前言
众所周知,在csdn下载资源有很多都是要收费的,最常见的是要积分的
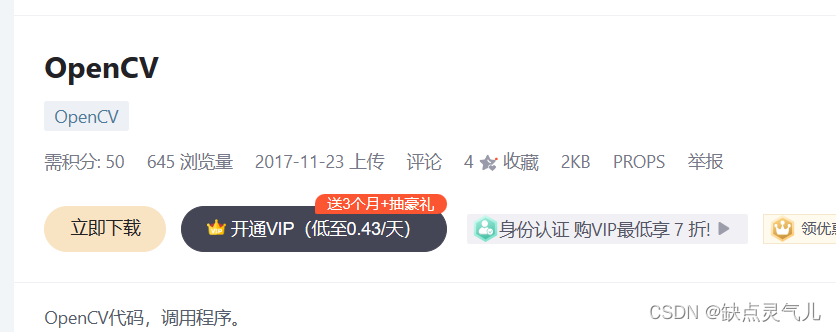
但是小编囊中羞涩,买不起VIP,也没有积分,而资源又要一个一个点进去才知道是不是免费的(最爱0积分了,老白嫖怪了),很烦
就花了一天做了个爬虫小代码来解决问题(一天?俺是菜鸟,本来也没咋练过)
顺便重温了爬虫和正则表达式,过程对本菜鸟来说挺痛苦的,估计也没人想知道,就直接放最终结果了
分步代码
导入模块
# -*- coding: utf-8 -*-
import requests
import re数据爬取
url = f'https://so.csdn.net/api/v3/search?q={key}&t=doc&p=1&s=0&tm=0&lv=-1&ft=0&l=&u=&ct=-1&pnt=-1&ry=-1&ss=-1&dct=-1&vco=-1&cc=-1&sc=-1&akt=-1&art=-1&ca=-1&prs=&pre=&ecc=-1&ebc=-1&platform=wap'
# 定义 HTTP 请求头部信息,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.203',
}
# 发送 HTTP GET 请求,并获取响应数据
response = str(requests.get(url, headers=headers).json())数据处理
originfile = re.findall("'originfile': '(.*?)'", response)
sourcescore = re.findall("'sourcescore': '(.*?)'", response)
digest = re.findall("'digest': '(.*?)'", response)
url = re.findall("'url': '(.*?)'", response)
author = re.findall("'author': '(.*?)'", response)
lenth = min([len(sourcescore), len(originfile), len(author), len(digest), len(url)])
if lenth:
dicts = {i: [sourcescore[i], originfile[i], author[i], digest[i], url[i]] for i in range(lenth)}
else:
print("没有找到您所要的数据")
return 0打印输出
b = ["所需积分:", "文件:", "上传者:", "简介:", "下载地址:"]
for i in dicts.values():
if int(i[0]) <= value:
for flag in range(5):
print(b[flag] + i[flag])
print("\n")闭包封装
# csdn积分资源搜寻器
def search(key: str, value: int):
# 第一步,数据爬取
url = f'https://so.csdn.net/api/v3/search?q={key}&t=doc&p=1&s=0&tm=0&lv=-1&ft=0&l=&u=&ct=-1&pnt=-1&ry=-1&ss=-1&dct=-1&vco=-1&cc=-1&sc=-1&akt=-1&art=-1&ca=-1&prs=&pre=&ecc=-1&ebc=-1&platform=wap'
# 定义 HTTP 请求头部信息,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.203',
}
# 发送 HTTP GET 请求,并获取响应数据
response = str(requests.get(url, headers=headers).json())
# 第二部,数据处理
originfile = re.findall("'originfile': '(.*?)'", response)
sourcescore = re.findall("'sourcescore': '(.*?)'", response)
digest = re.findall("'digest': '(.*?)'", response)
url = re.findall("'url': '(.*?)'", response)
author = re.findall("'author': '(.*?)'", response)
lenth = min([len(sourcescore), len(originfile), len(author), len(digest), len(url)])
if lenth:
dicts = {i: [sourcescore[i], originfile[i], author[i], digest[i], url[i]] for i in range(lenth)}
else:
print("没有找到您所要的数据")
return 0
# 第三步,打印输出
b = ["所需积分:", "文件:", "上传者:", "简介:", "下载地址:"]
for i in dicts.values():
if int(i[0]) <= value:
for flag in range(5):
print(b[flag] + i[flag])
print("\n")传参调用
if __name__ == '__main__':
print("这里是csdn免费资源搜寻器")
keys = input("请输入你想搜索的东西:")
values = int(input("请输入你想限制的最大积分数:"))
print("好的,请稍等片刻")
search(keys, values)
s = input("任务完成输入任意字符回车可关闭窗口")此时,整个案例就算完成了,后面附加完整代码和打包成.exe文件的方法
完整代码
# -*- coding: utf-8 -*-
import requests
import re
"""
由于csdn的付费资源也是0积分,俺是菜鸟,能力不足,无法筛选出去,请留意
"""
# csdn积分资源搜寻器
def search(key: str, value: int):
# 第一步,数据爬取
url = f'https://so.csdn.net/api/v3/search?q={key}&t=doc&p=1&s=0&tm=0&lv=-1&ft=0&l=&u=&ct=-1&pnt=-1&ry=-1&ss=-1&dct=-1&vco=-1&cc=-1&sc=-1&akt=-1&art=-1&ca=-1&prs=&pre=&ecc=-1&ebc=-1&platform=wap'
# 定义 HTTP 请求头部信息,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.203',
}
# 发送 HTTP GET 请求,并获取响应数据
response = str(requests.get(url, headers=headers).json())
# 第二部,数据处理
originfile = re.findall("'originfile': '(.*?)'", response)
sourcescore = re.findall("'sourcescore': '(.*?)'", response)
digest = re.findall("'digest': '(.*?)'", response)
url = re.findall("'url': '(.*?)'", response)
author = re.findall("'author': '(.*?)'", response)
lenth = min([len(sourcescore), len(originfile), len(author), len(digest), len(url)])
if lenth:
dicts = {i: [sourcescore[i], originfile[i], author[i], digest[i], url[i]] for i in range(lenth)}
else:
print("没有找到您所要的数据")
return 0
# 第三步,打印输出
b = ["所需积分:", "文件:", "上传者:", "简介:", "下载地址:"]
for i in dicts.values():
if int(i[0]) <= value:
for flag in range(5):
print(b[flag] + i[flag])
print("\n")
# 传参调用
if __name__ == '__main__':
print("这里是csdn免费资源搜寻器")
keys = input("请输入你想搜索的东西:")
values = int(input("请输入你想限制的最大积分数:"))
print("好的,请稍等片刻")
search(keys, values)
s = input("任务完成输入任意字符回车可关闭窗口")
打包使用
pycharm安装打包工具
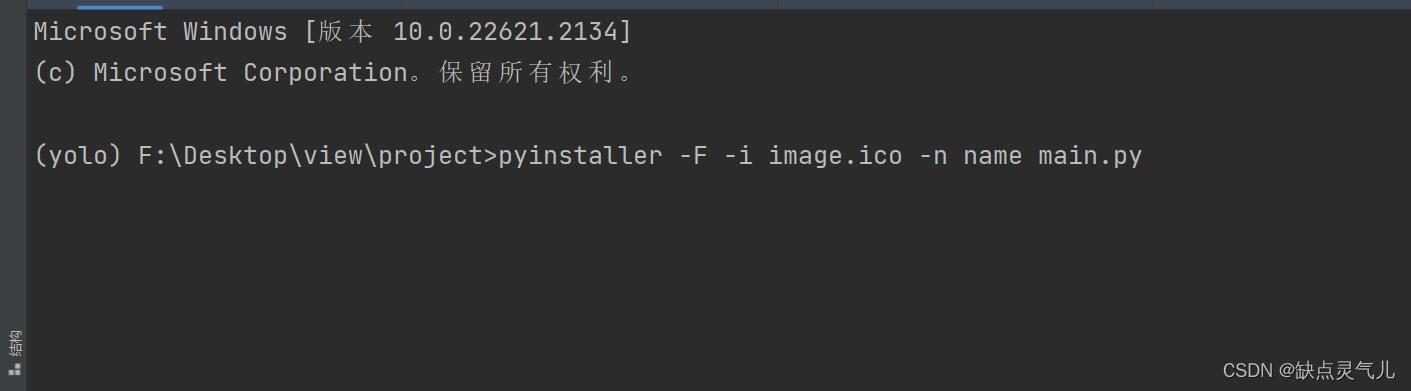
打开终端输入运行命令
pip install pyinstaller

打包成.exe文件
pyinstaller -F -i image.ico -n name main.py
图标最好用.ico格式,(虽然我的png好像也成功了),图标要换成自己的图片路径,name换成自己想要的名字,main.py 是你要打包的文件,没弹窗有输出的别写-w
参数说明
-F或--onefile:默认为禁用,即生成一个文件夹而不是单个可执行文件。-D或--onedir:默认为启用,即生成一个包含可执行文件和相关文件的文件夹。-n <name>或--name=<name>:默认为输入文件的基本名称。-w或--windowed:默认为禁用,即生成一个没有带控制台窗口的控制台程序。-c或--console:默认为启用,即生成一个有控制台窗口的窗口化程序。-i <icon>或--icon=<icon>:默认为无,默认情况下没有指定图标文件。-a <dir>或--add-data <dir>:默认为无,默认情况下不添加任何文件或目录。-b或--debug:默认为禁用,即生成一个不带调试信息的可执行文件。-p <path>或--path=<path>:默认为系统默认的模块搜索路径。-y或--noconfirm:默认为禁用,即在运行过程中会询问问题。
注意
-
-w参数禁用控制台窗口,生成的程序将不会显示命令行窗口。这在需要一个无窗口的GUI应用程序时非常有用。 -
-c参数生成一个带有控制台窗口的控制台程序,即生成的程序将在命令行窗口中运行,并可以查看程序的输出和错误信息。
默认情况下,PyInstaller会生成一个带有控制台窗口的控制台程序,因此-c 参数默认启用,而 -w 参数默认禁用。
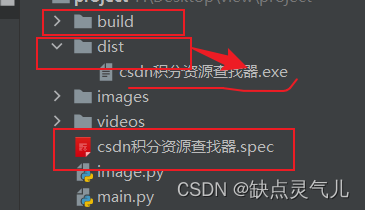
成功后生成build,dist,spec,东西在dist里,其他不重要,可删。