4.对下游任务进行微调
采用ResNet-50的epoch-300的RSP预训练模型ResNet-50-E300,
采用Swin-T的epoch-300的RSP预训练模型Swin-T-E300,
采用ViTAEv2-S的epoch-100作为ViTAEv2-S的RSP预训练模型ViTAEv2-S-E100。
采用上述三个网络的预训练模型开始对下游任务进行微调,包括图像识别,语义分割,目标检测、变换检测。场景识别采用的数据集为航拍场景中常用的,不再是MillionAID。
4.1航拍场景识别
4.1.1 数据集:①UCM数据集②AID数据集③NWPU-RESISC数据集
1.UCM:这是场景识别最重要的数据集。它包含2100张图像,大小均为256 × 256,像素分辨率为0.3m。这2100张图片分别属于21个类别。因此,每个类别有100张图片。所有样本都是从美国地质勘探局国家地图城市地区图像数据库中收集的来自全国各个城市地区的大图像中手动提取的。
2.AID:这是一个具有挑战性的数据集,它是通过收集GE上多源传感器的图像生成的。它有很高的阶级内部多样性,因为图像是从不同的国家精心挑选的。在不同的成像条件下,在不同的时间和季节提取它们。它有10000张图片,大小为600 × 600,属于30个类别。
3.NWPU-RESISC该数据集的特点是样本数量多。它包含31,500张图片和45个类别,其中每个类别有700个样本。每个图像有256 × 256像素。空间分辨率从0.2m到30m不等。一些特殊的地形,如岛屿、湖泊、普通山脉和雪山,可能分辨率较低。
4.1.2 实施细节及实验设置
设置各个数据集的训练验证比例为UCM (8:2), AID (2:8), AID (5:5), NWPU-RESISC (1:9), NWPU-RESISC (2:8).
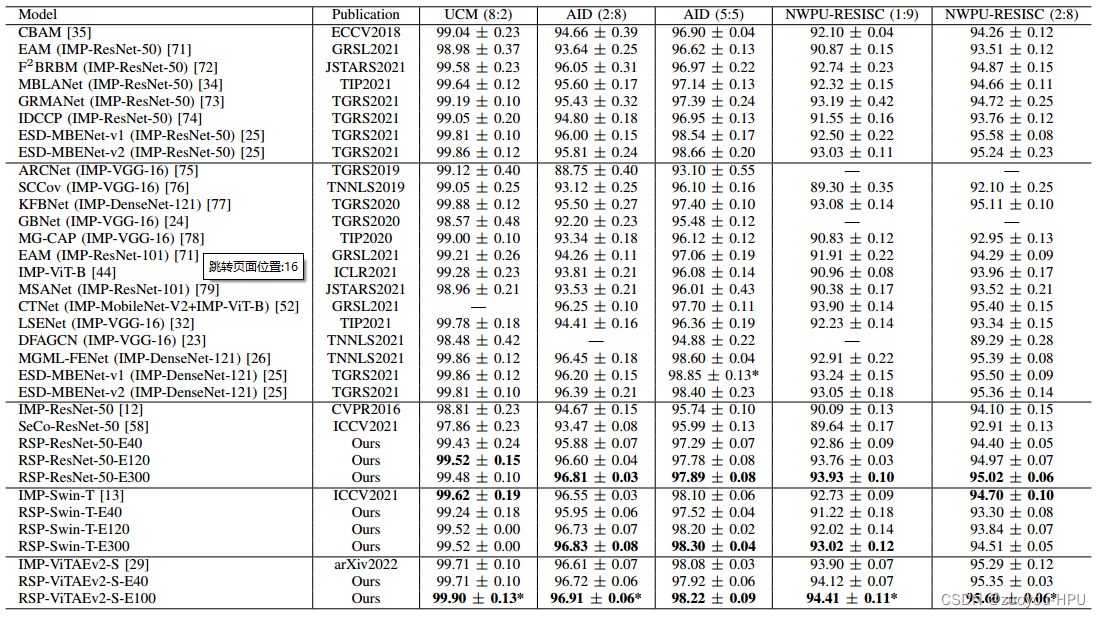
4.1.3 实验结果
4.2航空语义分割
航空语义分割也是一种类似于航空场景识别的分类任务,但它是在像素级而不是场景级。然后,我们在航空语义分割任务上对上述三种模型进行了评估,其中包括场景解析和目标分割子任务,前者侧重于标记整个场景的每个像素,后者侧重于前景目标的分割。
4.2.1 数据集
1. ISPRS Potsdam dataset:本数据集由ISPRS委员会WG II/4发布。它覆盖了波茨坦市3.42平方公里的大场景。包含38幅图像,平均大小为6000 × 6000像素,分辨率为0.5m。其中,训练集和测试集分别有24张和14张图像。这些场景包含6个类别,即不透水地表、建筑、低植被、树木、汽车和杂物。
2.iSAID:这是一个大规模的数据集,主要用于实例分割。此外,它还提供了包含空中物体的15个前景和1个背景类别的语义掩码。它由2,806张高分辨率图像组成,范围从800 × 800到4,000 × 13,000像素。训练集、验证集和测试集分别有1411张、458张和937张图像。在本文中,由于测试集不可用,因此仅使用验证集进行评估。
4.2.2 实施细节
分别对ISPRS Potsdam 和iSAID进行采样,裁剪成大小分别为512 × 512和896 × 896的patch,步幅分别为384和512,使用随机水平翻转数据增强策略。
4.2.3 实验结果


4.3航空目标检测
由于航空图像是在天空中自上而下拍摄的,因此在鸟瞰图中物体可以在任何方向呈现。因此,空中目标检测是定向边界框(OBB)检测,它区别于通常在自然图像上的水平边界框(HBB)任务]。在本文中,与分割类似,在实验中也使用了不同的检测数据集。具体地,分别对多类遥感目标检测和单类船舶检测子任务进行了评估。
4.3.1 数据集 采用同DOTA和HRSC2016数据集
DOTA:这是最著名的OBB检测大规模数据集。总共包含2806张图片,大小从800 × 800到4000 × 4000不等,其中包括15个类别的188282个实例。训练集、验证集和测试集分别有1411/458/937张。
HRSC2016:这是一个专门的船舶检测数据集,其中边界框以任意方向标注。包括1061幅图像,大小从300 × 300到1500 × 900不等。在官方部门中,436/181/444张图像分别用于训练、验证和测试。数据集只有一个类别,因为不需要识别船舶的类型。
4.3.2 实施细节及实验设置
对DOTA数据集进行采样并裁剪为1024 × 1024块,步长为824,而对HRSC2016图像进行缩放,保持较短边的宽高比为800,较长边的长度小于或等于1333。训练过程中的数据增强包括随机水平和垂直翻转。为方便起见,将原始训练集和验证集合并进行训练,而分别使用DOTA和HRSC2016的原始测试集进行评估。我们报告了所有类别的平均精度(mAP)和每个类别在相应测试集上的平均精度(AP)。
4.3.3实验结果


5.结论
在本研究中,我们研究了基于CNN和视觉变压器的最大遥感数据集MillionAID上的遥感预训练问题,并对它们在四项相关任务上的性能进行了综合评价。包括场景识别、语义分割、对象检测和变化检测,并与ImageNet预训练和其他Sota方法进行了比较。通过对实验结果的综合分析,得出如下结论:
1.与传统的CNN模型相比,视觉变换器在一系列遥感任务中表现出竞争力,并且在一些更具挑战性的数据集上,如iSAID和DOTA,它们可以获得更好的性能。特别是ViTAEv2-S,一种将CNN电感偏置引入视觉变换器的高级型号,在这些任务的几乎所有设置上都实现了最佳性能。
2.受益于ImageNet-1K数据集的大容量,经典的IMP使深度模型能够学习更多的通用表示,可以很好地推广到下游任务中的几乎所有类别。因此,IMP可以产生竞争力的基线结果,尽管空中场景。RSP与IMP相当,在一些特定的类别上表现非常好,如“桥”和“飞机”,这是由于减轻了上游预训练任务和下游任务之间的数据水平差异。
3.任务级差异也会对RSP的性能产生负面影响。如果特定下游任务所需的表示粒度为更接近的上游预训练任务,即场景识别,RSP通常会导致更好的性能。
我们希望本研究能为我们在使用先进的视觉变压器和遥感预训练方面提供有益的启示。在今后的工作中,我们将针对下游任务在大规模数据集上研究rsp,以及考虑到这一领域中大量未标记数据的非监督预培训。