样的,却重复写了三次。而且这段代码背后的含义,是将原始数据流stream复制三份,然后对每一份分别做筛选;这明显是不够高效的。我们自然想到,能不能不用复制流,直接用一个算子就把它们都拆分开呢?
使用侧输出流
关于处理函数中侧输出流的用法,我们已经在7.5节做了详细介绍。简单来说,只需要调用上下文ctx的.output()方法,就可以输出任意类型的数据了。而侧输出流的标记和提取,都离不开一个“输出标签”(OutputTag),指定了侧输出流的id和类型。
代码实现:将WaterSensor按照Id类型进行分流。
public class SplitStreamByOutputTag {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<WaterSensor> ds = env.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());
OutputTag<WaterSensor> s1 = new OutputTag<>("s1", Types.POJO(WaterSensor.class)){
};
OutputTag<WaterSensor> s2 = new OutputTag<>("s2", Types.POJO(WaterSensor.class)){
};
//返回的都是主流
SingleOutputStreamOperator<WaterSensor> ds1 = ds.process(new ProcessFunction<WaterSensor, WaterSensor>()
{
@Override
public void processElement(WaterSensor value, Context ctx, Collector<WaterSensor> out) throws Exception {
if ("s1".equals(value.getId())) {
ctx.output(s1, value);
} else if ("s2".equals(value.getId())) {
ctx.output(s2, value);
} else {
//主流
out.collect(value);
}
}
});
ds1.print("主流,非s1,s2的传感器");
SideOutputDataStream<WaterSensor> s1DS = ds1.getSideOutput(s1);
SideOutputDataStream<WaterSensor> s2DS = ds1.getSideOutput(s2);
s1DS.printToErr("s1");
s2DS.printToErr("s2");
env.execute();
}
}
基本合流操作
在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以Flink中合流的操作会更加普遍,对应的API也更加丰富。
联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。
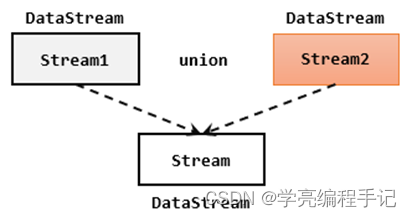
在代码中,我们只要基于DataStream直接调用.union()方法,传入其他DataStream作为参数,就可以实现流的联合了;得到的依然是一个DataStream:stream1.union(stream2, stream3, ...)
注意:union()的参数可以是多个DataStream,所以联合操作可以实现多条流的合并。
代码实现:我们可以用下面的代码做一个简单测试:
public class UnionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> ds1 = env.fromElements(1, 2, 3);
DataStreamSource<Integer> ds2 = env.fromElements(2, 2, 3);
DataStreamSource<String> ds3 = env.fromElements("2", "2", "3");
ds1.union(ds2,ds3.map(Integer::valueOf))
.print();
env.execute();
}
}
连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少出现。除了联合(union),Flink还提供了另外一种方便的合流操作——连接(connect)。
1)连接流(ConnectedStreams)
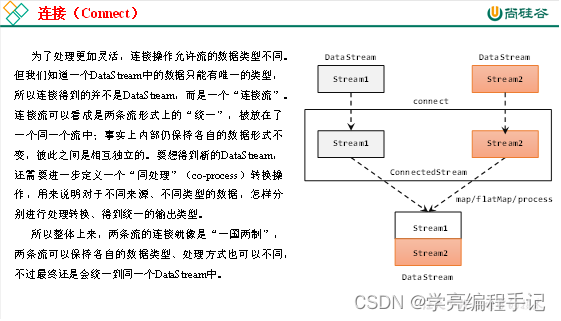
代码实现:需要分为两步:首先基于一条DataStream调用.connect()方法,传入另外一条DataStream作为参数,将两条流连接起来,得到一个ConnectedStreams;然后再调用同处理方法得到DataStream。这里可以的调用的同处理方法有.map()/.flatMap(),以及.process()方法。
public class ConnectDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// DataStreamSource<Integer> source1 = env.fromElements(1, 2, 3);
// DataStreamSource<String> source2 = env.fromElements("a", "b", "c");
SingleOutputStreamOperator<Integer> source1 = env
.socketTextStream("hadoop102", 7777)
.map(i -> Integer.parseInt(i));
DataStreamSource<String> source2 = env.socketTextStream("hadoop102", 8888);
/**
* TODO 使用 connect 合流
* 1、一次只能连接 2条流
* 2、流的数据类型可以不一样
* 3、 连接后可以调用 map、flatmap、process来处理,但是各处理各的
*/
ConnectedStreams<Integer, String> connect = source1.connect(source2);
SingleOutputStreamOperator<String> result = connect.map(new CoMapFunction<Integer, String, String>() {
@Override
public String map1(Integer value) throws Exception {
return "来源于数字流:" + value.toString();
}
@Override
public String map2(String value) throws Exception {
return "来源于字母流:" + value;
}
});
result.print();
env.execute(); }
}
上面的代码中,ConnectedStreams有两个类型参数,分别表示内部包含的两条流各自的数据类型;由于需要“一国两制”,因此调用.map()方法时传入的不再是一个简单的MapFunction,而是一个CoMapFunction,表示分别对两条流中的数据执行map操作。这个接口有三个类型参数,依次表示第一条流、第二条流,以及合并后的流中的数据类型。需要实现的方法也非常直白:.map1()就是对第一条流中数据的map操作,.map2()则是针对第二条流。
2)CoProcessFunction
与CoMapFunction类似,如果是调用.map()就需要传入一个CoMapFunction,需要实现map1()、map2()两个方法;而调用.process()时,传入的则是一个CoProcessFunction。它也是“处理函数”家族中的一员,用法非常相似。它需要实现的就是processElement1()、processElement2()两个方法,在每个数据到来时,会根据来源的流调用其中的一个方法进行处理。
值得一提的是,ConnectedStreams也可以直接调用.keyBy()进行按键分区的操作,得到的还是一个ConnectedStreams:
connectedStreams.keyBy(keySelector1, keySelector2);
这里传入两个参数keySelector1和keySelector2,是两条流中各自的键选择器;当然也可以直接传入键的位置值(keyPosition),或者键的字段名(field),这与普通的keyBy用法完全一致。ConnectedStreams进行keyBy操作,其实就是把两条流中key相同的数据放到了一起,然后针对来源的流再做各自处理,这在一些场景下非常有用。
案例需求:连接两条流,输出能根据id匹配上的数据(类似inner join效果)
public class ConnectKeybyDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Tuple2<Integer, String>> source1 = env.fromElements(
Tuple2.of(1, "a1"),
Tuple2.of(1, "a2"),
Tuple2.of(2, "b"),
Tuple2.of(3, "c")
);
DataStreamSource<Tuple3<Integer, String, Integer>> source2 = env.fromElements(
Tuple3.of(1, "aa1", 1),
Tuple3.of(1, "aa2", 2),
Tuple3.of(2, "bb", 1),
Tuple3.of(3, "cc", 1)
);
ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connect = source1.connect(source2);
// 多并行度下,需要根据 关联条件 进行keyby,才能保证key相同的数据到一起去,才能匹配上
ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connectKey = connect.keyBy(s1 -> s1.f0, s2 -> s2.f0);
SingleOutputStreamOperator<String> result = connectKey.process(
new CoProcessFunction<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>, String>() {
// 定义 HashMap,缓存来过的数据,key=id,value=list<数据>
Map<Integer, List<Tuple2<Integer, String>>> s1Cache = new HashMap<>();
Map<Integer, List<Tuple3<Integer, String, Integer>>> s2Cache = new HashMap<>();
@Override
public void processElement1(Tuple2<Integer, String> value, Context ctx, Collector<String> out) throws Exception {
Integer id = value.f0;
// TODO 1.来过的s1数据,都存起来
if (!s1Cache.containsKey(id)) {
// 1.1 第一条数据,初始化 value的list,放入 hashmap
List<Tuple2<Integer, String>> s1Values = new ArrayList<>();
s1Values.add(value);
s1Cache.put(id, s1Values);
} else {
// 1.2 不是第一条,直接添加到 list中
s1Cache.get(id).add(value);
}
//TODO 2.根据id,查找s2的数据,只输出 匹配上 的数据
if (s2Cache.containsKey(id)) {
for (Tuple3<Integer, String, Integer> s2Element : s2Cache.get(id)) {
out.collect("s1:" + value + "<--------->s2:" + s2Element);
}
}
}
@Override
public void processElement2(Tuple3<Integer, String, Integer> value, Context ctx, Collector<String> out) throws Exception {
Integer id = value.f0;
// TODO 1.来过的s2数据,都存起来
if (!s2Cache.containsKey(id)) {
// 1.1 第一条数据,初始化 value的list,放入 hashmap
List<Tuple3<Integer, String, Integer>> s2Values = new ArrayList<>();
s2Values.add(value);
s2Cache.put(id, s2Values);
} else {
// 1.2 不是第一条,直接添加到 list中
s2Cache.get(id).add(value);
}
//TODO 2.根据id,查找s1的数据,只输出 匹配上 的数据
if (s1Cache.containsKey(id)) {
for (Tuple2<Integer, String> s1Element : s1Cache.get(id)) {
out.collect("s1:" + s1Element + "<--------->s2:" + value);
}
}
}
});
result.print();
env.execute();
}
}