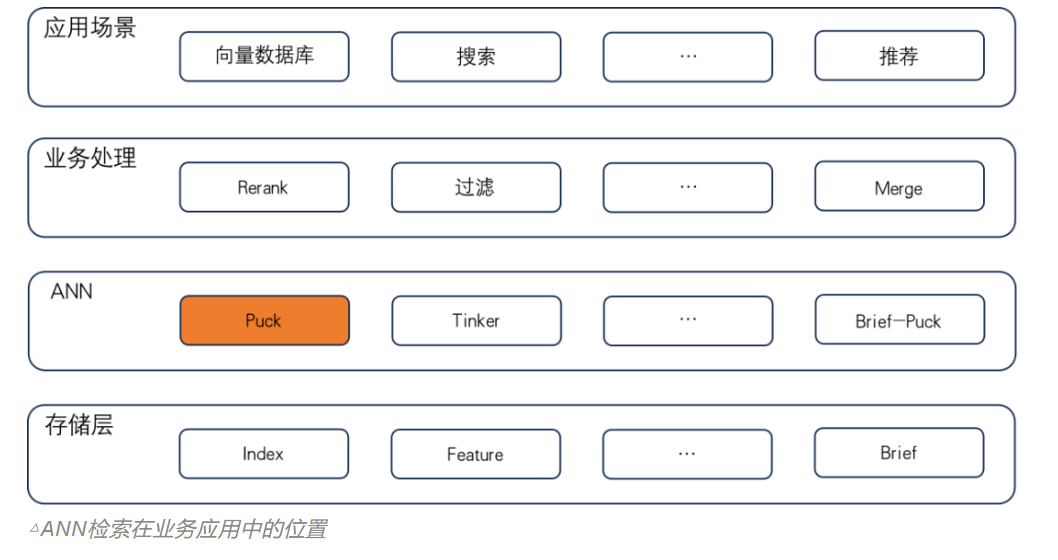
百度宣布在 Apache 2.0 协议下开源自研的 ANN 检索引擎 —— Puck,名称取自经典 MOBA 游戏 DOTA 中的智力英雄-Puck,是飘逸、灵动的代表。ANN全称近似最近邻检索(Approximate Nearest Neighbor),目标是从全量向量数据中寻找距离最近的TopK个向量,同时需要平衡检索效果和检索成本。
Puck 的优势
- 易用性:提供简单易用的API接入,尽量少的暴露参数,大部分参数使用默认即可达到良好性能。
- 扩展性:采用完全自研的索引结构,支持多种功能扩展,适应多种场景,项目模块划分合理,便于改造优化,可方便用户接口自行添加。
- 高性能:在benchmark的千万、亿、十亿等多个数据集上,Puck性能优势明显,均显著超过竞品。
- 可靠性:经过多年在实际大规模场景下的验证打磨,广泛应用于百度内部包括搜索、推荐等三十余条产品线,支撑万亿级索引数据和海量检索请求。
Puck 功能拓展
- 实时插入:支持无锁结构的实时插入,做到数据的实时更新。
- 条件查询:支持检索过程中的条件查询,从底层索引检索过程中就过滤掉不符合要求的结果,解决多路召回归并经常遇到的截断问题,更好满足组合检索的要求。
- 分布式建库:索引的构建过程支持分布式扩展,全量索引可以通过map-reduce一起建库,无需按分片build,大大加快和简化建库流程。
- 自适应参数:ANN方法检索参数众多,应用起来有不小门槛,不了解技术细节的用户并不容易找到最优参数,Puck提供参数自适应功能,在大部分情况下使用默认参数即可得到很好效果 。
公告指出,百度很早就投入了自研近似最近邻检索算法(ANN)的研究,2017 年 Puck 完成首次上线,2019 年底内部开源,目前已广泛应用于百度内部多条产品线,随着业务发展不断的优化和迭代,进行了充分的技术研发和测试,确保了技术的领先性和成熟度。
Puck 开源项目包含两种百度自研的检索算法Puck&Tinker,以高召回、高准确、高吞吐为目标,在大中小数据集上都有优异表现。在benchmark的千万、亿、十亿等多个数据集上,Puck性能优势明显,均显著超过竞品。在2021年底Nerulps举办的全球首届向量检索大赛BIGANN比赛中,Puck参加的四个项目均获得第一。
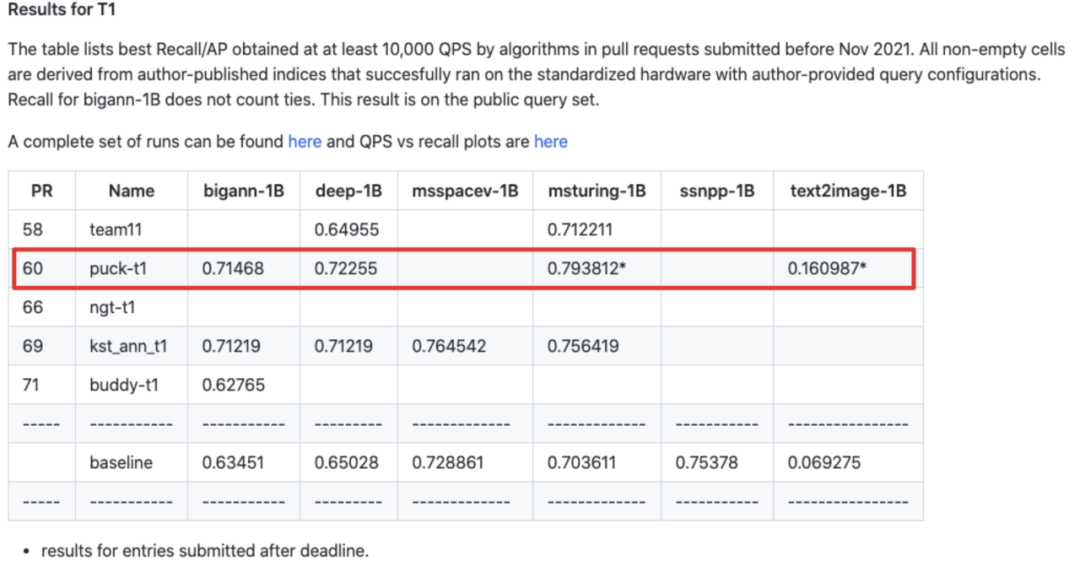
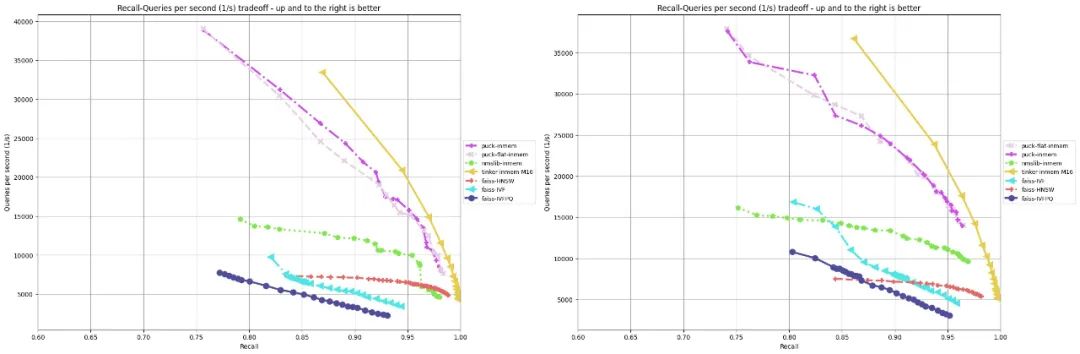
更详细的 benchmark 可在此查看。